基于LLVM的反混淆框架
摘要
近几年,软件的混淆强度一直在不断提升。基于编译器的混淆已经成为业界事实上的标准,最近的一些论文也表明软件的保护方式使用的是编译器级别的混淆。在这篇文章中,我们会介绍一个基于LLVM的通用的反混淆和混淆代码重编译的方式。我们会展示如何将二进制代码提升为编译器中间语言LLVM-IR,并解释如何使用基于编译器级的优化和可满足性模理论(SMT)的迭代控制流图控制算法[3],将混淆后的二进制函数还原出它的控制流图。这一方法不会对混淆后的代码做任何假设,取而代之的是使用LLVM中的强编译器级优化以及Souper Otimizer来简化混淆。我们的实验结果表明这一方法能有效的简化甚至移除开源的和商业混淆器中常用的混淆技术,如Constant unfolding,基于不透明表达式的certain arithmetic,死代码插入,虚拟控制流或是整数编码。恢复后的LLVM-IR能被进一步地被其他反混淆器处理,这些其他的反混淆器和混淆时使用的技术处于同一级别,或是会被某种LLVM后端编译到与其同一级别。这篇论文最终的成果是一个叫SATURN的反混淆工具(图1)

图1:SATURN反混淆框架的流程图
关键词
逆向工程,llvm,code lifting,混淆,反混淆,静态软件分析,二进制重编译,二进制重写
1. 简介
近些年,我们发现基于中间语言和源码的混淆器变得越来越流行,主要是因为各种目标架构变得越来越多样,尤其是移动市场[11]。传统的基于二进制的混淆方案容易受到基于模式匹配或是简单的静态分析的攻击,而基于中间语言和源代码的混淆则难以被有效地攻击。现代保护工具大多是基于 一些最先进的框架,如LLVM,这种工具支持更复杂的混淆逻辑[11][23]。
在这篇论文中,我们会展示一种基于LLVM代码优化的自动反混淆方式。这篇论文的重点集中在反混淆过程中需要解决的几个问题:将机器码翻译成LLVM-IR;控制流图恢复;不透明谓词检测;反混淆;Brightening(重构代码以使它更具可读性)恢复后的函数以及重编译。
将机器码转为LLVM-IR并不能一步到位。二进制操作码不仅仅会执行操作本身,还会操作条件码、条件标志,它们会影响到后续的分支指令。用于将机器码转为类似LLVM-IR的中间语言的信息往往会在编译时丢失,尤其是在处理混淆后的机器码的时候,这一过程会更难。其中一种解决方案是,将每一条机器码的语义存储到结构体中,然后保存当前寄存器的状态。这是将机器码转为虚拟环境又不需要对代码本身做出一些前提假设的常用方法。恢复后的LLVM-IR很实用,但是可读性非常差。这 篇论文中我们使用了Remil[21][14]来处理这一转化过程。
控制流混淆是一项用于隐藏原始函数的控制流的技术。要将函数反混淆,攻击者必须将混淆后的代码进行恢复。基于LLVM-IR的现代混淆工具能够对控制流图进行重度混淆。我们引入了一种算法,它使用Remill中的State结构体来恢复提升(将机器码转为更高一级的语言,本文中指LLVM-IR,后同)后的基本块的边。这些边和提升后的基本块构成了恢复后的控制流图。在提升(译者注:lifted,意为将机器码转为LLVM-iR)混淆后代码的过程中,控制流图的恢复是自动静态完成的。在控制流图的恢复过程中,相比于前人的方式([13][37][12][35][26]),我们的方法不需要任何机器码相关的先验知识,也不依赖函数追踪。相反,路径的恢复是基于部分反混淆后的基本块以及它们的前驱块。我们的算法和文章[3]“迭代控制流图构建”比较像,不过我们的更高级,算法结果与分支被访问的顺序是无关的。
隐藏控制流图的一种方法是插入不透明谓词(OP,opaque predicates),以使native级控制流图重建算法失效。不透明谓词是指插入到控制流图中用于增加逆向难度的条件分支。不过它的条件总是固定的,因此不会影响到程序的原有逻辑[7]。我们提出了一个检测并移除不透明谓词的方法。该方法基于LLVM和Souer Optimizer优化。对于那些和编译器优化相冲突的不透明谓词,我们使用SMT求解器来处理。用SMT求解器来识别不透明谓词并不新鲜[19],但我们相信把这几个工具和算法结合起来的方式是一种不错的方法。
常量折叠,基于数论的不透明表达式,死代码,虚拟控制流和整数编码不仅仅能在加固后的代码中找到,它也出现在一些未经混淆的代码中。通常而言,在源代码编译阶段,编译器会检测源代码的特征并对它进行优化以获得更高的执行效率。我们提出的方法基于LLVM-IR重构,因此,Remill将机器码提升的方式可能会使我们难以达到最好的效果。重新生成LLVM-IR需要的步骤都是通用的,并不需要任何关于混淆器的先验知识。
如果不进行brightening,LLVM-IR已经够用了,但本文的目标是使提升后的函数能够达到 vanilla(尽可能地达到与混淆和编译前的源码相近)状态。要达到这一状态,我们需要重构原来的函数参数并基于State结构体(代码1)将Remill指定的函数转换一个没有原始签名的LLVM函数。
