目录
一、ARM VMP简介
二、框架设计
三、文件分析反汇编
四、Opcode指令解析与VMCode生成
五、增加节区与入口点
六、VMP引擎
七、总结一、ARM VMP简介
ARM VMP是这几年颇为流行的移动端代码指令保护技术,该技术方案大规模应用到软件保护领域最早在PC时代源于俄罗斯的著名保护软件"VmProtect",该方案引起了软件保护壳领域的革命。各大软件保护壳开发团队都将虚拟机保护这一新颖的技术加入到自己的产品中。但是到目前为止该软件还未对ARM平台支持。
随着移动端安全开发的升级,移动应用的安全越来越被重视,在PC时代用到的VMP方案也被成功应用到移动端的加固产品中来。
二、框架设计
从加壳的整体流程来看主要分为加壳端与VM引擎端,引擎负责解析VM后的指令。框架主要分为代码分析与代码执行两个部分,如图1-1(ARM VMP加壳流程)与1-2(ARM VMP引擎运行流程)所示:
图2-1
图2-2
本节着重讲解了加壳与VM引擎的模块组成与总体流程设计思想,具体流程讲解在后面分析。
三、文件分析反汇编
在进行加壳保护之前,首先有一个重要的问题就是保护对象,确认保护对像是要反汇编分析识别出要保护的目标,解析ELF文件格式定位到目标指令,一个标准的ELF文件,是由文件头(ELF Header),程序头(Segment Header),节头(Section Header),符号表( Symbol Table),动态符号表(Dynamic Symbol Table)等组成,如下图3-1所示:
图3-1
反汇编目标指令。代码如下:
void disasm(unsigned char* code, size_t codesize, std::vector<string>& retcode){std::vector<string> strcode;uint64_t address = 0x40001000;cs_insn* insn;int i;size_t count;cs_err err;if (NULL == code || codesize <= 0) {return;}err = cs_open(CS_ARCH_ARM, CS_MODE_THUMB, &handle);if (err) {printf("Failed on cs_open() with error returned: %u\n", err);}count = cs_disasm(handle, code, codesize, address, 0, &insn);if (count) {size_t j;char codetemp[50] = {};for (j = 0; j < count; j++) {printf("0x%" PRIx64 ":\t%s\t%s\n", insn[j].address, insn[j].mnemonic, insn[j].op_str);sprintf_s(codetemp, sizeof(codetemp),"%s %s", insn[j].mnemonic, insn[j].op_str);printf("frm : %s\n", codetemp);string strcodetemp(codetemp);retcode.push_back(strcodetemp);}cs_free(insn, count);}elseprintf("ERROR: Failed to disassemble given code!\n");cs_close(&handle);return;}
通过反汇编引擎从代码开头开始遍历。先找函数开头的标记后,接下来找函数结尾,找到后与前一个开头标记进行闭合并记录。遇到其余指令则直接略过。依次循环下去。
当我们找到了我们的保护对象并将其反汇编后,接下来要做的是将每条汇编指令转换成opcode码,方便后续做VMcoode转换。代码如下:
void assemble_ks(const std::vector<std::string>& code, std::vector<uint32_t>& bycode) {std::vector<uint32_t> result;ks_engine* ks;ks_err err;size_t count;unsigned char* encode;size_t size;ks_arch arch = KS_ARCH_ARM;int mode = KS_MODE_THUMB;const char* assembly;int syntax = 0;Pks_open ks_open;Pks_option ks_option;Pks_asm ks_asm;Pks_free ks_free;Pks_close ks_close;Pks_errno ks_errno;HMODULE keystonedll = LoadLibrary("keystone.dll");if (NULL == keystonedll) {return;}ks_open = (Pks_open)GetProcAddress(keystonedll, "ks_open");ks_option = (Pks_option)GetProcAddress(keystonedll, "ks_option");ks_asm = (Pks_asm)GetProcAddress(keystonedll, "ks_asm");ks_free = (Pks_free)GetProcAddress(keystonedll, "ks_free");ks_close = (Pks_close)GetProcAddress(keystonedll, "ks_close");ks_errno = (Pks_errno)GetProcAddress(keystonedll, "ks_errno");if (NULL == ks_open || NULL == ks_option || NULL == ks_asm) {return;}err = ks_open(arch, mode, &ks);if (err != KS_ERR_OK) {printf("ERROR: failed on ks_open(), quit\n");return;}if (syntax)ks_option(ks, KS_OPT_SYNTAX, syntax);for (int i = 0; i < code.size(); i++) {std::string tempcode;tempcode = code[i];assembly = tempcode.c_str();if (ks_asm(ks, assembly, 0, &encode, &size, &count)) {printf("ERROR: failed on ks_asm() with count = %lu, error code = %u\n", count, ks_errno(ks));}else {size_t i;printf("%s = ", assembly);for (i = 0; i < size; i++) {printf("%02x ", encode[i]);}printf("\n");printf("Assembled: %lu bytes, %lu statements\n\n", size, count);}uint32_t byte_code = *((uint32_t*)encode);bycode.push_back(byte_code);ks_free(encode);}ks_close(ks);return;}
当分析到具体的指令时,将当前指令的编码,信息,结构以及引用的内存或者数据记录到指令记录结构。
四、Opcode指令解析与VMCode生成
指令信息分析,主要对每个需要保护的每条指令进行分析,将此条指令的机器码,汇编代码,内存地址,是否引用了数据,以及对标志寄存器与通用寄存器的影响一一列出。
arm指令一般编码格式和一般语法格式如下图4-1与4-2所示:
图4-1
图4-2
找到原始的Opcode替换成一个随机产生的OPCODE,默认Opcode的转码规则是采用将Opcode表与Handel通过打乱原有的映射生成的。例如原先“mov R0, 1”指令的硬编码是“4FF001 00”其Opcode部分是“4f”则在转换后有可能变换为“5fF001 00”。代码如下所示:
DecodedOperation Decoder::decode(uint32_t instr) {DecodedOperation op;op.cond = (instr & 0xF0000000) >> 28;op.i = (instr >> 25) & 1;op.s = (instr >> 20) & 1;op.code = (instr >> 21) & 0xF;op.reg_d = (instr >> 12) & 0xF;op.reg_n = (instr >> 16) & 0xF;if (op.i) {op.imm_val = instr & 0x000000FF;op.imm_rot = instr & 0x00000F00;} else {op.reg_m = instr & 0x0000000F;op.reg_s = instr & 0x00000FF0;}return op;}m_i = op.i;m_s = op.s;m_cond = op.cond;m_op_code = op.code;m_op_reg_d = op.reg_d;m_op_reg_n = op.reg_n;m_op_reg_m = op.reg_m;m_op_reg_s = op.reg_s;m_imm_val = op.imm_val;m_imm_rot = op.imm_rot;
五、增加节区与入口点
虚拟机保护会将被保护的代码与数据抹掉替换成VM入口,如果使用静态分析此函数将会一无所获。在虚拟机初始化阶段会使用“VM入口”来填充这个位置。当运行到此函数时,会首先进入“VM入口”。
VM入口代码,原始指令被替换成如下入口代码:
mov r0, codeindex //vmcode索引bx vmEntrance
添加新节区写入引擎代码与vmcode:
int addSectionFun(char *lpPath, char *szSecname, unsigned int nNewSecSize){char name[MAX_PATH];FILE *fdr, *fdw;char *base = NULL;Elf32_Ehdr *ehdr;Elf32_Phdr *t_phdr, *load1, *load2, *dynamic;Elf32_Shdr *s_hdr;int flag = 0;int i = 0;unsigned mapSZ = 0;unsigned nLoop = 0;unsigned int nAddInitFun = 0;unsigned int nNewSecAddr = 0;unsigned int nModuleBase = 0;memset(name, 0, sizeof(name));if(nNewSecSize == 0){return 0;}fdr = fopen(lpPath, "rb");strcpy(name, lpPath);if(strchr(name, '.')){strcpy(strchr(name, '.'), "_vm.so");}else{strcat(name, "_new");}fdw = fopen(name, "wb");if(fdr == NULL || fdw == NULL){printf("Open file failed");return 1;}fseek(fdr, 0, SEEK_END);mapSZ = ftell(fdr);base = (char*)malloc(mapSZ * 2 + nNewSecSize);memset(base, 0, mapSZ * 2 + nNewSecSize);fseek(fdr, 0, SEEK_SET);fread(base, 1, mapSZ, fdr);if(base == (void*) -1){printf("fread fd failed");return 2;}ehdr = (Elf32_Ehdr*) base;t_phdr = (Elf32_Phdr*)(base + sizeof(Elf32_Ehdr));for(i=0;i<ehdr->e_phnum;i++){if(t_phdr->p_type == PT_LOAD){if(flag == 0){load1 = t_phdr;flag = 1;nModuleBase = load1->p_vaddr;}else{load2 = t_phdr;}}if(t_phdr->p_type == PT_DYNAMIC){dynamic = t_phdr;}t_phdr ++;}s_hdr = (Elf32_Shdr*)(base + ehdr->e_shoff);nNewSecAddr = ALIGN(load2->p_paddr + load2->p_memsz - nModuleBase, load2->p_align);if(load1->p_filesz < ALIGN(load2->p_paddr + load2->p_memsz, load2->p_align) ){if( (ehdr->e_shoff + sizeof(Elf32_Shdr) * ehdr->e_shnum) != mapSZ){if(mapSZ + sizeof(Elf32_Shdr) * (ehdr->e_shnum + 1) > nNewSecAddr){printf("添加节区失败\n");return 3;}else{memcpy(base + mapSZ, base + ehdr->e_shoff, sizeof(Elf32_Shdr) * ehdr->e_shnum);ehdr->e_shoff = mapSZ;mapSZ += sizeof(Elf32_Shdr) * ehdr->e_shnum;s_hdr = (Elf32_Shdr*)(base + ehdr->e_shoff);}}}else{nNewSecAddr = load1->p_filesz;}int nWriteLen = nNewSecAddr + ALIGN(strlen(szSecname) + 1, 0x10) + nNewSecSize;char *lpWriteBuf = (char *)malloc(nWriteLen);memset(lpWriteBuf, 0, nWriteLen);s_hdr[ehdr->e_shstrndx].sh_size = nNewSecAddr - s_hdr[ehdr->e_shstrndx].sh_offset + strlen(szSecname) + 1;strcpy(lpWriteBuf + nNewSecAddr, szSecname);Elf32_Shdr newSecShdr = {0};newSecShdr.sh_name = nNewSecAddr - s_hdr[ehdr->e_shstrndx].sh_offset;newSecShdr.sh_type = SHT_PROGBITS;newSecShdr.sh_flags = SHF_WRITE | SHF_ALLOC | SHF_EXECINSTR;nNewSecAddr += ALIGN(strlen(szSecname) + 1, 0x10);newSecShdr.sh_size = nNewSecSize;newSecShdr.sh_offset = nNewSecAddr;newSecShdr.sh_addr = nNewSecAddr + nModuleBase;newSecShdr.sh_addralign = 4;load1->p_filesz = nWriteLen;load1->p_memsz = nNewSecAddr + nNewSecSize;load1->p_flags = 7; //可读 可写 可执行ehdr->e_shnum++;memcpy(lpWriteBuf, base, mapSZ);memcpy(lpWriteBuf + mapSZ, &newSecShdr, sizeof(Elf32_Shdr));fseek(fdw, 0, SEEK_SET);fwrite(lpWriteBuf, 1, nWriteLen, fdw);fclose(fdw);fclose(fdr);free(base);free(lpWriteBuf);return 0;}
六、VMP引擎
VMcode定义完后,就可以开始实现解释VMcode的解释器了。解释器我们需要实现一个虚拟环境以及各个VMcode对应的handle函数。虚拟环境则是真实物理机的一个虚拟,是自己定义的字节码运行的环境。
主要有如下步骤:
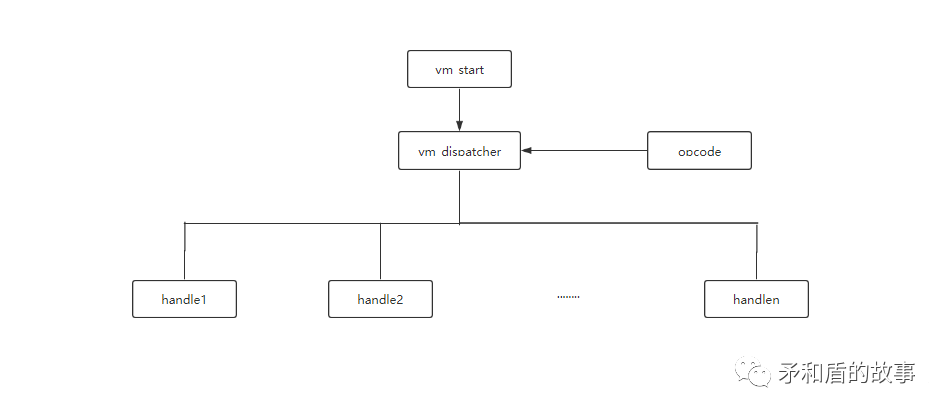
1、进入vm_start:
虚拟机的入口函数,对虚拟机环境进行初始化
2、vm_dispatcher:
调度器,解释opcode,并选择对应的handle函数执行,当handle执行完后会跳回这里,形成一个循环。
3、opcode :
程序可执行代码转换成的操作码
虚拟机执行的基本流程如图6-1所示:
图6-1
代码如下所示:
void VirtualMachine::execute() {uint32_t *op_dest = &m_registers[ m_op_reg_d ];uint32_t op_a = m_registers[ m_op_reg_n ];uint32_t op_b = m_registers[ m_op_reg_m ];if (m_i) {op_b = m_imm_val;}switch (m_op_code) {case Instruction::OP_AND:*op_dest = op_a & op_b;break;case Instruction::OP_EOR:*op_dest = op_a ^ op_b;break;case Instruction::OP_SUB:*op_dest = op_a - op_b;break;case Instruction::OP_RSB:*op_dest = op_b - op_a;break;case Instruction::OP_ADD:*op_dest = op_a + op_b;break;case Instruction::OP_ADC:*op_dest = op_a + op_b + m_carry;break;case Instruction::OP_SBC:*op_dest = op_a - op_b + m_carry - 1;break;case Instruction::OP_RSC:*op_dest = op_b - op_a + m_carry - 1;break;case Instruction::OP_TST:m_reg_cpsr = op_a & op_b;break;case Instruction::OP_TEQ:m_reg_cpsr = op_a ^ op_b;break;case Instruction::OP_CMP:m_reg_cpsr = op_a - op_b;break;case Instruction::OP_CMN:m_reg_cpsr = op_a + op_b;break;case Instruction::OP_ORR:*op_dest = op_a | op_b;break;case Instruction::OP_MOV:*op_dest = op_b;break;case Instruction::OP_BIC:*op_dest = op_a & (~ op_b);break;case Instruction::OP_MVN:*op_dest = ~ op_b;break;default:break;}}uint32_t VirtualMachine::run(std::vector<uint32_t> instructions) {*m_reg_pc = 0;m_running = true;while (m_running) {show_registers();uint32_t instr = fetch(instructions);decode(instr);execute();}return 0;}
七、总结
由于VMP方案的原因,大部分使用VMP场景时都考虑到效率问题,一般的程序都是只对一些核心算法进行了VMP,以达到防逆向分析或破解的目的。
一个好的VMP保护产品需要考虑很多方面,安全、性能、兼容、易用等,其中代码分析引擎、虚拟机引擎保护做得好与否直接关系到产品的稳定性。
如有侵权请联系:admin#unsafe.sh