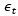
腾讯御见UEBA(用户实体行为分析)面向政务、金融、能源等行业的办公安全、数据安全、员工行为管理,使用一系列分析方法(统计学习、机器学习等高级分析方法)通过分析用户实体(用户、设备、主机等)相关行为日志构建用户实体画像(静态画像、动态画像),然后基于用户实体画像进行风险检测、风险分析、风险评估,最终识别内部风险用户和风险实体。在产品上,提供仪表板和风险时间线能力,帮助感知和运营,提升运营效率。
![]()
在用户实体行为分析(UEBA)中,很多场景都会用到时间序列分析、预测、检测相关的技术,例如:
检测某个重要服务器外发的数据大小是否异常
检测两个端点之间的通信模式是否异常
检测某个账号从服务器下载的数据量是否异常
检测某个用户访问的内网资源数量是否异常
检测用户每天的首次活跃时间是否有异常
然而,传统的分析方法无法较好的应对多周期、多变点、趋势变化等复杂因素下的时间序列检测问题,在落地中会带来较多的误报。因此,我们在UEBA的落地实践中,针对时间序列检测和预测问题做了一系列算法上的调研与落地尝试。本文主要介绍在复杂时间序列异常检测问题上,广泛受认可的方法:fbprophet。介绍有关时间序列的基本知识。先让大家理解算法上如何看待时间序列这类数据。
介绍fbprophet方法的原理。
介绍该方法与LSTM方法的效果对比,及分享我们在UEBA中做场景落地时候的收获。
小结。
附录:自动选择拐点时的处理逻辑
小彩蛋
时间序列在机器学习领域,是比较特别的一类数据。原因是它在取值之外,加上了时间维度。在检测问题上,它检测的是在某个时间点,观察到这个取值是否是正常的,而不是仅仅看取值是不是正常。例如,某个服务器在凌晨发1G/分钟的数据出去,与在中午12点发1G/分钟的数据的意义是不一样的,正常情况下,我们更倾向于中午12点的观测是由于访问量增加导致的,而凌晨的观测可能是由于被攻击导致的。因此,在检测时间序列之前,我们首先需要对时间序列的常见模式有个基本的认识。目前,工业界和学术界普遍将时间序列建模为如下几种因素,周期、频率、趋势、节假日、随机波动。下面结合一组图来介绍时间序列的几个关键概念,让大家对它有一个直观的理解,例如下图1和图2具有明显的周期形状(某个形状重复出现),下图1和下图2的周期重复频率又是不一样的(某个形状重复出现的快慢不一样),图1的频率比图2的频率高。图3和图4则在周期之外,添加了趋势分量,图3为平稳上升的趋势,图4则是平稳下降趋势。图5和图6则有了“均值漂移”的表现,在两张图中的中间部分可以看到“陡增“和“陡降”形状,在这部分改变之后,时间序列的走势又趋于平稳,在UEBA中我们叫它“拐点”,业界结合业务因素将这种“拐点”解释为由于节假日或者故障导致的波动因素。我们面对的时间序列检测问题,可以理解为是在复杂的因素综合作用下,识别哪些是异常变化,而不是由于趋势变化、周期变化、节假日活动影响导致的预期内变化。该问题在行业内是一个极具挑战的问题,而在我们的产品中,由于要把异常检测的能力做成一个通用的内置能力提供给客户,还要保证良好的效果,因此,在算法选型上具有更大的挑战。结合我们团队在时间序列检测上的一些积累,下文分享工业界领先的fbprophet方法及在ueba中的应用尝试。fbprophet方法是facebook开源的一个时间序列检测利器,频繁被AIOps作为瑞士军刀使用。它的特点在于调参成本低,即便不调参,也可以获得不错的效果,它的另一个优点是训练成本低,在UEBA的大部分场景中,它可以在分钟级别完成训练和预测,并且效果媲美训练了2,3个小时的lstm模型。这个优点,让它我们私有化的场景中加分不少,因为我们UEBA上,计算资源紧张,并且检测的问题很多。那么它是如何做到在保证质量的同时,还能在分钟级完成建模的呢?Fbprophet方法基于传统的加性模型,它将时间序列建模为趋势、周期、节假日和高斯噪声分量的加和,也就是说将观测的结果看作是4个分量的加法作用,可以表示为:其中g(t), s(t),h(t)分别为趋势分量、周期分量、节假日分量,![]() 为高斯噪声分量。在这个框架下,该方法为每个子分量精心的设计了模型。
为高斯噪声分量。在这个框架下,该方法为每个子分量精心的设计了模型。
fbprophet提到使用两种模型分别是饱和增长模型和线性模型来建模趋势分量。其中饱和增长模型的含义是指观测指标有个理论上的上限,且观测指标的变化以某个速率进行变化。例如,环境的可容纳人口有上限60亿,人口每年以0.4%的速率进行增长,那么我们观测每年的地球人口数量,可以按基础的饱和增长模型进行预测。饱和增长模型的基本形式如下:g(t)为趋势分量随时间变化的函数。其中C为饱和总量,k为增长率,m为常量偏置项。比较特别的是,在fbprophet这个方法中,它提出C,k都不应该是一个常量,它们应该也会随着时间t而变化。怎么理解呢?例如在互联网中,我们监控产品DAU,C则为网民数量,而网民数量不是静态不变的,它也是不断增加的,而同样的,在DAU上的增长率k也应是动态变化的。在这个设想下,C建模为时间t的函数C(t),在考虑k的变化的时候,则会更精细一点,它会考虑哪些因素对k有重要的影响,例如“拐点”。假设时间序列中存在S个拐点,每个拐点都对时间序列的走势有影响,那么在j时刻的影响大小为j之前时刻的拐点影响的总和。基于这个思路,首先将这些拐点的改变用向量表示为![]() 其中
其中![]() 为在拐点
为在拐点![]() 处增长率k的变化大小。那么在时间t处的增长率k会变为
处增长率k的变化大小。那么在时间t处的增长率k会变为![]() 。为了使用向量表示,引入一个指示向量
。为了使用向量表示,引入一个指示向量![]() .
.![]() 变为
变为![]() . 在偏置项的改变上,在j处也可以调整为:【至于为什么是这种形式,可以理解为,
. 在偏置项的改变上,在j处也可以调整为:【至于为什么是这种形式,可以理解为,![]() 为当前拐点的时间点,m为一个固定的偏置量,从
为当前拐点的时间点,m为一个固定的偏置量,从![]() 后退一个偏置量,再将过去拐点未知的扰动量减掉,剩下从语义上来说应为一个本次拐点的扰动大小。之后再利用增长率变化的大小做一个尺度的调整,即为本次拐点位置的扰动量。】在考虑C和k的动态性之后,原基础的饱和增长模型变化为:该模型也为fbprophet拟合中,growth取‘logistic’时的趋势项模型。在使用中,饱和总量C(t)需要事先指定,其他几个参数则有默认取值。除此之外,将logistic函数换为线性函数(或其他函数),即变为趋势模型的线性表示方式:该方法相比logistic趋势而言,虽然看上去简单,但实际使用中发现效果挺好,而且没有饱和总量C的参数。
后退一个偏置量,再将过去拐点未知的扰动量减掉,剩下从语义上来说应为一个本次拐点的扰动大小。之后再利用增长率变化的大小做一个尺度的调整,即为本次拐点位置的扰动量。】在考虑C和k的动态性之后,原基础的饱和增长模型变化为:该模型也为fbprophet拟合中,growth取‘logistic’时的趋势项模型。在使用中,饱和总量C(t)需要事先指定,其他几个参数则有默认取值。除此之外,将logistic函数换为线性函数(或其他函数),即变为趋势模型的线性表示方式:该方法相比logistic趋势而言,虽然看上去简单,但实际使用中发现效果挺好,而且没有饱和总量C的参数。
fbprophet考虑时间序列中存在多周期的情况,并利用fourier 变换来进行周期的表示。周期分量的fourier表示形式如下,其中通过配置不同的P和n,可以实现不同尺度的周期表示。一般来说,我们会配置(365.23,10),(7,3)两组参数,来抓住年周期趋势和周周期趋势。 它支持算法人员传入过去和未来的节假日列表,对于每个节假日,支持配置节假日的影响窗口,例如圣诞前前后各一天都算节假日的影响范围。在每个节假日上,配置对观测值的影响大小,即为![]() ,
, ![]() 表示第i个节假日的区间。我们假设服从均值为0,方差为的正态分布。在模型建立之后,在模型训练阶段,fbprophet方法利用stan’s LBFGS方法进行优化求解。容量C:在选择饱和增长模型的时候,容量C必须配置,具体的取值依赖业务知识(相比arima方法等,这种调参成本很低)拐点:拐点可以选择主动传入,也可以自动选择,自动选择的情况下,默认从前80%的点中,等距的选择25个点作为拐点。节假日和周期性:依赖业务经验,一般而言,可以依赖可视化来进行模型调优。(把曲线画出来,看下大概是什么样的周期,节假日变点在哪里)平滑参数:算法人员通过调节τ,v,δ 3个参数来控制拟合曲线的平滑度。lstm方法是深度学习方法中针对时间序列的经典方法,对比fbprophet方法而言,它没有建模过程,直接从历史观测序列中学习拟合。此处对lstm方法不做介绍,仅仅把它的结果和fbprophet方法做个对比。
