引言在网络安全的世界里,我们习惯于处理复杂的数据和不断变化的威胁。但是,当这些经验与人工智能的强大能力相结合时,我们能够开辟出全新的解决方案和应对策略。特别是,大型语言模型(LLM)的出现,如Open 2023-11-27 18:1:24 Author: M01N Team(查看原文) 阅读量:23 收藏
引言
在网络安全的世界里,我们习惯于处理复杂的数据和不断变化的威胁。但是,当这些经验与人工智能的强大能力相结合时,我们能够开辟出全新的解决方案和应对策略。特别是,大型语言模型(LLM)的出现,如OpenAI的GPT系列,已经彻底改变了我们处理语言和文本的方式。这些模型通过在海量数据上的训练,不仅能够理解和生成人类语言,而且为各种应用提供了前所未有的可能性。
然而,LLM在处理特定、复杂的查询时仍面临挑战,尤其是当所需信息超出其训练数据范围时。这就是检索增强生成(RAG)技术的意义所在。在这篇文章中,我将带领大家深入探索RAG的基本概念、技术背景,以及如何利用Langchain来实现对MITRE ATT&CK攻击知识库的高效问答。无论您是网络安全和AI领域的新人还是专家,我相信本文的探索都会为您带来新的启发和理解。
01 RAG的技术背景
在深入了解RAG之前,让我们先回顾一下大型语言模型(LLM)的基本原理。LLM,如GPT系列,通过在大量文本数据上进行训练,学会了理解和生成人类语言。这些模型的强大之处在于它们的多功能性和适应性,能够在诸如文本生成、摘要、翻译等多种任务上表现出色。
然而,LLM在处理特定领域或高度专业化的查询时可能会遇到局限性。例如,当询问的信息超出了模型训练数据的范围,或者需要最新的数据时,LLM可能会出现幻觉也就无法提供准确的答案。传统意义上,神经网络通过微调模型来适应特定领域或专有信息。虽然这种技术效果显著,但它需要大量的计算资源,成本高昂,并且需要专业技术知识,这使得它在适应不断演变的信息方面显得不够灵活。
2020年,检索增强生成(Retrieval-Augmented Generation, RAG)技术被提出,这一技术巧妙地结合了生成模型的强大能力与检索模块的灵活性。它能够动态地从外部知识源检索信息,显著提升了回答的准确性和相关性。这一过程有些类似于人类进行开卷考试:重点在于考察学生的推理能力,而非单纯记忆特定信息的能力。这种方法不仅极大地提高了模型的适应性,还扩展了其在各种应用场景中的有效性,尤其是在像网络安全这样快速发展和不断变化的领域。另外,将事实性知识与LLM的推理能力分离,存储在外部知识源中,可以更方便地进行访问和更新,这里就需要理解参数知识和非参数知识的区别。
参数知识是在LLM训练过程中学习到的,隐含地存储在神经网络的权重中。这种知识代表了模型对大量训练数据的理解和概括,是模型生成回答的基础。与此相对的是非参数知识,它存储在外部知识源中,如向量数据库。这种知识不是通过训练直接编码到模型中,而是作为额外的、可更新的信息源。非参数知识使得LLM能够访问和利用最新的或特定领域的信息,从而提高回答的准确性和相关性。
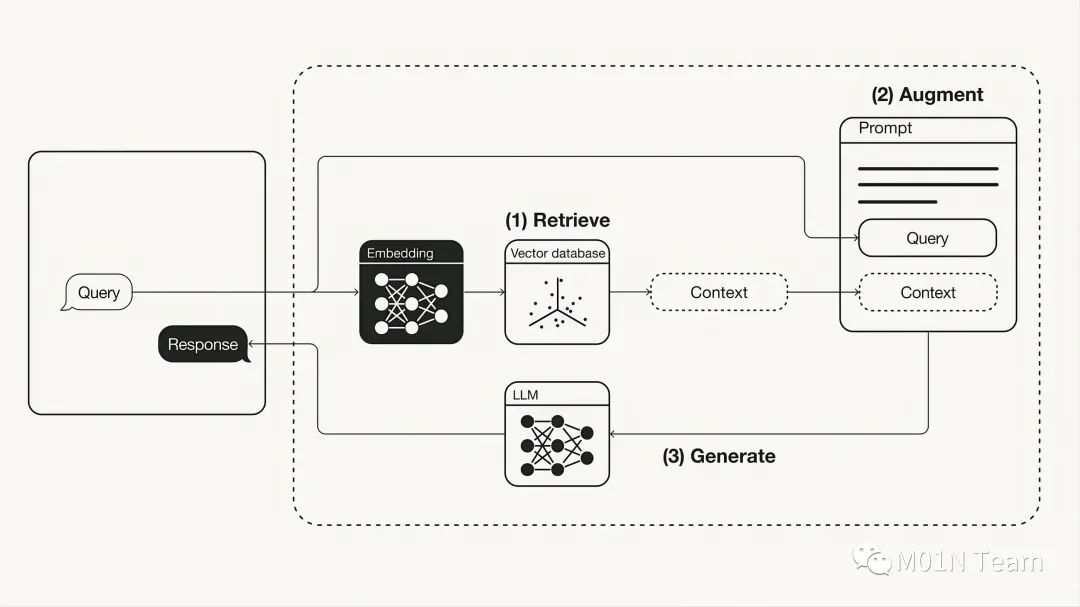
RAG的工作流程主要包括以下几个步骤:
检索(Retrieve):使用用户查询从外部知识源检索相关上下文。这一步骤通过将用户查询嵌入到与向量数据库中的额外上下文相同的向量空间中来实现,从而进行相似性搜索,并返回最接近的数据对象。
增强(Augment):将用户查询和检索到的额外上下文结合到提示模板中。
生成(Generate):最后,将增强后的提示输入到LLM中,生成回答。
通过这种方式,RAG结合了LLM的推理能力和外部知识源的实时更新能力,使得生成的回答既准确又相关。
02 使用LangChain实现RAG
MITRE ATT&CK框架知识库记录和分类了网络攻击的战术和技术,提供了关于网络攻击者的行为模式、常用的攻击手段以及攻击武器工具等详细信息。这里我讲介绍如何结合ChatGPT和LangChain以及Weaviate 向量数据库和OpenAI的嵌入模型创建RAG管道,实现一个ATT&CK知识增强的Chatbot。它将有助于我们网络安全从业者更好地利用ATT&CK知识库进行攻击技战术学习、威胁情报的查询分析,进而更好地适应企业安全运营和攻防能力建设等方面的工作。
第一步:数据准备和存储
MITRE官方在GitHub上公开有最新版本的ATT&CK资源库,是一个符合STIX 2.1标准的JSON数据集文件,在本次实践中我们使用enterprise-attack-14.1.json(39.8MB)。由于单文件比较大,无法完全适应LLM的上下文窗口,因此需要对文件进行分块处理。首先我们进行数据的加载,LangChain有许多内置的DocumentLoader,这里使用JSONLoader,如果是要加载文本则可以使用TextLoader。
由于原始状态下的Document太长,我们还需要进行数据分块,LangChain也内置了许多用于此目的的文本分割器。这里也可以使用CharacterTextSplitter,并设置chunk_size(块大小)为大约1000,chunk_overlap(块重叠)为20,以保持文本在各个块之间的连续性。
最后进行嵌入和存储。为了实现对文本块的语义搜索,这里需要为每个块生成向量嵌入,并将它们连同其嵌入一起存储,可以使用OpenAI的嵌入模型。而要存储这些嵌入数据,可以使用Weaviate这种向量数据库。
OpenAI的嵌入模型是基于先进的深度学习技术,它能够将复杂的文本信息转换为数学向量。这些向量不仅仅捕捉文字的表面意义,更重要的是,它们揭示了文本的深层语义。这种转换为机器提供了理解和处理自然语言的能力,是现代自然语言处理技术的核心。
在我们的应用中,这意味着无论是对ATT&CK知识库的深入分析,还是对网络安全相关查询的精准回答,OpenAI的嵌入模型都能提供强大的支持。通过这种方式,我们能够确保即使是最复杂的查询也能得到准确和全面的回答。
而向量化数据库是专为存储和检索由机器学习模型生成的高维向量数据而设计。与传统数据库相比,它们在处理这类特殊数据时更加高效和灵活。它不仅能够快速地在大规模向量数据中找到最相关的信息,还能够灵活地适应不断变化的数据需求。这对于实现对ATT&CK知识库的高效和精准访问尤为重要。
第二步:知识检索
知识检索是从大量数据中寻找与特定查询相关的信息的过程,这一步骤至关重要,因为它直接影响到后续的提示增强和内容生成的质量。在完成填充向量数据库后,就可以定义检索器了,使用Weaviate的Python客户端根据用户查询和嵌入块之间的语义相似性获取附加上下文。以下示例使用比较固定的查询语句。
第三步:提示增强
提示增强是指在原始查询的基础上添加额外信息以提高回答的质量和准确性的过程。这里编写一个简单的提示词模板,使用附加上下文来增强提示,同时避免生成幻觉。
第四步:内容生成
内容生成是整个系统的核心,它负责将检索到的信息和增强后的提示词结合起来,生成准确、相关且流畅的回答。在我们的系统中,这一过程通过构建一个Retrieval-Augmented Generation (RAG)链来实现,这个链条将检索器、提示词模板和大型语言模型(LLM)紧密地结合在一起,形成一个高效的工作流。
03 总结
网络安全领域高度依赖网络攻防专家的经验和知识,同时网络威胁的动态性意味着安全从业者必须紧跟快速变化的战术、技术和过程。LLM和AIGC技术的兴起必然对网络安全产生深远影响。本文通过探索Retrieval-Augmented Generation (RAG)技术实现对MITRE ATT&CK知识库增强的智能问答能力,当然网络安全领域还有更多的LLM应用场景值得去探索,LLM和AIGC技术也将在网络安全领域释放出巨大潜力,我们期待未来能为网络安全领域带来更多创新和突破。
附录 参考文献
[1] https://towardsdatascience.com/retrieval-augmented-generation-rag-from-theory-to-langchain-implementation-4e9bd5f6a4f2
[2] https://arxiv.org/abs/2005.11401
绿盟科技天元实验室专注于新型实战化攻防对抗技术研究。
研究目标包括:漏洞利用技术、防御绕过技术、攻击隐匿技术、攻击持久化技术等蓝军技术,以及攻击技战术、攻击框架的研究。涵盖Web安全、终端安全、AD安全、云安全等多个技术领域的攻击技术研究,以及工业互联网、车联网等业务场景的攻击技术研究。通过研究攻击对抗技术,从攻击视角提供识别风险的方法和手段,为威胁对抗提供决策支撑。
M01N Team公众号
聚焦高级攻防对抗热点技术
绿盟科技蓝军技术研究战队
官方攻防交流群
网络安全一手资讯
攻防技术答疑解惑
扫码加好友即可拉群
如有侵权请联系:admin#unsafe.sh