
2023-12-16 07:18:0 Author: www.cnblogs.com(查看原文) 阅读量:10 收藏
构建能够感知现实世界多种模态信信号,并解决各种任务的通用模型,是人工智能领域一个吸引人的目标。
在本文中,我们介绍了ChatBridge,这是一个新颖的多模态语言模型,它利用语言的表达能力作为催化剂,来弥合不同模态之间的差距。我们证明,只需要使用双模态的语言配对数据(image-text、video-text、audio-text)进行训练就足以连接所有模态。
ChatBridge在开源大型语言模型(LLM)(Vicuna-13B)的基础上进行构建,融合了多样的多模态输入,扩展了它的多模态零样本能力。
ChatBridge经历了两阶段的训练。
- 第一阶段将每种模态与语言对齐,这带来了多模态间的关联和协作能力。
- 第二阶段通过指令微调ChatBridge,使其与用户意图对齐,我们提出了一个新的多模态指令调整数据集,名为MULTIS,它涵盖了文本、图像、视频和音频模态的16种多模态任务的广泛范围。
我们在涵盖文本、图像、视频和音频模态的零样本多模态任务上展示了强大的定量和定性实验结果。
参考链接:
https://iva-chatbridge.github.io/
人类通过多种方式与世界互动——我们看见物体、听见声音、感受纹理、闻到气味、说出单词等等。通过利用每种方式提供的互补信息,我们获得了对周围环境的全面理解。为了使人工智能能够在自然环境中完成各种真实世界的任务,它需要能够解释、关联并推理来自多种方式的信息。
在这篇论文中,我们介绍了ChatBridge,这是一个统一的多模态模型,它利用先进的大型语言模型(LLM)作为语言催化剂,来解释、关联和推理关于不同方式的信息,并且能够通过多轮对话执行零样本人类指令任务。像ChatGPT、GPT-4和LLAMA这样的大型语言模型,在理解和生成类人文本方面表现出非凡的能力。它们表明,语言可以作为通用助手的通用界面,各种任务可以在语言中明确表示和响应。通过扩展LLMs的能力以包括多样化的多模态输入,我们设计了一种多模态语言模型,它不仅能够感知现实世界的多种方式,还可以遵循指令、思考并用自然语言与人类互动。
我们的方法不需要所有方式同时出现的数据集。相反,我们利用语言作为催化剂来连接各种方式,我们只需要容易获取的、与语言配对的双模态数据(例如,图像-文本对、视频-文本对、音频-文本对等)。这种策略导致了跨所有方式的多模态关联和协作的出现,实现了在没有明确配对训练数据的情况下对多模态输入的零样本感知能力(例如,罕见的视频-音频-文本三重数据,其中文本描述同时涉及视频和音频内容)。
ChatBridge 是一个多模态语言模型,能够感知现实世界的多模态信息,并且能够按照指令进行思考和用自然语言与人类互动。受到Flamingo和BLIP-2的启发,我们引入了感知模块来连接编码器和大型语言模型(LLM)。我们选择了开源的Vicuna-13B作为LLM,它基于LLaMA构建,并据报告在GPT-4的评估中达到了ChatGPT质量的90%。至于特定模态的编码器,我们选择了EVA-ViT-G作为图像和视频编码器,以及BEAT作为音频编码器来编码音频。
- 第一阶段:将每个模态与语言连接起来,利用大规模的与语言配对的双模态数据进行多模态对齐训练,包括图像-文本、视频-文本和音频-文本配对。
- 第二阶段:多模态指令调整,利用多模态指令数据集MULTIS对ChatBridge进行指令微调,使模型与用户意图对齐,从而在多模态任务上实现更有效的零样本泛化。
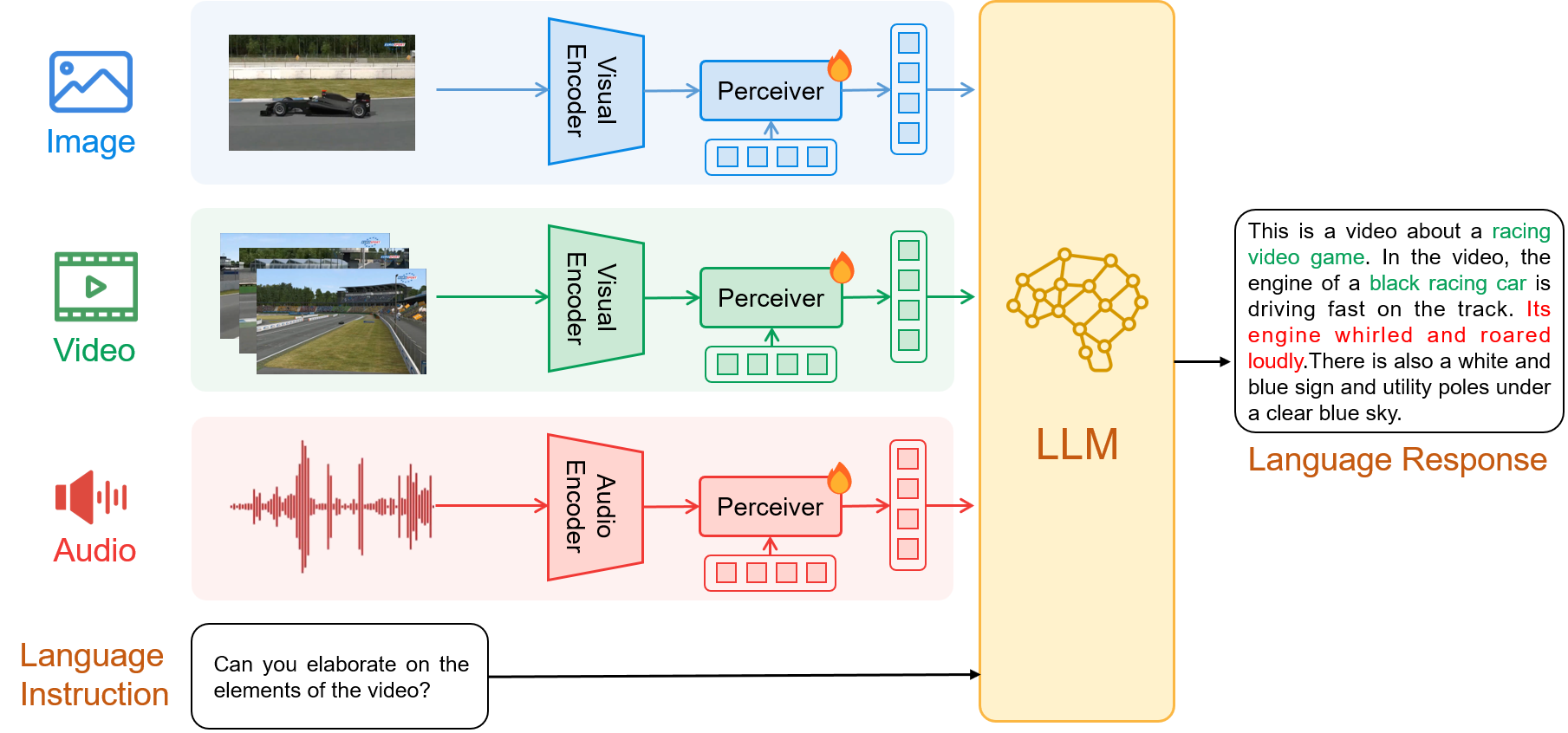
0x1:Architecture Overview
如上图所示,ChatBridge包含多个模态特定的编码器和感知模块,以及transformer-decoder-based LLM。
受到Flamingo和BLIP-2的启发,我们引入了感知模块来桥接编码器和LLM。
编码器嵌入作为输入。
感知模块使用给定数量的learnable query tokens,总结了每个编码器输出的可变长度嵌入。因此,它为所有模态产生了相同形状的输出。同时,由于query tokens的数量远小于编码器特征的大小,它显著降低了在LLM中的计算成本。我们将感知模块实例化为一个具有learnable query tokens的transformer decoder.
来自第 i 个模态的信息 Xi 首先被送入编码器 hi 以提取其特征。然后,每个具有learnable query Hi 的感知模块 ρi 将它们转换为共享的隐空间:
![]()
给定所有多模态输入和人类指令Xinstruction作为输入,大型语言模型(LLM)f 通过以下方式生成最终的响应文本序列Y:
![]()
具体而言,我们选择了基于LLaMA构建的开源Vicuna-13B作为大型语言模型(LLM),据GPT-4的评估报告显示,它能够达到ChatGPT质量的90%。
至于模态特定的编码器,我们选择
- ViT-G作为视觉编码器去编码图像和视频。我们从每个视频中采样4帧,并将它们各自的帧特征串联起来,形成视频特征,这些是视频感知器的输入。
- BEAT作为音频编码器去编码音频。对于每个音频,我们将其分成10秒间隔的片段,然后串联这些片段的特征以创建音频特征。
我们使用一个共享的感知器处理所有模态,而每种模态都有其独立的可学习查询令牌(learnable query tokens)。
由于计算资源有限,我们在整个训练过程中只训练感知器及其可学习的查询令牌,同时保持编码器和LLM在训练期间不变。
0x2:Two-stage Training
受到基于预训练GPT-3.5构建的ChatGPT的启发,ChatBridge同样经历了在大规模语言配对的双模态数据上的两阶段训练,以及自建的多模态指令跟随数据的训练。
1、Stage1:Multimodal Alignment
在第一阶段,我们预训练ChatBridge以使每个模态与语言对齐,这带来了与LLM紧密结合的涌现多模态相关性和协作能力,LLM在这里充当语言催化剂。我们利用大规模的语言配对的双模态数据进行多模态对齐训练,包括图像-文本、视频-文本以及音频-文本对。
具体来说,训练数据包括
- 公开可用的图像-文本对数据集(包括MS-COCO、SBU Captions、Conceptual Captions、LAION-115M)
- Webvid10M的视频-文本对
- WavCaps的音频-文本对
原始的单模态数据(即图像、视频、音频)被顺序地送入特定模态的编码器和感知器中,以获取单模态嵌入。
LLM在这一训练阶段的输入格式是:
![]()
”<unimodal input>“是由感知器生成的单模态嵌入序列,可以被看作是软提示。
语言模型(LLM)直接将”<unimodal input>“作为输入,并在训练样本中被训练以输出相应的文本”<text>“。
在这个训练阶段,我们训练了150k步,使用批次大小为256,在8个A100 GPU上进行训练。
2、Stage2:Multimodal Instruction Tuning
在使用LLM对单模态数据进行对齐之后,我们的模型已经具备了理解不同模态信息的基本能力。然而,模型仍然需要提高处理不同模态和遵循人类指令的能力。一些先前的方法已经证明,通过指令来调整大型模型可以帮助它理解人类的意图。受到这些方法的启发,在第二阶段的训练中,我们进一步对ChatBridge进行指令微调,以使模型在广泛的多模态任务上与用户意图对齐,从而实现多模态任务上更有效的零样本泛化。为此,我们仔细收集了一个多模态指令微调数据集来微调我们的模型,其中的指令是多模态的,包含文本、图像、视频和音频,而响应仅为文本。
我们以以下标准格式组织了所有样本:
![]()
其中”<multimodal input prompt>“是一些人工制作的prompt提示,它结合了感知器中的多个单模态嵌入序列。
LLM吞吐整个序列,并被训练以输出正确的响应。这一训练阶段在8块A100 GPU上使用4k令牌的批量大小,共进行了10k步骤。
0x3:Multimodal Instruction Tuning Dataset — MULTIS
我们开发了一个用于多模态指令微调的多样化数据集,名为MULTIS,用来对ChatBridge模型进行指令微调。MULTIS包含两个不同的部分:
- 任务特定数据
- 多模态聊天数据
前者提供需要简洁回应的标准化任务,而后者通过特色的开放式对话模拟人与多模态助手之间解决现实世界问题的场景。
如下图所示,MULTIS的整个收集涵盖了16个多模态任务类别和15个来源数据集。我们保留了6个数据集用于模型评估目的。
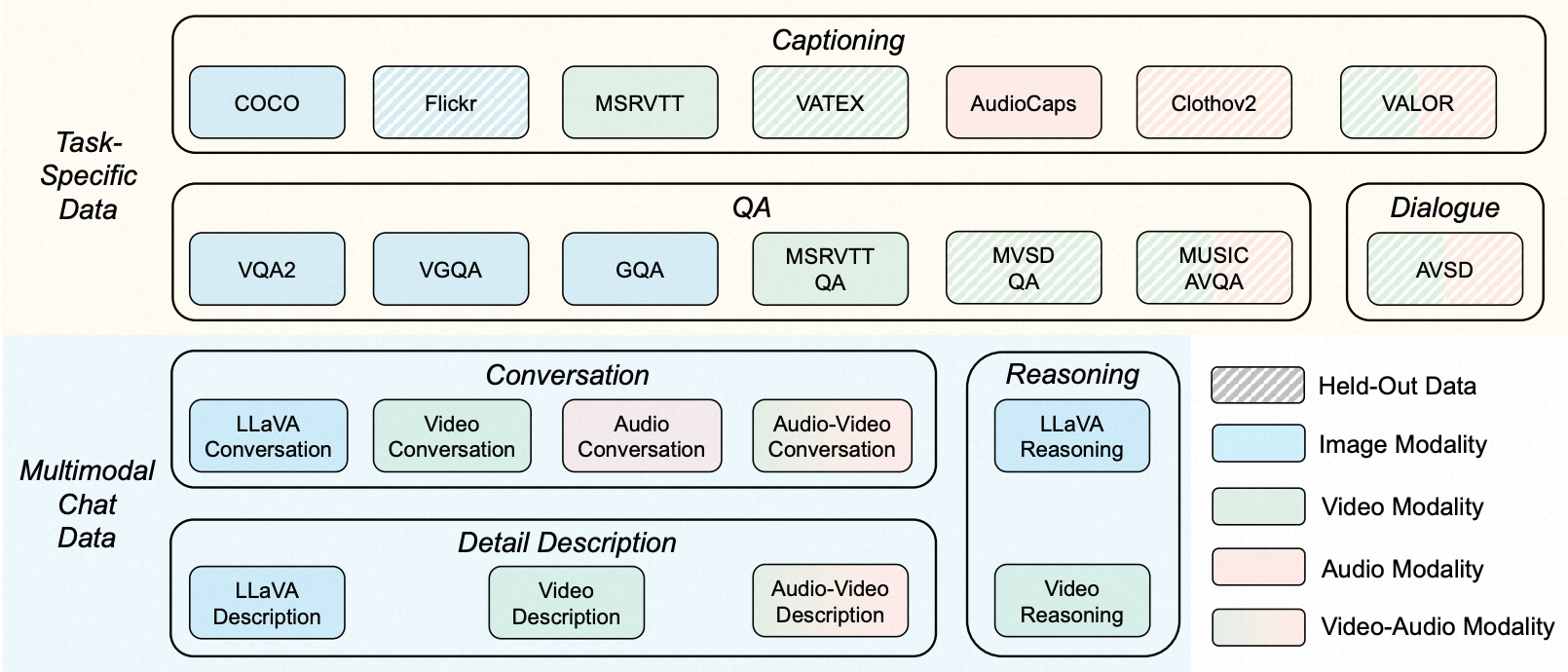
1、任务特定数据(Task-Specific Data)
我们收集了大量公开可用的人类注释的多模态数据集,并将它们转换成统一的指令微调格式。
具体来说,我们组装了大量常见的包含图像-文本、视频-文本和音频-文本配对的问答(QA)和描述数据集,包括VQAv2、VG-QA、COCO Caption、MSRVTTQA、MSRVTT Caption、AudioCaps。
对于每个任务,我们采用ChatGPT来派生10~15个独特的指令模板,然后手动过滤和细化这些模板,以确保理由和多样性是最优的。
由于公开数据集本质上偏爱较短的回应,我们设计了指令模板修饰符来指定所需的回应风格,如对于简短回答数据使用”short“和”brief“,对于描述数据使用”a sentence“和”single sentence“。
2、多模态聊天数据(Multimodal Chat Data)
虽然任务特定数据赋予了模型完成标准化任务的能力,但多模态聊天数据提供了现实世界中开放式的对话,这些对话需要更复杂的意图理解和情境推理能力,并提供了更多样化、有帮助的、类似人类的响应。
尽管由LLaVA-Instruct-150K生成的图像到文本聊天数据集存在,但跨其他模态的聊天数据仍然有限。为此,我们构建了一个包括图像、视频和音频模态的单模态和多模态输入的多模态聊天数据集。
我们采用LLaVA-Instruct-150K作为图像聊天数据。为了加入额外的模态,即视频、音频和视频-音频内容,我们设计了一个由离线开源模型和ChatGPT协助的流水线,如下图所示。
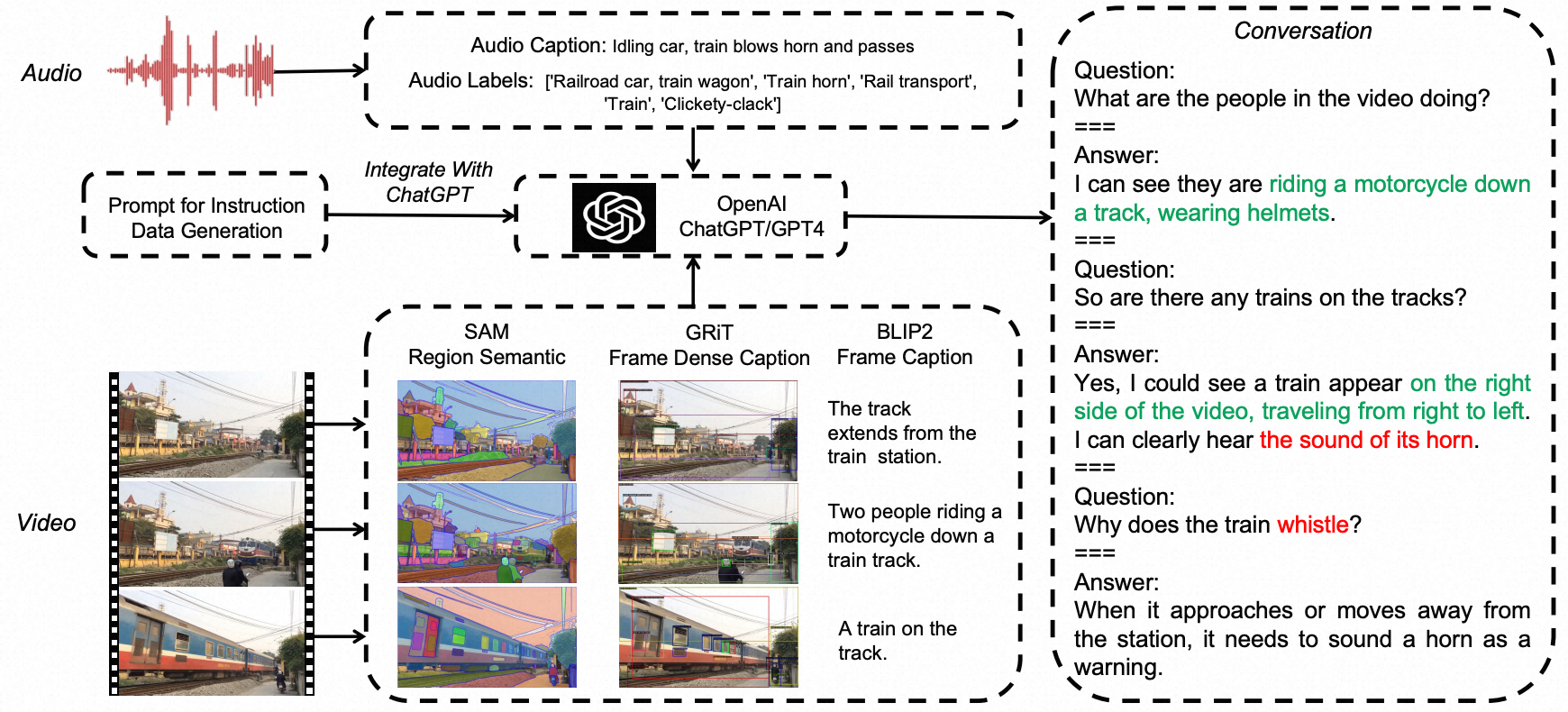
我们生成了包括对话、详细描述和复杂推理的三种类型的指令跟随数据。
我们从MSRVTT数据集中获取视频,从AudioCaps获取音频,从VALOR获取视频-音频。为了向仅支持文本的ChatGPT或GPT-4进行Prompt询问,我们将这些非文本模态转换为文本描述。具体来说,
- 对于每个视频,我们提取三个帧,并使用Semantic-SAM、GRIT和BLIP-2来开发帧的区域语义、区域描述和帧描述级别的注释。然后我们使用手工制作的Prompt提示,将这些帧注释按时间顺序与人类注释的视频描述结合起来。
- 对于每个音频,我们使用原始数据集中的音频描述和标签。我们将这些细粒度和全局描述的集合与手动设计的种子示例结合起来,以在上下文学习(in-context-learning)的方式查询ChatGPT或GPT-4。
通过上述流水线,我们收集了包括24k对话、18K详细描述和9k复杂推理的视频、音频和视频-音频多模态聊天样本。
综上所述,MULTIS包含了440万个任务特定样本和20.9万个多模态聊天样本。
0x4:Examples of multimodal chat
1、Audio+Video Input
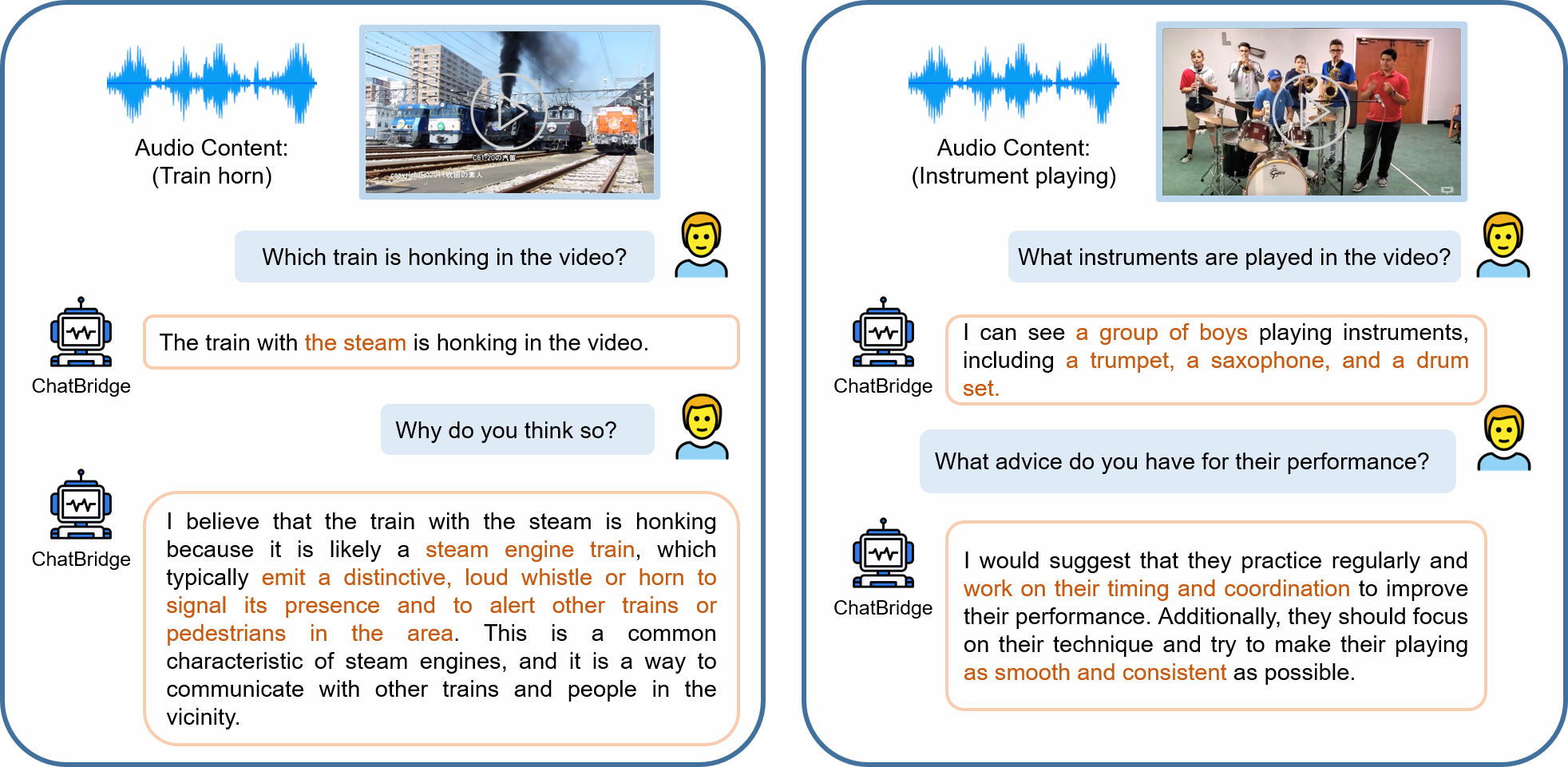
2、Audio+Image Input

3、Image Input

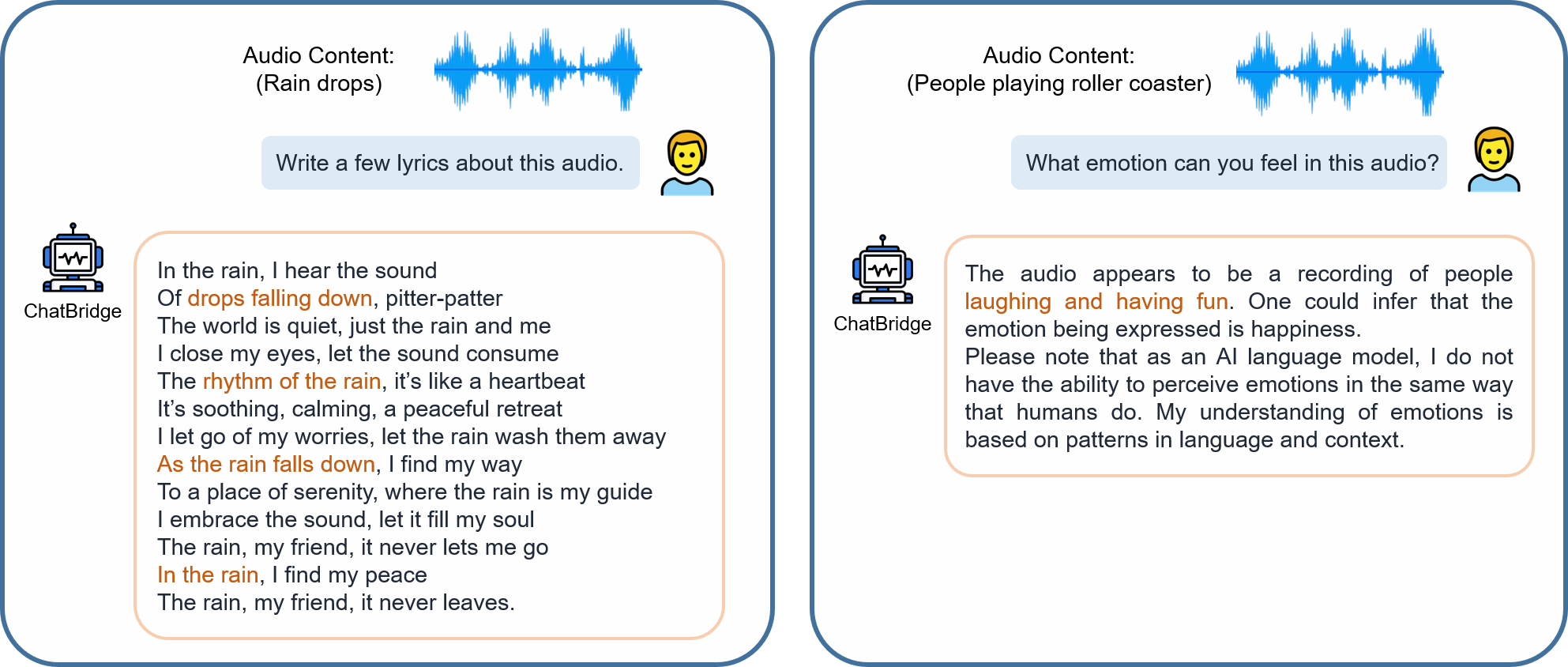
4、Audio Input
5、Video Input

参考链接:
https://github.com/joez17/ChatBridge https://arxiv.org/pdf/2305.16103.pdf
如有侵权请联系:admin#unsafe.sh