一、联邦学习背景和意义
我们正处在万物互联的人工智能时代,大数据驱动的人工智能推动着各个行业快速发展,但是事实上在大多数行业中,数据是以孤岛的形式存在的,由于隐私保护、行业竞争、数据资产利益冲突等诸多问题,使得同行业下不同公司甚至是同公司不同部门之间的数据整合成为难题。联邦学习技术,能够在数据孤岛之间架设桥梁,成为在满足数据安全下解决数据孤岛的一个可行方案。二、联邦学习概述
联邦学习是一种机器学习技术。传统的机器学习需要将客户端的数据上传至服务器进行训练,用户数据的隐私成为了一个大问题。在联邦学习中服务器端将训练程序下发到客户端,客户的数据就在客户端计算下降的梯度和损失,或者是模型的参数,并上传至服务器,服务器将来自各个客户端的数据整合,更新模型的参数,这样就完成了训练的一次迭代,经过若干次迭代之后模型训练成功。即数据不出本地的情况下,各方进行数据联合训练,建立共享的机器学习模型。![]()
2.2 联邦学习的特点
各方数据都保留在本地,不泄露隐私也不违反法规;
各个参与者联合数据建立虚拟的共有模型,并且共同获益的体系;
在联邦学习的体系下,各个参与者的身份和地位相同;
联邦学习的建模效果和将整个数据集放在一处建模的效果相同,或相差不大;
迁移学习是在用户或特征不对齐的情况下,也可以在数据间通过交换加密参数达到知识迁移的效果。
2.3 联邦学习在机器学习技术中的地位
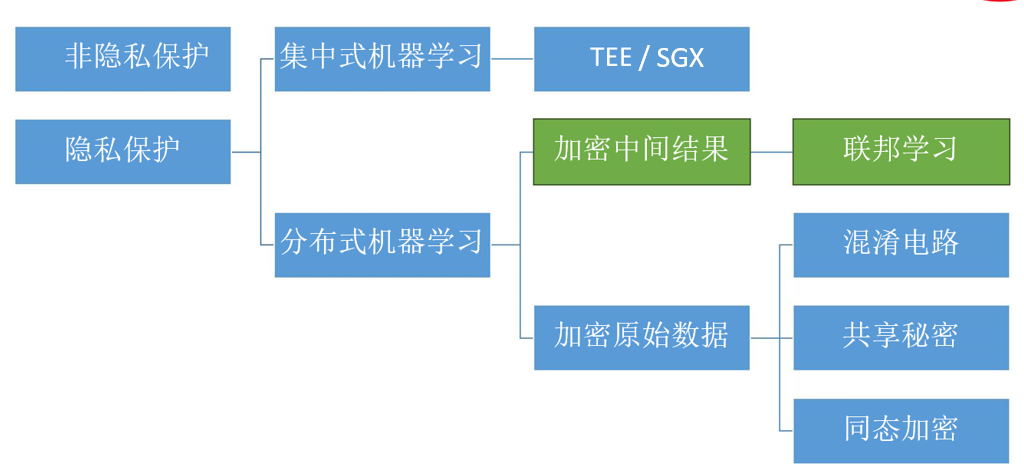
将机器学习按照是否进行隐私保护的维度进行划分,集中式机器学习的代表是基于硬件的TEE(可信执行环境),其技术实现被叫做SGX(英特尔实现)。基于硬件的技术是在CPU的层面上进行加密和解密,要求数据持有方将数据送入物理机集群中。分布式机器学习有两种技术路线,为了保护数据隐私,第一种方案是加密原始数据后进行运行,无论后续如何操作,底层数据均不可见。第二种思路是加密中间结果,由于原始数据集可能会很大,加解密过程长导致运算效率会很低。所以不加密原始数据,而是加密两个机器学习算法进行交换的中间结果。通过加密中间结果的方式来隐藏原始数据,这就是联邦学习的主要思想。![]()
2.4 联邦学习对加密技术的使用
目前,主流的联邦学习多用同态加密技术。同态加密的主要思路是需要把未加密的数据送到运算方,但想在运算方不知道数据具体内容的前提下,让其对数据进行运算。在同态加密中,对经过同态加密的数据进行处理得到一个输出,将这一输出进行解密,最终其结果与用同一方法处理未加密的原始数据得到的输出结果是一样的。也就是说同态加密是一种不需要访问数据本身就可以加工数据的方法![]()
图中,用Alice和Cloud模拟云场景下的同态加密过程。
Alice对数据进行加密。并把加密后的数据发送给Cloud;Alice向Cloud提交数据的处理方法,这里用函数f来表示;Cloud在函数f下对数据进行处理,并且将处理后的结果发送给Alice;严格来说,目前实现的联邦学习只能称作半同态加密,F只能实现加法(全同态要求F还能实现乘法)三、联邦学习分类
