
作者:0x7F@知道创宇404实验室
时间:2020年01月09日
0x00 前言
随着技术浪潮的涌动,国家政策的推动,区块链又慢慢的进入了我们的视野中。在 2020 年初这个时刻,不妨我们再回头看看区块链的发展,聊聊区块链中的几个技术点,为新的一年打打基础。
2017 年是数据货币大爆发的一年,其标志性事件是 2017 年 12 月比特币价格达到历史最高,并将区块链引入公众的视野中;也因此,2018 年被称之为区块链元年,各类数字货币和与区块链沾边的技术如雨后春笋般出现在互联网上;后来随着区块链的监管力度增大,2019 年则是区块链冷寂的一年,最后经过考验的都是具有价值的区块链项目。
那么本文,我们就抛开数字货币不谈,仅从区块链的方面来聊聊;文中使用比特币 v0.19.x(commit: 0655c7a94cc9bf54d43eceed805e83f1b59e2409) 的源码来帮助理解。
0x01 区块链的简介
区块链随着比特币的诞生而诞生,首次出现于比特币的白皮书中(https://bitcoin.org/bitcoin.pdf),用于存储比特币的交易记录;在比特币中,根据时序将多条交易记录整理集中存储以形成区块,块与块之间采用哈希值的方式连接形成链式结构,我们将这种结构称为区块链。
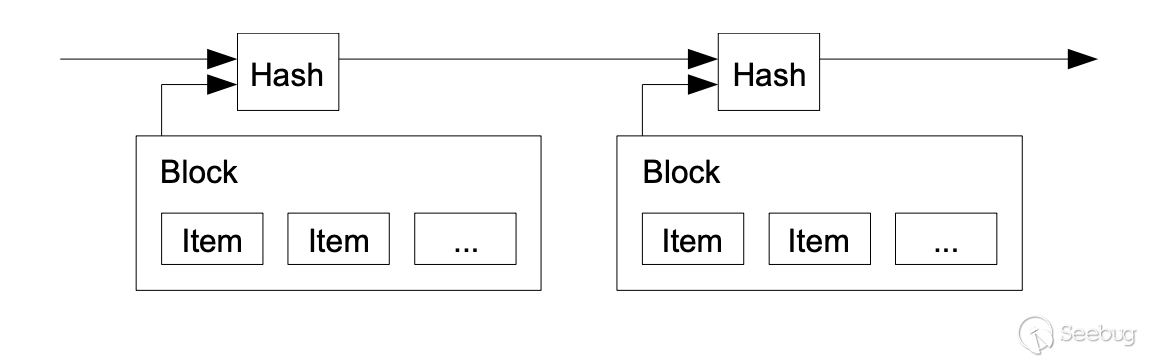
比特币中,多个节点通过P2P网络共同维护一条区块链,使得这种链式结构具有去中心化、不可篡改、可追溯等特性。后续的以太坊、超级账本等项目也都基于这种链式结构。
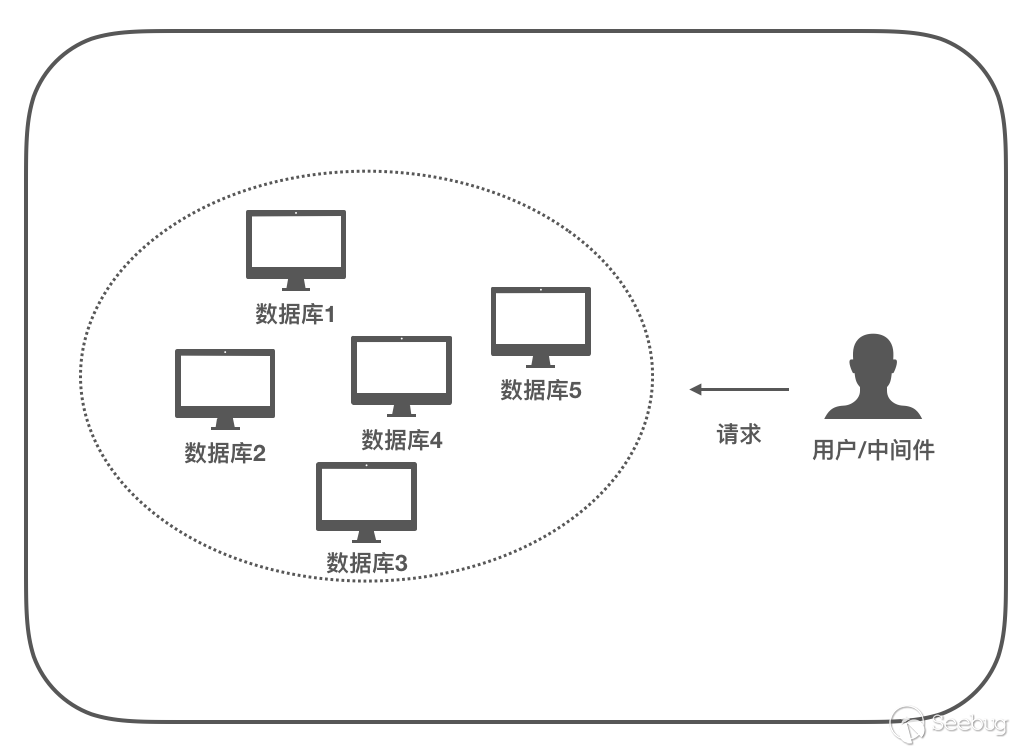
这里我们抛开数字货币,把区块链作为主角来看,我们可以更加容易的来理解区块链:区块链就是一个基于P2P的分布式数据库,以多个节点共同维护一份数据;那么从这个角度来看,比特币的区块链存储的「交易记录」也是数据,只是数据比较特别而已。
0x02 区块链vs分布式数据库
