基本信息
原文名称 Free Lunch for Testing: Fuzzing Deep-Learning Libraries from Open Source
原文作者 Anjiang Wei; Yinlin Deng; Chenyuan Yang; Lingming Zhang
原文链接 Free Lunch for Testing: Fuzzing
Deep-Learning Libraries from Open Source | IEEE Conference Publication | IEEE Xplore
发表期刊 2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE)
开源代码 https://github.com/ise-uiuc/FreeFuzz
一、背景
(一)存在的挑战
运行和测试深度学习模型都不可避免地涉及到底层的深度学习库,这些库是构建、训练、优化和部署深度学习模型的基础设施的核心部分。目前为止,大量的研究工作都致力于测试DL(Deep Learning)模型,用于测试底层DL库的工作仍然有限。面临着以下挑战:
01
DL库中实现了数百甚至数千个API来支持各种任务,为每个API手动构造测试输入几乎是不可能的。
02
来自DL库的大多数公共API使用Python,而Python是一种动态类型语言,不能静态地确定输入参数的类型,这使得在给定API定义的情况下自动生成测试输入非常具有挑战性。例如图1中Conv2d运算符,我们不知道in_channels, out_channels等是什么类型的参数;从定义中推断参数padding是一个整数(从默认值padding=0推断),但实际上padding控制应用到输入的填充量,它可以是字符串' valid ',也可以是一个int元组。
图1 Conv2d运算符定义
03
与传统软件相比,因DL库的特殊性,DL库的测试存在着测试oracle问题,目前对DL库的测试使用不一致性度量作为测试的近似oracle。
(二)现有的方法
由于上述DL库测试生成的挑战,CRADLE提出直接利用现有的DL模型来测试DL库。通过在不同的后端执行相同的DL模型时检查实现的不一致性,以检测DL库的错误。检测到不一致之后,启动确认过程来揭示错误的不一致,并启动一个定位过程以精确定位不一致的来源。
LEMON在CRADLE的基础上通过提出模型级突变来改进DL库的测试。设计了一组模型级突变规则来生成突变模型,目的是调用更多的库代码。
缺陷:在这样的模型级测试中,DL模型作为测试输入是有限的,只能覆盖DL库中有限范围的API;相当低效,每一个模型都需要完全端到端执行,以获得预测结果;模型级突变的突变规则有严格的约束,例如层添加方法中,要插入的API的输出形状和它的输入形状必须相同。
图2 现有方法的整体框架
(三)本文的工作
为了克服上述的障碍,本文做出了以下贡献:
01
通过从开源中挖掘来收集测试输入,为DL库的API级模糊化开辟了一个新维度。
02
实现了一个API级的DL库模糊技术FreeFuzz,它利用了三个不同的输入源,包括来自库文档的代码片段、库开发人员测试和野外的DL模型。FreeFuzz跟踪所有输入源的动态API调用信息,还通过差分测试和变形测试解决了测试oracle问题。
03
本文对两个最流行的DL库(PyTorch和TensorFlow)的广泛研究表明,FreeFuzz可以成功地跟踪2530个API中的1158个,并有效地检测出49个错误,其中38个已经被开发人员确认为之前未知的错误,21个已经修复。
二、 方法
如图3所示,Freefuzz首先从实际模型和API文档中挖掘API代码。然后,在运行所有收集的代码时动态记录每个调用API的所有输入参数的动态信息。动态信息包括张量的类型、形状和参数的值。跟踪的信息可以为每个API形成一个值空间,以及一个参数值空间,在测试期间,可以在类似API的参数之间共享值。最后,FreeFuzz利用跟踪的信息基于各种策略执行基于突变的模糊化,并在不同的后端通过差分测试和蜕变测试来检测错误。