struct State {
VectorReg vec[kNumVecRegisters];
ArithFlags aflag;
Flags rflag;
Segments seg;
AddressSpace addr;
GPR gpr;
X87Stack st;
MMX mmx;
FPUStatusFlags sw;
XCR0 xcr0;
FPU x87;
SegmentCaches seg_caches;
}
代码1:Remill中x86_64的State结构体
在控制流图恢复后,我们就可以认为这个函数已经被反混淆了,我们提出的方法的其中一个目标是重编译并执行提升后的函数。因为选择将LLVM-IR作为提升后函数的目标语言,所以我们可以使用任意一种LLVM后端(X86,ARM,AArch64,RISC-V以及其他)轻易地将恢复后的代码重新编译成机器码。
实验表明我们的方法可以和当前的一些先进的混淆器相结合,以对抗文章[22]中的反符号反混淆技术。
我们的成果不仅仅可以用于反混淆,事实上这一方法还有一些其他的作用,比如模糊测试,作为动态符号执行(DSE,dynamic symbolic execution)引擎的输入,如KLEE[4],作为基于LLVM的混淆器的输入,如O-LLVM[11],在漏洞利用中实现payload的自动生成[34],或是以最高的CPU优化级别(-march=native)重新编译成机器码以提高程序的性能或是使用有安全保护功能的编译器重新进行编译。上述功能主要是针对那些没有源代码的应用。
1.1 目标和挑战
我们想要现有的应用开发一个基于LLVM及其强优化的反混淆框架。在开始阶段使用LLVM进行逆向似乎过于复杂了,但它和源代码编译的过程很类似。LLVM编译器框架有大量的工具可用于创建并修改控制流图,基本块和指令。真正困难的地方在于将机器码提升为LLVM-IR,并将之重构为未经过编译和混淆的源代码。要达成这一目标,这项技术需要是一门通用,稳定和轻量级的技术。这一框架生成的LLVM-IR需要能够重新被编译和执行。我们希望这一框架生成的LLVM-IR非常易于理解,在LLVM生态系统中,有大量成熟的工具可以对LLVM-IR进行操作。我们的最终目标是将攻击点还原到它实现的地方——编译级。
1.2 贡献
我们的贡献可以总结如下.
- 提出了一个通用的自动化反混淆工具,足以应用多种混淆技术。
- 提出了一个能够重编译并将LLVM-IR注入到给定二进制程序中的框架
- 提出了一个高效识别LLVM-IR级的不透明谓词的方法,然后使用编译器级的优化和SMT求解器处理、验证该方法。
- 提出一个使用Remill又不需要Remill的State结构体,将机器码转为LLVM-IR的通用方法,其中包括栈和函数参数的恢复。
- 我们会证明如何使用我们的框架将诸如文章[22]中的一些反符号执行的手段弱化甚至完全移除,及将之用于源码级的动态符号执行工具。
- 我们提出了一个框架,这个框架可以生成一个模糊约束的简洁表示,使其被更好地解析及检查可满足性。
1.3 讨论
将混淆后的机器码提升为LLVM-IR的过程可以分为好几步。在SATURN中,我们实现了几种算法来处理混淆后的机器码的各种情况。据我们所知,SATURN的实现足够先进,它能将攻击面从混淆后的机器码提升到编译器级别。我们的成果对混淆后的二进制安全也有足够的影响,它使得源码级的或是IR级的动态符号执行工具,如KLEE,能够进一步地对恢复后的代码进行分析。我们列举了几个可能使代码提升失效的小案例,以及将我们的方法用在强混淆的程序中的实例。
2.1 LLVM
LLVM最初是伊得诺大学的一项研究项目,目的是提供一种基于SSA的现代编译方法[33],以使其支持任意语言的动态和静态编译。后来,LLVM逐渐发展为一个由许多子项目组成的大项目,其中许多子项目也被用于各种各样的商业或开源项目,在学术研究中也有了广泛的使用[16]。要理解本文的框架并不需要我们对LLVM及其中间语言LLVM-IR有多深的了解,但你需要知道LLVM-IR是基于静态单赋值(SSA,Single Assignment form)[8]的,这使得它更容易被构造成传给SMT求解器的公式。
2.2 Remill
Remill是一个将机器码转为LLVM bitcode的静态二进制转换器。它支持x86和amd64架构。本文优化了Remill将机器码转换成IR的过程。Remill并不会对栈和提升后的函数参数做任何假设,因为它是基于单指令的。
2.3 Souper优化器
Souper使用起来很方便,因为它是基于LLVM的项目,它使用KLEE将一系列LLVM-IR指令转换为SMT公式,并使用SMT求解器来寻找可行的优化。我们可以使用它的结果来确定条件分支中的不透明谓词。它可以将SMT的查询结果缓存起来,并放入Redis数据库中以提高性能[24]。它会生成一个由不透明谓词和混淆特征组成的数据库,方便我们进一步分析。
2.4 KLEE
KLEE是一个基于LLVM-IR的符号执行工具,它可以自动生成测试用例,并能在一系列复杂的和环境密集型项目上实现高覆盖率。KLEE并不仅仅是一个用于测试软件的工具,它也能用于还原被混淆的代码。文章[22]的工作试图使类似KLEE这样的工具难以达到其预期的效果。
3.1 攻击模型
目标:我们设想的是man-at-the-end(MATE)场景,即攻击者对被保护的应用程序拥有所有的访问权限,但是获取不到源码或是未经保护的应用程序。我们的攻击模型和使用的方法和[28]相似,同时也类似于[22]。具体的说,我们主要关注下述目标:
- 控制流图的恢复。要理解原函数的程序逻辑,还原混淆后的控制流图是一步非常关键的步骤。
- 不透明谓词的检测。只有检测出不透明谓词并移除它后,才能正确地还原控制流图。
- 几种混淆技术的反混淆。要使程序更具可读性,则必须将注入的混淆后的特征代码移除。
- 栈和参数的恢复。如果攻击者能重建栈和参数,那么函数代码会变得非常简洁。
- 恢复后代码的运行。如果攻击者能够执行反混淆后的代码并保证执行效果与未反混淆前一样,那么就能基于此做更多的事,比如使用调试器进行调试。
3.2 分析案例
我们先来介绍几个在文章[22]中提到的小程序,它们使用了反符号执行的面向路径的保护方案。代码2展示了一个没有使用混淆优化的小例子,它使用了文章[22]中提到的FOR和SPLIT来进行反符号执行,并额外加上了不透明谓词来保护条件分支的计算。
intfunc(charchr,charch1,charch2) {
chargarb = 0;charch = 0;
// FOR trickfor(inti = 0; i < chr; i++)
ch++;
// SPLIT trick
if(ch1 > 60)
garb++;
else
garb--;
if(ch2 > 20)
garb++;
else
garb--;
// MBA based opaque predicate
if((chr + ch2) == ((chr ^ ch2) + 2 * (chr & ch2)))
ch ^= 97;
else
ch ^= 23;
return(ch == 31);
}
代码2:基于文章[22]的小程序,使用了反符号执行,面向路径和FOR及SPLIT的保护方案
define dso_local i32 @func(i8 signext) local_unnamed_addr #0 {
%2 =icmp eq i8%0, 126
%3 =zext i1%2to i32
ret i32%3
}
代码3:编译成LLVM-IR的未经保护的小程序
反符号执行的手段不能防御编译器级的优化,因此在编译时使用clang -O3级的优化,可以轻松地将它去掉。不透明谓词对编译器级的优化依然有效,只能通过SMT求解器来进行恢复。在我们的测试用例中,我们使用clang -O0对程序进行编译,以防止优化器将我们的反符号执行优化掉。输出的二进制包含几个栈slots,需要我们在重构代码时对它进行还原。如果我们不能还原栈slots和参数,那么LLVM优化就无法生效,反符号执行也没办法移除掉。如果我们成功地还原了,那么我们获取的LLVM-IR看起来应该和代码3中使用clang -O3 -S -emit-llvm对未混淆的代码编译后,编译出的IR相似。
SATURN的两个核心功能分别是控制流图重构和遍历。LLVM生态系统依赖于算法的强大和准确,在开发SATURN的pass的过程中,我们使用的就是这些算法。在本节中,我们会介绍SATURN是如何对函数的机器码进行恢复的。
4.1 代码提升为LLVM-IR
SATURN非常依赖Remill。这也是为什么我们说理解Remill是如何将native指令提升为LLVM-IR是一件很重要的事情。Remill利用目标体系架构的CPU指令集来提升指令。在表1中,我们可以看到x86_64架构中的State结构体。
为了模拟x86_64中如add rax,rcx这样的指令,Remill会生成一个辅助函数的调用语句,以模拟对应的指令。辅助函数将State结构体作为参数(代码4),并根据指令的语义计算其结果,以及修改Flags寄存器。当基本块中的所有指令转为IR后,生成的调用会作为一个内联函数放进调用者中。这一步中输出的LLVM-IR可读性还不高,但是它的功能和native指令完全一致。
Memory *__remill_basic_block(State &state, addr_t curr_pc, Memory* → memory);
代码4:Remill基本块的C/C++函数签名
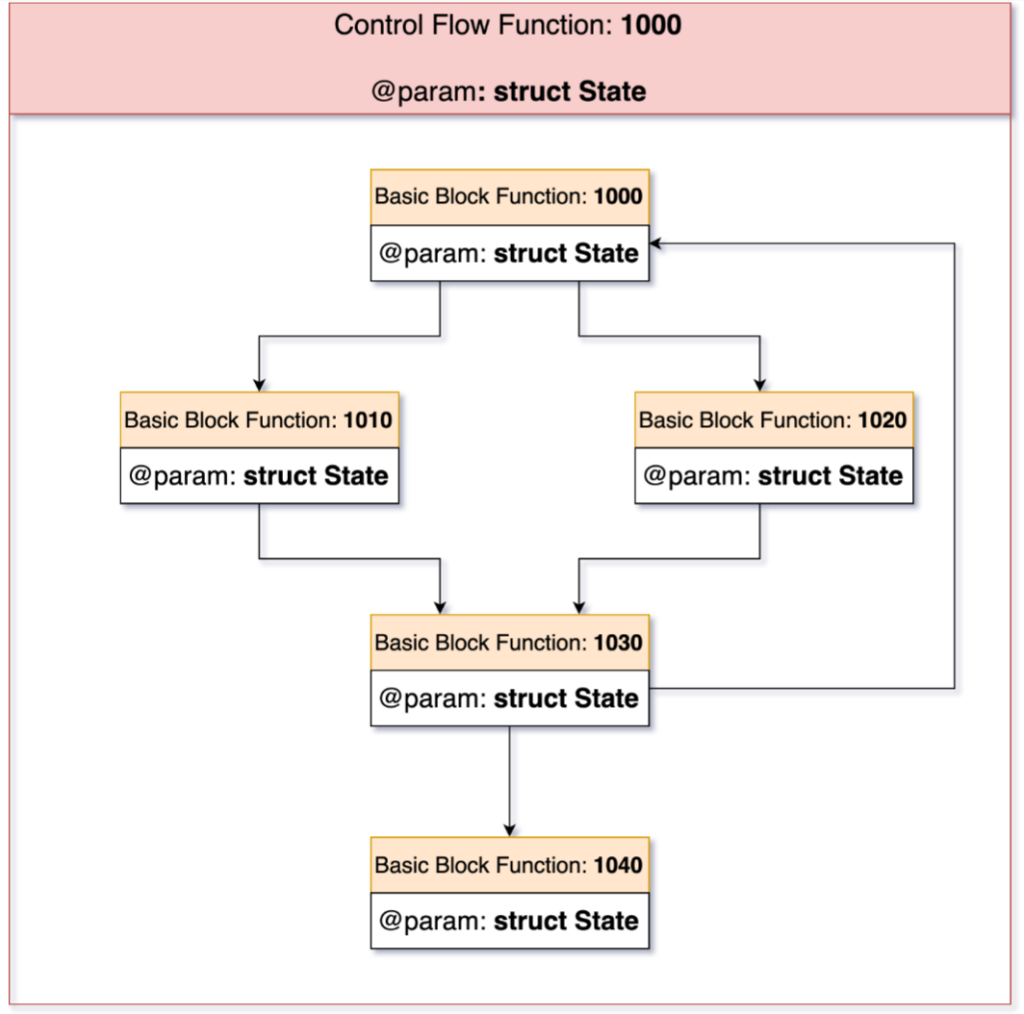
在转化为IR的过程中,SATURN将每个恢复后的基本块存储进自身的LLVM-IR函数中。接下来,这些基本块函数会和一个个LLVM-IR函数连接起来,用于组成恢复后的控制流图(图2)

图2:地址1000处的包含恢复后的控制流图的LLVM函数,基本块会被转为LLVM函数,并根据其用法被调用。调用的结果决定了条件分支的目标地址。
通过这种设计方式,我们可以直接优化提升为IR的基本块函数,并在后续的反混淆步骤中优化性能。在这一步中进行优化也能移除一些简单的混淆特征。控制流函数需要保持尽量简单,理想的情况是在不需要修改提升后的代码及处理LLVM的PHI节点的情况下,能够自由地添加或移除边[33]。
SATURN中规定了在提升基本块为IR的过程中,是怎样进行路径搜索的。SATURN使用Remill中的指令分类方式来对生成的提升函数进行分类。SATURN会基于这个分类来判断基本块是不是以不透明谓词(表1)结尾的。如果基本块可能是不透明谓词,SATURN会首先尝试使用LLVM的优化passes来确定它的出边。如果优化过后,出边的数量大于1,SATURN会尝试使用Souper和Z3 SMT求解器[9]计算出它真正的出边具体是哪一条。SATURN会尽量优先使用LLVM的优化,因为相比于SMT求解器,它的性能消耗更低。我们对各种混淆引擎的测试表明大多数不透明谓词都无法对抗LLVM的优化。我们会在第5节中具体描述不透明谓词的处理细节。
表1:路径搜索
| kCategory | Exploration | Opaqueness Proof |
|---|---|---|
| NoOp | Continue | No |
| Normal | Continue | No |
| FunctionReturn | Stop | Yes |
| IndirectJump | Stop | Yes |
| DirectJump | Stop | Yes |
| ConditionalBranch | Stop | Yes |
| IndirectFunctionCall | Stop | Yes |
| DirectFunctionCall | Continue | Yes |
每发现一条新边,SATURN都会将其转为IR。当SATURN发现一条新的基本块的入边时,我们得证明这条新发现的边,会不会使基本块的不透明性发生变化(表1)。我们采取如下步骤来验证:
(1)基于表4的定义,新建一个叫做FSlice的函数
(2)找到对提升后的基本块进行控制的控制块(BBLift)。
(3)如果找到一个以上前驱,转到步骤5 。
(4)基于控制块使用前驱作为输入重复2-3步骤,并将结果存入有序列表中(PSort)
(5)对于PSort中的每个前驱,以逆序在FSlice中创建一个调用。
(6)使用条件分支连接被调用的前驱
(7)在FSlice的末尾调用BBLift,并使用分支将它连接至调用的控制前驱。
(8)将FSlice中的所有调用内联,并使用LLVM优化。
目前SATURN使用的是节5.3中介绍的方案来确定一个基本块是不是不透明谓词。
基本块的不透明性可能会变化,它可以帮助我们检测误报(false positive)。这一步很重要,因为它会指导我们怎么进行下一步的代码遍历。我们也需要这一步,因为在最初的时候,我们不可能获取到所有的入边,只有在代码遍历的过程中,才能进一步获取到构建控制流图必要的信息。基本块的不透明性会根据表2来变化。
表2:基本块的不透明性
| Current Opaqueness | New Edge | New Opaqueness |
|---|---|---|
| No OP | No OP | No OP |
| No OP | OP | No OP |
| OP | No OP | No OP |
| OP | OP | OP |
让开发者能够轻松地定制自己的优化pass是LLVM核心设计的一部分,在这一节中,我们会介绍如何定制一个用于常量传播和不透明谓词识别的优化pass。
5.1 常量
在data section中存储常量是一种常见的混淆技术,它可以使IDA Pro的反汇编生成错误的结果或是使函数的不能被反汇编。在反混淆时,SATURN会尝试检测这些常量的访问并将read指令替换为LLVM-IR中的常量。全局常量的降级可以帮助LLVM优化pass进行常量折叠,并对抗一些类似的反混淆手段。用户需要使用SATURN的constantPool参数来确定常量数据的地址范围。我们的测试用例使用了几种混淆手段,结果表明将常量存储进data section中的安全强度还不够。在我们使用的混淆器中,我们可以找到用于获取这些常量的read/write属性。
5.2 栈指针别名
在Remill中没有栈的概念,它并没有模拟栈,而是使用读和写指令(代码5)来对栈寄存器中的地址进行操作。栈寄存器是State结构体的一部分,它声明一个无符号整型,如x86_64架构中的uint64_t State.gpr.rsp.qword。在SATURN中,对栈的访问是通过对IntToPtr的load/store操作来实现的。这使得它不可能使用LLVM中的指针别名,因为LLVM不支持整型的指针别名[17]。
uint<T>_t __remill_read_memory_<T>(Memory *, addr_t); Memory *__remill_write_memory_<T>(Memory *, addr_t, uint<T>_t)
代码5:Remill中内存读写指令的定义的
在SATURN中,我们通过具体化表示控制流图的函数中的栈寄存器来解决这一问题,首先表基本块函数内联并进行优化。在优化期间,具体的栈寄存器值会被传给LLVM-IR,并将IntToPtr操作数替换为一个具体的内存地址,该具体值能帮我们确定栈。然后在控制流图函数的开头,为栈中空间创建一个全局变量和一个LLVM-IR的Alloca指令。在执行Alloca指令之后,我们从全局变量中读取值并将它存储进Alloca中。除此之外,还需要维护一个栈中空间,全局变量和生成的Alloca指令的映射关系。接下来基于allocas对代码进行进一步的优化,这样在LLVM中就能使用指针别名的pass了。这些步骤可能会使我们发现一些新的栈空间,我们需要重复这一步骤直到没有新的栈空间被发现。在完成这些步骤之后,移除无用的全局变量。
在算法结束之后,某些全局变量就不能再进行优化了。这些全局变量代表着返回值,通过栈传递的函数参数和函数执行时从栈中读取或写入栈中的数据。这是算法的一个副作用,不过我们可以在后面的代码重构和函数参数恢复这两个反混淆步骤中使用它。
栈中的指针别名是反混淆时的一个 重要特征。后续的优化步骤需要用到这一步得到的结果,因此,它的准确性就很重要了。
0x146253057:learsp, [rsp-8] 0x14625305F:pushrcx 0x146253060:xchgrcx, [rsp+8] 0x146253065:movrcx, r14 0x146253068:mov[rsp+8], rcx 0x14625306D:movrcx, [rsp] 0x146253071:mov[rsp], r14 0x146253075:pushrcx 0x146253076:learcx, [rsp+8] 0x14625307B:notr14 0x14625307E:xorr14, [rcx] 0x146253081:poprcx 0x146253082:pushrbx 0x146253083:mov ebx, 0xD4469D6E 0x146253088:pushrsi 0x146253089:mov esi, 0xB7E07B2A 0x14625308E:add esi,ebx 0x146253090:mov ebx,esi 0x146253092:xor ebx, 0x533C089A 0x146253098:mov esi, 0xAB832EC0 0x14625309D:ror ebx, 0x14 0x1462530A0:and esi, 0x5B171CFB 0x1462530A6:rcl ebx, 0x1E 0x1462530A9:or ebx, 0xE4E97533 0x1462530AF:shld esi,ebx, 6 0x1462530B3:rcl ebx, 0xD 0x1462530B6:jb 0x1465C8B69
代码6:混淆后的x86_64不透明谓词
5.3 使用LLVM-IR优化解决不透明谓词
SATURN解决不透明谓词的方法分为两步。首先,它对指令进行切片(译者注:即将函数中的指令切分为一个个基本块),然后在其上应用LLVM优化。如果优化成功了,这块切片会被折叠为一个具体的值。
目前已有的一些切片器([38] [5] [29])都已经过时了,它生成的结果可能并不准确。而我们的算法是基于C语言中切片过程建模的基础上,并使用LLVM优化来生成切片。
5.3.1 SATURN的切片
代码4中的Remill的基本块定义,包含在Remill函数执行前后,读、写通用寄存器需要的信息。基于Remill的基本块,切片的过程如下所示:
(1)使用符号state初始化Remill的State结构体
(2)为RIP(初始指令指针,initial instruction pointer)赋值
(3)调用之前使用常量提升和栈别名pass优化过后的不透明基本块,这一函数调用是内联的。
(4)将State结构体传给不透明基本块
(5)在基本块执行后,获取其返回的State结构体,具体地说就是读取最终的指令指针。
extern "C" uint64_t __saturn_slice_rip(State state, addr_t curr_pc,Memory *memory, uint64_t *Stack) {
// 1 Allocate a local Remill State structure and initialize it
State S;
S.gpr.rax.qword = state.gpr.rax.qword;
...
S.gpr.rsp.qword = (uint64_t) Stack;
S.gpr.r15.qword = state.gpr.r15.qword;
S.aflag.af = state.aflag.af;
...
S.aflag.zf = state.aflag.zf;
// 2 Concretize RIP
S.gpr.rip.qword = curr_pc;
// 3/4 Call opaque basic block with initialized State struct
// This function call will be replaced with the lifted one
__remill_basic_block(S, curr_pc, memory);
// 5 Inspect the value of RIP
return
S.gpr.rip.qword;
}
代码7:SATURN的切片函数
初始化和进一步的读取操作如代码7所示。最后一步是获取到生成的__saturn_slice_rip函数,并使用LLVM对它进行优化。如果函数中使用到了不透明谓词,而LLVM能够将之去掉,函数的返回值就是一个具体的数值。这一数值就是基本块的后续指令的地址。代码6是一个混淆后的不透明谓词的例子。代码8中是我们前面这一系列步骤的结果。可以看到,函数的不透明性已经被去除,其具体的目标地址已经恢复了。
SATURN有两个选项来控制切片时,要生成的基本块的数量。sovlerBB-Countfcc和solverBBCountReturn这两个选项可以让用户在优化之前,设置只有单一前驱的不透明基本块的数量。
define dso_local i64 @__saturn_slice_rip(%struct.State*,i64, %struct.Memory*,i64*) {
entry:
ret i645475437417 ; 0x1465C8B69
}
代码8:在偏移0x1465C8B69处经过切片和优化并恢复不透明谓词后LLVM-IR
5.4 使用Souper和Z3处理不透明谓词
之前的方法可能会失败,因为LLVM优化不一定能将切片后的指令转为常量。这也就意味着条件分支是基于强度更高的不透明谓词,或是本身就是一个真实的条件分支。为了进一步分析分支,我们使用了Souper Optimizer[27]和SMT求解器。Souper中集成的Z3引擎识别不透明谓词的步骤如下:
(1)从不透明基本块(代码9中的%17的值)中提取分块后的指令。
(2)将Souper要处理的表达式收集起来。
(3)从这些表达式中选取与分片后的指令对应的表达式
(4)使用SMT获取分片指令表达式的解
(5)如果没有满足条件的解,那么说明在之前的步骤中有错误,LLVM的pass会失败
(6)如果解存在,我们就已经找到了一个正确的解,我们需要再进行一次SMT求解的过程,以此判断当前的解是否是唯一解,如代码10所示。
(7)如果第二次求解仍然有解,这说明这一条件分支是一个不透明谓词,它的真实目标地址就可以确定了。
(8)如果第二次无解,说明这是一个真实的条件分支,或是SMT求解器无法确定是不是不透明谓词。
define i64 @__saturn_slice_rip(%struct.State.32* %state,i64 %curr_pc, %struct.Memory* %memory,i64 * %Stack)#2 {
entry:
%0 =getelementptr inbounds%struct.State.32, %struct.State.32* %state,i64 0,i32 6,i32 17,i32 0,i32 0
%1 =load i64 ,i64 * %0, align 8, !tbaa !9
%2 =getelementptr inbounds%struct.State.32, %struct.State.32* %state,i64 0,i32 6,i32 19,i32 0,i32 0
%3 =load i64 ,i64 * %2, align 8, !tbaa !9
%4 =shl i64 %1, 56
%5 =ashr exact i64 %4, 56
%6 =add i64 %5, %3
%7 =xor i64 %3, %1
%8 =shl i64 %7, 56
%9 =ashr exact i64 %8, 56
%10 =and i64 %3, %1
%11 =shl i64 %10, 56
%12 =ashr exact i64 %11, 55
%13 =add nsw i64 %12, %9
%14 =trunc i64 %6to i32
%15 =trunc i64 %13to i32
%16 =icmp eq i32 %14, %15
%17 =select i1%16, i64 5368713261,i64 5368713259
ret i64 %17
}
代码9:demo分片后的MBA
(set-logic QF_BV )
(declare-fun arr () (_ BitVec 8) )
(declare-fun arr0 () (_ BitVec 8) )
(assert (let ( (?B1 arr0 ) (?B2 arr ) ) (let ( (?B3 ((_ sign_extend
24) ?B1 ) ) (?B4 ((_ sign_extend 24) ?B2 ) ) (?B5 (bvand ?
B2 ?B1 ) ) (?B6 (bvxor ?B2 ?B1 ) ) ) (let ( (?B11 ((_
sign_extend 24) ?B6 ) ) (?B10 ((_ sign_extend 24) ?B5 ) )
(?B8 (bvadd ?B4 ?B3 ) ) (?B9 (bvashr ?B4 (_ bv31 32) ) ) (?
B7 (bvashr ?B3 (_ bv31 32) ) ) ) (let ( (?B14 ((_ extract 0
0) ?B9 ) ) (?B12 ((_ extract 0 0) ?B7 ) ) (?B15 (bvshl ?
B10 (_ bv1 32) ) ) (?B13 (bvashr ?B8 (_ bv31 32) ) ) (?B16
(bvashr ?B11 (_ bv31 32) ) ) ) (let ( (?B17 ((_ extract 0
0) ?B13 ) ) (?B22 ((_ extract 0 0) ?B16 ) ) (?B19 (bvadd ?
B15 ?B11 ) ) (?B20 (bvashr ?B15 (_ bv31 32) ) ) (?B21 (
bvashr ?B15 (_ bv1 32) ) ) (?B18 (= ?B14 ?B12 ) ) ) (let (
(?B27 ((_ extract 0 0) ?B20 ) ) (?B25 (bvashr ?B19 (_ bv31
32) ) ) (?B23 (= ?B17 ?B14 ) ) (?B28 (= ?B21 ?B10 ) ) (?B24
(=false?B18 ) ) (?B26 (= ?B19 ?B8 ) ) ) (let ( (?B31 (
ite ?B26 (_ bv5368713423 64) (_ bv5368713442 64) ) ) (?B30
((_ extract 0 0) ?B25 ) ) (?B29 (or?B24 ?B23 ) ) (?B32 (=
?B27 ?B22 ) ) ) (let ( (?B35 (=false?B32 ) ) (?B33 (= ?
B30 ?B27 ) ) (?B34 (= (_ bv5368713423 64) ?B31 ) ) ) (let (
(?B36 (or?B35 ?B33 ) ) ) (let ( (?B37 (and?B36 ?B28 ) )
) (let ( (?B38 (and?B37 ?B29 ) ) ) (let ( (?B39 (=false?
B38 ) ) ) (let ( (?B40 (or?B39 ?B34 ) ) ) (and?B38 (=
false?B34 ) ) ) ) ) ) ) ) ) ) ) ) ) ) ) )
(check-sat)
(exit)
代码10:Z3的SMT中求解demo中的不透明谓词的过程
SATURN不仅 可以提升并反混淆代码,它还会重编译LLVM-IR,使之可以正常运行。这一节中我们会介绍SATURN中是怎么处理要重编译的代码,使其结果和vanilla中的结果类似。
6.1 IR优化
当混淆函数被恢复后,SATURN就会进入IR优化阶段,它使用图2中的控制流图函数作为输入,具体步骤如下:
(1)对State中的栈寄存器(RSP)和指令寄存器(RIP)赋值
(2)创建allocas用于标志寄存器的计算,并将结果存至State结构体中,这有助于优化掉不必要的标志寄存器的计算
(3)像图2那样内联基本块函数
(4)对这一函数进行LLVM优化
(5)对这一函数进行常量提升算法(节5.1)和栈别名分析(节5.2)。
(6)重复2-4步骤直到不再发生变化。
在上述优化完成后,输出的LLVM-IR不会再有混淆,但是,如代码11所示,因为对Remill的State结构体做了一些操作,我们仍然难以理解它的代码逻辑。在这一步中,对寄存器的赋值可以去掉了,可以使用LLVM的后端将LLVM-IR重新编译成机器码。例子中,我们使用Clang将LLVM-IR编译成Shared Object,SATURN有两种方式来重编译LLVM-IR:
- 第一种是使用如代码4中的Remill签名。创建的C++辅助函数会将x86_64环境转成虚拟环境,并管理State结构体
- 第二种是恢复原函数的参数,并移除State结构体。这种方法的好处是,方法可以被直接调用而不需要环境切换。它的细节在节6.2会具体介绍
6.2 代码重构
Remill提升后的函数运行在虚拟环境中(代码11),也就是State结构体。这使得一些优化难以进行,因为它必须将结果存储在State结构体的寄存器中。这一操作发生在代码11中介绍的所有寄存器中。此时输出的代码仍然难以被进一步地分析。这一节中,我们会解决这个问题,并展示如何重构原始的函数签名,包括函数参数的恢复,State结构体的移除(它会使得生成的结果和vanilla相似)6.2.1 函数参数
基于5.2节的算法,提升后的函数参数是通过栈来传递的,它可以通过全局变量来进行读取。在节5.2算法执行的过程中,SATURN会追踪全局变量和他们的栈偏移,这些信息可以用于确定参数的数量,函数使用的ABI和函数调用约定。如果函数没有栈参数,我们通过访问State结构体来确定参数的数量。我们只关注通用寄存器的重构,具体步骤如下:
define dllexport i64 @F_140001000(%struct.State.32* %S,i64 %curr_pc,%struct.Memory.0* %memory) {
entry:
%0 =getelementptr inbounds%struct.State.32, %struct.State.32* %S,i64 0,i32 6,i32 33,i32 0,i32 0
%1 =getelementptr inbounds%struct.State.32, %struct.State.32* %S,i64 0,i32 13
store i80,i8* %1, align 1
%2 =getelementptr inbounds%struct.State.32, %struct.State.32* %S,i64 0,i32 6,i32 5,i32 0
%3 =bitcast%union.anon.2* %2to i8*
%4 =getelementptr inbounds%struct.State.32, %struct.State.32* %S,i64 0,i32 6,i32 17,i32 0
%5 =bitcast%union.anon.2* %4to i8*
%6 =load i8,i8* %5, align 1
%7 =load i8,i8* %3, align 1
store i64 5368713251,i64 * %0, align 8
%8 =sext i8%7to i64
%phitmp =icmp eq i8%7, 126
%9 =getelementptr inbounds%struct.State.32, %struct.State.32* %S,i64 0,i32 6,i32 1,i32 0,i32 0
%10 =getelementptr inbounds%struct.State.32, %struct.State.32* %S,i64 0,i32 6,i32 5,i32 0,i32 0
%11 =sext i8%6to i64
%12 =and i64 %11, 4294967295
store i64 5368713372,i64 * %0, align 8
%13 =getelementptr inbounds%struct.State.32, %struct.State.32* %S,i64 0,i32 6,i32 7,i32 0,i32 0
%14 =xor i8%7, %6
%15 =sext i8%14to i64
%16 =getelementptr inbounds%struct.State.32, %struct.State.32* %S,i64 0,i32 6,i32 17,i32 0,i32 0
store i64 %12,i64 * %16, align 8
%17 =and i64 %12, %8
%18 =shl nuw nsw i64 %17, 1
%19 =and i64 %18, 4294967294
store i64 %19,i64 * %13, align 8
%20 =add nsw i64 %18, %15
%21 =and i64 %20, 4294967295
store i64 %21,i64 * %10, align 8
store i80,i8* %1, align 1
%22 = zext i1%phitmpto i8store i8%22,i8* %3, align 1
%23 = zext i1%phitmpto i64
store i64 %23,i64 * %9, align 8
ret i64 %23}
代码11:从Remill的State结构体中恢复出的demo的LLVM-IR
(1)基于函数的调用约定,从函数的最后一个寄存器参数开始[18],寻找第一条getElementPtr(GEP)指令,这条指令可以用来访问寄存器,同时它也控制着其他的GEP指令
(2)如果没找到GEP指令,继续找下一个寄存器,并使参数数量减1
(3)如果找到了GEP指令,向前滑动GEP的值,以寻找GEP指令的引用树。
(4)根据这些引用在函数中的支配树(DT,dominance tree)的位置排序。
(5)寻找读和写指令以确定GEP的用法。
(6)如果找到了读、写指令,就假设这个寄存器是一个参数
(7)否则,将参数数量减1,继续步骤3
6.2.2 函数重构。
基于恢复操作获取到的参数数量,去掉State结构体,重构提升后的函数。我们使用C/C++中的辅助函数来帮助我们将函数参数与它们的State中的位置对应起来,如代码12所示:
extern "C" Memory * F_Lifted(State &state, addr_t curr_pc, Memory *memory);
extern
"C" uint64_t x64_MS_2_ARG(uint64_t *RCX, uint64_t *RDX) {
struct State S;
// Set 1. arg
S.gpr.rcx.qword = (uint64_t) RCX;
// Set 2. arg
S.gpr.rdx.qword = (uint64_t) RDX;
// Call lifted function which will be replaced and inlined
F_Lifted(S, 0, nullptr);
// Return result
return S.gpr.rax.qword;
}
代码12:SATURN中用于处理windows64位的ABI中2个参数的ABI函数的C/C++辅助函数
我们只需要基于参数准备好寄存器辅助函数,对于将参数传递到栈上的函数,我们只需要将新的参数添加到LLVM-IR的辅助函数中并替换所有的全局变量引用,将这些全局变量表示为新创建的函数参数。后续操作就与参数数量无关了:
(1)找到F_Lifted伪函数的调用
(2)将F_Lifted的引用替换为提升后的IR函数
(3)将调用内联进辅助函数中
(4)使用LLVM进行强优化
基于LLVM的优化,我们可以获取到一个简洁的LLVM-IR函数,它看起来和代码13中的vanilla很像。如果我们将输入的LLVM-IR和代码13中的结果相比较,可以发现LLVM是有多么的强大。
define dllexport i64 @F_140001000_args(i64* %RCX,i64* %RDX,i64* %R8) {
entry:
%0 =ptrtoint i64* %RCXto i64
%1 =trunc i64%0to i8
%2 =icmp eq i8%1, 126
%3 =zext i1%2to i64
ret i64%3
}
代码13:恢复参数后优化后的MBA LLVM-IR函数
(译者注:后面的内容没有什么技术上的东西,精力有限,就不翻译了,感兴趣的自己看原文吧)
原文见附件
编译: 看雪翻译小组 梦野间
校对: 看雪翻译小组 lumou
[2020元旦礼物]《看雪论坛精华17》发布!(补齐之前所有遗漏版本)!
最后于 3天前 被梦野间编辑 ,原因:
如有侵权请联系:admin#unsafe.sh