原文标题:DeepWukong: Statically Detecting Software Vulnerabilities Using Deep Graph Neural Network原文作者:X 2023-12-19 19:26:20 Author: 安全学术圈(查看原文) 阅读量:27 收藏
原文标题:DeepWukong: Statically Detecting Software Vulnerabilities Using Deep Graph Neural Network
原文作者:XIAO CHENG, HAOYU WANG, JIAYI HUA, GUOAI XU, Yulei Sui
发表会议:ACM Transactions on Software Engineering and Methodology (TOSEM), 2021
原文链接:https://dl.acm.org/doi/abs/10.1145/3436877
主题类型:软件漏洞挖掘,深度学习
笔记作者:soda
主编:黄诚@安全学术圈
1、研究介绍
现代软件系统有各种各样的漏洞,这些漏洞在编程逻辑中非常复杂,难以识别,通常是由各种不规范的编程习惯造成的,现有漏洞检测难以解决。需要为不同类型的漏洞开发精确、高效的静态分析方法。 现有的基于深度学习的漏洞检测方法以粗粒度的方式在方法或文件级别进行漏洞检测,开发人员难以更精确地定位漏洞。
针对上述问题,本文提出了一种基于深度学习的源代码漏洞检测方法deepwukong,可以在更细粒度的程序切片级别上,静态检测 C/C++ 程序的top10软件漏洞(如下图所示)。作者首先提出了一种新的程序切片方法,可以提取程序更复杂的高级语义特征(包括程序的数据流和控制流特征),实现更精确的代码嵌入;在构建神经网络时,嵌入程序的非结构化信息(XFG连接信息)与结构化信息(代码token),使用图神经网络将代码片段嵌入到紧凑的低维表示中,产生一种新的代码表示。
2、主要思路
deepwukong整体的流程图如上所示。框架总体来说分为三个部分:程序切片,代码嵌入,图神经网络模型。在程序切片过程中,从源代码中提取控制流图(CFG)和数据流图(VFG),构建基于控制和数据依赖关系的程序依赖图(PDG),然后根据程序兴趣点构造PDG的子图XFG,即源代码的程序切片。在代码嵌入过程中,对XFG中每一个节点的token进行标准化和嵌入。最后,将代码嵌入结果送入到图卷积网络模型中获得最终的预测结果。
2.1 程序切片
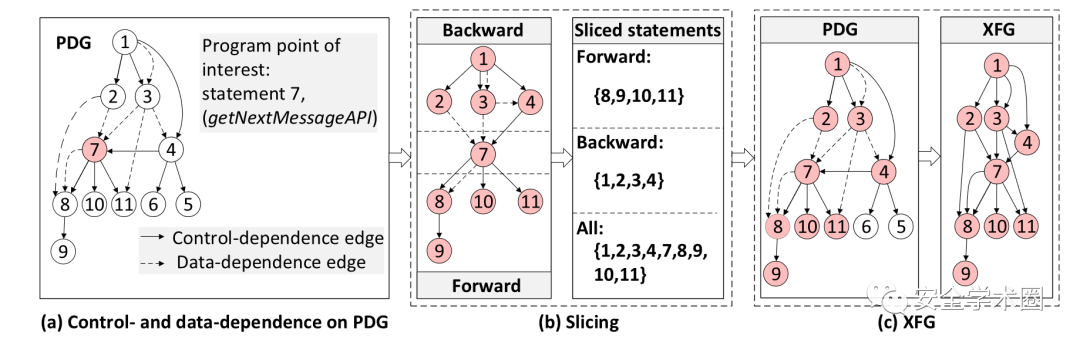
程序兴趣点(Program Points of Interest):指程序中广泛使用且容易出错的指令。本文中将系统API调用函数以及包含算术运算符的代码语句:算术运算,位运算,复合赋值运算,递增、递减定义为程序兴趣点。
如上图所示为代码切片过程的流程图,首先找到程序兴趣点(图中的节点⑦),根据代码语句的控制流与数据流依赖关系构建程序依赖图PDG;然后以程序兴趣点为中心,分别进行前向遍历与后向遍历获得所有可达的前向节点子集Backward和后向节点子集Forward;最后取子集Forward和Backward的并集,构造PDG相应的子图XFG,获得相应的程序切片。
2.2 代码嵌入
代码token的标准化
如下图所示,尽管代码A与代码B的功能与结构完全相同,由于变量命名和函数命名的差异,后续可能会生成两种完全不同的向量表示。
因此使用符号映射表将相同含义的函数名、变量名映射为一个相同的名称,进行代码token的标准化,以减少由程序变量的个性化命名引入的噪声,更好地保留原始代码语义。
代码token的嵌入
使用 Doc2Vec 算法,将代码切片图XFG中每个节点的代码token转换为向量,多轮训练趋于稳定后获得节点代码的嵌入表示。
2.3 深度神经网络模型
整体的深度神经网络模型设置如上图所示,以XFG的边和相应的代码嵌入表示作为输入,送入到交替连接的图卷积层(GCL)和图池化层(GPL)中学习图中不同层次的抽象特。在每一组图卷积/池化块后,获得当前图的一个综合表示,并将所有的综合表示送入到图读出层(GRL),整合不同图规模上的特征得到最终的图特征向量。最后使用一个多层感知器(MLP)进行最终的预测,判断当前切片是否含有漏洞。
2.4 实验结果
作者将deepwukong和四种传统静态漏洞检测器、三种基于深度学习的漏洞检测SOTA模型做了比对,评估该模型在检测最常见的 10 个 C/C++ 漏洞方面的有效性,最终在平均准确率和F1上都取得了非常好的结果。
3、个人思考
deepwukong使用程序兴趣点来执行程序切片。但是因为程序兴趣点的选取并不完善,可能会丢失一些与所选择程序兴趣点无关的漏洞。 文章的实验仅仅在C/C++的top-10漏洞数据集上进行,无法证明该模型在其他漏洞及其他语言上进行漏洞检测的有效性 文章中提到数据集的标注可能存在一定的问题。很多基于深度学习进行漏洞检测文章都提到了数据集方面存在的问题,现阶段所提出的基于神经网络的漏洞检测技术大多都是在自建的各种不同粒度数据集上进行评估的,规模较小,训练数据集存在数据重复、易受攻击代码的分布不实际等问题,导致了模型在自建数据集上表现良好但是在现实环境中表现差的现象。因此,迫切需要一个标准的基准数据集作为评估和比较所提出方法的有效性的统一指标
论文团队信息
通讯作者Yulei Sui,新南威尔士大学 (UNSW)计算机科学技术学院副教授,曾获多次杰出审稿人、杰出论文奖。
主要研究方向:程序分析、软件安全和机器学习 多篇论文发表在程序分析和软件工程领域的顶级会议和期刊上,如TSE、TOSEM、ICSE、 ISSTA、ASE等。 个人主页:https://yuleisui.github.io/
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh