
2023-12-19 10:56:0 Author: www.cnblogs.com(查看原文) 阅读量:9 收藏
尽管深度学习已经彻底改革了计算机视觉领域,但当前的深度学习视觉方案方法存在几个主要问题:
- 高质量的视觉数据集,制作过程耗时且成本高昂,同时只包含了有限范围的视觉概念
- 标准的深度学习视觉模型(例如ImageNet、ResNet)擅长完成单一任务,且只能完成一个任务,需要投入巨大的努力(迁移学习、stacking fine-tune)才能适应新的任务
- 在基准测试上表现良好的模型,在压力测试与泛化测试中的性能却令人失望,这让人对整个深度学习在计算机视觉领域的方法产生了怀疑。
我们提出了一种旨在解决这些问题的神经网络:它接受训练时使用了多种多样的图片,以及网络上大量可得的自然语言语料进行自监督监督训练。
通过设计,这个网络可以使用自然语言进行操控,完成多种分类基准测试,而不需提前针对基准数据集进行针对性训练优化,这类似于GPT-2和GPT-3的“零样本学习(zero-shot)”能力。
这是一个关键的变化:通过不提前针对基准数据集进行针对性训练优化,我们展示了它能够变得更具代表性。我们的系统在缩小“鲁棒性差距”方面达到了高达75%的效果,同时在不使用任何原始的128万个标注样本的情况下,与原始的ResNet-50在ImageNet零样本学习中的表现匹敌。

参考链接:
https://openai.com/research/clip
CLIP(Contrastive Language–Image Pre-training)建立在大量关于”zero-shot transfer“、”natural language supervision“、”multimodal learning“和”transfer learning“的研究基础之上。
零样本学习的理念可以追溯到十多年前,但直到最近,这一理念在计算机视觉领域主要被研究作为推广到未见过物体类别的方法。一个关键的洞见是利用自然语言作为一种灵活的预测空间,以实现泛化和转移。2013年,斯坦福大学的Richer Socher及其合作者开发了一个概念验证,通过在CIFAR-10上训练一个模型,使其在一个词向量嵌入空间中进行预测,并展示了该模型能够预测两个未见过的类别。同年,DeVISE扩展了这一方法,并证明可以对一个ImageNet模型进行微调,使其能够正确地预测原始1000训练集之外的对象。
CLIP最受启发的是FAIR的Ang Li及其合作者在2016年展示了使用自然语言监督来实现zero-shot transfer到几个现有的计算机视觉分类数据集的工作,如典型的ImageNet数据集。他们通过对一个ImageNet CNN进行微调,预测来自3000万Flickr照片的标题、描述和标签文本中更广泛的视觉概念集(视觉n-grams),并能够在ImageNet零次学习上达到11.5%的准确率。
最后,CLIP是过去一年重新审视从自然语言监督中学习视觉表示的一系列论文中的一部分。这一系列工作包括:
- 使用了更现代的架构,如Transformer,并包括VirTex,它探讨了自回归语言建模
- ICMLM,它研究了掩码语言建模
- ConVIRT,它研究了我们在CLIP中使用的相同对比目标,但应用于医学成像领域。
参考链接:
https://www.cnblogs.com/LittleHann/p/17354069.html#_label3_3_1_3
我们展示了只需扩大一个简单的预训练任务,就足以在各种各样的图像分类数据集上实现有竞争力的零样本学习性能。
我们的方法使用了一种大量可获得的监督来源:互联网上与图片配对的文本。这些数据被用来为CLIP创建以下的代理训练任务:给定一幅图像,预测在我们数据集中实际与之配对的32,768个随机采样的文本片段中的哪一个。
为了解决这个任务,我们的直觉是CLIP模型将需要学会识别图像中的各种视觉概念,并将它们与其名称关联起来。结果,CLIP模型可以应用于几乎任意的视觉分类任务。例如,如果数据集的任务是分类狗和猫的照片,我们检查每幅图像是否更可能与CLIP模型预测的文本描述“一张狗的照片”或“一张猫的照片”配对(用自然语言方式实现离散多分类任务)。
基本架构图如下所示,


CLIP pre-trains an image encoder and a text encoder to predict which images were paired with which texts in our dataset. We then use this behavior to turn CLIP into a zero-shot classifier. We convert all of a dataset’s classes into captions such as “a photo of a dog” and predict the class of the caption CLIP estimates best pairs with a given image.
CLIP可以缓解传统深度学习方法在计算机视觉方面的许多主要问题。
0x1:缓解昂贵数据集(Costly datasets)问题
深度学习需要大量数据,传统上,视觉模型是在人工标注的数据集上训练的,这些数据集的构建成本高昂,且只为有限数量的预先确定的视觉概念提供监督。
ImageNet数据集是这一领域最大的努力之一,它需要超过25,000名工人为14百万张图片注释22,000个对象类别。相比之下,CLIP从互联网上已公开可用的文本-图像对中学习。
0x2:缓解模型处理任务领域狭窄(Narrow)问题
一个ImageNet模型擅长预测1000个ImageNet类别,但这就是它“开箱即用”能做的全部。如果我们希望执行任何其他任务,机器学习从业者需要构建一个新的数据集,添加一个输出头(output head),并对模型进行微调(fine-tune)。
相比之下,CLIP可以在不需要额外训练样本的情况下,适应执行各种各样的视觉分类任务。要将CLIP应用于新任务,我们所需要做的就是“告诉”CLIP的文本编码器任务的视觉概念名称,它将输出CLIP视觉表示的线性分类器。这个分类器的准确率往往与完全监督的模型具有竞争力。
我们在下面展示了各种数据集中的示例上,零样本学习CLIP分类器的随机、未经精选的预测结果。

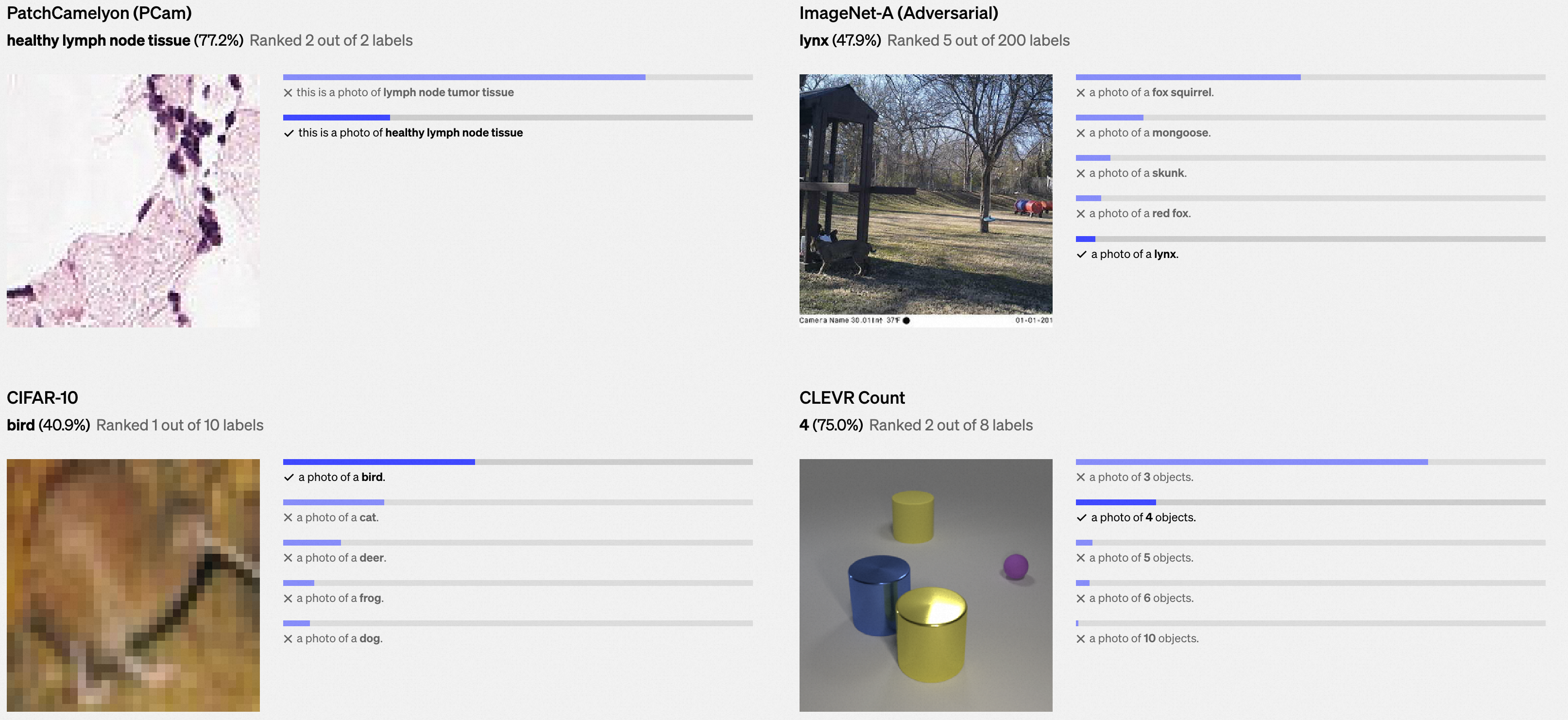
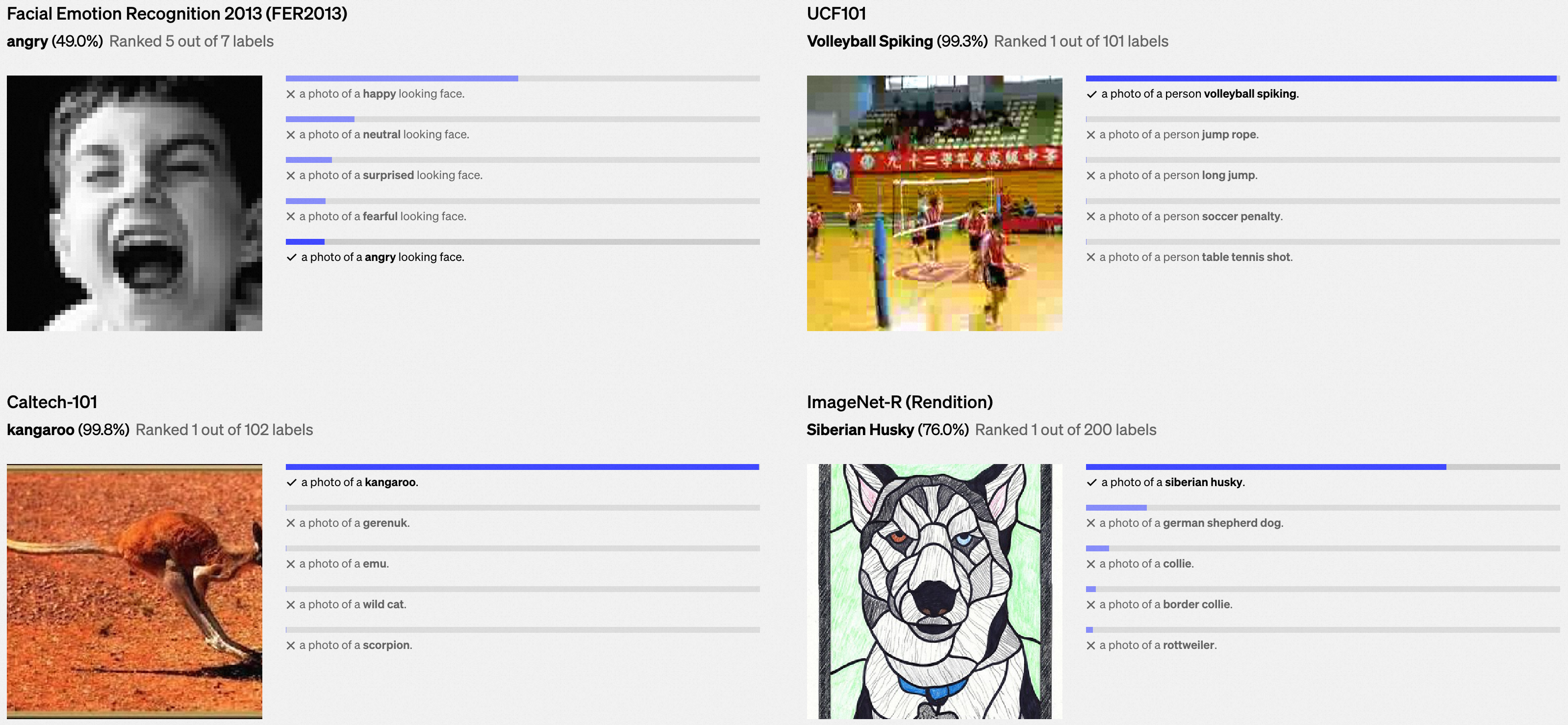


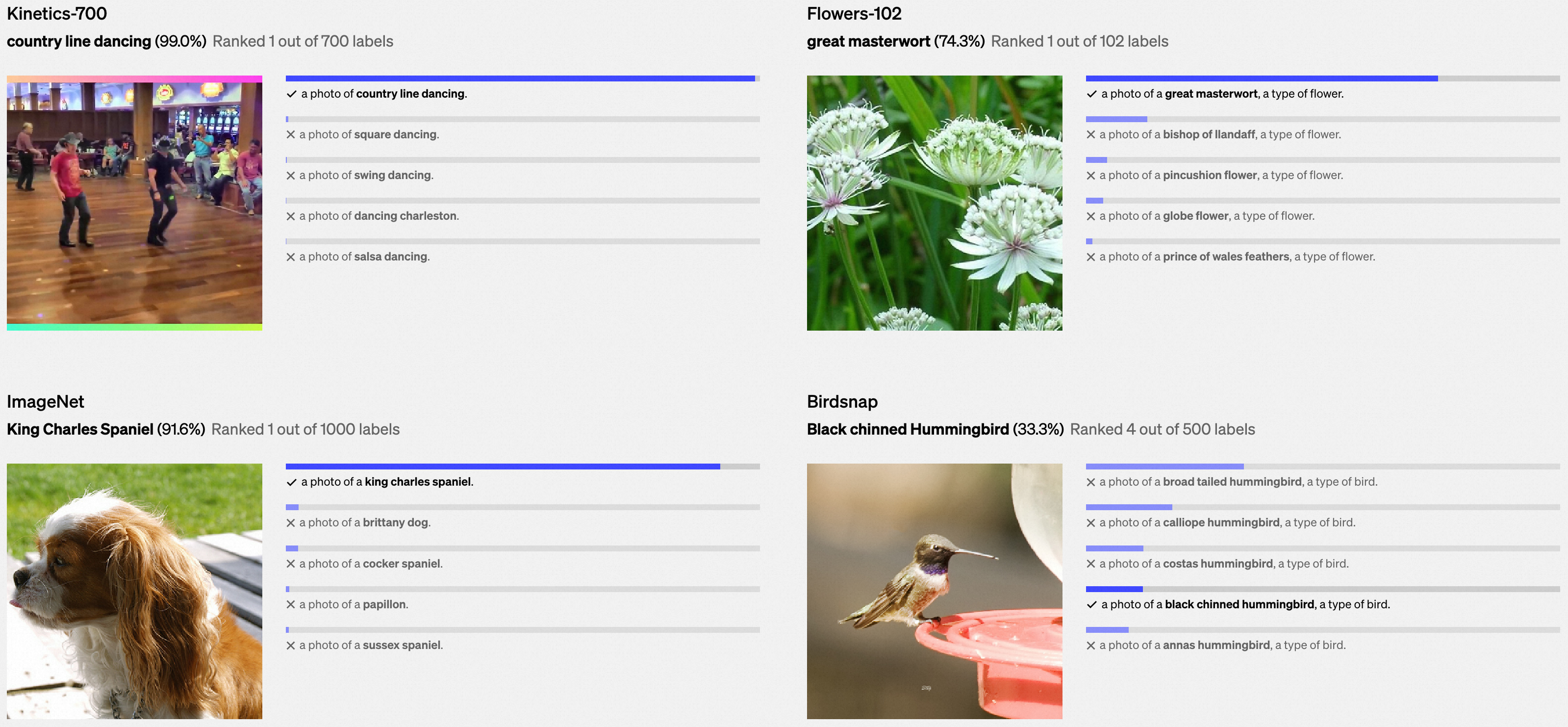

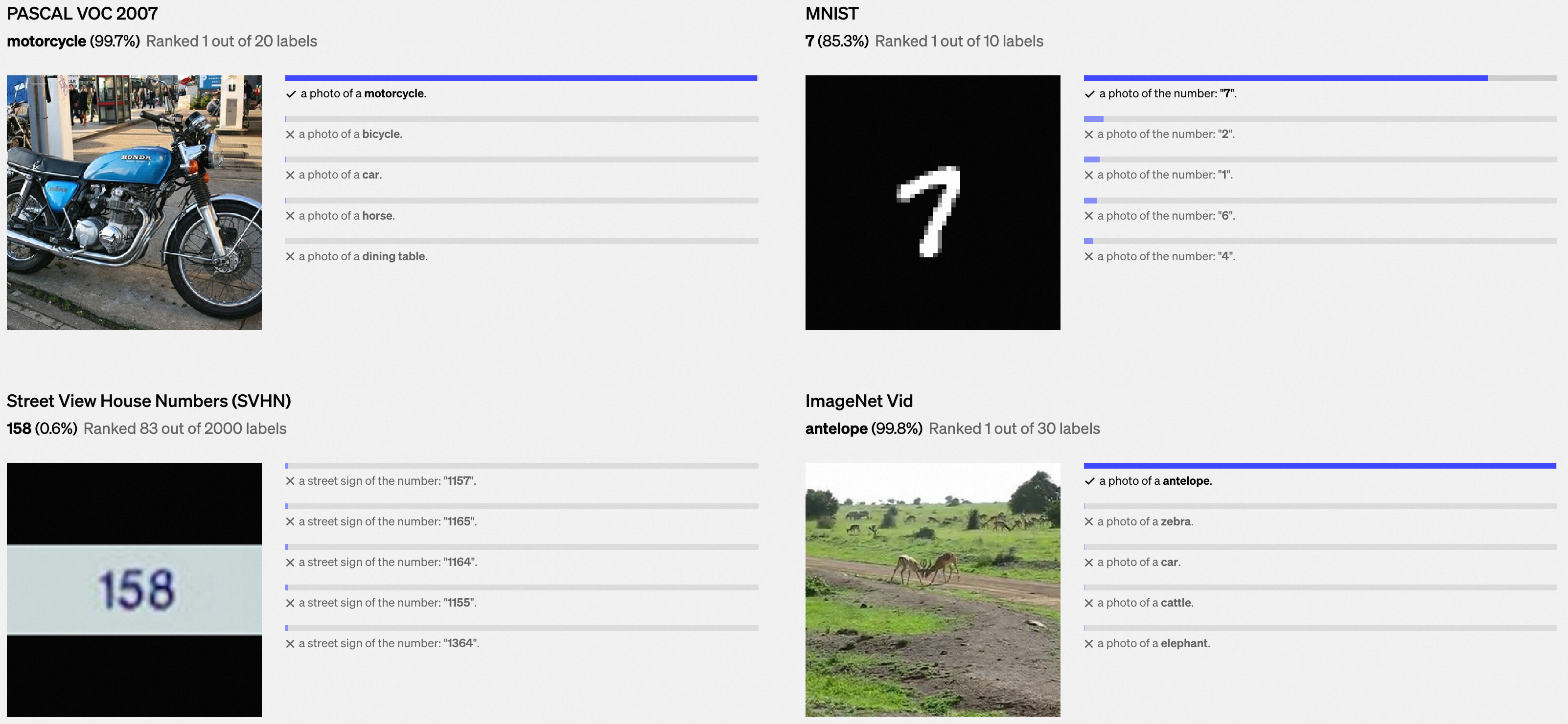
0x3:缓解模型泛化能力较差(Poor real-world performance)问题
深度学习系统常常被报道在视觉基准测试中达到了人类甚至是超越人类的表现,然而一旦部署到实际环境中,它们的表现往往远低于基准所设定的期望。换句话说,存在着“基准表现”和“实际表现”之间的差距。我们推测,这种差距之所以出现,是因为模型通过仅仅优化对基准的表现来“作弊”,这就像一个学生通过只学习往年考试题目来通过考试一样。
相反,CLIP模型可以在不需要训练其数据的情况下对基准进行评估,因此它无法以这种方式“作弊”。这导致它在基准测试中的表现更能代表其在实际环境中的表现。为了验证“作弊假设”,我们还测量了CLIP在能够为ImageNet“备考”时表现的变化。通过在CLIP的特征之上拟合线性分类器,其在ImageNet测试集上的准确率提高了近10%。然而,这个分类器在衡量“鲁棒”表现的其他7个数据集评估套件上的平均表现并没有更好。
0x1:CLIP is highly efficient
CLIP从未经过滤的、高度多变的、高度嘈杂的数据中学习,并且旨在以零样本学习的方式使用。
我们从GPT-2和GPT-3知道,训练在此类数据上的模型可以实现引人注目的零样本学习性能。然而,此类模型需要显著的训练计算资源。为了减少所需的计算资源,我们专注于改进算法来提高我们方法的训练效率。
我们这里展示了两个导致显著计算节省的算法选择。
- 第一个选择是采用对比目标(contrastive objective)来连接文本和图像。最初我们探索了类似于VirTex的图像到文本方法,但在扩展到实现最先进性能时遇到了困难。在小到中等规模的实验中,我们发现CLIP使用的对比目标(contrastive objective)在zero-shot ImageNet分类中的效率是标准方法的4到10倍。
- 第二个选择是采用了Vision Transformer模型,这比标准的ResNet模型进一步提高了3倍的计算效率。最终,我们性能最佳的CLIP模型在256个GPU上训练了2周,这与现有的大规模图像模型相当。
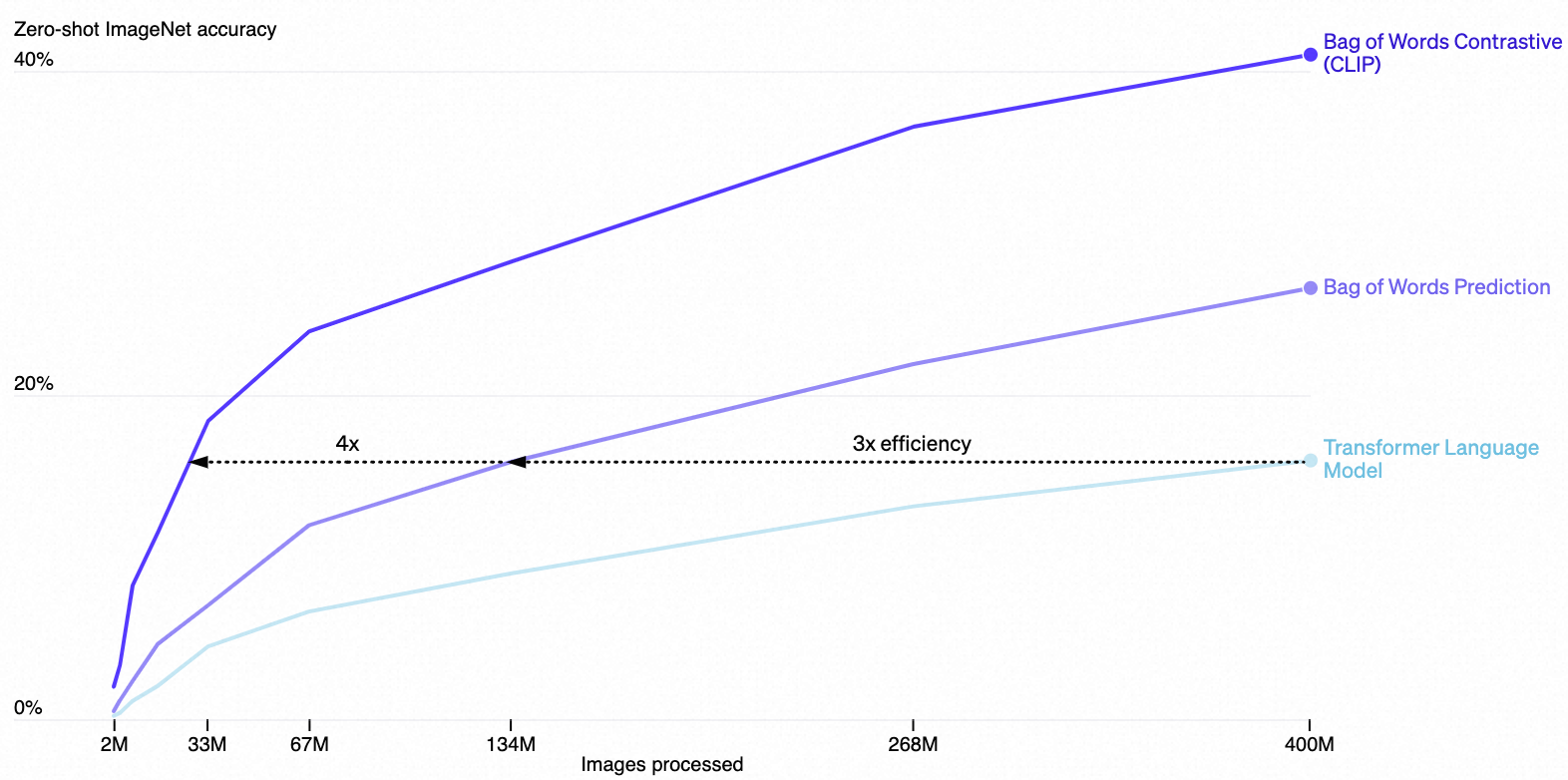
We originally explored training image-to-caption language models but found this approach struggled at zero-shot transfer. In this 16 GPU day experiment, a language model only achieves 16% accuracy on ImageNet after training for 400 million images. CLIP is much more efficient and achieves the same accuracy roughly 10x faster.
0x2:CLIP is flexible and general
由于CLIP模型直接从自然语言中学习了广泛的视觉概念,它们比现有的ImageNet模型具有更高的灵活性和普适性。我们发现它们能够零样本学习执行许多不同的任务。为了验证这一点,我们测试了CLIP在30多个不同数据集上的零样本学习表现,包括如
- 细粒度物体分类
- 地理定位
- 视频中的动作识别
- OCR等任务
这一发现也反映在使用线性探针的标准表示学习评估上。我们测试的26个不同迁移数据集中,最好的CLIP模型在20个数据集上胜过了最好的公开可用的ImageNet模型。
尽管CLIP的零样本学习OCR表现参差不齐,但它的语义OCR表示却非常有用。
- 当在以图像形式呈现的SST-2自然语言处理数据集上评估时,CLIP表示上的线性分类器与直接访问文本的CBoW模型不相上下。
- CLIP在检测仇恨性模因方面也具有竞争力,而无需真实文本的标注。
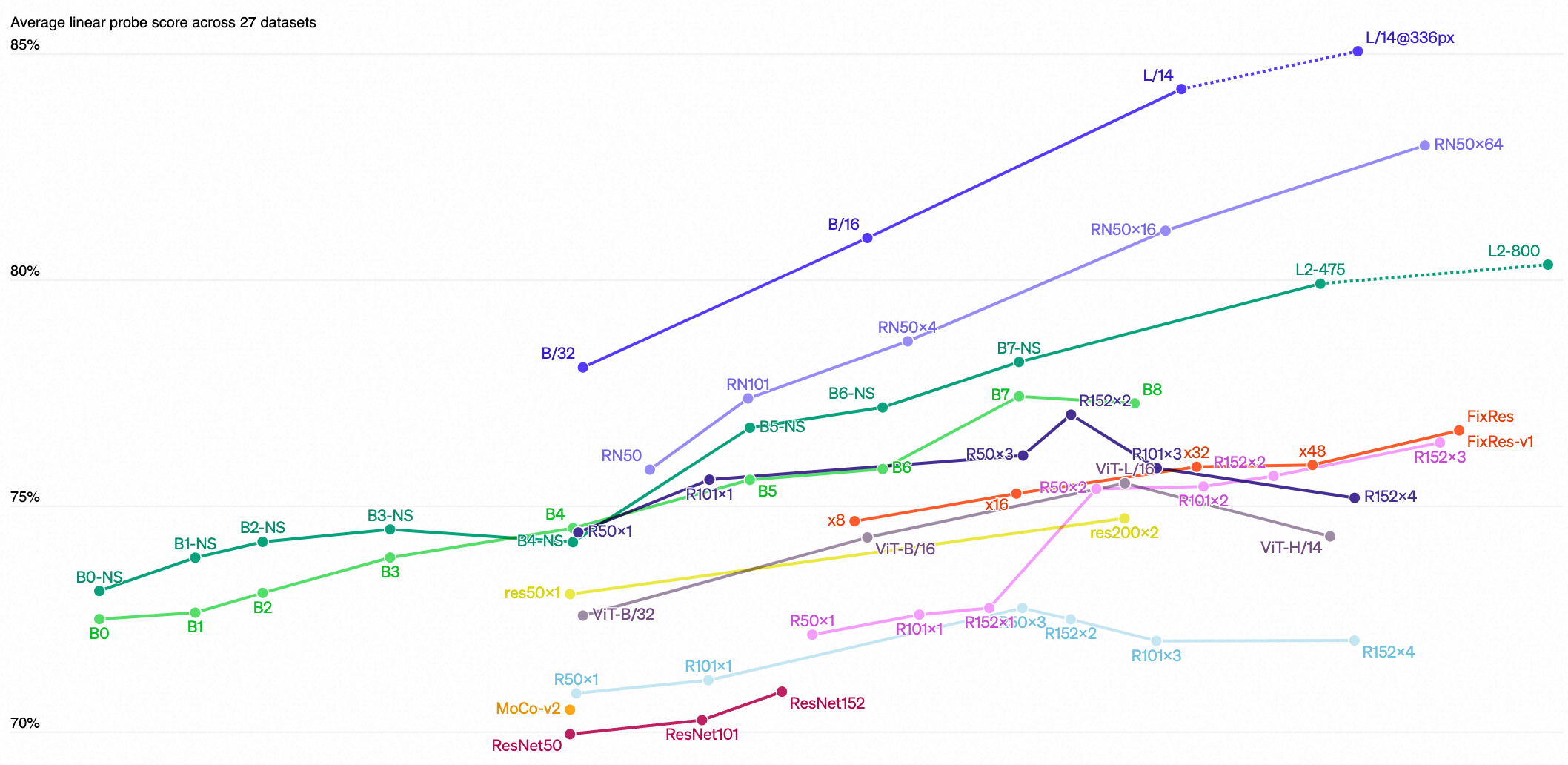
Across a suite of 27 datasets measuring tasks such as fine-grained object classification, OCR, activity recognition in videos, and geo-localization, we find that CLIP models learn more widely useful image representations. CLIP models are also more compute efficient than the models from 10 prior approaches that we compare with.
虽然CLIP通常在识别常见物体方面表现良好,但它在更抽象或系统性的任务上(例如计算图像中的物体数量)以及在更复杂的任务上(例如预测照片中最近的汽车有多近)却遇到了困难。在这两个数据集上,零样本学习的CLIP仅比随机猜测略好一些。零样本学习的CLIP在非常细致的分类任务上也难以与特定任务的模型相比,比如区分汽车型号、飞机的不同变种或者花卉品种。
CLIP对于其预训练数据集未涵盖的图像的泛化能力也仍然较差。例如,尽管CLIP学会了一个有能力的OCR系统,但在对MNIST数据集的手写数字评估时,零样本学习的CLIP仅达到了88%的准确率,远远低于人类在该数据集上的99.75%准确率。
最后,我们观察到CLIP的零样本学习分类器对措辞或措词非常敏感,有时需要通过试错的“提示工程”来使其表现良好。
使用CLIP,我们测试了任务无关的预训练是否可以使用互联网规模的自然语言这一推动了最近自然语言处理(NLP)领域突破的力量,来提高深度学习在其他领域的性能。我们对迄今为止应用这种方法于计算机视觉领域所看到的结果感到兴奋。与GPT家族一样,CLIP在预训练期间学习了多种任务,我们通过零样本迁移学习(zero-shot transfer)来展示这一点。我们也被我们在ImageNet上的发现所鼓舞,这表明零样本评估是衡量模型能力更具代表性的指标。
通过CLIP的研究和实验,我们看到预训练模型能够在没有特定任务数据的情况下,学会并执行多种任务。CLIP展示了零样本学习在多个不同领域的数据集上的能力,这表明了将大规模预训练与自然语言的强大结合应用于视觉任务的潜力。
此外,我们对zero-shot evaluation相较于传统的微调和特定任务训练方法提供了更真实的性能指标。
这些发现促进了我们对模型能力、局限性和偏差的理解,并激励了对这些领域进一步研究的兴趣。我们期待与研究社区就这些问题展开更深入的交流和合作
如有侵权请联系:admin#unsafe.sh