Loading...

12 min read

It's a never-ending effort to improve the performance of our infrastructure. As part of that quest, we wanted to squeeze as much network oomph as possible from our virtual machines. Internally for some projects we use Firecracker, which is a KVM-based virtual machine manager (VMM) that runs light-weight “Micro-VM”s. Each Firecracker instance uses a tap device to communicate with a host system. Not knowing much about tap, I had to up my game, however, it wasn't easy — the documentation is messy and spread across the Internet.
Here are the notes that I wish someone had passed me when I started out on this journey!
A tap device is a virtual network interface that looks like an ethernet network card. Instead of having real wires plugged into it, it exposes a nice handy file descriptor to an application willing to send/receive packets. Historically tap devices were mostly used to implement VPN clients. The machine would route traffic towards a tap interface, and a VPN client application would pick them up and process accordingly. For example this is what our Cloudflare WARP Linux client does. Here's how it looks on my laptop:
$ ip link list
...
18: CloudflareWARP: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1280 qdisc mq state UNKNOWN mode DEFAULT group default qlen 500
link/none
$ ip tuntap list
CloudflareWARP: tun multi_queue
More recently tap devices started to be used by virtual machines to enable networking. The VMM (like Qemu, Firecracker, or gVisor) would open the application side of a tap and pass all the packets to the guest VM. The tap network interface would be left for the host kernel to deal with. Typically, a host would behave like a router and firewall, forward or NAT all the packets. This design is somewhat surprising - it's almost reversing the original use case for tap. In the VPN days tap was a traffic destination. With a VM behind, tap looks like a traffic source.
A Linux tap device is a mean creature. It looks trivial — a virtual network interface, with a file descriptor behind it. However, it's surprisingly hard to get it to perform well. The Linux networking stack is optimized for packets handled by a physical network card, not a userspace application. However, over the years the Linux tap interface grew in features and nowadays, it's possible to get good performance out of it. Later I'll explain how to use the Linux tap API in a modern way.

To tun or to tap?
The interface is called "the universal tun/tap" in the kernel. The "tun" variant, accessible via the IFF_TUN flag, looks like a point-to-point link. There are no L2 Ethernet headers. Since most modern networks are Ethernet, this is a bit less intuitive to set up for a novice user. Most importantly, projects like Firecracker and gVisor do expect L2 headers.
"Tap", with the IFF_TAP flag, is the one which has Ethernet headers, and has been getting all the attention lately. If you are like me and always forget which one is which, you can use this AI-generated rhyme (check out WorkersAI/LLama) to help to remember:
Tap is like a switch,
Ethernet headers it'll hitch.
Tun is like a tunnel,
VPN connections it'll funnel.
Ethernet headers it won't hold,
Tap uses, tun does not, we're told.
Listing devices
Tun/tap devices are natively supported by iproute2 tooling. Typically, one creates a device with ip tuntap add and lists it with ip tuntap list:
$ sudo ip tuntap add mode tap user marek group marek name tap0
$ ip tuntap list
tap0: tap persist user 1000 group 1000Alternatively, it's possible to look for the /sys/devices/virtual/net/<ifr_name>/tun_flags files.
Tap device setup
To open or create a new device, you first need to open /dev/net/tun which is called a "clone device":
/* First, whatever you do, the device /dev/net/tun must be
* opened read/write. That device is also called the clone
* device, because it's used as a starting point for the
* creation of any tun/tap virtual interface. */
char *clone_dev_name = "/dev/net/tun";
int tap_fd = open(clone_dev_name, O_RDWR | O_CLOEXEC);
if (tap_fd < 0) {
error(-1, errno, "open(%s)", clone_dev_name);
}With the clone device file descriptor we can now instantiate a specific tap device by name:
struct ifreq ifr = {};
strncpy(ifr.ifr_name, tap_name, IFNAMSIZ);
ifr.ifr_flags = IFF_TAP | IFF_NO_PI | IFF_VNET_HDR;
int r = ioctl(tap_fd, TUNSETIFF, &ifr);
if (r != 0) {
error(-1, errno, "ioctl(TUNSETIFF)");
}If ifr_name is empty or with a name that doesn't exist, a new tap device is created. Otherwise, an existing device is opened. When opening existing devices, flags like IFF_MULTI_QUEUE must match with the way the device was created, or EINVAL is returned. It's a good idea to try to reopen the device with flipped multi queue setting on EINVAL error.
The ifr_flags can have the following bits set:
IFF_TAP / IFF_TUN | Already discussed. |
IFF_NO_CARRIER | Holding an open tap device file descriptor sets the Ethernet interface CARRIER flag up. In some cases it might be desired to delay that until a TUNSETCARRIER call. |
IFF_NO_PI | Historically each packet on tap had a "struct tun_pi" 4 byte prefix. There are now better alternatives and this option disables this prefix. |
IFF_TUN_EXCL | Ensures a new device is created. Returns EBUSY if the device exists |
IFF_VNET_HDR | Prepend "struct virtio_net_hdr" before the RX and TX packets, should be followed by setsockopt(TUNSETVNETHDRSZ). |
IFF_MULTI_QUEUE | Use multi queue tap, see below. |
IFF_NAPI / IFF_NAPI_FRAGS | See below. |
You almost always want IFF_TAP, IFF_NO_PI, IFF_VNET_HDR flags and perhaps sometimes IFF_MULTI_QUEUE.
The curious IFF_NAPI
Judging by the original patchset introducing IFF_NAPI and IFF_NAPI_FRAGS, these flags were introduced to increase code coverage of syzkaller. However, later work indicates there were performance benefits when doing XDP on tap. IFF_NAPI enables a dedicated NAPI instance for packets written from an application into a tap. Besides allowing XDP, it also allows packets to be batched and GRO-ed. Otherwise, a backlog NAPI is used.
A note on buffer sizes
Internally, a tap device is just a pair of packet queues. It's exposed as a network interface towards the host, and a file descriptor, a character device, towards the application. The queue in the direction of application (tap TX queue) is of size txqueuelen packets, controlled by an interface parameter:
$ ip link set dev tap0 txqueuelen 1000
$ ip -s link show dev tap0
26: tap0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 ... qlen 1000
RX: bytes packets errors dropped missed mcast
0 0 0 0 0 0
TX: bytes packets errors dropped carrier collsns
266 3 0 66 0 0
In "ip link" statistics the column "TX dropped" indicates the tap application was too slow and the queue space exhausted.
In the other direction - interface RX queue - from application towards the host, the queue size limit is measured in bytes and controlled by the TUNSETSNDBUF ioctl. The qemu comment discusses this setting, however it's not easy to cause this queue to overflow. See this discussion for details.
