IntroductionIn this blog post, we will share the story about how we discovered a critical stack corr 2023-2-8 19:0:0 Author: microsoftedge.github.io(查看原文) 阅读量:19 收藏
Introduction
In this blog post, we will share the story about how we discovered a critical stack corruption bug that has existed in Windows for more than 20 years (CVE-2023-36719). The bug was found in a core Windows OS library which is used by countless software products but is most notably reachable from within the sandbox of all Chromium-based browsers, exposing a sandbox escape which is reachable from the web via JavaScript.
We will walk through the process on how we chose the target and the method that led us to discover this vulnerability, as well as some thoughts on how this could lead to browser and full system compromise.
In line with our goal to make Microsoft Edge the most secure browser for Windows, we decided to target a platform-specific feature in the Web Speech API, which offers speech synthesis functionality to aid user experience and accessibility and ends up using the internal Microsoft Speech API.
The Web Speech API
The Web Speech API is defined in the JavaScript standard. It is a set of APIs which allow web developers to use speech synthesis and recognition features in their web applications.
As an example, consider the following JavaScript code snippet:
1
2
3
let text = "Hello World!";
speechSynthesis.speak(new SpeechSynthesisUtterance(text));
The speak method interacts with the platform-specific Text-To-Speech (TTS) service, and the audio will be played on the device.
Chromium Multi-Process Architecture
We will briefly cover the sandboxing architecture of Chromium-based browsers. Readers who are already familiar with this can skip to the next section,
As you may be aware, Chromium-based browsers (and most widespread modern browsers) use a multi-process architecture. All the content of a site, including untrusted JavaScript code, is parsed and executed within a separate process with no access to the file system, network or many other system resources. Generically, we refer to these as “sandbox” processes and there are several different types, in this case we are referring specifically to the Renderer Process.

Diagram showing Chromium multi-process architecture. Reference
Following the principle of least privilege, many of the higher trust responsibilities and functionalities are managed by the more privileged Browser Process. It has the permission to initiate many kinds of actions, including (but not limited to) accessing the filesystem, the device’s camera, geolocation data, and more.
Every time that the Renderer Process wants to perform a privileged action, it sends a request to the Browser Process over an IPC (Inter-Process Communication) channel.
The IPC functionality is implemented by Mojo, a collection of runtime libraries integrated into Chromium, that provides a platform-agnostic abstraction of common primitives, such as message passing, shared memory and platform handles.
The internal details of Mojo are not relevant for this blog post and are not necessary to follow the rest of the analysis. For more information, please refer to the official documentation.
Crossing the Boundary
In this case, the JavaScript call initiated by the web page will result in an IPC call from the renderer process to the SpeechSynthesis Mojo Interface, which is implemented by the browser process: speech_synthesis.mojom - Chromium Code Search
Effectively, calling the speak JavaScript API crosses a privilege boundary, and any bug that we trigger in the browser code may allow an attacker to gain code execution outside of the context of the sandbox.
Chromium does not have a custom TTS engine, as such the SpeechSynthesis interface is just a wrapper around the platform-specific service.
In the case of Windows, the “speak” method will call into the ISpVoice COM interface, as can be seen here: tts_win.cc - Chromium Code Search
1
2
3
4
Microsoft::WRL::ComPtr<ISpVoice> speech_synthesizer_;
HRESULT result = speech_synthesizer_->Speak(merged_utterance.c_str(),
SPF_ASYNC, &stream_number_);
The (untrusted) data that is passed as an argument to the JavaScript call is forwarded as-is* to the browser process and used as argument for ISpVoice::Speak call.
* Actually, it goes through some conversion process, from string to wide string, and some more characters are prepended to it, but it doesn’t really matter for the sake of this analysis.
The ISpVoice COM interface
Windows offers a framework, called COM (Component Object Model), which allows different software components to communicate and interoperate with each other, regardless of their programming language.
Without getting too much into details, whenever an instance of ISpVoice object is used, like this:
1
speech_synthesizer_->Speak(...);
the COM system framework (combase.dll) finds the path of the library which implements such interface and takes care of routing the call to the correct function.
In case of ISpVoice interface, the library which implements it resides in C:\Windows\System32\Speech\Common\sapi.dll.
This library will be dynamically loaded within the Browser Process memory (for the readers who are familiar with COM: this is because the ISpVoice service is an in-process service).
The ISpVoice interface implements the Windows Speech API (SAPI) and is very well documented here ISpVoice (SAPI 5.3) | Microsoft Learn
From the documentation we quickly learn that TTS engines are complex machines and not only support simple text but support a specific markup language based on XML that can be used to produce more accurate audio, specifying pitch, pronunciation, speaking rate, volume, and more. Such language is called SSML (Speech Synthesis Markup Language) and it’s a standard for Text-to-Speech engines. Microsoft also extends this standard by offering an additional grammar, called SAPI XML grammar (XML TTS Tutorial (SAPI 5.3) | Microsoft Learn).
For example, one could use SAPI grammar like this:
1
2
speechSynthesis.speak(new SpeechSynthesisUtterance(`<volume level="50">
This text should be spoken at volume level fifty.</volume>`);
The XML string passed as an argument ends up being parsed by the native library sapi.dll, which makes this a perfect target for vulnerability research.
This breaks the Chromium project Rule of 2 (indirectly using sapi.dll) because the OS library code is written in C++, it parses untrusted inputs, and it runs unsandboxed within the Browser process.
As emphasized before, a bug in this code might lead to a potential browser sandbox escape exploit. Moreover, being reachable directly from JavaScript, this would be one of those rare cases in which a sandbox escape could be achieved without compromising the Renderer process.
Fuzzing
Now that we have our target, we wanted to begin hunting for exploitable bugs. For our first approach, we decided to go for black box fuzzing to get something running as quickly as possible and get feedback on how to iterate later.
We found out that, overall, the best choice for our case was Jackalope, a fuzzer developed by Google Project Zero which supports coverage-guided black box fuzzing without much overhead and comes with a grammar engine which is especially useful to fuzz our SSML/SAPI parser.
Since we did not have any experience with the COM framework and how to interact with the ISpVoice service, we asked Bing Chat to write a harness for us, it sped up our development and worked flawlessly.

Prompt: Create a simple C++ program using Windows SAPI API to speak an input string
Then, we modeled SAPI grammar and ran our harness using Jackalope as the main engine.
This approach quickly resulted in our first bug, which was found in less than a day of fuzzing (!)
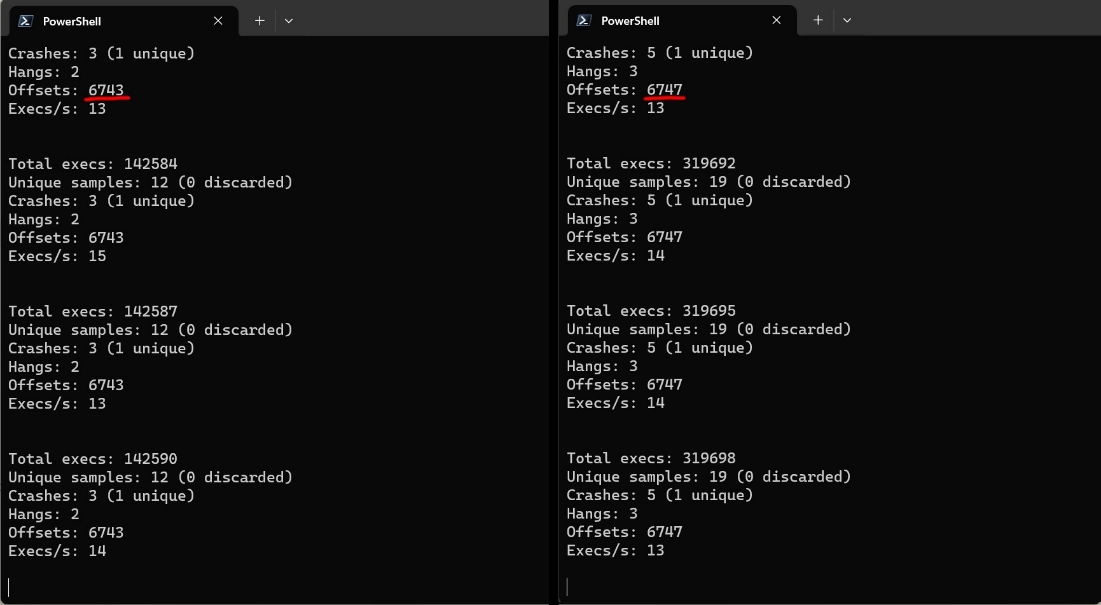
However, we noticed that the coverage measured by Jackalope (Offsets) reached a plateau very quickly in just a few days as you can see from the comparison screenshot, and consequently corpus size also stopped growing.

Comparison of Jackalope coverage after 3 days.
This is probably because mutating the existing corpus could not yield new code paths without hitting the same bug, so we did not get any more interesting test cases after the first crash.
In parallel, we decided to try another approach: generation-based fuzzing with Dharma (shout out to our colleague Christoph, who created it!).
Dharma is also a powerful solution, it's extremely quick and easy to set up and it’s not coverage guided. As such, it can generate huge test cases that extensively test all the grammar features right from the start. With this approach, we found again the same bug within a night of fuzzing.
The Bug
The bug in question is reachable through the function ISpVoice::Speak (SAPI 5.3), which takes as input an XML string that can support both tags specific to Microsoft SAPI format, and SSML (Speech Synthesis Markup Language) which is the standard for speech synthesis used by many other engines.
Looking at the source code of that function, we soon realized that the XML input goes through a 2-step processing:
- First, the XML string is parsed using the standard MSXML Windows library (msxml6.dll), looking for SSML tags.
- If the first step fails for whatever reason (e.g. broken XML string, or unrecognized SSML tags), the code falls back to SAPI parsing, which is implemented using a custom XML parser (written in C++)
Custom parsing of untrusted data is difficult and often results in exploitable security bugs. As you probably guessed, the bug we found resides in the latter part of the code.
When parsing a tag, the following struct is filled:
1
2
3
4
5
6
7
8
9
#define MAX_ATTRS 10
struct XMLTAG
{
XMLTAGID eTag;
XMLATTRIB Attrs[MAX_ATTRS];
int NumAttrs;
bool fIsStartTag;
bool fIsGlobal;
};
You may notice that the maximum number of attributes for each tag is set to 10. This is because according to the specification, there is no tag that requires that many.
Perhaps unsurprisingly, the bug happens when more than 10 attributes are used in a single XML tag, as no bounds checks are performed when adding them to the Attrs array, leading to a buffer overflow.
A simple PoC that could crash your browser process directly from JavaScript, on the vulnerable version of the library, is this:
1
2
let text = `<PARTOFSP PART="modifier" PART="modifier" PART="modifier" PART="modifier" PART="modifier" PART="modifier" PART="modifier" PART="modifier" PART="modifier" PART="modifier" PART="modifier" PART="modifier" ></PARTOFSP>`;
speechSynthesis.speak(new SpeechSynthesisUtterance(text));
The Overflow
Trying to reproduce the bug on a vulnerable version of sapi.dll results in a crash due to invalid rip value and completely corrupted stack trace. This immediately points to a possible stack buffer overflow.

WinDBG catching the browser crash.
The first thing we noticed was that the crash did not trigger the corruption of a stack canary. This discovery intrigued us, but we needed to gather more information before digging into this oddity.
In order to get to the root cause of the bug we wanted to use Time Travel Debugging to easily step backwards to the exact point where the stack got corrupted, we found something similar to this:
Note: we’re omitting the original code and using some equivalent snippets
1
2
3
4
5
6
7
HRESULT CSpVoice::ParseXML(…)
{
...
XMLTAG Tag; // XMLTAG struct on the stack
...
ParseTag(input_str, &Tag, ...); // Call to the vulnerable function
}
In the ParseTag function there is the loop that will parse every attribute and fill in the &Tag->Attrs[] array and eventually write past its end:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
HRESULT ParseTag(wchar* pStr, XMLTAG* pTag, …) {
// some code … //
while (hr == S_OK && *pStr) {
// Fill attribute name from the input string
hr = FindAttr(pStr,
&pTag->Attrs[pTag->NumAttrs].eAttr,
&pStr);
if( hr == S_OK )
{
// Fill attribute value
hr = FindAttrVal(pStr,
&pTag->Attrs[pTag->NumAttrs].Value.pStr,
&pTag->Attrs[pTag->NumAttrs].Value.Len,
&pStr);
if( hr == S_OK )
{
++pTag->NumAttrs;
}
}
}
}
Stack cookies? No thanks
At this point it’s clear that we had a stack buffer overflow, and we had a few questions:
- Why didn’t the process crash with a corrupted stack cookie?
- We have control of RIP; is it exploitable? What other primitives does it give us?
Regarding the first question, we wanted to know why we hadn’t triggered a stack canary exception despite clearly overflowing and corrupting the call stack. We dug out the source code from the OS repository and began to investigate. From the build scripts it was clear that the library was compiled with /GS (Stack Canaries). In disbelief, we opened the binary in IDA pro and saw the canary check in the relevant function.

It was clear that something fishy was going on and that more investigation was required.
Let’s start by recalling the structures involved here:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
struct XMLTAG
{
XMLTAGID eTag;
XMLATTRIB Attrs[MAX_ATTRS];
int NumAttrs;
bool fIsStartTag;
bool fIsGlobal;
};
struct XMLATTRIB
{
XMLATTRID eAttr; // enum that identifies the attribute name
SPLSTR Value;
};
struct SPLSTR
{
WCHAR* pStr; // wstring pointing to the attribute value
int Len; // length of the attribute value
};
Our overflow allows us to write additional XMLATTRIB structures past the end of the XMLTAG.Attrs array. Serializing the members of this structure means we can effectively write content in chunks of 24 bytes as shown:
1
2
3
XMLATTRID eAttr; // 4 bytes enum (padded to 8)
WCHAR* pStr; // 8 bytes pointer that points to our controlled string
int len; // 4 bytes controlled length (padded to 8)
What is the first thing we overwrite past the Attrs array?
It’s the NumAttrs field of XMLTAG structure. We can overlap it with any value from the possible XMLATTRID values. Those are chosen from the attribute name, and it can be any controlled value from 0 to 23.
Since NumAttrs is used by the vulnerable function to index the array, we can pick this number to cause a non-linear overflow and jump past the current frame’s stack cookie when overwriting the stack.

This is exactly what happened (accidentally) with our first PoC: the 11th attribute PART gets parsed into an XMLATTR structure with eAttr value higher than 10. That value overwrites NumAttrs and then the next attribute (12th attribute) actually overwrites directly the saved rip without touching the stack cookies.
We tried to modify the PoC by crafting a possible rip value and run on a machine with Intel CET enabled and it resulted in a crash related to shadow stack exception.
In fact, on most recent devices, overwriting rip wouldn’t be a feasible exploitation strategy because of shadow stack (Understanding Hardware-enforced Stack Protection), which double checks the return address saved on the stack before jumping to it.
But it’s worth mentioning that most of the current Desktop users are not protected by this mitigation, since it was introduced only recently.
To summarize: stack canaries are ineffective, CET protection isn’t available on the average customer machine. How easy does it get for attackers?
Since this bug allows us to corrupt almost anything we want on the stack, even at deeper stack frames, we could look for more possible targets to overwrite, other than saved rip, and there are indeed some object pointers in the stack that we could overwrite, but we need to keep some limitations in mind.
There are two possible strategies here:
We can either overwrite a pointer with full qword (the pStr value, that points to our controlled wide string) and in that case we would be able to replace an object with almost arbitrary content.
However, crafting data, and especially pointers, will not be very feasible, since we can’t include any 2-nullbytes sequence (\x00\x00) because that is a null wchar and the xml parsing will stop early.
This makes it very hard (impossible?) to craft valid pointers within the controlled content. Moreover, apart from null bytes, there are other invalid byte sequences that will not be accepted as valid wide strings and would break the parsing early.
Alternatively, we could overwrite a value in the stack that is aligned with our controlled len field. In this case, since len is of type int, only the least significant 4 bytes will be overwritten, leaving the most significant part untouched.
Even here, to craft a valid pointer, we would need to have a huge length, which doesn’t work in practice.
Due to time constraints of the project, we didn’t explore exploitation possibilities further, but we believe that starting from a corrupted renderer, exploitation would be much more feasible given these primitives.
Keep fuzzing the surface
After the initial quick success and given the necessity to fix the first bug to keep fuzzing further, we decided to spend some time figuring out how to re-compile our target library sapi.dll with ASAN (Address SANitizer) and code coverage to test more effectively.
Having ASAN enables us to catch potential heap errors that would otherwise have been missed by PageHeap sanitizer (that we used during our first iteration). Plus, it gives detailed information for stack corruptions as well right-away, dramatically reducing debugging time in case we found more of those.
As mentioned earlier, the Windows Speech API is called from Chromium via the COM interface ISpVoice.
Our target DLL is not directly linked to the harness, but it is loaded at runtime by the COM framework, based on the path specified in the system registry for that COM CLSID.
To make our fuzzer simpler to deploy on other infrastructures such as OneFuzz, we decided to use Detours to hook LoadLibraryEx and replace the DLL path loaded from the system registry with the path of our instrumented DLL instead of modifying the registry.
Having the library built with ASAN and SANCOV allowed us to use any other fuzzer, such as Libfuzzer which is the standard de-facto (although deprecated).
Therefore, our second iteration consisted of rewriting and expanding the grammar for the coverage guided whitebox fuzzer. This was done using LibProtobuf-Mutator.
Nowadays, the fuzzer keeps running on our continuous fuzzing infrastructure using OneFuzz and keeps helping our engineers in fixing bugs on this surface.
Conclusion
In this blog post, we have shown how we discovered and reported a critical bug on Windows that was reachable from the browser using the Web Speech API. We have explained how we used the SAPI XML grammar to craft malicious inputs that could trigger memory corruption in the sapi.dll library, which runs unsandboxed in the browser process.
Bugs like the one discussed here are particularly rare since, when exploited, lead to full compromise of the browser process without the need of additional bugs (normally you would need a chain of at least two bugs to gain control over the browser process).
Moreover, this bug would have been reachable from any Chromium based browser (Edge, Chrome, Brave Browser, and so on…) regardless of their version, which makes this case even more interesting.
One could wonder: were other browsers affected as well?
Normally, yes. Any browser that implements the speechSynthesis JavaScript interface and uses the Windows Speech API should be affected.
However, some browsers took slightly different approaches that might spare them from this bug. Firefox, for instance, does use sapi.dll, but it strips away XML tags from the input, at the cost of losing all the features that the SSML standard provides.
The need for modern browsers to interact with multiple OS components in order to offer rich functionalities (like speech synthesis, speech recognition, etc.) makes things harder for security, since third-party libraries are loaded in the browser process and often take inputs from untrusted sources.
In this case, we limited our analysis to the case of Windows platform and to the Speech API, but there might be other cases where a comparable situation occurs.
In the future, we plan to investigate more COM components used by browsers and perform audits to external libraries that are loaded in the Browser Process and may expose security risks.
如有侵权请联系:admin#unsafe.sh