一. 引言
近年来,深度神经网络模型在计算机视觉识别、语音识别、自然语言处理等领域取得了巨大的成功。但是受限于较高的计算复杂度和较大的存储需求,深度模型的部署在有限资源设备上面临着诸多挑战,因此相继出现了各种模型压缩和加速技术。其中知识蒸馏是一种典型的方法,它能从一个大的教师模型中学习到一个小的学生模型,受到了工业界和学术界的广泛关注。
本文介绍一篇知识蒸馏的研究综述【1】,从知识迁移的不同角度进行介绍,包括各种类型的知识、蒸馏方案、蒸馏算法等,共分为上、下两篇,本篇为上篇,希望各位能从中受益并引发更多思考。
二.典型的蒸馏算法
目前已经提出了多种不同的算法来改进复杂环境下的知识迁移过程,本节将回顾在知识蒸馏领域提出的典型的知识迁移的方法。
2.1
对抗蒸馏
在知识蒸馏中,教师模型很难完美地从真实的数据分布中学习,而且学生模型的容量很小,无法准确地模仿教师模型。由于对抗学习获得了广泛地关注,其中判别器评估一个样本来自训练数据分布的概率,而生成器试图使用生成的数据样本欺骗判别器,受此启发,许多对抗性的知识蒸馏方法被提出,以使师生模型能更好地理解真实的数据分布。
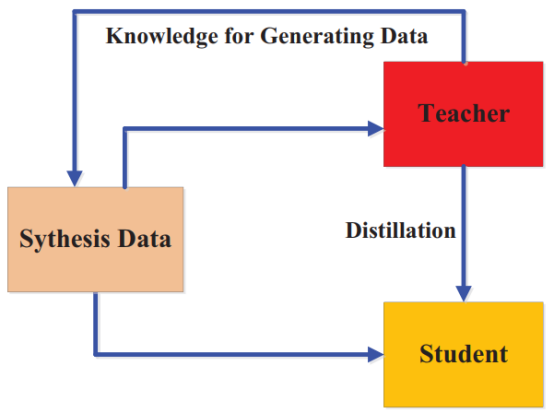
如图1所示,基于对抗蒸馏的方法可以分为三种:第一种,训练一个生成器来生成数据,用于训练数据集或增强训练集;第二种,为了学生模型更好地匹配教师模型,判别器通过使用logits或特征来区分师生样本数据;第三种,对抗蒸馏以在线方式进行,每次迭代中师生模型共同优化。因此,对抗学习不仅可以增强学生模型的学习能力,而且它和知识蒸馏的联合可以生成有价值的数据,克服数据不可用或不可访问的限制,知识蒸馏还可以用来压缩生成对抗网络。
图1 三种主要的对抗蒸馏方法
2.2
多教师蒸馏
不同的教师模型可以为学生模型提供不同的知识,教师模型可以单独或整体地用于训练学生模型,最简单的方法是使用所有教师模型的平均响应来监督学生模型。多教师蒸馏的通用框架如图2所示,然而如何有效地整合来自多个教师模型的不同类型的知识还需要进一步研究。
图2 多教师蒸馏的通用框架
2.3
跨模态蒸馏
某些模态的数据或标签在训练或测试期间可能无法获得,所以在不同的模态之间传递知识是很重要的。跨模态蒸馏的一般框架如图3所示。
图3 跨模态蒸馏的通用框架
目前,跨模态知识蒸馏在视觉识别任务重表现良好,但是当存在模态差距如缺乏不同模态之间的成对样本时,跨模态知识迁移是一项具有挑战性的研究。
2.4
基于图的蒸馏
大多数知识蒸馏方法都侧重于将单个实例知识传递给学生,而最近提出了一些使用图来探索数据内部关系的方法,主要思想是利用图作为教师知识的载体并利用图来控制教师知识的信息传递。基于图的蒸馏的通用框架如图4所示。每个顶点代表一个自监督的教师模型,使用logits和特征构造两个图,将多个自监督教师模型的知识传递给学生。
图4 基于图的蒸馏的通用框架
基于图的蒸馏可以传递数据的信息结构知识,然而如何正确地构造图来建模数据的结构知识仍然是一个具有挑战性的研究。
2.5
基于注意力的蒸馏
由于注意力可以很好地反映神经网络中神经元的激活情况,所以知识蒸馏中使用一些注意力机制来提高学生模型的性能。其中注意力迁移的核心是在神经网络各层中定义用于特征嵌入的attention-map。
2.6
无数据蒸馏
为了克服由于隐私、合法性、安全性和机密性等而导致的数据不可用问题,无数据蒸馏方法被提出,意味着没有训练数据,类似于零采样学习,数据是利用教师模型的特征表示信息生成的,如图5所示。但是如何生成高质量的多样化训练数据并提高模型的泛化能力仍然具有挑战性。
图5 无数据蒸馏的通用框架
2.7
量化蒸馏
网络量化通过将高精度网络转换为低精度网络来降低神经网络的计算复杂度,而知识蒸馏的目标是训练小模型使其与复杂模型性能相当,因此基于量化的知识蒸馏方法被提出,其框架如图6所示。
图6 量化蒸馏的通用框架
2.8
终生蒸馏
终生学习包括持续学习、连续学习和元学习,目标是像人类一样学习,它积累以前学到的知识并将其迁移到未来的学习中。基于终身学习,知识蒸馏也提供了这样一种有效的方法来保存和迁移所学的知识并避免灾难性遗忘
2.9
基于神经结构搜索的蒸馏
神经结构搜索是目前最流行的自动机器学习技术之一,目标是自动识别深度神经网络模型并自适应学习合适的神经网络结构。知识蒸馏中知识迁移不仅取决于教师模型的知识,也取决于学生模型的结构,为了解决两者之间的性能差异,基于神经结构搜索的蒸馏方法被提出,同时知识蒸馏也能提高神经结构搜索的效率。
三.讨论
知识蒸馏作为一种有效地深度神经网络压缩和加速技术,已广泛应用于人工智能的各个领域,包括视觉识别、语音识别、自然语言处理和推荐系统,此外,还可以用于数据隐私和对抗攻击的防御。但是目前知识蒸馏仍然面临着一些挑战:
1.大多数知识蒸馏方法利用不同类型知识的组合,而每一种知识的影响和不同类型知识之间的相互作用是复杂的,如基于响应的知识具有和平滑标签、正则化相似的动机,基于特征的知识通常用于模拟教师模型的中间过程,基于关系的知识则用于捕获不同样本之间的关系。因此在一个统一的框架中对不同类型知识进行建模仍然是一个挑战;
2. 如何将丰富的知识从教师模型迁移到学生模型是知识蒸馏的关键,离线蒸馏通常用于复杂教师模型知识的迁移,而使用在线蒸馏和自蒸馏时教师模型和学生模型的性能相近。因此模型复杂度和各种蒸馏方法之间的关系需要进一步研究;
3. 目前大多数蒸馏方法集中在新型知识或蒸馏损失函数的设计,而对师生架构的设计研究较少,但是学生模型可能因为和教师模型之间的性能差异而导致学到的东西很少,因此设计一个有效的学生模型或教师模型仍然具有挑战性;
4. 尽管知识蒸馏的方法和应用非常多,但对知识蒸馏的理论解释和实验验证评价仍然不足,特别是衡量知识或师生结构的质量仍然非常困难。
为了提高知识蒸馏的性能,最重要的是采用什么师生网络结构、从教师模型中学习什么知识和如何蒸馏。因此未来还有一些可能的研究方向:
5. 深度神经网路的模型压缩和加速方法通常分为参数剪枝和共享、低秩分解、紧凑卷积核和知识蒸馏,目前讨论知识蒸馏和其他压缩方法结合的工作很少,而混合压缩方法是很有必要的,此外如何确定不同压缩方法的应用顺序也将是未来的一个研究问题;
6. 由于师生结构知识迁移的特性,除了对深度神经网络进行加速压缩外,知识蒸馏目前已被用于数据隐私保护、对抗攻击、跨模态、灾难性遗忘、加速学习、神经结构搜索加速、自监督和数据增强等领域,因此知识蒸馏扩展到其他应用可能是一个有意义的方向;
7. 知识蒸馏类似于人类的学习,所以将其推广到经典和传统的机器学习方法是可行的,也可以将其灵活地部署到各种学习方案中,如对抗学习。自动机器学习、终身学习和强化学习等,因此将知识蒸馏与其他学习方案结合将有助于解决未来的实际挑战。
参考文献
[1] Gou J , Yu B , Maybank S J ,et al.Knowledge Distillation: A Survey[J]. 2020.DOI:10.1007/s11263-021-01453-z.
内容编辑:创新研究院 王萌
责任编辑:创新研究院 舒展
本公众号原创文章仅代表作者观点,不代表绿盟科技立场。所有原创内容版权均属绿盟科技研究通讯。未经授权,严禁任何媒体以及微信公众号复制、转载、摘编或以其他方式使用,转载须注明来自绿盟科技研究通讯并附上本文链接。
关于我们
绿盟科技研究通讯由绿盟科技创新研究院负责运营,绿盟科技创新研究院是绿盟科技的前沿技术研究部门,包括星云实验室、天枢实验室和孵化中心。团队成员由来自清华、北大、哈工大、中科院、北邮等多所重点院校的博士和硕士组成。
绿盟科技创新研究院作为“中关村科技园区海淀园博士后工作站分站”的重要培养单位之一,与清华大学进行博士后联合培养,科研成果已涵盖各类国家课题项目、国家专利、国家标准、高水平学术论文、出版专业书籍等。
我们持续探索信息安全领域的前沿学术方向,从实践出发,结合公司资源和先进技术,实现概念级的原型系统,进而交付产品线孵化产品并创造巨大的经济价值。
长按上方二维码,即可关注我
如有侵权请联系:admin#unsafe.sh