原文标题:The Role of Class Information in Model Inversion Attacks against Image Deep Learning Classifier 2023-11-7 14:5:43 Author: 安全学术圈(查看原文) 阅读量:20 收藏
原文标题:The Role of Class Information in Model Inversion Attacks against Image Deep Learning Classifiers
原文作者:Zhiyi Tian, Lei Cui, Chenhan Zhang, Shuaishuai Tan, Shui Yu, Yonghong Tian
发表期刊:IEEE Transactions on Dependable and Secure Computing
原文链接:https://ieeexplore.ieee.org/document/10225397
主题类型:深度学习模型隐私
笔记作者:ZhiyiTian
主编:黄诚@安全学术圈
我们都知道深度学习方法的基本模式是从海量的训练数据集中推导出与任务相关的信息。但是,由于现有的深度学习算法设计的局限,模型在训练过程中可能会记住一些与任务无关的隐私信息。例如,一个用于识别性别的模型可能会记住某些个体的人脸信息。在正常运行的过程中这些被记住的隐私信息是不易被察觉,但是经过多年的研究发现,模型记住的隐私信息是可以被利用而造成隐私泄露的。
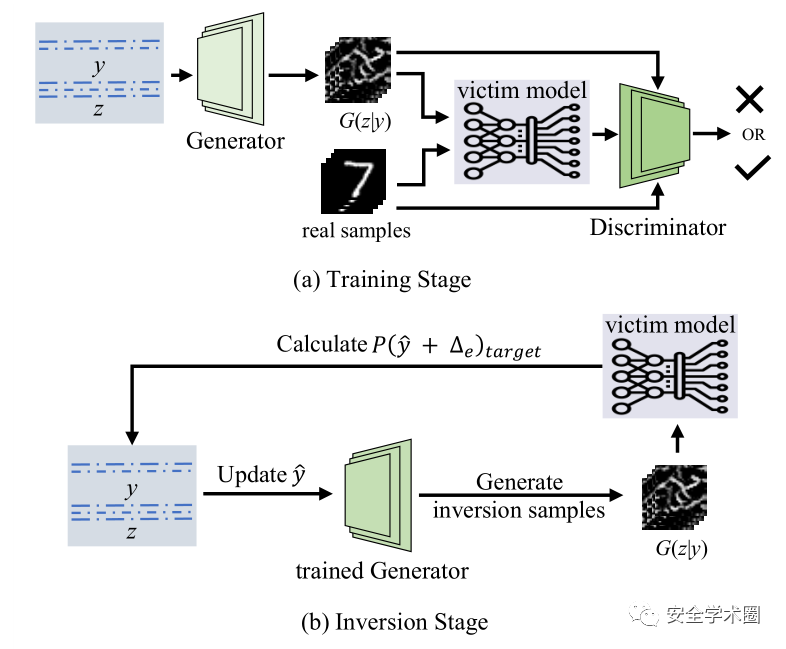
其中,模型反演(model inversion)攻击是深度学习方法所面临最为严峻的隐私挑战。模型反演攻击的目标是利用从训练好的深度学习模型中收集的信息,以及开源渠道收集的辅助信息来重构模型的训练样本以刺探训练样本的隐私。现有的工作大多假设攻击者拥有受害者模型的白盒访问权限,以及一些关于目标样本的先验知识(例如模糊的目标样本)来辅助攻击。但是在真实场景中,大部分模型都是以Machine learning as a service(MLaaS)的形式提供服务的,这使得攻击者只有黑盒访问的能力。
有鉴于此,本文尝试进行黑盒的模型反演攻击。我们观察到受害者模型的输入输出对中包含了充足的隐私信息可以用于协助攻击者重建训练样本。因此,我们首先利用一个与受害者模型训练数据集接近的辅助数据集训练一个cGAN来作为辅助模型。在训练过程中,我们将受害者模型的输出作为cGAN的条件输入以监督辅助模型的训练,这样辅助模型就能够学习到受害者模型对于样本类别的理解。而后我们再通过优化辅助模型的输入以重建训练样本。
作者通过系统性的大规模实验验证了提出的方法的有效性。
我们的研究揭示了深度学习模型输出的隐私漏洞。我们证明受害模型输出中包含的信息足以揭示其训练数据的隐私。攻击者可以仅凭其输出成功地还原受害模型的训练样本。我们还发现,受害模型中包含的隐私信息是通过其预测值的组合泄漏的。而不是某一个类别的置信度泄露的。
我们认为,目前的深度学习方法未能捕获来自训练样本的抽象语义知识,从而导致模型的预测中存在隐私泄漏。模型输出中包含的隐私信息是由于语义相似性在模型输出中引起的预测偏差。当模型性能较差时,它包含的隐私信息也是不准确的。相反,当模型表现出色时,隐私泄漏相对较小。
模型反演攻击已渐渐从实验室中走向真实环境,但是其带来的威胁却没有引起人们足够的重视。在未来,如何防御模型反演攻击是一个非常重要的研究方向。我们认为可以从模型学习到的知识的角度出发,减少模型学习到的与任务无关的隐私信息,同时提升模型学习与任务相关的特征的能力。
最后,欢迎大家来讨论,引用我们的文章,为安全的深度学习的发展贡献我们的力量。联系方式:[email protected]
田智毅,悉尼科技大学博士生,主要研究方向是深度学习的安全与隐私,机器学习在通信中的应用。https://scholar.google.com/citations?hl=zh-TW&user=6N-XUgUAAAAJ
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh