知识图谱
知识图谱(Knowledge Graph,KG)由Google于2012年正式提出,致力于以结构化的形式描述客观世界中实体及其之间的关系;从表现形式看,可以简单理解为多关系图;被认为是从“感知智能”向“认知智能”发现的一个重要里程碑。
按时间逻辑关系,可以分为:离线部分和在线部分。离线部分通过知识构建、知识获取、知识存储,生成知识图谱,而在线部分使用知识图谱去做知识查询、知识表示、知识推理。
首先,知识建模。知识图谱是由实体和关系组成,通俗地说是由点和边组成。首先进行知识建模,确定知识图谱包括哪些实体,以及实体和实体之间具有什么样的关系。
其次,知识加工。这一步目的是获取结构化数据。无论是通过爬虫爬取现成的结构化数据,还是通过CRF、HMM等传统统计模型,亦或是NN-CRF等深度学习模型,去从半结构化和非结构化数据中,识别出实体,进而转成结构化数据。
将结构化数据填充入知识图谱的方法大致有两种,一是分两阶段提取,先提取实体,再提取关系。二是联合提取,直接提取实体和关系。在加工的过程中,可能有几个问题需要我们去解决。拿第一种方法来说,首先需要从结构化数据中提取实体,即点,实体数据可能会有很多噪声,比如近义词、歧义。所以需要利用自然语言处理技术对实体进行融合、链接。然后需要从结构化数据中提取关系,即边,关系抽取可以依赖NLP技术或者少量人工标注的弱监督,例如远程监督算法去完成。
最后是知识存储。图存储相较于关系型存储,是从下到上建设,上层一开始很难有固定的计算范式,底层图是一种更灵活的结构。具体的图数据库或图存储,在公司内部有iGraph、GeaBase、MaxGraph、GraphDB等。其中iGraph不是严格意义上的图数据库,是查询引擎。GeaBase是蚂蚁的查询、存储引擎。GDB,是在线实时图数据库。
离线部分到这里就粗略讲完了,知识图谱已经构建完毕,下面讲一下在线部分,即知识图谱的应用。
首先是知识查询。知识查询比较简单,给定一个切入点,从整个知识图谱中查询出相关实体数据,再进行扩线查询一度关系、多度关系。
其次是知识表示。其实说到底无论是知识图谱,还是自然语言处理,再或是传统的机器学习,这些上层领域的应用都需要依赖知识的表征,只不过不同领域的术语不一样罢了,本质都是在做数据的向量化表征,知识图谱中是利用图embedding达到知识表示这个目的。
最后是知识推理。相较于单纯的知识查询,知识推理是最具有想象力的技术。因为知识查询不会产生新知识,都是知识图谱中有的。而知识推理可以通过图谱中已知的实体/关系/属性等,推测出隐藏在图谱多度关系之后的隐含知识。例如可以基于逻辑规则的FOIL/PRA算法、基于距离表示的TransX系列算法、基于图神经网络的DeepWalk/HeGNN算法等去做实体推理、边推理。推理出的实体属性、边,是新知识,先前不存在的知识。
安全知识图谱
基础安全领域,安全知识图谱主要有APT组织图谱、网络空间测绘图谱、漏洞知识图谱、恶意样本知识图谱、软件供应链安全图谱、攻击路径推理图谱等。
其中APT组织图谱的实体是STIX框架定义的实体,举个例子:NSA利用永恒之蓝漏洞发起攻击。那么威胁主体是NSA,攻击工具是Metasploit,攻击模式是永恒之蓝漏洞攻击,漏洞是CVE-2017-0143,应对措施是关闭445端口。其数据来源主要是APT报告。对于乙方安全来说,尚且可以投入,但对于甲方安全来说,可落地性、实际价值不高。
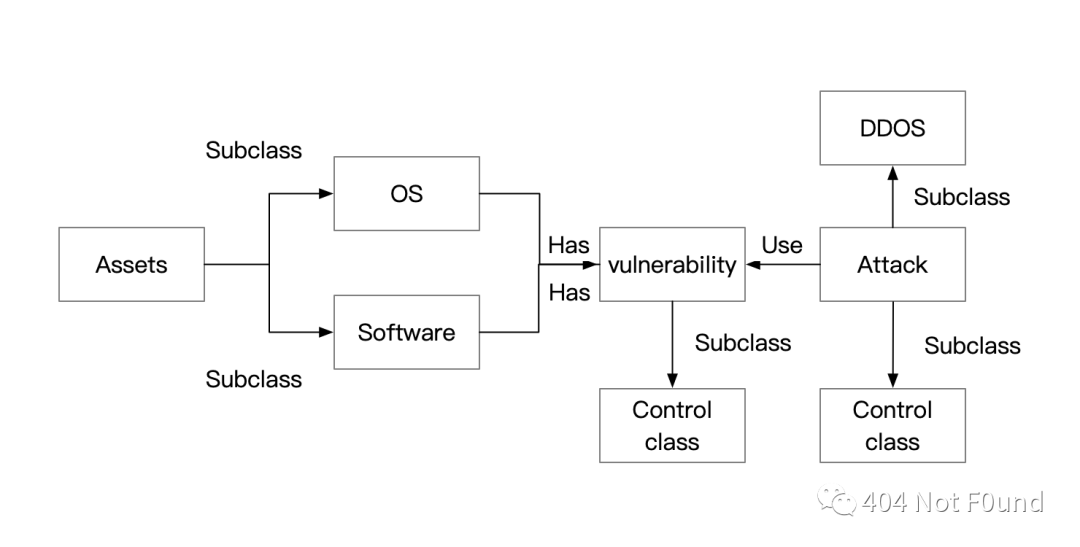
再比如漏洞知识图谱,实体是漏洞、资产、软件、操作系统、攻击,关系有子类、含有、使用,定义出来的本体模型:
其数据来源是各种漏洞库,攻击来源是诸如OWASP、SRC之类信息安全网站。场景可落地性还可以,兼顾实际价值,适合大甲方、乙方安全投入,不适合中小甲方安全。
业务安全领域,知识图谱的安全应用主要有基于实体推理、边推理的的账户风控、转账交易风控、内容安全等等。
举两个例子,实体推理可以应用到个人或企业主体账户的风控,根据已有风险账户和关系,推理出其他账户是否是风险账户。
边推理可以应用到业务转账风控中,一次转账的发起,以往风控可能通过发起方和接收方的设备维度信息,或者两方间是否存在朋友或者转账的直接关系,去判断转账是否可信。现在借助边推理技术,可以推理出你朋友的朋友的朋友是你的朋友,或者推理出你对陌生人的转账,陌生人是你多年未联系的老同学,还是诈骗犯。
上面这些应用场景看上去五花八门,但实际上都是一样的套路:将安全问题转化为知识图谱问题,定义知识结构,填充数据。在这个过程中,知识图谱最大的价值体现是作为一个标准范式,融合多源异构数据,有希望作为一个数据中心、决策中心。
攻击者知识图谱
攻击者知识图谱(Attacker Knowledge Graph,AKG),目的是数字化攻击者,发现头部攻击者、群体、攻击活动,提升防守方对攻击方发起威胁的对抗能力。
攻击者知识图谱是基于威胁情报相关标准之一的STIX框架(Structured Threat Information eXpression,结构化威胁信息表达式)魔改、填充知识而成,还在不断优化。回过头来看,最大的挑战反而不在于框架性实体和关系的定义,而在于很朴素的一点:数据,贴合本企业的真实、高价值、安全数据的长期沉淀,汇聚的数据渠道、种类、量级越多,越能发挥出1+1>2的效果。
当前AKG主要包括10+个节点,40+条边,节点主要有攻击主体、身份、硬件设备、网络环境、攻击工具、漏洞、恶意软件、攻击模式、攻击活动、攻击指示、受害者等,边主要有身份利用攻击指示和恶意软件、攻击指示攻击过受害者、攻击指示指示工具等。
知识构建阶段:知识建模效果图
知识加工阶段:根据先前知识建模阶段定义的知识结构,有目的性地获取各个维度的数据。另外,考虑到投资回报比,我们分阶段获取知识,先易后难。第一个阶段相对简单,按照攻击者数字化维度的需求,从团队内外获取所有能获取到的资源,这部分资源主要是已经经过处理的单点、高价值、结构化数据,比如ioc数据,各类安全产品的告警运营数据,稍作加工即可使用,例如基于安全产品拦截数据可以产出攻击者身份维度信息。需要注意的是这个阶段会考验沟通协调能力,在这里感谢团队内部、主站安全团队和阿里云安全团队师傅们、各个外部安全情报厂商的理解和支持。