表示第i个节假日的区间。我们假设服从均值为0,方差为的正态分布。在模型建立之后,在模型训练阶段,fbprophet方法利用stan’s LBFGS方法进行优化求解。容量C:在选择饱和增长模型的时候,容量C必须配置,具体的取值依赖业务知识(相比arima方法等,这种调参成本很低)拐点:拐点可以选择主动传入,也可以自动选择,自动选择的情况下,默认从前80%的点中,等距的选择25个点作为拐点。节假日和周期性:依赖业务经验,一般而言,可以依赖可视化来进行模型调优。(把曲线画出来,看下大概是什么样的周期,节假日变点在哪里)平滑参数:算法人员通过调节τ,v,δ 3个参数来控制拟合曲线的平滑度。lstm方法是深度学习方法中针对时间序列的经典方法,对比fbprophet方法而言,它没有建模过程,直接从历史观测序列中学习拟合。此处对lstm方法不做介绍,仅仅把它的结果和fbprophet方法做个对比。
从预测效果上看,lstm预测效果比fpprophet要好,实验中lstm的mse值在0.21,而fbprophet方法的mse在0.25。但是在训练时间上,lstm在无GPU的机器上,训练用了2.5小时,而fbprophet方法在默认参数下,分钟级别完成训练和预测。在UEBA的实践中,针对“设备外发数据量检测”,“用户访问资源数量检测”,基于该方法都取得了较好的效果,从中也体会到该方法善于抓住周期、趋势和突变的优点,极大的降低了误报。UEBA中的很多场景涉及到时间序列检测问题,在业界的大多数实现方案中,可以通过k-sigma,box-plot,esd,s-esd, wavelet, fourier decomposion等多种方法来进行检测。但实际中,发现简单的模型会带来比较多的误报,而复杂的模型又没有办法在有限的资源中进行全量检测。因此,在算法的实际落地中,我们在UEBA中多采用层次检测和集成检测两种思路,层次检测指的是搭建多个简单模型对全量数据进行粗筛,之后在用性价比高、可解释性好的模型进行精准检测,在某些场景中,我们也会采用多个算法集成输出的思路,以提高检测的有效性和准确性。
拐点作为该方法的亮点之一,此处附加fbprophet方法中关于拐点的选择逻辑。该算法原文中提到,算法人员可以主动提供拐点(可以通过将时间序列画出来,拿到拐点,传入算法模型);也可以根据业务经验粗略的定拐点(例如一年中的节假日、产品活动日等)。最后也可以由算法自动的进行拐点的选择。在自动选择拐点的模式下,算法人员传入对δ的一个稀疏先验,并假设该稀疏先验服从参数为(0,τ)的拉普拉斯分布。τ在调参上的含义主要是用来控制在增长率改变上的灵活度,如下,拉普拉斯分布在中间部分的集中度是不一样的,在集中度比较小的时候,对τ有较大的概率采样到一个较大的值,自动选择拐点的逻辑具体如下:假设T个点中有S个拐点,每个拐点服从一个参数为(0,τ)的拉普拉斯分布。在预测的情况下,我们模拟未来增长率的改变,通过将τ替换为一个从数据中推测得到的数值。这个数值使用过去拐点处增长率改变的均值。在预测未来走势的时候,拐点是按如下方式采样得到。
这里有个假设是在增长率的改变上,未来会有与过去相同的平均频率和幅值。当增大τ的时候,训练误差会降低。
该账号主要围绕智能化技术如何帮助企业提升网络安全水平展开,内容涉及机器学习、大数据处理等智能化技术在安全领域的实践经验分享,业界领先的产品和前沿趋势的解读分析等。通过分享、交流,推动安全智能的落地、应用。欢迎关注~
文章来源: https://mp.weixin.qq.com/s?__biz=MzI2NDUyMjAyOA==&mid=2247484259&idx=1&sn=17a397fd81cee37fade72afc74ae03f9&chksm=eaaa1320dddd9a36fe89014b5001d00264032001cbbe2610eb88f24b9c46fbb9b333b12ea9fd&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh