摘要:样例采用内存位置无关代码编程并带混淆,经过1401次对折叠代码的层层随机释放执行,最终对userkey进行逻辑运算(或解密)后与拓展的username对比。
找到一个支点就可以突防。
一、随机释放执行机制
代码都是内存位置无关代码,使用相对地址索引相关信息;
主要是将系统的栈克隆到全局区域,然后释放相应代码执行;
栈操作主要针对 NtTib中的StackBase和StackLimit操作,这是我们要的主要支点。
dt nt!_TEB32 nttib. ntdll!_TEB32 +0x000 NtTib : +0x000 ExceptionList : Uint4B +0x004 StackBase : Uint4B +0x008 StackLimit : Uint4B +0x00c SubSystemTib : Uint4B +0x010 FiberData : Uint4B +0x010 Version : Uint4B +0x014 ArbitraryUserPointer : Uint4B +0x018 Self : Uint4B
以下是主程序入口的代码逻辑,从中我们可以看到它是如何迁移和切换栈的
(1)通过VirtualProtect开放读写属性,用于释放后擦除;
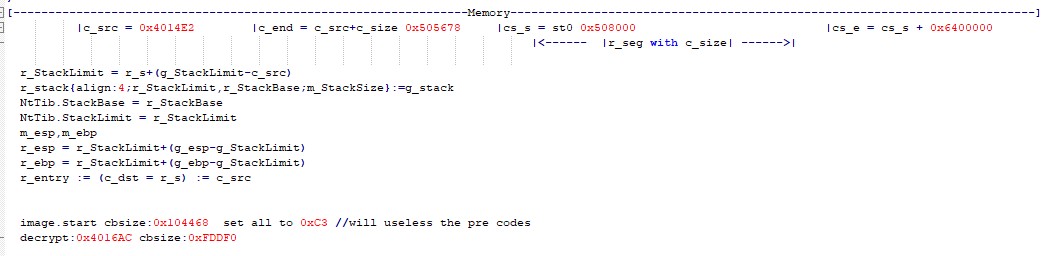
(2)通过浮点寄存器st0保存image.20hww处的随机执行区域基址;
(3)将系统栈内容复制到全局区域的m_stack,同时更新esp和ebp相对全局栈;
(4)最后给系统装上自己的全局栈。
main
-------------esp
.-04hww tmpvar
VirtualProtect from main.start.0x401210 to 0x505678:=start+0x104468
VirtualProtect from base.0x400000 to 0x401000:=start+0x1000
st0 = image.20hww 0x508000
m_stack{
m_StackBase.bottom = NtTib.StackBase
m_StackLimit.top = NtTib.StackLimit
image.24hww = m_StackSize = m_StackLimit-m_StackBase = 0x3000
}
m_esp,m_ebp
g_esp = g_StackLimit+(m_esp-m_StackLimit)
g_ebp = g_StackLimit+(m_ebp-m_StackLimit)
g_stack{align:4;g_StackLimit,g_StackBase;m_StackSize}:=m_stack
NtTib.StackBase = g_StackBase启动时核心代码区间如下,其中username和userkey位于区间中
c_src = 0x4014E2 username: 4FF49B userkey: 4FF65C c_size = 0x104196 c_end = c_src+c_size 0x505678
随机代码执行区间如下,代码会根据rdtsc指令结果随机释放到该区间位置
cs_s = st0 0x508000 随机代码执行区起始基址(非执行入口),不变 cs_e = cs_s + 0x6400000 随机代码执行区尾部,不变 rdtsc_mod = rdtsc % 0x6400000 随机代码释放点偏移量,也是执行入口, r_s = cs_s+rdtsc_mod 解密释放代码到随机地址,也作为入口,每次释放由于rdtsc计算的不同而不同 r_e = r_s + c_size
每次释放代码都会伴随栈的复制迁移和挂靠,也会”清除“之前的代码(全设为C3指令)。

跟随一两层释放执行过程,是条不归路,unicorn伴keystone或miasm模拟执行是另一条牛刀女装路。
还是看看有没其他着力点。
二、着力点
由于代码和数据(包括username和userkey)每次都随机迁移到执行区,所以没有写自动化跟踪脚本辅助下,人工追踪的可行性没法预期。
(1)尝试
由于最后输出错误提示,我们试着断最后的prinf来回溯,看看有没发现,最好其调用点附件的上下文是明文对比,希望是美好的,万一真是呢。

很好,轻松到达错误的终点,赶紧回头看下返回地址上下文处有没明文对比userkey,如下

(A)prinf的返回点位于0x6D12DCD,我们可以看到其参数的传递,无疑就是错误信息内容地址。
(B)我们同时注意到前面还有个printf,且有个jne跳转,去看下上面的printf的参数内容。
hex(0x6012D65-0x401122+0x404B47)
的确如所料,'0x601678a'是正确信息的内容地址,当然,我们这时与其他敏感信息区擦肩而过(我们现在假装没看到下图后面方框区域内容)
正确提示后面的KCTF应该是看到的,这时拓展username,16字节,也假装没看到。

当我们看到判断的前面"C3C3C3C3"时,心凉半截,执行过的代码被擦除了!

问题变成了如何赶在擦除之前拿到代码,又回到了起初的怎么跟踪这N层释放,毕竟我们要最后一层的代码。
看到群了的”女装“,我们应该有所启示————栈的挂靠
三、不变应万变
由于每次释放前都需要先复制迁移栈并设置挂靠,所以我们选择了TEB中StackBase作为我们的硬件断点位置
如下图,我们拿到TEB内存位置

然后我们在StackBase处设置我们的硬件写断点

然后一路女装狂奔(直接点的,保持个优雅的姿势,按这F9一动不动,跟它耗上,调试器是x64dbg)
最终如下图,总共触发了1401次。

OK,马上再来一个更优雅的姿势,跑到1401次时停止 (如果忘了清除之前的硬件断点,不妨命令行里清除下bphc)
如下图,我们停在第1401次硬件断点处

剩下就是一路F7单步进入了,F8很容易跑飞,飞了就只能重来。

来到下面这部分,看到老相识lodsb,和后面一堆猛操作,就知道是解密代码的业务逻辑,

记下代码地址(0x53c3A8C) 和大小(大小 0x3b33+1= 0x3b34 ),并在后面的循环结束处,断下,等解密完后,dump出代码

来到断点后,代码已解密完,我们可以
运行命令dump出来:
savedata "C:\CTF2019\Q4\CTF06\last_3B34.dec",0x53c3A8C,0x3b34
参考附件内容。继续F7,于是我们碰见老朋友rdtsc和0x6400000,这些都是前面完成栈操作后,实现代码迁移到随机执行区,
最后通过call eax 转移执行,这部分代码才是我们的主角,
其中ecx=0x53C3B17,大小位0x9E56,同样,我们dump出来备用
savedata "C:\CTF2019\Q4\CTF06\last_9e56.dec",0x66988A,0x9e56

四、主角
由call eax跳转后,没几条指令就进入关键步骤,开头是擦除之前的代码(有兴趣也可以在擦除前dump出来)
然后就是计算esi地址,存放username和userkey的地方,曾记否,我们在前面曾与它擦肩而过
从 push ebp;mov ebp,esp开始是完整函数的序言操作(enter),这个很重要,能不能有效去掉混淆,还原核心代码逻辑就靠它。

在进入序言之前,我们看下计算出的esi指向的内容,特别是序言开始后,操作的esi+0x1B0这些,就是我们输入的userkey

五、IDA表演时间
为了方便,我们就近取材,在主函数里,第一次解密0x4016AC出的代码位置,
我们将我们最后dump出的核心代码加载到0x4016AC处,
IDAPython执行 loadfile(r"C:\CTF2019\Q4\CTF06\last_9e56.dec",0,0x4016AC,0x9e56)

【四中】的IDA版,其中几处,简单运用了混淆清除,多此一举,有兴趣可以参考后面内容。

重建核心函数基本操作就是,按”U“(undefine push ebp前面的代码),从序言开始一直使用”C“ (code)反汇编。
一直到尾部;其实到pop ebp实际也已经可以,可以后面修改ret就行,直接全面反编译也可以,影响不大。

函数的尾部将变换后(或解密出)的userkey与拓展username比较,相等正确,比较长度时0x10


其中看到121212这些是最初使用的输入的测试userkey=12121212121212121212121212121212 ,如果使用A0A1A2A3A4A5A6A7A8A9AAABACADAEAF,dump出来加载后此处看到的就是A0A1A2A3A4A5A6A7A8A9AAABACADAEAF,但算法换算(解密)后,如果正确就会和拓展的username一样,
其中username是覆盖补齐的16字节


上面nop部分应用了部分去混淆,收尾工作如下图,pushf和popf确保上述的repe cmpsb结果不受清除代码过程影响

下面是去除混淆后的


应当注意到下述结果信息

下述代码用于简单清除 call-pop-sub-add 模式混淆,其他混淆并未处理,sim_call_pop_sub_add(0,1),参数1提供call $0地址(默认当前地址),参数2作为开关控制是否asm with nop替换未简化结果,使用keystone汇编器
from keystone import *
ks = Ks(KS_ARCH_X86, KS_MODE_32)
import sark,idc
def sim_call_pop_sub_add(ea = 0,basm=False):
global ks
if ea == 0:
ea = idc.here()
cl_call = sark.Line(ea)
cl_pop =cl_call.next
cl_sub =cl_pop.next
cl_add =cl_sub.next
if cl_call.insn.mnem!='call' or cl_pop.insn.mnem!='pop' or cl_sub.insn.mnem!= 'sub' or cl_add.insn.mnem!= 'add':
raise Exception("not call pop sub add")
iv = cl_pop.ea
vs = cl_sub.insn.operands[1].imm
va = cl_add.insn.operands[1].imm
r = cl_add.insn.operands[0].reg
print("{:X} {:X} {:X}".format(iv,vs,va))
asmstr = "MOV {},0x{:X}".format(r,iv-vs+va)
encoding, count = ks.asm(asmstr)
if basm:
i4size = sum([ins.size for ins in [cl_call,cl_pop,cl_sub,cl_add]])
#asmc = ''.join(chr(c) for c in encoding)
#asmc+= '\x90'*(i4size-asmc.__len__())
asmc = encoding + [0x90]*(i4size-len(encoding))
pea = cl_call.ea
for i in range(0,len(asmc)):
idc.PatchByte(pea+i,asmc[i])
return [encoding,count,asmstr]六、【F5】
虽然一直对F5排斥,但无奈之下还是得用上一用,毕竟对付简单的混淆,编译器语法树层级的一些优化效果还是很可观。如图

去混淆可观,结果还不是很直观,我们整理修改编译下,完整测试代码参考附件c代码。
a2是我们的esi,原码的userkey放于esi+0x1B0处,对齐,我们优化之前去掉了0x1B0,让userkey从0开始对齐,
这样a2指向需要解密的userkey即可,中间的prinf结果用于python还原逆向逻辑时观察保证逆向的逻辑正确性对比。
因为在调试中,我们使用
K:A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 AA AB AC AD AE AF
解密后得到是
D:7B E6 79 E0 89 E3 D3 6B 83 ED 81 EB 7A EA 5A 0A
所以我们每次修改 decrypt2的代码,都要确保由K得到正确的D,且pythn逆向逻辑过程中,中间的观察量需要与C代码输出的一致。
void decrypt2(int a2){
__int16 K0f;
__int16 K21;
__int16 K43;
__int16 K65;
__int16 K87;
__int16 Ka9;
__int16 Kcb;
__int16 Ked;
__int16 wTX;
__int16 Kr1;
__int16 Kr2;
int wS;
int Ks;
int wX;
int wA;
int wT1;
int wT3;
int wST;
int wR;
unsigned int A53;
unsigned int x6587;
K0f=*(unsigned __int8*)(a2+0xF)+(*(unsigned __int8*)(a2+0x0)<<8);
K21=*(unsigned __int8*)(a2+0x1)+(*(unsigned __int8*)(a2+0x2)<<8);
K43=*(unsigned __int8*)(a2+0x3)+(*(unsigned __int8*)(a2+0x4)<<8);
K65=*(unsigned __int8*)(a2+0x5)+(*(unsigned __int8*)(a2+0x6)<<8);
K87=*(unsigned __int8*)(a2+0x7)+(*(unsigned __int8*)(a2+0x8)<<8);
Ka9=*(unsigned __int8*)(a2+0x9)+(*(unsigned __int8*)(a2+0xA)<<8);
Kcb=*(unsigned __int8*)(a2+0xB)+(*(unsigned __int8*)(a2+0xC)<<8);
Ked=*(unsigned __int8*)(a2+0xD)+(*(unsigned __int8*)(a2+0xE)<<8);
wS=(unsigned __int16)(Kcb-Ka9);
wX=(K21^K43)&0xFFFF;
x6587 = K65^K87;
A53=(unsigned __int16)((((x6587&0x5555)+(((unsigned __int16)x6587>>1)&0x5555))&0x3333)
+(((unsigned __int16)((x6587&0x5555)
+(((unsigned __int16)x6587>>1)&0x5555))>>2)&0x3333));
Ks=((unsigned __int16)((A53&0xF0F)+((A53>>4)&0xF0F))>>8)
+(unsigned __int8)((A53&0xF)+((A53>>4)&0xF));
wA=(K0f+Ked);
wT1=(unsigned __int16)(wS&~(_WORD)wX|wX&wA);
printf("wS:%X\twX:%X\twA:%X\twT1:%X\n",wS,wX,wA,wT1);
wTX=wT1^K65;
Kr1=__ROL2__(wTX,Ks);
Kr2=__ROL2__(wT1^K87,Ks);
printf("x6587:%X\tks:%d\n",x6587,Ks);
wT3=(unsigned __int16)((wX*(unsigned int)(unsigned __int16)wT1>>Ks)+24);
wST=wS^wT3;
wR=wT1&wT3|(unsigned __int16)wST&(wT1|wT3);
printf("wT3:%X\twST:%X\twR:%X\n",wT3,wST,wR);
printf("wTX:%X\tKr1:%X\tKr2:%X\n",wTX,Kr1,Kr2);
*(_WORD*)(a2+0x0)=K43^wR; //U10 or D10
*(_WORD*)(a2+0x2)=K21^wR; //U32 or D32
*(_WORD*)(a2+0x4)=wST+K0f; //U54 or D54
*(_WORD*)(a2+0x6)=Ked-wST; //U76 or D76
*(_WORD*)(a2+0x8)=wT3+Kcb; //U98 or D98
*(_WORD*)(a2+0xA)=wT3+Ka9; //Uba or Dba
*(_WORD*)(a2+0xC)=Kr2; //Udc or Ddc
*(_WORD*)(a2+0xE)=Kr1; //Ufe or Dfe
}七、正向与反向业务逻辑
(A)正向验证逻辑:由decrypt(usrekey)==extern(username)
上述核心代码中,userkey(定义为K),K (Ked,Kcb,Ka9,K87,K65,K43,K21,K0f,其中0到f表示对userkey的索引下标)
主要是对K变换(或者解密)得到D (D10,D32,D54,D76,D98,Dba,Ddc,Dfe,其中0到f表示索引下标)
最后D与默认拓展的username(定义为U),U (U10,U32,U54,U76,U98,Uba,Udc,Ufe,其中0到f表示索引下标)比较。
即验证逻辑是userkey是否解密得到拓展的username。(从K到D或U)
而注册机逻辑就需要我们从拓展的username得到userkey。(从U或D 到K)
其中的拓展username机制是,username的默认值是下述全局定义数组,
char u[0x11] = {0x9A, 0x1E, 0x1D, 0x1C, 0x1B, 0x1A, 0x19, 0x18, 0x17, 0x16, 0x15, 0x14, 0x13, 0x12, 0x11, 0x10};
通过scanf("%s",&u[0])方式覆盖读入,如输入KCTF,或将 0x9A, 0x1E, 0x1D, 0x1C, 0x1B,覆盖为KCTF\x00(注意此处的0x00)
后续的默认值不变,还是整个数组的前面有效16字节位作为有效的拓展username。
(B)用于追踪的正确的username和userkey对。
拿到一对正确的username和userkey不难,我们先不管username,利用样例验证解密过程,我们可以从任意提供的userkey解密得到对应的username。
这里我们取userkey,K=A0A1A2A3A4A5A6A7A8A9AAABACADAEAF
在上述x64dbg调试器中,我们在pop ebp断下,再次观察userkey的内存位置,就得到百分百正确的D或U,即我们对应的username,为
U or D = 7B E6 79 E0 89 E3 D3 6B 83 ED 81 EB 7A EA 5A 0A
(为何不使用我们的F5伪码呢?编译器都不一定保证源码的百分比正确,反编译也一样,毕竟都是编译器,只是src源和dst目标不一样)
我们需要用百分百正确的username和userkey修整或修正我们的F5伪码,保证其业务逻辑的等效。
(C)从D或U到K的逆向逻辑
基于下述K(userkey)和D(username)的逆向还原测试,
逆向的逻辑需要从D得到K,而我们还原的C代码是由K得到D,但两个过程的中间观察量是一致的。
即无论是正向还是反向,上述修正代码中的关键观察量应该产生一样的结果,这就是我们逆向业务逻辑的参照标准。
核心观察量有,x6587,Ks,wS,wX,wA,wT1,wT3,wST,wR
K:A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 AA AB AC AD AE AF
D:7B E6 79 E0 89 E3 D3 6B 83 ED 81 EB 7A EA 5A 0A
从F5源码分析上,可以清楚知道,从D或U到K的逆向过程,可以先从D或U得到 x6587,Ks,wS,wX,wA,wT1,wT3,wST,wR这些关键观察量,然后再计算得到K,就简单许多。
(D)关键观察量突破口,x6587和Ks
参考下述代码
x6587 = K65^K87; wTX=wT1^K65; Kr1=__ROL2__(wTX,Ks); Kr2=__ROL2__(wT1^K87,Ks); *(_WORD*)(a2+0xC)=Kr2; //Udc or Ddc *(_WORD*)(a2+0xE)=Kr1; //Ufe or Dfe
因为 Kr1^Kr2=Ufe^Udc=__ROL2__(wTX,Ks) ^ __ROL2__(wT1^K87,Ks); =__ROL2__(wTX ^ wT1 ^ K87,Ks) =__ROL2__(wT1 ^ K65 ^ wT1 ^ K87,Ks) =__ROL2__(K65 ^ K87,Ks) =__ROL2__(x6587,Ks) 定义 An = Kr1^Kr2= = Ufe ^ Udc 即 An = x6587 <<< Ks //可以直接由D或U的 Ufe ^ Udc 计算得到 那么如何由An得到x6587和Ks呢?
又因为
A53=(unsigned __int16)((((x6587&0x5555)+(((unsigned __int16)x6587>>1)&0x5555))&0x3333)
+(((unsigned __int16)((x6587&0x5555)
+(((unsigned __int16)x6587>>1)&0x5555))>>2)&0x3333));
Ks=((unsigned __int16)((A53&0xF0F)+((A53>>4)&0xF0F))>>8)
+(unsigned __int8)((A53&0xF)+((A53>>4)&0xF));
其中A53由x6587计算得到,我们不需要关注细节
而Ks实际是计算A53 类型是双字节0x****四个“Half-Byte"的和,作为循环左移的次数。
实际也不需关注细节,因为双字节循环左移的结果只有16种,我们简单枚举下,就可以由An得到x6587和Ks
An = c_ushort(Ufe ^ Udc)
x6587 = c_ushort(0)
A53 = c_ushort(0)
_Ks = None
for Ks in range(0x10):# x6587<<Ks | x6587 >> (16-Ks) An=x6587 <<< Ks --> x6587=An >>> Ks
x6587.value = ((An.value >> Ks)|(An.value << (16-Ks)))&0xFFFF
A53.value=((((x6587.value&0x5555)+((x6587.value>>1)&0x5555))&0x3333)+((((x6587.value&0x5555)+((x6587.value>>1)&0x5555))>>2)&0x3333))&0xFFFF;
cKs = (((A53.value&0xF0F)+((A53.value>>4)&0xF0F))>>8)+((A53.value&0xF)+((A53.value>>4)&0xF))
if cKs==Ks:
_Ks = Ks
_x6587 = x6587
print("x6587=0x{:04X};Ks={} from D-to-K python".format(x6587.value,Ks))
Ks = _Ks
x6587 = _x6587.value其余关键观察量,
主要利用D或U直接的加减和异或计算中间观察量: 因为, *(_WORD*)(a2+0x0)=K43^wR; //U10 or D10 *(_WORD*)(a2+0x2)=K21^wR; //U32 or D32 *(_WORD*)(a2+0x4)=wST+K0f; //U54 or D54 *(_WORD*)(a2+0x6)=Ked-wST; //U76 or D76 *(_WORD*)(a2+0x8)=wT3+Kcb; //U98 or D98 *(_WORD*)(a2+0xA)=wT3+Ka9; //Uba or Dba 又因为, wS=(unsigned __int16)(Kcb-Ka9); wX=(K21^K43)&0xFFFF; wA=(K0f+Ked); 所以, wS=U98-Uba //=(wT3+Kcb)-(wT3+Ka9)=Kcb-Ka9 wX=U32^U10 //=(K21^wR)^(K43^wR) = K21^K43 wA=U54+U76 //=(wST+K0f)+(Ked-wST) = K0f+Ked wT1=(wS&~wX|wX&wA)
继续有 wT3=(((wX*wT1)>>Ks)+24)&0xFFFF wST=wS^wT3 wR=(wT1&wT3)|(wST&(wT1|wT3)) Kr1=Ufe Kr2=Udc wTX=((Kr1 >> Ks)|(Kr1 << (16-Ks)))&0xFFFF
有了中间观察量,由观察量到K就简单多了 K65=wTX^wT1 #ok K87=x6587^K65 #ok K21=U32^wR #ok K43=U10^wR #ok Ked=(U76+wST)&0xFFFF #ok K0f=c_ushort(U54-wST).value Ka9=c_ushort(Uba-wT3).value Kcb=c_ushort(U98-wT3).value
下述是完整从python逆向逻辑测试代码,附件的keygen.py用于作为注册机
from ctypes import *
import struct
#D=7B E6 79 E0 89 E3 D3 6B 83 ED 81 EB 7A EA 5A 0A
Ufe=0x0a5A
Udc=0xEA7A
U98=0xed83
Uba=0xeb81
U32=0xe079
U10=0xe67b
U54=0xe389
U76=0x6bd3
An = c_ushort(Ufe ^ Udc)
x6587 = c_ushort(0)
A53 = c_ushort(0)
_Ks = None
for Ks in range(0x10):# x6587<<Ks | x6587 >> (16-Ks) An=x6587 <<< Ks --> x6587=An >>> Ks
x6587.value = ((An.value >> Ks)|(An.value << (16-Ks)))&0xFFFF
A53.value=((((x6587.value&0x5555)+((x6587.value>>1)&0x5555))&0x3333)+((((x6587.value&0x5555)+((x6587.value>>1)&0x5555))>>2)&0x3333))&0xFFFF;
cKs = (((A53.value&0xF0F)+((A53.value>>4)&0xF0F))>>8)+((A53.value&0xF)+((A53.value>>4)&0xF))
if cKs==Ks:
_Ks = Ks
_x6587 = x6587
print("x6587=0x{:04X};Ks={} from D-to-K python".format(x6587.value,Ks))
Ks = _Ks
x6587 = _x6587.value
#---check ok---
#x6587=0x8080;Ks=2
#x6587=0x0E02;Ks=4
wS=U98-Uba
wX=U32^U10
wA=U54+U76
wT1=(wS&~wX|wX&wA)
print("wS:{:X}\twX:{:X}\twA:{:X}\twT1:{:X} from D-to-K python\n".format(wS,wX,wA,wT1))
#wS:202 wX:602 wA:14F5C wT1:600
#wS:202 wX:602 wA:FFFF4F5C wT1:600
#---check ok---
wT3=(((wX*wT1)>>Ks)+24)&0xFFFF
wST=wS^wT3
wR=(wT1&wT3)|(wST&(wT1|wT3))
print("wT3:{:X}\twST:{:X}\twR:{:X} from D-to-K python\n".format(wT3,wST,wR))
#wT3:40D8 wST:42DA wR:42D8
#wT3:40D8 wST:42DA wR:42D8
#---check ok---
Kr1=Ufe
Kr2=Udc
wTX=((Kr1 >> Ks)|(Kr1 << (16-Ks)))&0xFFFF
print("wTX:{:X}\tKr1:{:X}\tKr2:{:X} from D-to-K python\n".format(wTX,Kr1,Kr2))
#wTX:FFFFA0A5 Kr1:A5A Kr2:FFFFEA7A
#wTX:A0A5 Kr1:A5A Kr2:EA7A
#---check ok---
K65=wTX^wT1 #ok
K87=x6587^K65 #ok
K21=U32^wR #ok
K43=U10^wR #ok
Ked=(U76+wST)&0xFFFF #ok
K0f=c_ushort(U54-wST).value
Ka9=c_ushort(Uba-wT3).value
Kcb=c_ushort(U98-wT3).value
struct.pack("HHHHHHHH",K21,K43,K65,K87,Ka9,Kcb,Ked,K0f).encode('hex').upper()
得到 K='A1A2A3A4A5A6E466A9AAABACADAEAFA0',即对应我们的参考
userkey=A0A1A2A3A4A5A6A7A8A9AAABACADAEAF (注意其中的A0位置)
通过C和python两个正反过程验证了我们的K-D后,
我们就可以得到任意D或U对应的K
#D: 4B 43 54 46 00 1A 19 18 17 16 15 14 13 12 11 10 U10=0x434B U32=0x4654 U54=0x1A00 U76=0x1819 U98=0x1617 Uba=0x1415 Udc=0x1213 Ufe=0x1011 替换D,运行上述python得到 K:=CDE9D2EC1D469DC67C647E66B4C5656C 则userkey为置换K最后一字节到开头得到 6CCDE9D2EC1D469DC67C647E66B4C565
八、附件等内容
C 直接编译: del decryptTest.exe & cl decryptTest.c & decryptTest.exe
python 直接执行: python keygen.py KCTF 得到 x6587=0x8080;Ks=2 from D-to-K python wS:202 wX:51F wA:3219 wT1:219 from D-to-K python wT3:AF99 wST:AD9B wR:AF99 from D-to-K python wTX:4404 Kr1:1011 Kr2:1213 from D-to-K python username:KCTF userkey :6CCDE9D2EC1D469DC67C647E66B4C565
最后于 4小时前 被HHHso编辑 ,原因:
如有侵权请联系:admin#unsafe.sh