我们将以孤岛数据的分布特点为依据对联邦学习进行分类。考虑有多个数据拥有方,每个数据拥有方各自所持有的数据集 D_i 可以用一个矩阵来表示。矩阵的每一行代表一个用户,每一列代表一种用户特征。同时,某些数据集可能还包含标签数据。如果要对用户行为建立预测模型,就必须要有标签数据。我们可以把用户特征叫做 X,把标签特征叫做 Y。比如,在金融领域,用户的信用是需要被预测的标签 Y;在营销领域,标签是用户的购买愿望 Y;在教育领域,则是学生掌握知识的程度等。用户特征 X 加标签 Y 构成了完整的训练数据(X,Y)。但是,在现实中,往往会遇到这样的情况:各个数据集的用户不完全相同,或用户特征不完全相同。具体而言,以包含两个数据拥有方的联邦学习为例,数据分布可以分为以下三种情况:两个数据集的用户特征(X1,X2,…)重叠部分较大,而用户(U1, U2…)重叠部分较小;
两个数据集的用户(U1, U2…)重叠部分较大,而用户特征(X1,X2,…)重叠部分较小;
两个数据集的用户(U1, U2…)与用户特征(X1,X2,…)重叠部分都比较小。
为了应对以上三种数据分布情况,我们把联邦学习分为横向联邦学习、纵向联邦学习与联邦迁移学习。
![]()
在两个数据集的用户特征重叠较多而用户重叠较少的情况下,我们把数据集按照横向(即用户维度)切分,并取出双方用户特征相同而用户不完全相同的那部分数据进行训练。这种方法叫做横向联邦学习。比如有两家不同地区银行,它们的用户群体分别来自各自所在的地区,相互的交集很小。但是,它们的业务很相似,因此,记录的用户特征是相同的。此时,就可以使用横向联邦学习来构建联合模型。Google 在 2017 年提出了一个针对安卓手机模型更新的数据联合建模方案:在单个用户使用安卓手机时,不断在本地更新模型参数并将参数上传到安卓云上,从而使特征维度相同的各数据拥有方建立联合模型的一种联邦学习方案。
![]()
在两个数据集的用户重叠较多而用户特征重叠较少的情况下,我们把数据集按照纵向(即特征维度)切分,并取出双方用户相同而用户特征不完全相同的那部分数据进行训练。这种方法叫做纵向联邦学习。比如有两个不同机构,一家是某地的银行,另一家是同一个地方的电商。它们的用户群体很有可能包含该地的大部分居民,因此用户的交集较大。但是,由于银行记录的都是用户的收支行为与信用评级,而电商则保有用户的浏览与购买历史,因此它们的用户特征交集较小。纵向联邦学习就是将这些不同特征在加密的状态下加以聚合,以增强模型能力的联邦学习。目前,逻辑回归模型,树型结构模型和神经网络模型等众多机器学习模型已经逐渐被证实能够建立在这个联邦体系上。
![]()
在两个数据集的用户与用户特征重叠都较少的情况下,我们不对数据进行切分,而可以利用迁移学习来克服数据或标签不足的情况。这种方法叫做联邦迁移学习。比如有两个不同机构,一家是位于中国的银行,另一家是位于美国的电商。由于受到地域限制,这两家机构的用户群体交集很小。同时,由于机构类型的不同,二者的数据特征也只有小部分重合。在这种情况下,要想进行有效的联邦学习,就必须引入迁移学习,来解决单边数据规模小和标签样本少的问题,从而提升模型的效果。
四、联邦学习框架
以包含两个数据拥有方(企业A和企业B)的场景为例,出于数据隐私和安全考虑,A 和 B 无法直接进行数据交换。此时,可使用联邦学习系统建立模型,系统架构由两部分构成,如下图所示。![]()
第一部分:加密样本对齐。由于两家企业的用户群体并非完全重合,系统利用基于加密的用户样本对齐技术,在 A 和 B 不公开各自数据的前提下确认双方的共有用户,并且不暴露不互相重叠的用户。以便联合这些用户的特征进行建模。第二部分:加密模型训练。在确定共有用户群体后,就可以利用这些数据训练机器学习模型。为了保证训练过程中数据的保密性,需要借助第三方协作者 C 进行加密训练。以线性回归模型为例,训练过程可分为以下 4 步:协作者 C 把公钥分发给 A 和 B,用以对训练过程中需要交换的数据进行加密;
A 和 B 之间以加密形式交互用于计算梯度的中间结果;
A 和 B 分别基于加密的梯度值进行计算,同时 B 根据其标签数据计算损失,并把这些结果汇总给 C,C 通过汇总结果计算总梯度并将其解密;
C 将解密后的梯度分别回传给 A 和 B;A 和 B 根据梯度更新各自模型的参数。
迭代上述步骤直至损失函数收敛,这样就完成了整个训练过程。在样本对齐及模型训练过程中,A 和 B 各自的数据均保留在本地,且训练中的数据交互也不会导致数据隐私泄露。因此,双方在联邦学习的帮助下得以实现合作训练模型。第三部分:效果激励。联邦学习的一大特点就是它解决了为什么不同机构要加入联邦共同建模的问题,即建立模型以后模型的效果会在实际应用中表现出来,并记录在永久数据记录机制(如区块链)上。提供的数据多的机构会看到模型的效果也更好,这体现在对自己机构的贡献和对他人的贡献。这些模型对他人效果在联邦机制上以分给各个机构反馈,并继续激励更多机构加入这一数据联邦。以上三个步骤的实施,即考虑了在多个机构间共同建模的隐私保护和效果,又考虑了如何奖励贡献数据多的机构,以一个共识机制来实现。所以,联邦学习是一个“闭环”的学习机制。五、联邦学习应用实例
要平衡数据孤岛与数据隐私之间的关系是联合建模面临的挑战。从图中可以看到,联合建模的效果最好,但是隐私保护的难度最高。定制和通用建模比较简单,但是精度一般。联邦学习综合了两方的优点,可以在有效保护隐私的前提下达到较好的模型效果,且模型难度较低。![]()
图为微众银行FATE联邦学习模型原理架构图,微众银行和腾讯进行联合建模,在底层是无法进行数据交互的。在进行联邦学习之前,双方需要先对齐样本,而后通过同态加密共享中间结果。如此以来,双方的数据不需要出私有域,也更好地保护数据安全。而且整个操作是远程的,无需驻场,高效便捷,能够实现模型的快速迭代。![]()
六、未来展望
基于联邦学习的智能风控有利于促进基于数据安全联合建模的AI技术应用落地,更好地支撑消费金融行业的价值创造,并提升此类行业的风险控制能力。同时可以通过联邦学习提升金融科技公司对金融机构各项业务的服务能力。目前,联邦学习已实现可参与至风控流程各环节,包括反欺诈、白名单初筛、信贷预审、贷中和贷后预警评分等,根据业务企业及机构需求,可进行多维度合作。后续,联邦学习将通过深入信贷风控审核主流程,进一步用联邦建模渗透到信审各环节,实现数据隐私保护下的数据连接及合作。
文章来源: https://mp.weixin.qq.com/s?__biz=Mzg3NDY3NjcxOA==&mid=2247483942&idx=1&sn=c29eb68a439f6ed82b2c2ef8fa3aa665&chksm=cecc6aa7f9bbe3b11eb74f484545f79d19e4043d1bf9e94d865376f49d90871a99881a247a78&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh