read file error: read notes: is a directory 2023-11-4 06:34:26 Author: 网络与安全实验室(查看原文) 阅读量:23 收藏
2023.10.30-2023.11.05
每周文章分享
标题: Intelligent Delay-Aware Partial Computing Task Offloading for Multi-user Industrial Internet of Things Through Edge Computing
期刊: IEEE Internet of Things Journal, vol. 10, no. 4, pp. 2954-2966, Feb 2023.
作者: Xiaoheng Deng, Jian Yin, Peiyuan Guan, Neal N. Xiong, Lan Zhang and Shahid Mumtaz.
分享人: 河海大学——邹昕莹
研究背景
工业物联网(IIoT)和工业4.0的发展彻底改变了传统制造业。智能物联网技术通常涉及大量密集型计算任务。资源受限的IIoT设备通常无法满足这些任务的实时要求。作为一种有前途的范式,移动边缘计算(MEC)系统将计算密集型任务从资源受限的IIoT设备迁移到附近的MEC服务器,从而获得更低的延迟和能耗。然而,考虑到变化的信道条件以及各种计算任务的不同延迟要求,在多个用户之间协调计算任务卸载是具有挑战性的。因此,本文面向工业物联网中多用户MEC系统,以最小化系统延迟为目标,提出了一个针对延迟敏感计算任务的自治部分卸载算法,为用户提供更好的服务质量(QoS)。
关键技术
在本文中,提出了一个智能自主部分卸载系统(IAPO ),用于处理多用户IIoT MEC系统中延迟敏感的计算任务。这种计算卸载模型考虑了部分计算卸载的情况,允许在本地和MEC服务器上并行处理计算任务。本文首先提出了一个Q-learning方案。针对部分计算卸载的问题,使用Q-learning算法并根据预定义的比率执行部分计算卸载。然而,随着用户设备(UD)数量的增加,状态空间会急剧增加,而预定义的计算卸载率的增加也将意味着动作空间的增加。此外,人工预定义的计算卸载率不够精细,使得计算任务的并行性无法得到充分利用。因此,本文随后提出了基于深度强化学习(DRL)的的解决方案。具体来说,本文使用深度确定性策略梯度(DDPG)算法,通过DDPG算法中的演员(actor)网络来制定计算卸载策略。Actor网络的输出空间是一个连续的动作空间,意味着任务能以任意比例卸载。Actor网络解决了部分计算卸载的问题。本文在DDPG算法中使用批评家(critic)网络来估计Q值,而不是Q表。Critic网络解决了由于Q表维数大而导致的搜索困难的问题。
该方法的创新和贡献如下:
1)本文为多用户IIoT MEC系统提出了一个具有延迟感知的部分计算任务卸载系统。综合考虑变化的信道条件、多用户之间的各种延迟约束以及有限的无线电和计算资源,将最小化延迟的优化问题公式化,以进行卸载决策。本文建立了一个支持延迟感知的部分计算任务卸载的DRL框架,并详细定义了状态空间、动作空间和奖励函数。
2)为了提供自主有效的卸载决策,提出了两种基于Q-learning算法和DDPG算法的部分计算卸载策略。
算法介绍
一、系统模型
A. 网络模型
图1 网络模型
如图1所示,系统由一个基站,N个用户设备(UD)和一个与基站部署在一起的边缘计算服务器组成。UD可以感知工业4.0场景中的生产环境,每个UD有一个基于人工智能的计算密集型任务需要被计算。由于UD存在计算资源上的限制,因此可以将任务卸载至边缘服务器以辅助计算。本文假设任务的优先级相同,当任务同时卸载时,无线带宽资源将均匀分配给每个上传任务UD。
B. 计算任务模型
计算任务被定义为R_n,包括R_n的数据量D_n,完成R_n所需的CPU周期数C_n和最大可容忍延迟t_n,t_n表示完成R_n的时间不应大于t_n。每个UD任务的三个参数可能不同并且可以通过应用程序的相关配置文件进行估计。UD的任务能以任意比例进行卸载,卸载比例表示为:θ_n∈[0,1]。
C. 本地计算模型
当UD在本地执行部分或全部任务时,任务完成过程完全使用本地计算资源,与MEC服务器无关。
D. 边缘计算模型
计算任务可以卸载到MEC服务器上进行计算,以节省物联网设备的能耗,提高用户的QoS。由于任务计算结果的数据量比初始计算任务的数据量小得多,并且下行链路的传输速率比上行链路的传输速率高得多,所以可以忽略计算结果的下行传输延迟。因此,MEC服务器上计算任务的总计算卸载延迟包任务传输延迟和在MEC服务器上的计算延迟。
二、优化问题
本文的优化目标是最小化IIoT系统的长期总延迟。由于任务R_n的并行性,UD_n执行部分计算卸载策略的总时间延迟应是任务R_n进行部分本地计算和部分边缘计算中较大的时间延迟。该优化问题的约束条件包括:1)卸载百分比之和不超过1;2)MEC服务器分配的计算资源不超过其总计算资源;3)MEC服务器分配给所有卸载任务的计算资源总量不应超过其计算资源总量;4)每个任务的完成时间不应超过最大可容忍延迟。
三、DRL框架
1)状态空间
理论上应考虑包括用户数量,任务情况,MEC服务器的计算资源等因素,但事实上,当用户数量增加,会引起越来越多额外的系统开销,考虑到本文系统目标为整个系统的总时延,因此定义状态空间为:
2)动作空间
每个用户的动作空间为:θ_n∈[0,1],表示任务可以以任意比例卸载。因此,计算卸载向量A=[θ_1, θ_2, ..., θ_n],表示N个用户的卸载决策。
3)奖励函数
系统奖励和系统时延成反比,系统奖励函数定义为:
(4)Q-learning算法
Q-learning算法包含Q函数对应于状态对和动作对。Q函数表示在状态S和动作a的情况下可以获得的长期奖励的估计。然后Q-learning算法使用Q函数选择长期奖励最大的最佳策略。Q函数的计算方法为:
其中,s’表示在状态s中采取行动a时所达到的状态,α为学习率,γ为未来奖励的折扣因子,其中,0≤γ≤1,γ表示未来奖励的重要性。为了运用Q-learning算法,对于状态空间,将状态四舍五入为一个整数。对于动作空间,预定义了L + 1离散部分计算卸载比。
UD_n的计算卸载策略表示为θ_n∈{0,1/L,2/L,...,L/L}。L的大小可以调整,通常更大的L会产生更好的计算卸载策略,但代价是更高的复杂度。每个UD都有自己的动作空间,所以在Q函数中添加一个用户数的维数,它由Q(S,N,L+1)表示。对于IIoT系统的Q函数的计算方法,本文改进了Q函数的计算公式,如下所示:
在上述公式中,Q(s,i,θ_i)表示当IIoT 系统处于s状态时,第i个UDi采用θ_i计算卸载策略时可以获得的长期未来奖励的估计。由于Q表要求其索引是一个非负整数,所以θ_i在Q函数中乘以L。值得注意的是,公式中的s’是IIoT系统中所有UD都采用计算卸载策略A后的状态,其中A包含此时第i个UD的计算卸载策略。也就是说,IIoT系统的所有UD在执行计算卸载策略A后都具有相同的状态s’。
(5)DDPG算法
虽然本文使用Q-learning算法,通过预定义的离散部分计算卸载率来实现部分计算卸载策略。然而,Q-learning算法使用一个Q表来存储所有的Q值。随着IIoT系统中UD数量的增加和预定义的离散部分计算卸载比的增加,Q表将面临维度爆炸的问题。而DDPG算法将DRL动作空间扩展到一个连续域,并使用一个特殊的重放缓冲区容器,该容器存储一定数量的记录,而不是传统的RL算法中的Q表。每个记录由[s_t,a_t,r_t,s_t+1]组成。
图2 基于DDPG算法的MEC计算卸载框架
如图2所示,DDPG算法包含四个深度神经网络(全连接层),包括actor网络、critic网络、目标actor网络和目标critic网络。actor网络负责根据状态选择计算卸载的动作。目标critic网络和目标actor网络使用重放缓冲区对目标Q值进行评估,并由critic网络负责计算Q值。目标Q值的计算方法为:
对于当前网络的参数更新,采用梯度下降算法,使目标Q值与当前网络输出之间的差值最小化。损失函数是一个平方损失函数。损失函数的计算方法由:
其中,M为小批量经验的大小。具体来说,本文使用了Adam 优化器来最小化损失函数。actor网络的策略梯度为:
对于目标网络参数的更新,DDPG算法使用actor网络和critic网络的参数对目标网络进行软目标更新。软目标更新的方法为:
其中,τ为目标网络的软更新速度。参数τ满足0 <τ< 1。τ越小,意味着目标网络参数的更新速度越慢。
本文根据上述描述设计了DDPG算法中的神经网络。Actor网络的输入层维数为1,用于IIoT系统的状态输入,输出层维数为N,表示所有的UD计算卸载策略。由于动作空间的限制,使用sigmoid激活函数来缩放行动者网络的输出。这是因为参与者网络的输出需要满足计算卸载策略,即:
Actor网络的隐藏层由全连接层组成。目标actor网络的结构与actor网络的网络结构相同。Critic网络的输入层由两部分组成,一部分是IIoT系统状态,另一部分是每个UD的计算卸载策略向量。Critic网络输出层的维数为1,表示Q值的预测。Critic网络的隐层由完连接层组成。目标critic网络与critic网络具有相同的结构。
实验分析
一、仿真设置
本文将所提出方案与全本地计算方案(Local computing)、全卸载方案(Full offloading)以及基于DQN算法的计算卸载策略进行了比较。在本文提出的部分计算卸载策略的参数设计中,设置预定义的离散部分计算卸载比L = 3,学习率α = 0.1和折扣因子γ = 0.8。DDPG算法中其他相关参数设置如表1所示。
表1 DDPG算法参数设置
二、算法执行性能
图3 不同UD数量下的总延迟
如图3所示,所有方案的总延迟随着UD数的增加而增加。然而,当用户数量超过5时,Full offloading方案的总延迟最高。这是因为此时所有任务都被卸载到MEC服务器上,而MEC服务器由于计算能力有限,无法满足所有UD的计算要求。此时,MEC服务器的计算能力是影响用户体验质量的主要因素。与其他算法相比,Q-learning算法和DDPG算法具有更低的时延。
图4 MEC服务器不同计算能力下的总时延
如图4所示,由于Local computing与MEC服务器的状态无关,所以Local computing的结果是一条直线,其他方案随着MEC服务器计算能力的增加,系统总时延逐渐减少,因此提高MEC服务器的计算能力有助于提高系统性能。当MEC服务器的计算能力大于7 GHz/s时,系统的总延迟缓慢降低。这是因为此时限制系统总时延的主要因素是传输时延。Q-learning算法和DDPG算法的时延始终低于基线算法。
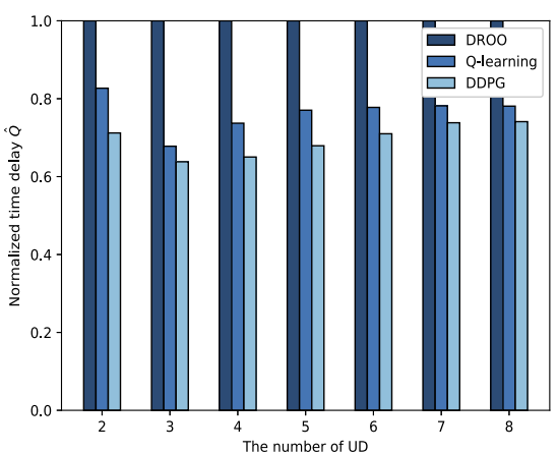
图5 Q-learning算法和DDPG算法的归一化时延
如图5所示,DROO的计算卸载方案的归一化时延是1,这意味着DROO方案可以找到最好的二进制卸载策略。本文提出的部分卸载策略的归一化时延都低于1。其中,Q-learning算法比最佳二进制计算卸载策略低23%,DDPG算法比最佳二进制计算卸载策略低30%。因此,部分计算卸载能更好地减少系统总延时和提高用户体验质量。
三、算法收敛性能
图6 Q-learning算法和DDPG算法的收敛性能
如图6所示,在算法收敛速度方面,基于Q-learning算法的离散计算卸载策略比基于DDPG算法的连续计算卸载策略收敛更快。迭代次数达到60次后,Q学习算法达到稳定状态。Q-learning算法的收敛速度与L的值有关,一般来说,L的值越大,算法收敛速度越慢。基于DDPG算法的计算卸载策略的收敛速度比Q学习算法慢,但DDPG计算卸载策略具有更强的降低IIoT系统总时延的能力,优化程度高于Q-learning算法。
总结
本文研究了工业4.0中时延敏感型多用户工业物联网MEC系统的部分计算任务卸载问题。本文以减少系统的总时间延迟为目标,建立了一个适合部分计算卸载的DRL模型。针对部分计算卸载策略,提出了Q-learning算法和DDPG算法,并将二进制计算卸载方案扩展到连续动作域。仿真实验证明所提出算法能有效降低系统的总时延。在未来的工作中,本文将考虑计算卸载的混合决策问题,以处理MEC中不同类型的计算资源问题,以及考虑在具有服务迁移功能的复杂边缘计算网络环境中IIoT应用的计算卸载问题。
END
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh