



官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

如何寻找所有js文件
在我们挖掘src的时候很多都是登录页面,我们知道很多js文件需要你登录后才可以加载出来,但是如果对方是webpack打包的网站,他的js文件命名格式都是像下面这样,其他或者chunk-XXX格式之类的
我们可以全局搜索已经加载出来的js文件特征,我们可以看的全部的js文件都被写在这里了
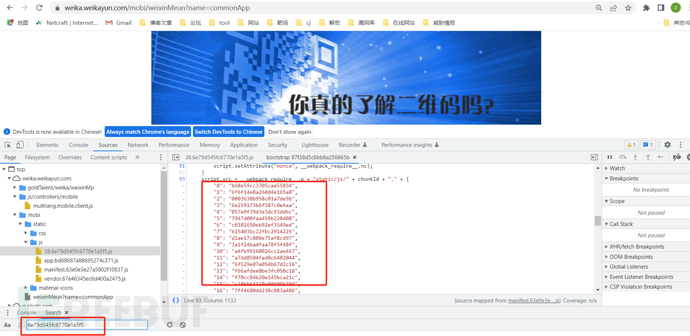
下面就可以写脚本爬取所有js文件,根据接口格式来爬全部接口,接口我们可以bp抓登录接口,然后全局搜索一下来观察它的命名格式


py脚本
把js路径全部复制一下,删除引号等相关字符

然后写个脚本批量爬一下
import requests
import re
result = set()#创建的是集合来去重
with open('js.txt','r') as file:
for line in file:
line = line.strip()
r = requests.get('https://xxx.xxx.com/static/js/'+line,verify=False)#加载所有js文件
#print(r.text)
data = re.findall(r'url: "(.*?)"', r.text)#正则表达式来匹配所有接口
print(data)
for url in data:
result.add(url)#将结果添加到集合当中
list = []
#这里是统一前面添加斜杠,因为有的奇葩网站有的接口前面有/,有的没有
for url in result:
if not url.startswith('/'):
url = '/'+result
list.append(url)
#将结果导出到99999.txt
with open('99999.txt','a') as output_file:
for url in list:
output_file.write(url+'\n')效果如下图

接下来可以用burp来进行批量fuzz测试,fuzz一些参数来测试未授权之类的一些漏洞