第二个阶段相对复杂,因为不可能什么都是现成的。需要依赖数据智能和机器智能技术,清洗原始数据,预测提取出攻击者各个维度的结构化数据。比如工具维度,主站安全同学支持了常见黑客工具的识别,在此基础上,我们训练机器学习算法对机器攻击进行了识别。比如攻击源维度,我们训练攻击聚类算法,试图从海量攻击数据中找到它们的共性,结果也有了一些发现。再比如漏洞维度,当前获取结构化CVE情报需要依靠官方和第三方厂商例如snyk,时间滞后且不可控。因此我们把从非结构化CVE数据中提取结构化数据的安全问题转化为了自然语言处理领域中的经典任务:命名实体识别。基于经典神经网络可以实时从CVE描述性文本中预测出漏洞影响的产品名和版本号实体信息。
有了上面这些个单点结构化数据,还需要根据先前知识建模阶段定义的知识结构,对点与点进行关联分析构建边关系。如果只是对边界安全做攻击者画像的话,一般用来源ip进行关联。如果是全链路的话,会变复杂很多。比如一个RCE穿透过边界安全防护、生产网防护,在机器上成功执行黑客命令,就需要从命令等维度进行关联。
当完成了上面两个阶段,数据就分门别类地汇入到知识图谱中,变成了知识。
知识存储阶段:攻击者知识图谱依赖网商独立化部署的知识图谱平台知蛛,不用操心图存储、图计算等底层知识存储能力,可以专注于做上层的分析和推理。
离线攻击者知识图谱到这里构建完毕,此时,我们已经将所有历史知识和专家经验知识,按照一定的标准化结构,打入到了AKG。下面是在线部分。
知识查询:攻击者知识查询,只需要一个切入点信息,就可以查询出所有相关的历史知识,无论是在溯源排查,还是威胁研判,都可以被广泛应用。因为这属于降维打击,用一个面的知识,对抗你一个个点状知识。比如根据我的支付宝ID进行知识查询,可以得到所有的一度关系,然后可以扩展得到二度关系,以此类推。
知识表示和知识推理,强依赖Gremlin语法、图的embedding、图神经网络算法等技术,尚处于探索阶段,推测可以用于高危攻击及攻击者群体发现。
攻击者知识图谱作为一个数据中心,触达的数据五花八门,有应用层的流量数据、端上数据、各系列安全产品防御数据、各安全项目建设及运营产出数据、蚂蚁安全数据、集团安全数据、阿里云威胁情报数据、金融行业情报数据、三方外采情报数据等。从数据流通的角度,攻击者知识图谱作为一个情报交换中心,用数据流联动各个防御节点,提升安全产品单点防御能力和整体安全防线水位。当数据累积到一定量级,可能完成数据、情报中心向决策中心的进化。
Ref
安全场景知识图谱应用(作者:绮琛)
安全知识图谱技术白皮书《践行安全知识图谱,携手迈进认知智能》(作者:绿盟科技)
如有侵权请联系:admin#unsafe.sh