我们可以认为区块链就是基于P2P的分布式数据库,是因为区块链和分布式数据库有着相似的目标:使用多个节点来共同维护一份数据。
但我们仅仅以「存储」这一个操作来理解,并且忽略掉了它们本身的应用场景、默认所有节点都是可信、可靠、无延时通信的、等等。实际环境下,我们需要去考虑如上诸多的因素,因此区块链不能等同于分布式存储数据库。
我们使用表格来对比区块链和分布式数据库:
| 区块链 | 分布式数据库 | |
|---|---|---|
| 架构 | 分布式 | 分布式 |
| 价值主张 | 数字化信任系统 | 高性能存储和访问 |
| 网络通信 | peer-to-peer | client-server |
| 管理方式 | 集中管理 | 分散管理 |
| 数据结构 | 链式 | 索引、等等 |
| 节点关系 | 怀疑 & 制约 | 信任 & 协作 |
| 一致性 | 共识算法 | 主从复制 |
| 数据持久 | 数据不可变 | 可修改 & 非持久 |
| 性能 | 低 | 高 |
在了解区块链和分布式存储数据库的异同点后,我们可以知道无论是分布式存储数据库还是区块链,都需要去解决分布式中的问题;并且区块链还需要去解决它所特有的问题。所以我们以分布式存储数据库为基础,来帮助我们理解区块链中所涉及到的技术点。
0x03 分布式中的挑战
1.FLP不可能原理
对于分布式系统中的不确定性,Fischer、Lynch和Patterson三位科学家在1985年发表论文并提出FLP不可能原理:在网络可靠,但允许节点失效(即便只有一个)的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性算法。
所以理论上不存在一个可以完美解决一致性问题的方法,但在工程应用中,我们可以选择牺牲部分特性,以换取一个可行的方案。
2.CAP原理
那么我们应该如何选择代价,来换取这个可行的方案呢?在 2000 年由 Eric Brewer 教授在 ACM 组织的一个研讨会上提出了 CAP 原理:分布式系统不可能同时确保以下三个特性:一致性(Consistency)、可用性(Availability)和分区容忍性(Partition),设计中往往需要弱化对某个特性的保证。
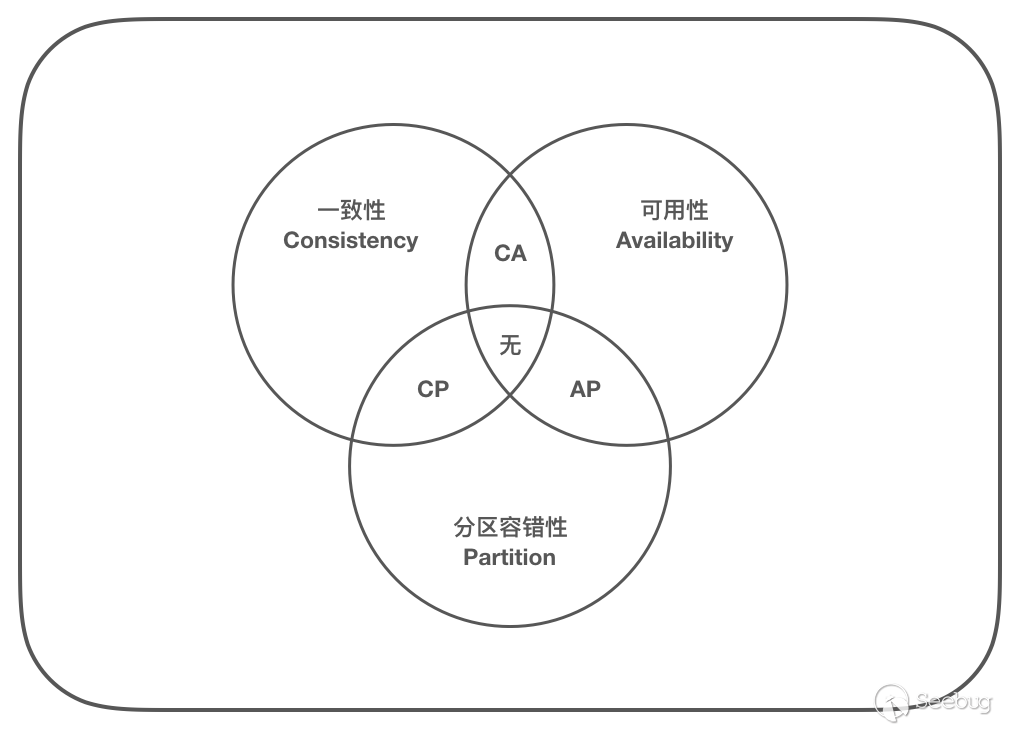
根据 CAP 原理,我们就可以根据不同的需求,对三种特性进行抉择。如访问分布式的网站的静态内容,可以接受数据延迟更新,这是弱化了一致性;而在区块链中,即便牺牲性能也要保证只有一份公认的数据,这是弱化了可用性。
3.拜占庭容错
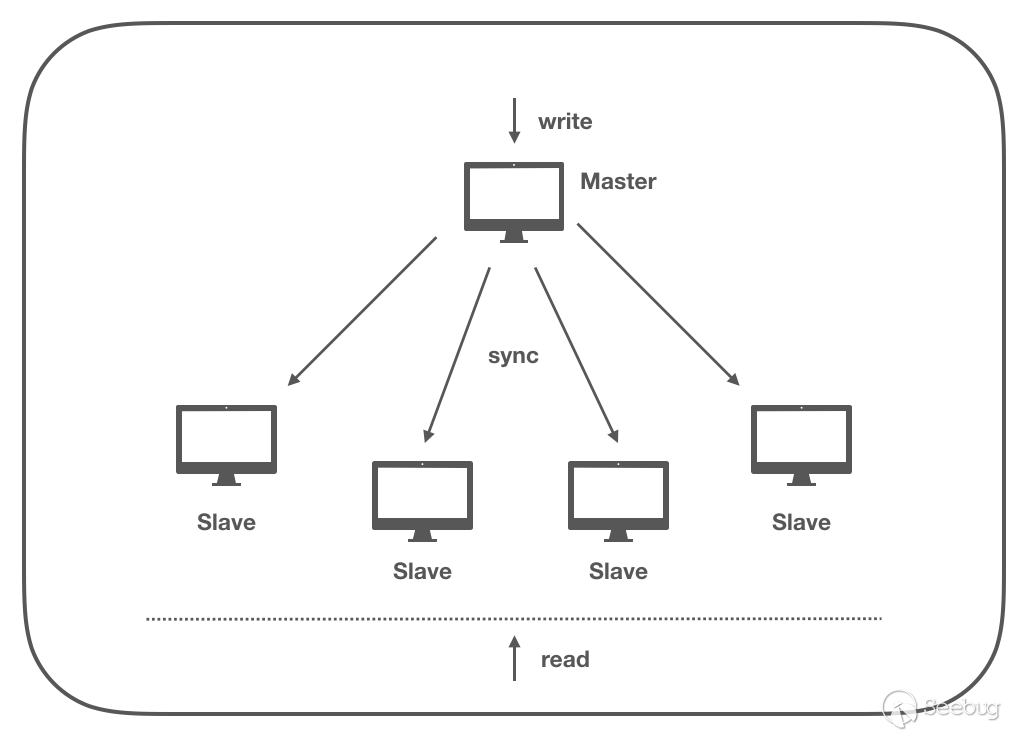
在分布式数据库中,节点之间是相互信任的、是忠诚的,它们可能会离线、宕机,但它们绝不会发送错误的消息;所以我们可以信任任意一个节点,分布式数据库常用「主从复制」实现一致性,也就是:从中选择一个节点作为主节点,其他节点从该节点复制数据,如果该节点出现故障,则重新选择新的主节点。
而在区块链中节点是自由的加入和退出的,可能会出现恶意节点:该节点可能会离线、宕机,并且会发送错误的消息来扰乱数据的一致性;这就是常说的拜占庭将军问题。
这是 20 世纪 80 年代提出的一个假想问题,描述的是:「一组拜占庭将军分别各率领一支军队共同围困一座城市,由于各支军队处于城市不同方向,所以他们只能通过信使进行联系;军队的行动策略限定为进攻或撤离两种,部分军队进攻部分军队撤离都可能会造成灾难性后果,因此各位将军必须通过投票来达成一致策略;每位将军都将自己投票信息通过信使通知其他将军,所以每位将军根据自己的投票和其他所有将军送来的信息就可以知道投票结果而决定行动策略」。
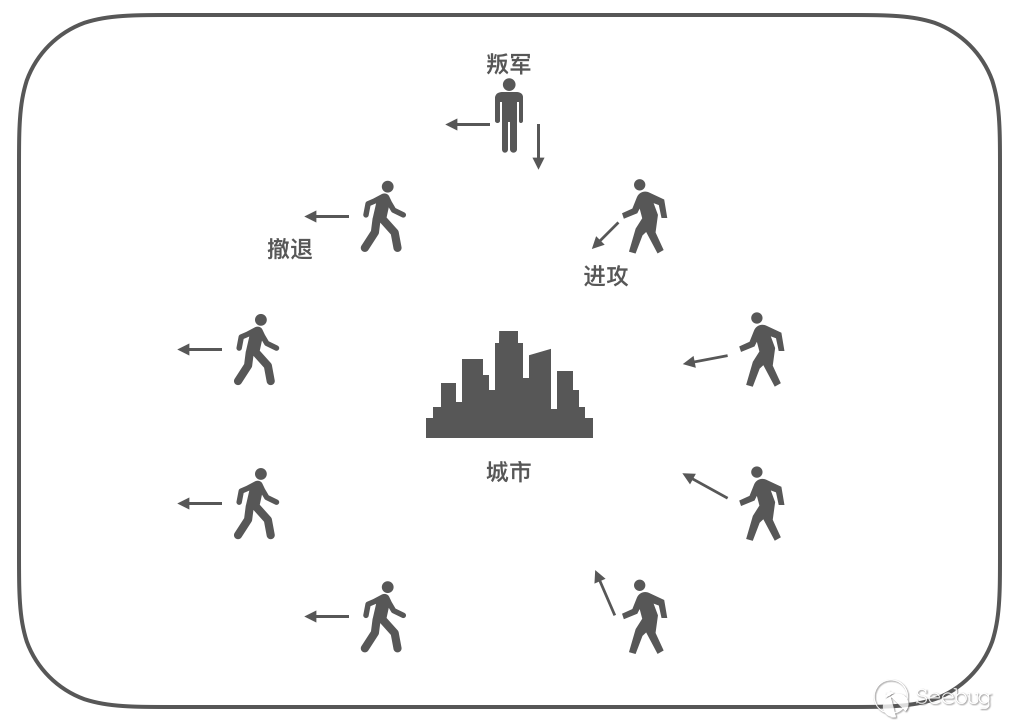
在上图中,由叛军发送错误的投票信息引起不一致的问题,称之为「拜占庭错误」,能够处理拜占庭错误的方法称为「拜占庭容错」(Byzantine Fault Tolerance)。那么区块链中是如何解决的呢?
0x04 共识算法
PBFT算法
PBFT(Practical Byzantine Fault Tolerance) 算法的提出主要就是为了解决拜占庭错误。其算法的核心为三大阶段:pre-prepare阶段(预准备阶段),prepare阶段(准备阶段),commit阶段(提交阶段),我们以下图来理解该算法。
其中 C 表示发起请求客户端,0123 表示服务节点,3 节点出现了故障,用 f 表示故障节点的个数。
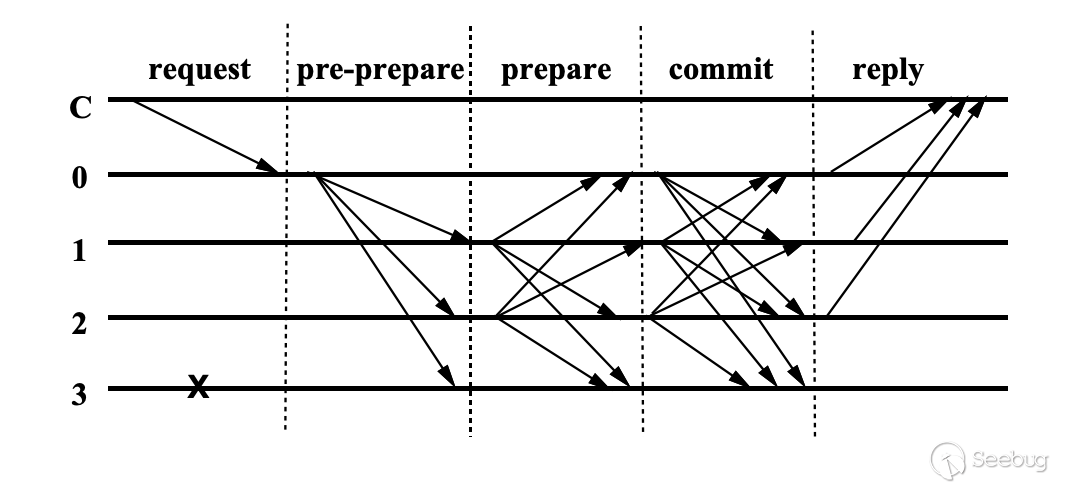
- C 向 0 节点发起请求
- 0 节点广播该请求到其他服务节点
- 节点在收到 pre-prepare 消息后,可以选择接受和拒绝该消息,接收该消息则广播 prepare 消息到其他服务节点
- 当一个节点在 prepare 阶段并收到 2f 个 prepare 消息后,进入到 commit 阶段,广播 commit 消息到其他服务节点
- 当一个节点在 commit 阶段并收到 2f+1 个 commit 消息后(包括它自己),发送消息给 C 客户端
- 当 C 客户端收到 f+1 个 reply 消息后,表示共识已经完成
(详细可以参考http://pmg.csail.mit.edu/papers/osdi99.pdf)
PBFT 中节点数必须满足 N >= 3f+1 这个关系,只要节点中的故障节点不超过 1/3 时,就可以完成共识确定一致性。由于 PBFT 算法的特性以及性能问题,所以其常用于小规模联盟链中。
PoW算法
比特币中使用 PoW(Proof of Work) 算法,即为工作量证明算法。其算法的核心为利用复杂的数学计算竞争一次添加区块的机会,结合「不利原则」,并仅认可最长的链为合法的链 这一规则,完成节点共识。
在比特币中,PoW 的工作方式如下:
- 用户发起交易,由节点广播交易至所有节点
- 节点收到交易打包并将其放入块中
- 某一节点计算出了哈希结果,获得添加区块的机会,将 2 中的块添加到区块链尾部,并广播区块至所有节点
- 节点收到新的区块信息后,验证区块合法性,合法后将其添加到区块链尾部,并进入下一轮的竞争
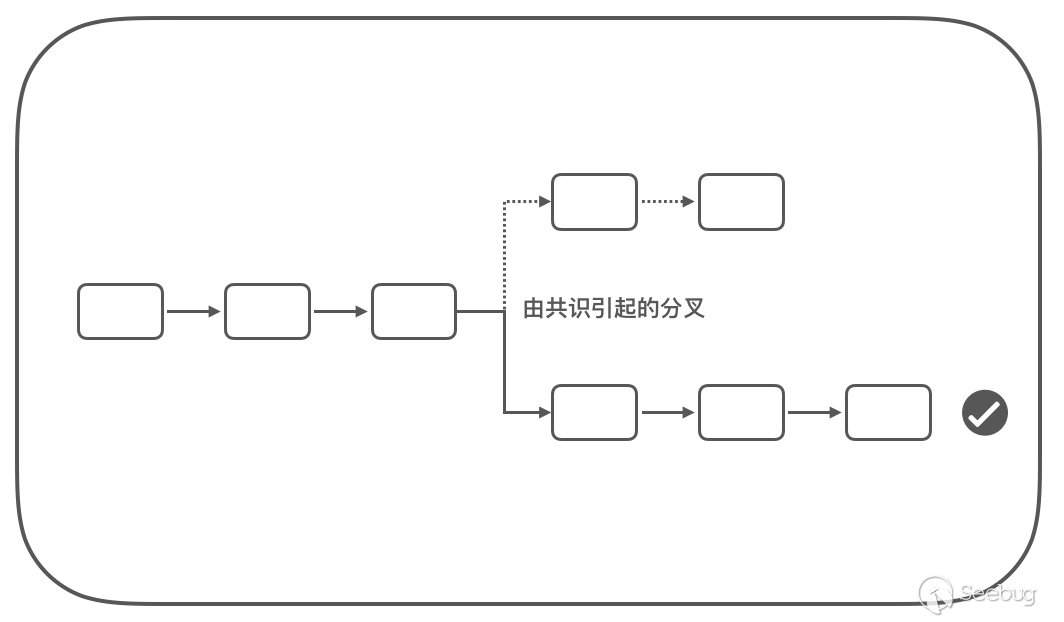
通过 PoW 算法,比特币可以允许全网有 50% 的节点错误的情况下,依然能够完成共识。
code>>>>
那么在比特币中是如何实现 PoW 算法的呢?PoW 算法位于区块生成的模块中(挖矿)。我们先看看比特币的启动流程,比特币程序入口位于 bitcoind.cpp 下,通过这样的调用链启动比特币中的各项服务:
main()->AppInit()->AppInitMain()其中包括 RPC 服务,在比特币中我们需要使用 bitcoin-cli 通过 RPC 服务启动挖坑,最终到 rpc/mining.cpp/generateBlocks() 这个区块生成主逻辑:
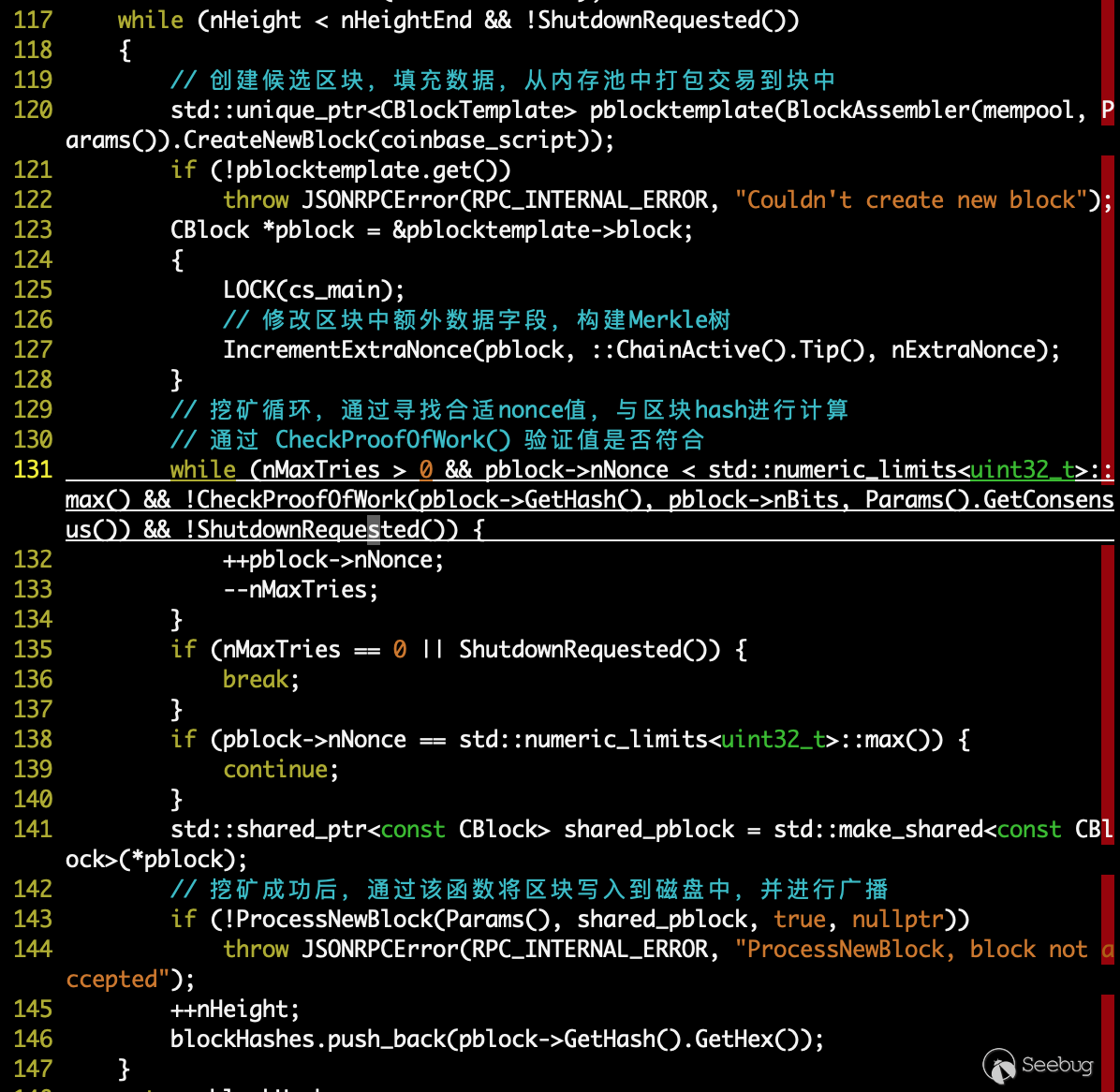
其中 pow.cpp/CheckProofOfWork() 函数进行了 PoW 算法的验证,主要是判断在当前 nonce 值的情况下,区块哈希值是否小于难度值:
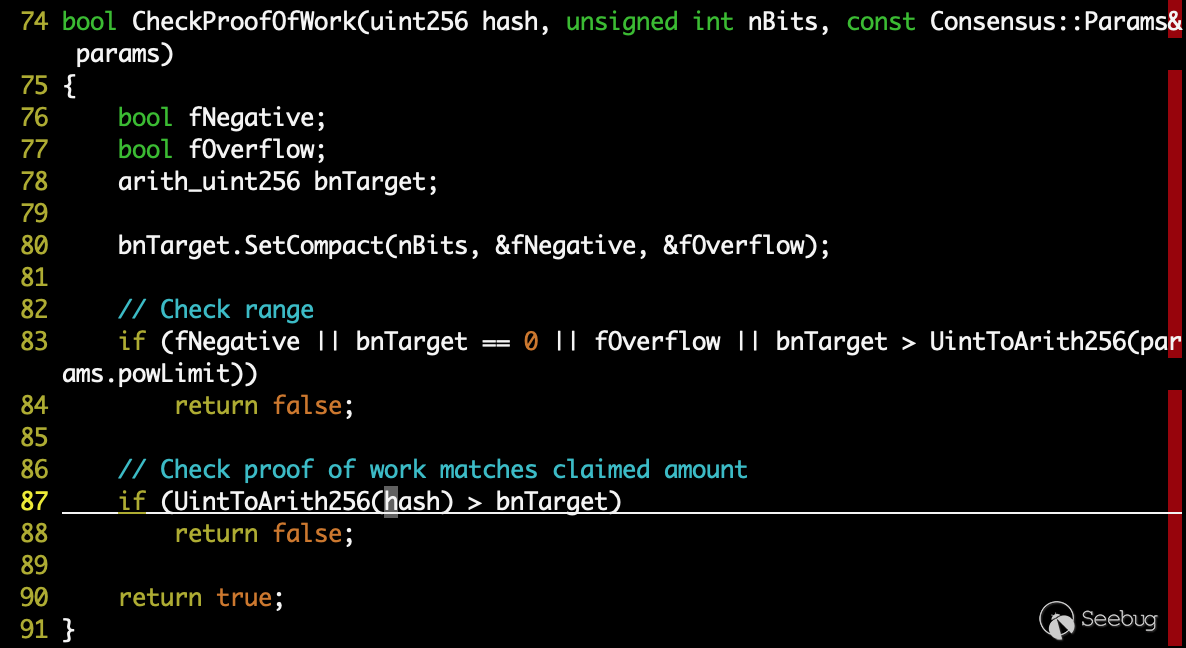
<<<<
其他
但由于 PoW 算法性能低下、而且会造成大量的算力浪费,大家纷纷提出新的共识算法,如 PoS(股权权益证明)、DPoS(委托权益人证明机制),等等;但以比特币占据区块链项目的半壁江山来看,PoW 仍是目前用得最多的共识算法。
0x05 存储结构
在了解共识算法后,我们可以保证数据的一致性了,那么这些数据是如何在区块链中存储的呢?
Merkle树
在比特币中,使用 Merkle 树组织和存储一个块内的交易信息,它是一种基于哈希的二叉树(或多叉树),其结构如下:
- 叶子节点存储数据
- 非叶子节点存储其子节点的内容的哈希值
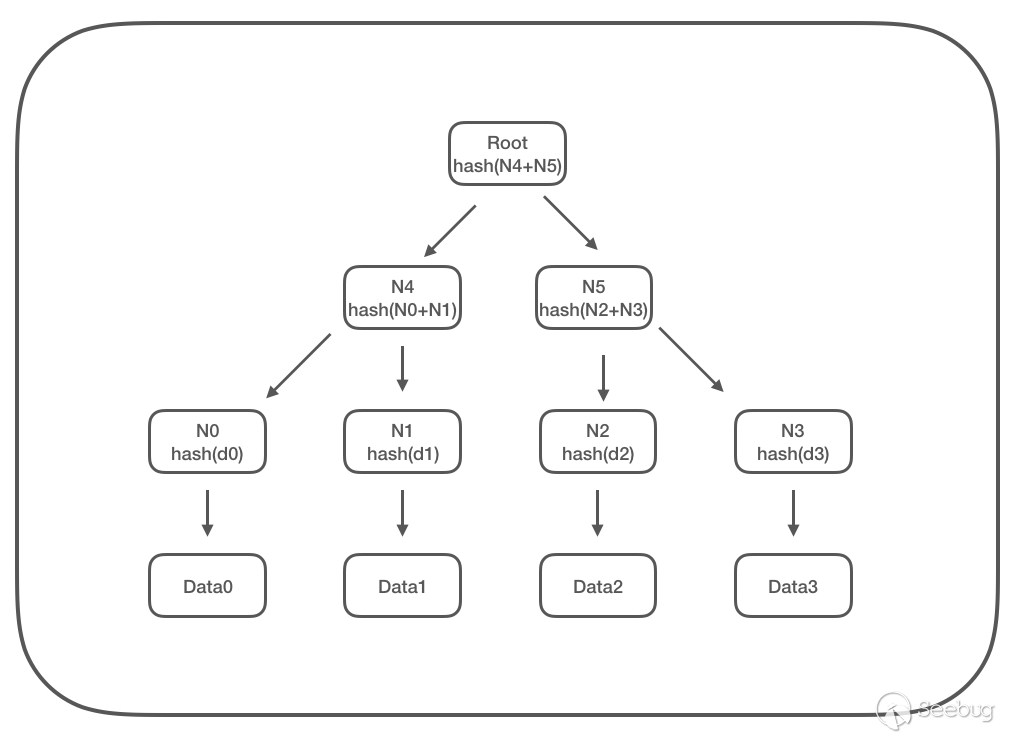
使用 Merkle 树的优势所在:
- 快速比较大量数据,比较根节点的哈希值即可知道两组数据是否相同
- 快速定位修改,任何子节点的变动都会传递至根节点,从根节点向下检索即可找到修改的节点。
code>>>>
在比特币中,Merkle 树的生成是挖矿步骤中的子步骤,跟入上文中的区块生成流程中的 miner.cpp/IncrementExtraNonce() 函数中,在该函数中调用 consensus/merkle.cpp/BlockMerkleRoot() 函数以构建 Merkle 树:
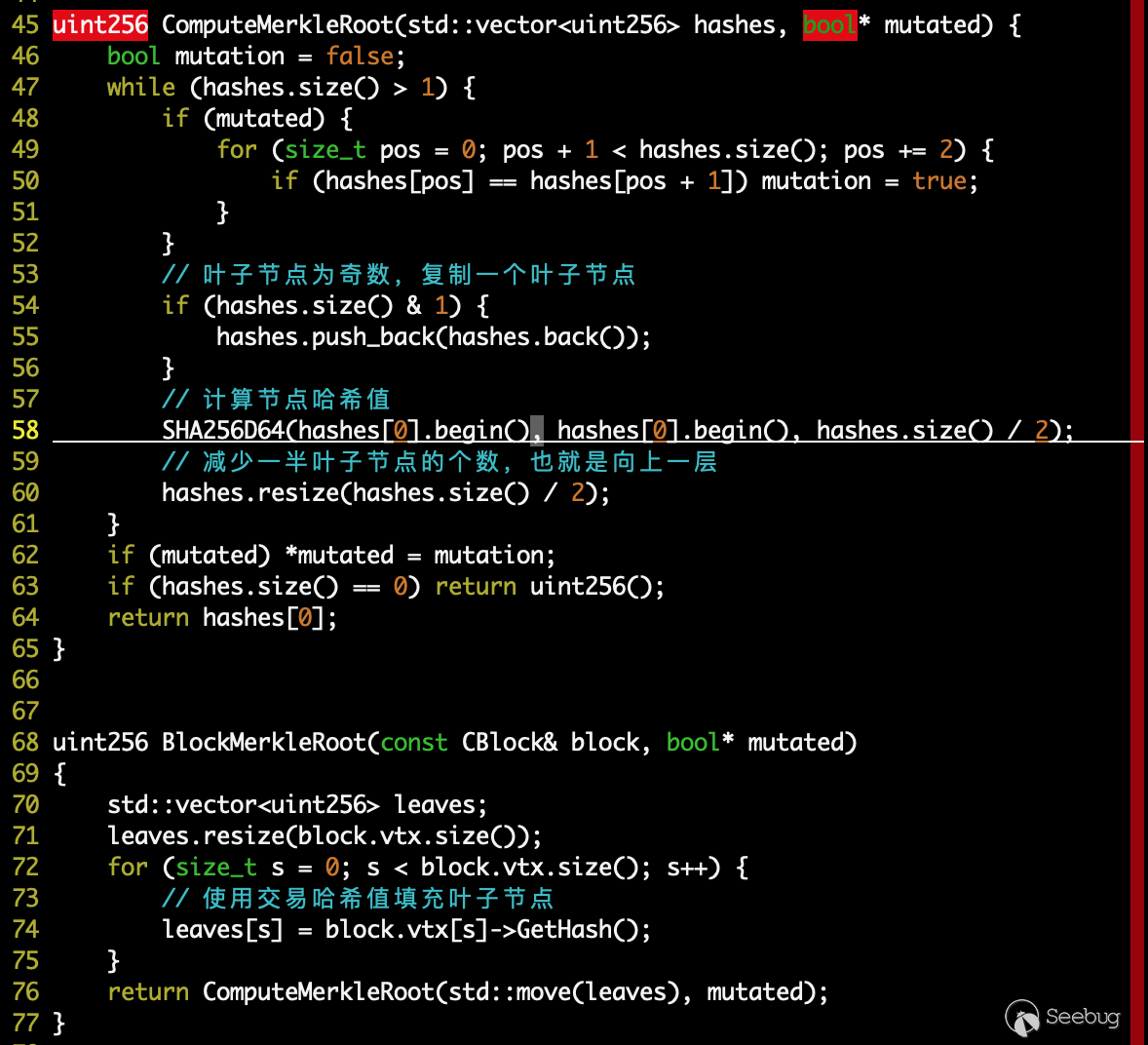
<<<<
哈希链
在一个区块中,除了打包成Merkle树的交易信息,还包括块高度、随机数、时间等等信息,其中父块哈希值将各个区块联系起来,形成链式结构,如下:
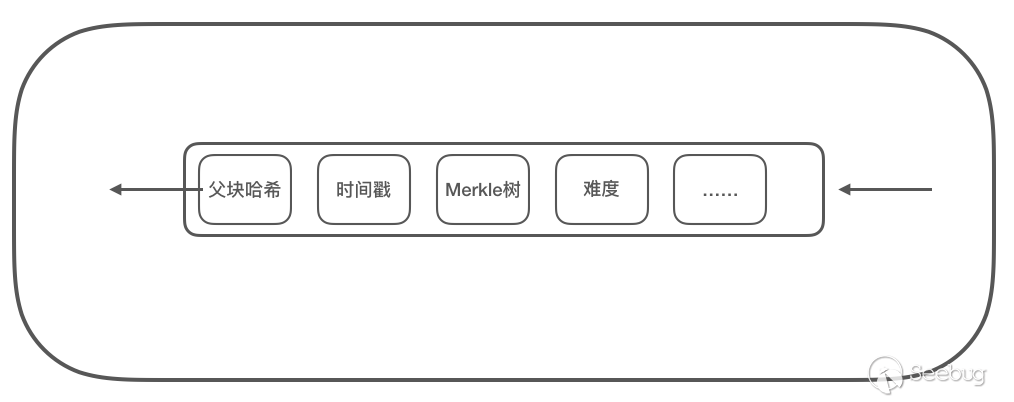
code>>>>
在比特币中,区块由区块头和 Merkle 交易树组成,区块头数据结构定义在 primitives/block.h,如下:

<<<<
0x06 网络通信
那么在区块链中,各个节点之间是如何传递数据的呢?相对于分布式数据库 server-client 网络结构,采用主从复制的方式同步数据,区块链则是 peer-to-peer 的网络结构,节点在获取数据的同时,还需要提供数据给其他节点。
我们直接来看看比特币中 p2p 协议的实现方式。
code>>>>
在比特币中,默认在 8333 端口建立 tcp 监听,启动 p2p 服务。在 bitcoind 启动流程的 init.cpp/AppInitMain() 中,对网络进行了初始化启动:
[init.cpp/AppInitMain()]
1.node.connman->Start()
启动节点入口,网络初始化和建立
[net.cpp/Start()]
2.InitBinds()
建立网络监听
3.AddOneShot()
添加种子节点
4.&TraceThread<>......
启动五个网络处理线程p2p网络处理流程就由这五个线程进行负责:
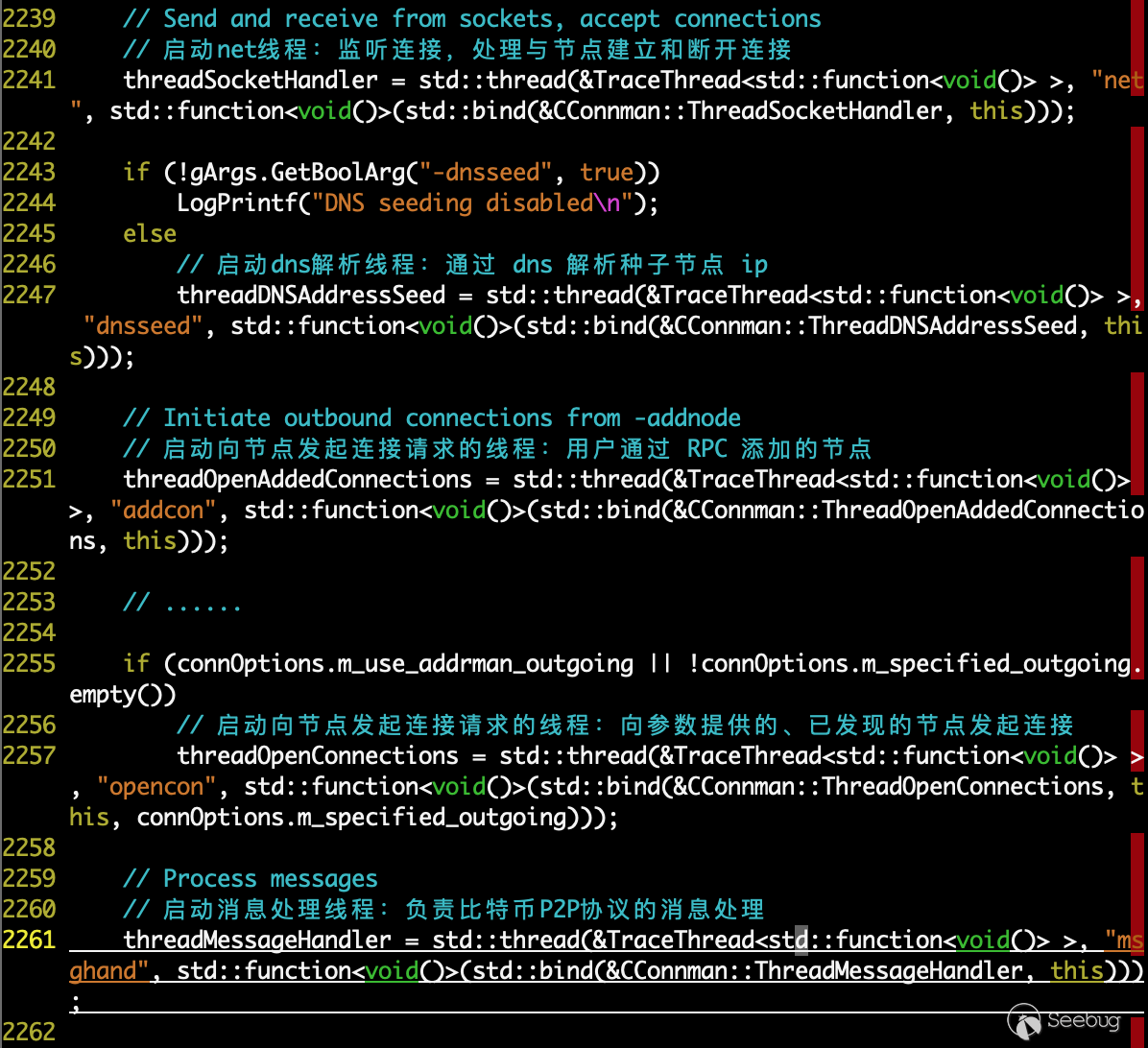
其中负责 p2p 协议处理的线程就是 ThreadMessageHandler() 线程,我们主要来看看这一部分的流程;在该线程中尝试对每个节点接收数据,接收到数据就如下的调用流程:
[net_processing.cpp]
ProcessMessages()->ProcessMessage()在 ProcessMessages() 对协议格式进行判断,比特币中 p2p 协议格式如下:

随后进入到 ProcessMessage() 进行实际的消息处理流程,在该函数中主要逻辑是多个 if-else 语句根据 commmand 进入不同的消息的处理流程,支持的消息有:
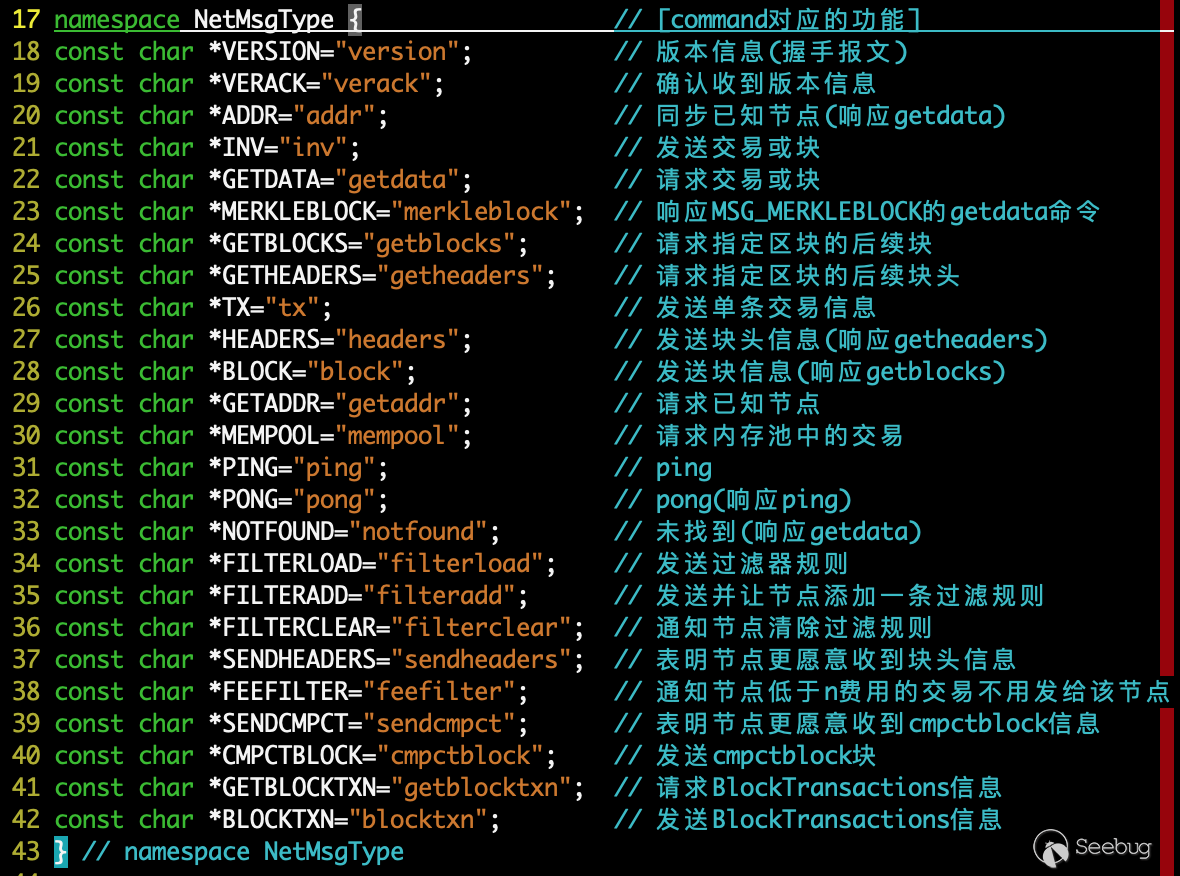
每个命令下都有不同报文格式和处理逻辑,比特币通过这样的方式,打通了节点间的通道。
<<<<
0x07 总结
通过本文我们在脱离数字货币的情况下,从分布式数据库的角度,聊了些区块链中的几个技术点,了解到区块链与传统分布式的异同之处,也了解到区块链中的基本概念和原理。
区块链的去中心化、不可篡改性的特性,给我们提供了无限的遐想,但目前还没有公开的、完善的区块链项目出现,我们希望这一天能早点到来。
References:
1. 《区块链技术指南》
2. 《白话区块链》
3. 《区块链原理、设计与应用》
4. https://bitcoin.org/bitcoin.pdf
5. https://101blockchains.com/blockchain-vs-database-the-difference/
6. https://groups.csail.mit.edu/tds/papers/Lynch/jacm85.pdf
7. https://medium.com/ultrain-chain/the-difference-between-blockchain-and-a-distributed-database-556f8361e6b3
8. http://pmg.csail.mit.edu/papers/osdi99.pdf
9. https://github.com/bitcoin/bitcoin
10. https://zh.wikipedia.org/wiki/%E6%8B%9C%E5%8D%A0%E5%BA%AD%E5%B0%86%E5%86%9B%E9%97%AE%E9%A2%98
11. https://www.zhihu.com/question/264717547
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1110/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1110/