vnethdr size
After the device is opened, a typical scenario is to set up VNET_HDR size and offloads. Typically the VNETHDRSZ should be set to 12:
len = 12;
r = ioctl(tap_fd, TUNSETVNETHDRSZ, &(int){len});
if (r != 0) {
error(-1, errno, "ioctl(TUNSETVNETHDRSZ)");
}Sensible values are {10, 12, 20}, which are derived from virtio spec. 12 bytes makes room for the following header (little endian):
struct virtio_net_hdr_v1 {
#define VIRTIO_NET_HDR_F_NEEDS_CSUM 1 /* Use csum_start, csum_offset */
#define VIRTIO_NET_HDR_F_DATA_VALID 2 /* Csum is valid */
u8 flags;
#define VIRTIO_NET_HDR_GSO_NONE 0 /* Not a GSO frame */
#define VIRTIO_NET_HDR_GSO_TCPV4 1 /* GSO frame, IPv4 TCP (TSO) */
#define VIRTIO_NET_HDR_GSO_UDP 3 /* GSO frame, IPv4 UDP (UFO) */
#define VIRTIO_NET_HDR_GSO_TCPV6 4 /* GSO frame, IPv6 TCP */
#define VIRTIO_NET_HDR_GSO_UDP_L4 5 /* GSO frame, IPv4& IPv6 UDP (USO) */
#define VIRTIO_NET_HDR_GSO_ECN 0x80 /* TCP has ECN set */
u8 gso_type;
u16 hdr_len; /* Ethernet + IP + tcp/udp hdrs */
u16 gso_size; /* Bytes to append to hdr_len per frame */
u16 csum_start;
u16 csum_offset;
u16 num_buffers;
};
offloads
To enable offloads use the ioctl:
unsigned off_flags = TUN_F_CSUM | TUN_F_TSO4 | TUN_F_TSO6;
int r = ioctl(tap_fd, TUNSETOFFLOAD, off_flags);
if (r != 0) {
error(-1, errno, "ioctl(TUNSETOFFLOAD)");
}
Here are the allowed bit values. They confirm that the userspace application can receive:
TUN_F_CSUM | L4 packet checksum offload |
TUN_F_TSO4 | TCP Segmentation Offload - TSO for IPv4 packets |
TUN_F_TSO6 | TSO for IPv6 packets |
TUN_F_TSO_ECN | TSO with ECN bits |
TUN_F_UFO | UDP Fragmentation offload - UFO packets. Deprecated |
TUN_F_USO4 | UDP Segmentation offload - USO for IPv4 packets |
TUN_F_USO6 | USO for IPv6 packets |
Generally, offloads are extra packet features the tap application can deal with. Details of the offloads used by the sender are set on each packet in the vnethdr prefix.
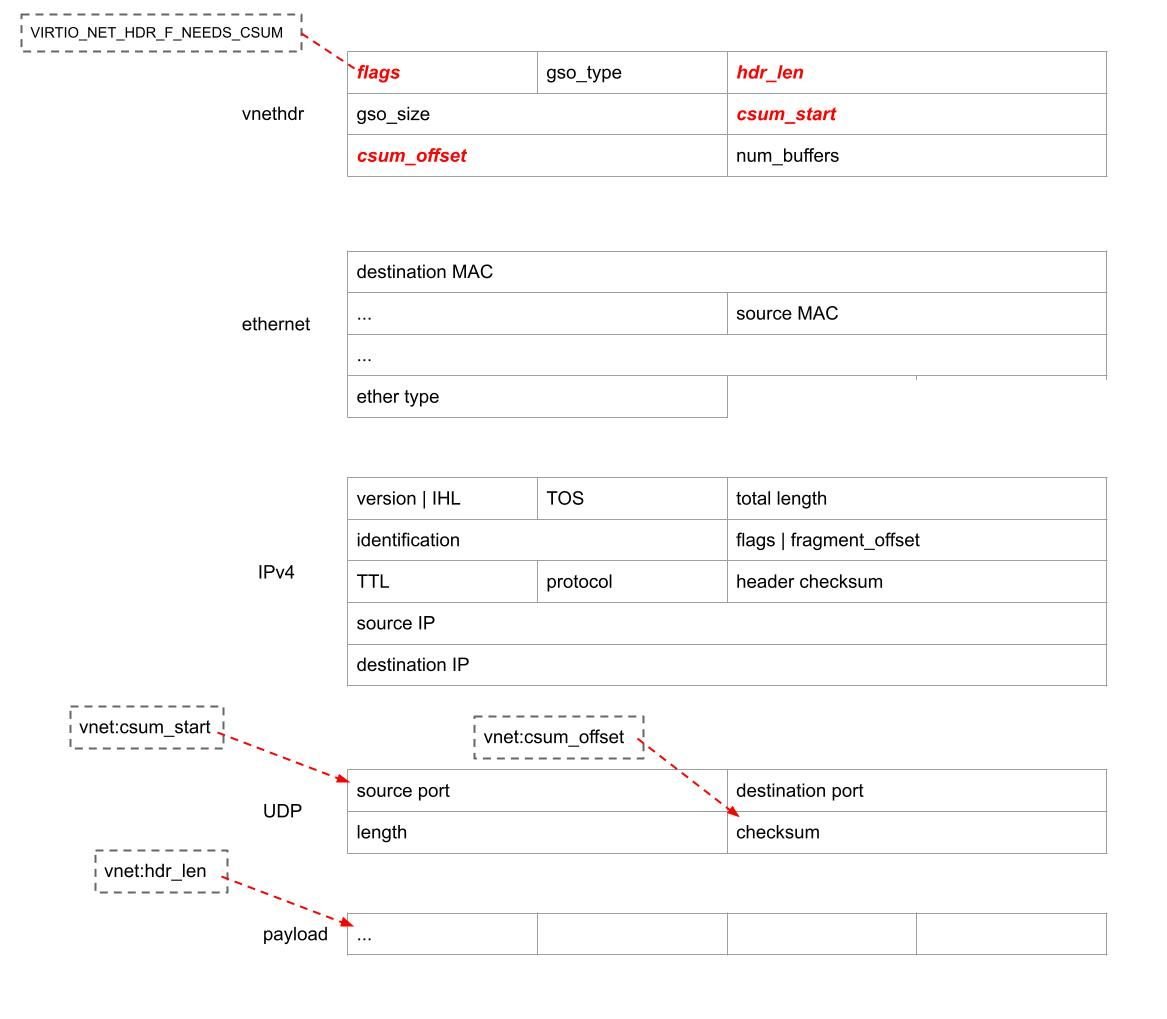
Checksum offload TUN_F_CSUM
Let's start with the checksumming offload. The TUN_F_CSUM offload saves the kernel some work by pushing the checksum processing down the path. Applications which set that flag are indicating they can handle checksum validation. For example with this offload, for UDP IPv4 packet will have:
- vnethdr flags will have VIRTIO_NET_HDR_F_NEEDS_CSUM set
- hdr_len would be 42 (14+20+8)
- csum_start 34 (14+20)
- and csum_offset 6 (UDP header checksum is 6 bytes into L4)
This is illustrated above.
Supporting checksum offload is needed for further offloads.
TUN_F_CSUM is a must
Consider this code:
s = socket(AF_INET, SOCK_DGRAM)
s.setsockopt(SOL_UDP, UDP_SEGMENT, 1400)
s.sendto(b"x", ("10.0.0.2", 5201)) # Would you expect EIO ?
This simple code produces a packet. When directed at a tap device, this code will surprisingly yield an EIO "Input/output error". This weird behavior happens if the tap is opened without TUN_F_CSUM and the application is sending GSO / UDP_SEGMENT frames. Tough luck. It might be considered a kernel bug, and we're thinking about fixing that. However, in the meantime everyone using tap should just set the TUN_F_CSUM bit.
Segmentation offloads
We wrote about UDP_SEGMENT in the past. In short: on Linux an application can handle many packets with a single send/recv, as long as they have identical length.
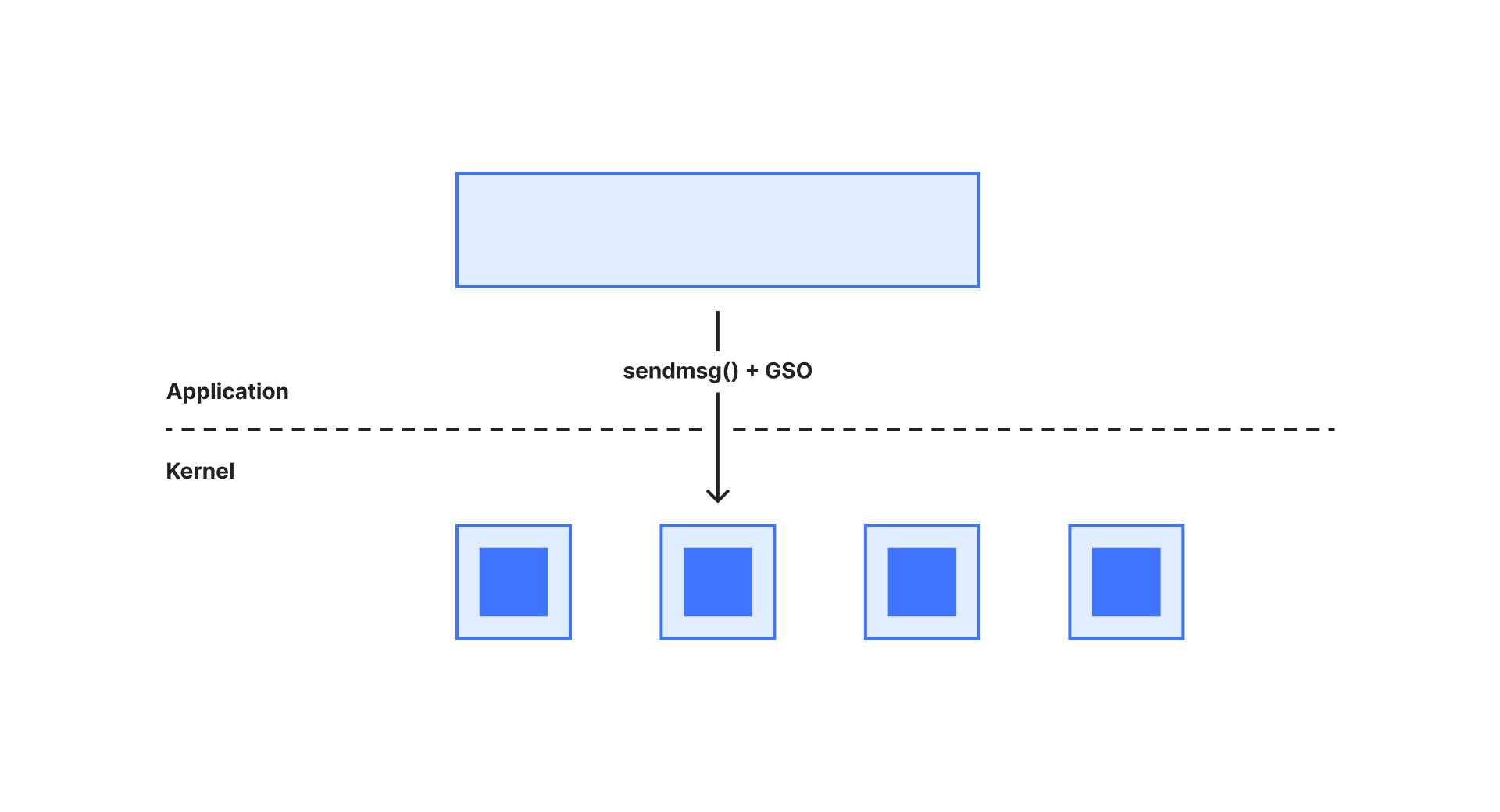
Tap devices support offloading which exposes that very functionality. With TUN_F_TSO4 and TUN_F_TSO6 flags the tap application signals it can deal with long packet trains. Note, that with these features the application must be ready to receive much larger buffers - up to 65507 bytes for IPv4 and 65527 for IPv6.
TSO4/TSO6 flags are enabling long packet trains for TCP and have been supported for a long time. More recently TUN_F_USO4 and TUN_F_USO6 bits were introduced for UDP. When any of these offloads are used, the gso_type contains the relevant offload type and gso_size holds a segment size within the GRO packet train.
TUN_F_UFO is a UDP fragmentation offload which is deprecated.
By setting TUNSETOFFLOAD, the application is telling the kernel which offloads it's able to handle on the read() side of a tap device. If the ioctl(TUNSETOFFLOAD) succeeds, the application can assume the kernel supports the same offloads for packets in the other direction.
Bug in rx-udp-gro-forwarding - TUN_F_USO4
When working with tap and offloads it's useful to inspect ethtool:
$ ethtool -k tap0 | egrep -v fixed
tx-checksumming: on
tx-checksum-ip-generic: on
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: on
tcp-segmentation-offload: on
tx-tcp-segmentation: on
generic-segmentation-offload: on
generic-receive-offload: on
tx-udp-segmentation: on
rx-gro-list: off
rx-udp-gro-forwarding: off
With ethtool we can see the enabled offloads and disable them as needed.
While toying with UDP Segmentation Offload (USO) I've noticed that when packet trains from tap are forwarded to a real network interface, sometimes they seem badly packetized. See the netdev discussion, and the proposed fix. In any case - beware of this bug, and maybe consider doing "ethtool -K tap0 rx-udp-gro-forwarding off".
Miscellaneous setsockopts
TUNGETFEATURES | Return vector of IFF_* constants that the kernel supports. Typically used to detect the host support of: IFF_VNET_HDR, IFF_NAPI and IFF_MULTI_QUEUE. |
TUNSETIFF | Takes "struct ifreq", sets up a tap device, fills in the name if empty. |
TUNGETIFF | Returns a "struct ifreq" containing the device's current name and flags. |
TUNSETPERSIST | Sets TUN_PERSIST flag, if you want the device to remain in the system after the tap_fd is closed. |
TUNSETOWNER, TUNSETGROUP | Set uid and gid that can own the device. |
TUNSETLINK | Set the Ethernet link type for the device. The device must be down. See ARPHRD_* constants. For tap it defaults to ARPHRD_ETHER. |
TUNSETOFFLOAD | As documented above. |
TUNGETSNDBUF, TUNSETSNDBUF | Get/set send buffer. The default is INT_MAX. |
TUNGETVNETHDRSZ, TUNSETVNETHDRSZ | Already discussed. |
TUNSETIFINDEX | Set interface index (ifindex), useful in checkpoint-restore. |
TUNSETCARRIER | Set the carrier state of an interface, as discussed earlier, useful with IFF_NO_CARRIER. |
TUNGETDEVNETNS | Return an fd of a net namespace that the interface belongs to. |
TUNSETTXFILTER | Takes "struct tun_filter" which limits the dst mac addresses that can be delivered to the application. |
TUNATTACHFILTER, TUNDETACHFILTER, TUNGETFILTER | Attach/detach/get classic BPF filter for packets going to application. Takes "struct sock_fprog". |
TUNSETFILTEREBPF | Set an eBPF filter on a tap device. This is independent of the classic BPF above. |
TUNSETQUEUE | Used to set IFF_DETACH_QUEUE and IFF_ATTACH_QUEUE for multiqueue. |
TUNSETSTEERINGEBPF | Set an eBPF program for selecting a specific tap queue, in the direction towards the application. This is useful if you want to ensure some traffic is sticky to a specific application thread. The eBPF program takes "struct __sk_buff" and returns an int. The result queue number is computed from the return value u16 modulo number of queues is the selection. |
Single queue speed
Tap devices are quite weird — they aren't network sockets, nor true files. Their semantics are closest to pipes, and unfortunately the API reflects that. To receive or send a packet from a tap device, the application must do a read() or write() syscall, one packet at a time.
One might think that some sort of syscall batching would help. Sockets have sendmmsg()/recvmmsg(), but that doesn't work on tap file descriptors. The typical alternatives enabling batching are: an old io_submit AIO interface, or modern io_uring. Io_uring added tap support quite recently. However, it turns out syscall batching doesn't really offer that much of an improvement. Maybe in the range of 10%.
The Linux kernel is just not capable of forwarding millions of packets per second for a single flow or on a single CPU. The best possible solution is to scale vertically for elephant flows with TSO/USO (packet trains) offloads, and scale horizontally for multiple concurrent flows with multi queue.
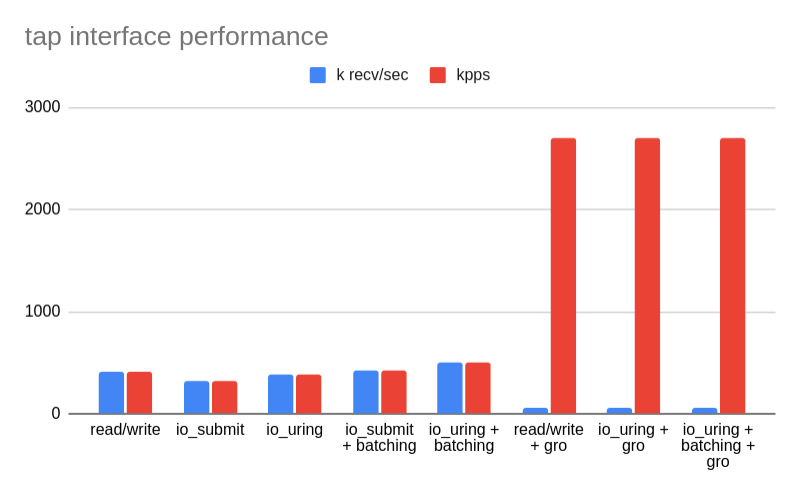
In this chart you can see how dramatic the performance gain of offloads is. Without them, a sample "echo" tap application can process between 320 and 500 thousand packets per second on a single core. MTU being 1500. When the offloads are enabled it jumps to 2.7Mpps, while keeping the number of received "packet trains" to just 56 thousand per second. Of course not every traffic pattern can fully utilize GRO/GSO. However, to get decent performance from tap, and from Linux in general, offloads are absolutely critical.
Multi queue considerations
Multi queue is useful when the tap application is handling multiple concurrent flows and needs to utilize more than one CPU.
To get a file descriptor of a tap queue, just add the IFF_MULTI_QUEUE flag when opening the tap. It's possible to detach/reattach a queue with TUNSETQUEUE and IFF_DETACH_QUEUE/IFF_ATTACH_QUEUE, but I'm unsure when this is useful.
When a multi queue tap is created, it spreads the load across multiple tap queues, each one having a unique file descriptor. Beware of the algorithm selecting the queue though: it might bite you back.
By default, Linux tap driver records a symmetric flow hash of any handled flow in a flow table. It saves on which queue the traffic from the application was transmitted. Then, on the receiving side it follows that selection and sends subsequent packets to that specific queue. For example, if your userspace application is sending some TCP flow over queue #2, then the packets going into the application which are a part of that flow will go to queue #2. This is generally a sensible design as long as the sender is always selecting one specific queue. If the sender changes the TX queue, new packets will immediately shift and packets within one flow might be seen as reordered. Additionally, this queue selection design does not take into account CPU locality and might have minor negative effects on performance for very high throughput applications.
It's possible to override the flow hash based queue selection by using tc multiq qdisc and skbedit queue_mapping filter:
tc qdisc add dev tap0 root handle 1: multiq
tc filter add dev tap0 parent 1: protocol ip prio 1 u32 \
match ip dst 192.168.0.3 \
action skbedit queue_mapping 0
tc is fragile and thus it's not a solution I would recommend. A better way is to customize the queue selection algorithm with a TUNSETSTEERINGEBPF eBPF program. In that case, the flow tracking code is not employed anymore. By smartly using such a steering eBPF program, it's possible to keep the flow processing local to one CPU — useful for best performance.
Summary
Now you know everything I wish I had known when I was setting out on this journey!
To get the best performance, I recommend:
- enable vnethdr
- enable offloads (TSO and USO)
- consider spreading the load across multiple queues and CPUs with multi queue
- consider syscall batching for additional gain of maybe 10%, perhaps try io_uring
- consider customizing the steering algorithm
References:
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.