图3 FreeFuzz整体概述
(一)代码收集
01 库文档中的代码片段
几乎所有DL库都会提供如何调用API的详细文档,库文档会给出用自然语言编写的详细规范,以详细显示每个API的每个参数的用法。同时,这种基于自然语言的规范通常还附带代码片段。PyTorch中调用2D-Convolution API的示例代码片段如图4所示。但是并非所有API都有示例代码,并且示例代码不能枚举所有可能的参数值。因此,考虑其他来源也很重要。
图4 API文档中的示例代码
02 库开发人员测试
DL库开发人员编写/生成大量的测试,以确保DL库的可靠性和正确性。例如,流行的TensorFlow和PyTorch DL库分别有1493和1420测试来测试Python API,本文简单地运行所有这样的Python测试。
03 开源的DL模型
流行的DL库已被广泛用于训练和部署DL模型,每个模型将在模型训练和推断期间涵盖各种API。本文从Github的流行存储库中获得了102个PyTorch模型和100个TensorFlow模型。这些模型是多样化的,它们涵盖了各种任务,如图像分类、自然语言处理、强化学习、自动驾驶等。
(二)Instrumentation
执行代码工具来收集各种动态执行以生成测试输入。首先,hook API调用,然后执行在第一阶段收集的代码,以跟踪每个API调用的各种动态执行信息。无论怎样调用API(例如,在代码片段、测试或模型中执行),运行时相应的参数信息都会被记录在数据库中,形成值空间,用于模糊化。
01 类型监控工具
Freefuzz为API参数构建了定制的类型监控工具FuzzType。例如,参数stride=(2,1)的类型可以通过运行Fuzztype((2,1))来计算,返回(int,int)。类似的,张量 type(torch.randn(20,16,50,100))在Python的类型系统中简单地返回, 但使用Fuzztype,可以返回 Tensor<4,float32> 。
图5 定制类型监控系统FuzzType
02 API值空间
根据动态跟踪期间传入的API具体值构建每个API的值空间。API值空间的一个条目代表一个API调用及其对应的具体参数列表,将在突变阶段用作起点,以生成更多的突变/测试。
03 参数值空间
由不同的参数名称和类型以及调用不同API时记录的值组成。参数值空间是根据API值空间中收集的信息构造的,基于参数名称聚合来自不同API的值,更具体地说,参数值空间的形成基于这样一种思想,即一个API的参数值可以作为其他类似API的参数的潜在合理值。
(三)基于突变的模糊
根据在第二阶段收集的跟踪信息,有效地为用于目标API的测试输入(即参数列表)生成突变,突变规则由两部分组成:类型突变和值突变。
01 类型突变策略
Tensor Dim Mutation:将n1维张量突变成n2维度张量。
Tensor Dtype Mutation:改变张量的数据类型。
Primitive Mutation:将一种原始类型突变为另一种原始类型。
Tuple Mutation和List Mutation:突变元组或列表中元素的类型。
表1 类型突变策略
02 值突变策略
随机值变异:使用随机值突变。
Random Tensor Shape:使用随机整数作为形状去突变n维张量。
Random Tensor Value:使用随机值初始化张量。
Random Primitive, Random Tuple,Random List:使用随机值对不同类型的参数值进行变异。
数据库值变异:从参数值空间的数据库中选择相应的项进行突变。
Database Tensor Shape,Database Tensor Value:从参数值空间中随机选择相应的形状或值初始化张量。
Database Primitive、Database Tuple、Database List:根据参数名称和类型从参数值空间选取相应的值来初始化参数值。
表2 值突变策略
03 突变算法
输入:要突变的API、API值空间VS和参数值空间DB。
①从VS[API]中采样来启动突变过程。
②计算参数argNum的数量,并随机选择1~argNum之间的一个整数作为需要突变的参数数量,即numMutation。
③然后开始一个内部循环,对numMutation个参数进行突变,以生成一个新的测试。参数通过随机参数索引argIndex选择。在每次确定要改变的参数之后,使用FuzzType获取类型,之后进行类型突变或值突变。突变完成后,FreeFuzz将生成一个新的测试,这个测试将用于测试API。
其中,ValueRule(db)函数是基于参数值空间突变特定API参数值的过程。
①接收API名称、参数类型argType、参数名称argName和数据库DB作为输入。
②然后查询数据库,收集与当前测试API具有相同参数名称和类型的所有API。
③根据API定义之间的Levenshtein Distance计算当前被测试API和每个返回值之间的文本相似性。具体公式如下:
④规范文本相似性,将它们转换为选择相似API的概率。
⑤根据概率选择相似度高的API,并记录该API的值,通过这种方式,存储在数据库中的API的参数值可以被作为另一个API的参数值。
(四)测试oracle
在对参数进行变异之后,会有一个测试代码生成器生成测试代码。测试通过在不同的DL库后端和硬件上进行差分测试和蜕变测试来解决测试oracle问题并检测潜在的DL库bug。
Wrong-Computation Bugs。通过在三种模式来运行每个AP:CPU、禁用CuDNN的GPU和启用CuDNN的GPU,比较结果的不同来发现错误的计算结果。
Performance bugs。在同一台机器上,具有相同函数参数和相同形状张量 tensor的API,在时间成本上具有以下关系,如果数据类型精度越大,那么时间成本消耗也就越大。如果违背了这个关系就认为发生了错误。
Crash Bugs。如果一个API崩溃或抛出运行时异常,那么它可能被认为是一个Crash bug。
三、 实验设计及结果
(一)研究问题
01
FreeFuzz的三个不同的输入源对DL库测试的有效性?
02
为每个API执行不同数量的突变对于DL库测试的影响?
03
不同的突变策略如何影响FreeFuzz的性能?
04
与之前工作的比较?
05
FreeFuzz能检测到现实世界中的bug吗?
(二)实验设置
实验主要是在DL库的稳定发布版本上进行的:PyTorch 1.8和TensorFlow 2.4。采用的评价指标为:覆盖的API的数量、API值空间大小(每个API调用都可以向API值空间中添加一个条目)、行覆盖率(Python API调用的C/ c++代码的覆盖率)、发现的bug数。
(三)具体实验
01 实验一:验证三个不同的输入源对DL库测试的有效性
实验结果如表3所示,包括只使用文档、只使用测试、只使用模型,以及同时使用TensorFlow和PyTorch的所有信息。将所有三个信息源放在一起,在API覆盖率、API值空间大小、行覆盖率方面都能比使用任何单一信息源获得更好的结果。
表3 关于不同来源的统计数据
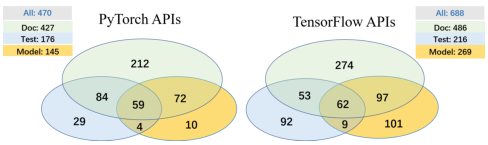
图6、图7结果表示,每个输入源都专门覆盖了一些API,只有一小部分API被所有三个信息源覆盖;每个输入源专门覆盖不同的代码部分,但覆盖的大部分代码往往由所有三个输入源共享。原因是不同的API实现不同的代码逻辑,但它们可以被分解为一组用C/ c++实现的通用底层操作符。总的来说,实验结果进一步证实了考虑不同的信息源对有效的DL库测试是必要和重要的。
图6 覆盖API的韦恩图
图7 用于代码覆盖的韦恩图
02 实验二:验证对每个API执行不同数量的突变对于DL库测试的影响
实验结果如图8,其中x轴表示为每个API生成的突变体数量,而y轴表示通过为每个API生成不同数量的突变体而实现的行覆盖率。在为每个API运行600个突变后,覆盖率在很大程度上变得稳定,这表明在实践中,600个突变是一个具有成本效益的选择。同时,为每个测试中的API启用更多的突变,确实可以覆盖更多的代码行,展示了突变策略的整体有效性。
图8 PyTorch覆盖率趋势分析
03 实验三:测试不同的突变策略如何影响FreeFuzz的性能
该实验通过禁用每种突变策略来进一步研究每种突变策略的影响。实验有三个变体,FreeFuzz- typemu(禁用类型突变策略),FreeFuzz- randmu(禁用随机值突变策略),FreeFuzz- dbmu(禁用数据库值突变策略)。
图8、图9结果表明,默认的FreeFuzz行覆盖率优于所有其他变体,其次,随机值和数据库值突变策略在代码覆盖方面表现相似,而类型突变甚至更有效,因为不同类型的底层实现往往更不同。
图9 TensorFlow覆盖率趋势分析
04 实验四:与之前工作的比较
该实验将FreeFuzz与最先进的LEMON和CRADLE工作进行比较。实验首先根据覆盖API的数量和覆盖率来比较它们的输入来源。为了与之前的工作进行公平的比较,强制FreeFuzz使用来自LEMON的完全相同的模型作为DL模型输入源,而另外两个输入源为TensorFlow v1.14的开发人员测试和文档代码。LEMON和CRADLE只是运行它们的原始工作中使用的DL模型。表4的结果表示FreeFuzz使用的输入源可以实现比LEMON和CRADLE更高的API和代码覆盖率。
表4 输入覆盖率比较
表5比较了FreeFuzz与LEMON使用的突变策略有效性。对于默认设置的FreeFuzz,可以覆盖比LEMON多约9倍的API,而消耗的时间比LEMON少约3.5倍,代码覆盖率也得到了提升。仅使用模型输入源的FreeFuzz,虽然LEMON比它多覆盖5个API,但是FreeFuzz花费的时间却比LEMON快75倍,这进一步证明了API级测试与模型级测试相比性能得到了很大的提升。
表5 与LEMON在突变策略的比较
05 实验五:真实世界bug的检测
由表6知,FreeFuzz对于两个研究的DL库总共能够检测出49个错误(其中38个已经确认为之前未知的错误),其中21个已经被开发人员修复。此外,每个突变策略都可以帮助检测到其他突变策略无法检测到的某些bug,证明了FreeFuzz所有突变策略的重要性。
表6 真实世界检测到的bug
图10显示了FreeFuzz通过比较两个后端二维卷积的计算结果,启用CuDNN和禁用CuDNN的输出结果具有显著差异,最后抛出了断言错误。进一步比较CPU执行的计算结果表明,只有在禁用CuDNN的GPU上,计算结果是错误的。这是一个被开发人员确认的错误,并在最新版中修复。
图10 二维卷积的差分测试
图11显示了崩溃错误。当调用三维卷积时,程序因为padding_mode参数被设置为' reflect’而崩溃。错误是由数据库突变策略触发的,freefuzz从参数值空间选择' reflect '作为Conv3d参数padding_mode的输入。最后开发人员确定了三维卷积中padding_mode参数值中' reflect '是可用的。
图11 Conv3d中的crash bug
四、 局限
01
只专注于测试单个API的正确性,仍然可能错过只有调用一系列API才能触发的错误。
02
只是进行随机的种子选择和突变,没有一定的引导机制。
03
给定完全相同版本的库API,有些测试会在一台机器上失败,但会在另一台机器上通过。会受到底层基础设施和硬件不同的影响。
04
由于一些复杂的输入约束,FreeFuzz仍然不能总是生成有效的输入。
五、 总结
本文提出了FreeFuzz,这是第一个通过从开源中挖掘来模糊DL库的方法。更具体地说,FreeFuzz考虑了三个不同的来源:库文档、开发人员测试、野外的DL模型。然后,FreeFuzz自动运行所有收集的代码/模型,并使用工具跟踪每个覆盖API的动态信息。最后,FreeFuzz将利用跟踪的动态信息为每个覆盖的API执行模糊测试。在PyTorch和TensorFlow上对FreeFuzz的广泛研究表明,FreeFuzz能够自动跟踪1158个API的有效动态信息,比最先进的LEMON多9倍,开销降低3.5倍。
如有侵权请联系:admin#unsafe.sh