2023-12-21 17:35:0 Author: www.cnblogs.com(查看原文) 阅读量:11 收藏
随着LLM的兴起,由于其强大的语言理解和推理能力,在学术和工业界中越来越受欢迎。LLM的进展也启发了研究人员将LLM作为多模态任务的接口,如视觉语言学习、音频和语音识别、视频理解等,因此多模态大语言模型(Multimodal Large Language Model, MLLM)也引起了研究人员的关注。
然而,目前的研究依赖特定于单模态的编码器,通常在架构上有所不同,并且仅限于常见的模态。
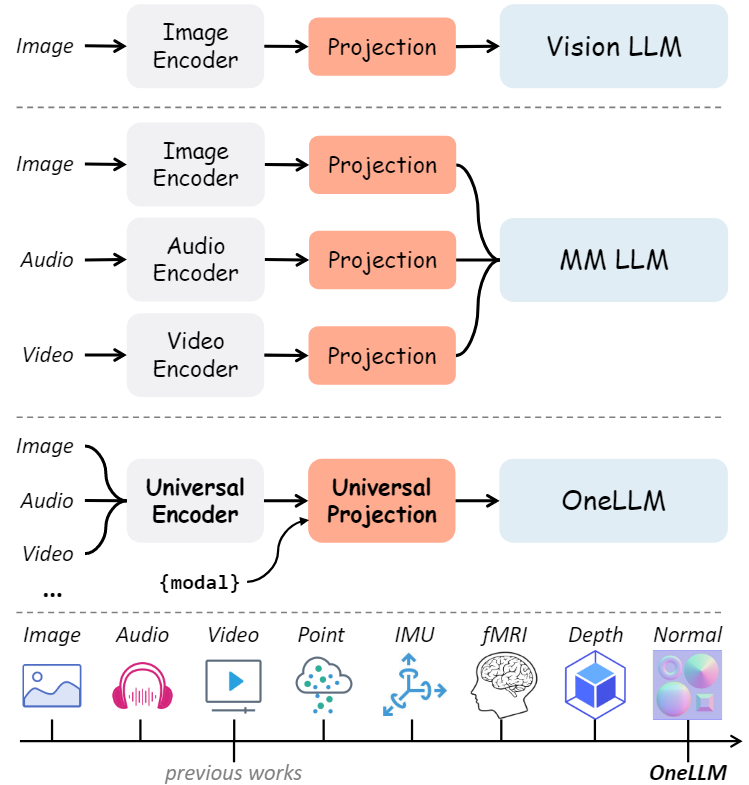
本文提出了OneLLM,这是一种MLLM,它使用一个统一的框架将八种模式与语言对齐。通过统一的多模态编码器和渐进式多模态对齐pipelines来实现这一点。不同多模态LLM的比较如下图所示,可以明显的看出OneLLM框架的工作方式与之前研究的区别。
OneLLM由以下几个核心组件组成:
- 轻量级模态标记器
- 通用编码器
- 通用投影模块(UPM)
- LLM
与之前的工作相比,OneLLM 中的编码器和投影模块在所有模态之间共享。
特定于模态的轻量级模态标记器,每个标记器仅由一个卷积层组成,将输入信号转换为一系列标记。此外,我们添加了可学习的模态标记,以实现模态切换并将不同长度的输入标记转换为固定长度的标记。
参考链接:
https://mp.weixin.qq.com/s/2-C_O0M_w9PD6E2h3BTLbw https://arxiv.org/pdf/2312.03700.pdf
大型语言模型(LLMs)由于其强大的语言理解和推理能力,在研究社区和工业界越来越受欢迎。值得注意的是,像GPT4这样的LLM已经达到了与人类在各种学术考试中几乎相当的表现。
LLMs的进步还激励了研究人员使用LLMs作为多模态任务的接口,例如
- 视觉-语言学习
- 音频和语音识别
- 视频理解等
在这些任务中,视觉-语言学习是最活跃的领域,在最近半年内就提出了50多个视觉LLMs。
通常,视觉LLM包括
- 一个视觉编码器
- 一个LLM
- 连接这两个组件的投影模块
视觉LLM首先在大量成对的图像-文本数据上进行训练,以实现视觉-语言对齐,然后在视觉指令数据集上进行微调,使其能够完成与视觉输入相关的各种指令。
除了视觉之外,还有大量努力投入到开发其他模态特定的LLMs,如音频、视频和点云。这些模型通常复制视觉LLMs的架构框架和训练方法,并依赖于预训练的模态特定编码器和精心策划的指令微调数据集的稳固基础来发挥其效力。
也有几次尝试将多种模态整合到一个MLLM中。作为视觉LLM的扩展,大多数先前的工作使用模态特定的编码器和投影模块将每个模态与LLM对齐。例如,X-LLM和ChatBridge使用独立的Q-Former或Perceiver模型将预训练的图像、视频和音频编码器与LLMs连接起来。
然而,这些模态特定的编码器通常在架构上有所不同,需要付出相当的努力才能将它们统一到一个单一框架中。此外,能够提供可靠性能的预训练编码器通常仅限于广泛使用的模态,如图像、音频和视频。这种限制对MLLMs扩展到更多模态的能力构成了制约。因此,MLLMs面临的一个关键挑战是如何构建一个统一且可扩展的编码器,能够处理广泛的模态范围。
我们从最近关于将pretrained transformers迁移到下游模态的研究中获得了灵感。
- Lu等人证明了一个冻结的语言预训练transformers可以在下游模态如图像分类上达到强大的性能。
- MetaTransformer展示了一个冻结的视觉编码器可以在12种不同数据模态上取得有竞争力的结果。
上述工作的洞察表明,每个模态的预训练编码器可能不是必需的。相反,一个训练良好的transformers可能作为一个通用的跨模态编码器。
在本文中,我们提出了OneLLM,一个使用统一框架将八种模态与语言对齐的MLLM。如下图所示,
OneLLM由以下几个核心组件组成:
- 轻量级模态标记器
- 通用编码器
- 通用投影模块(UPM)
- LLM
与先前的工作不同,OneLLM中的编码器和投影模块在所有模态中都是共享的。模态特定的标记器(tokenizers),每个只包含一个卷积层,将输入信号转换成一系列标记(tokens)。此外,我们添加了可学习的模态标记(modality tokens),以实现模态切换,并将不同长度的输入标记转换成固定长度的标记。
从头开始训练如此复杂的模型提出了重大挑战。我们从视觉LLM开始,以逐渐的方式将其他模态与LLM对齐。具体来说过程如下,
- (i)我们使用预训练的CLIP-ViT作为图像编码器,配合几层transformer层作为图像投影模块,并以LLaMA2作为LLM。在大规模成对的图像-文本数据上预训练后,投影模块学习将视觉表征映射到LLM的嵌入空间。
- (ii)为了与更多模态对齐,我们需要一个通用编码器和投影模块。如前所述,预训练的CLIP-ViT有可能作为通用编码器。对于UPM,我们提出将多个图像投影专家混合作为一个通用的X到语言的接口。为了增强模型的能力,我们还设计了一个动态路由器,控制给定输入下每个专家的权重,这使得UPM变成了软混合专家。
- (iii)最后,我们根据它们的数据量逐步将更多模态与LLM对齐。
我们还策划了一个大规模多模态指令数据集,包括八种模态的字幕、问答及推理任务:
- 图像
- 音频
- 视频
- 点云
- 深度/法线图
- 惯性测量单元(IMU)
- 功能性磁共振成像(fMRI)
通过在这个数据集上进行微调,OneLLM具有强大的多模态理解、推理和指令跟随能力。
我们在多模态字幕、问答和推理基准测试中评估了OneLLM的性能,它比先前的专业模型和MLLMs都有更优越的表现。
LLM的迅猛发展引起了研究人员的重视,因此有研究人员提出了视觉领域的大型视觉语言模型,并取得了较好的性能。除了视觉领域大语言模型之外,研究人员将其拓展到了多模态领域,如音频、视频和点云数据中,这些工作使得将多种模式统一为一个LLM成为可能即多模态大语言模型。X-LLM,ChatBridge,Anymal,PandaGPT,ImageBind-LLM等MLLM不断涌现。然而,当前的 MLLM 仅限于支持常见的模式,例如图像、音频和视频。目前尚不清楚如何使用统一的框架将 MLLM 扩展到更多模式。
在这项工作中,提出了一个统一的多模态编码器来对齐所有模态和语言。将多种模式对齐到一个联合嵌入空间中对于跨模态任务很重要,这可以分为:
- 判别对齐
- 生成对齐
判别对齐最具代表性的工作是CLIP,它利用对比学习来对齐图像和文本。后续工作将 CLIP 扩展到音频文本、视频文本等。
本文的工作属于生成对齐。与之前的工作相比,直接将多模态输入与LLM对齐,从而摆脱训练模态编码器的阶段。
0x1:Model Architecture
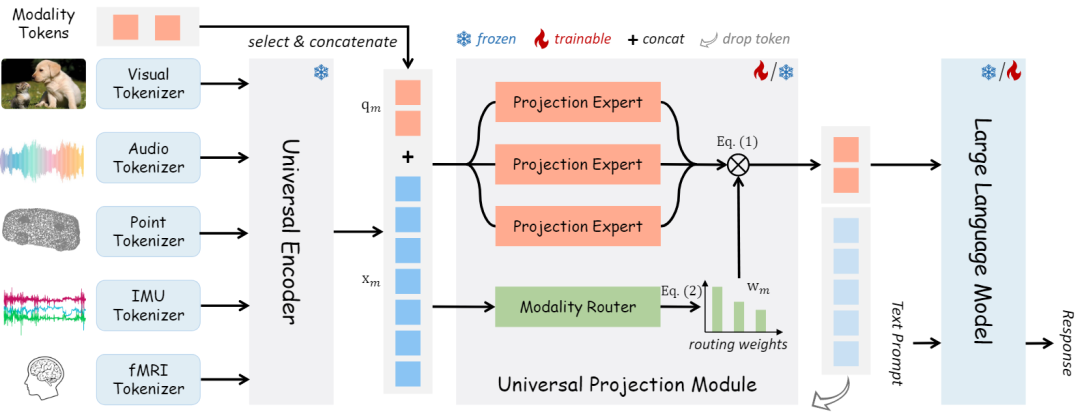
上图展示了 OneLLM 的四个主要组件:特定于模态的轻量标记器、通用编码器、通用投影模块和 LLM。
- 轻量模态标记器(Lightweight Modality Tokenizers):模态标记器是将输入信号转换为标记序列,因此基于transformers的编码器可以处理这些标记。为每个模态设计了一个单独的标记器。对于图像和视频等二维信息的视觉输入,直接使用单个二维卷积层作为标记器。对于其他模态,将输入转换为 2D 或 1D 序列,然后使用 2D/1D 卷积层对其进行标记。
- 通用编码器(Universal Encoder):利用预训练的视觉语言模型作为所有模态的通用编码器。视觉语言模型在对大量图文数据进行训练时,通常学习视觉和语言之间的稳健对齐,因此它们可以很容易地转移到其他模式。在OneLLM中,使用CLIPViT作为通用计算引擎。保持CLIPViT的参数在训练过程中被冻结。
- 通用投影模块(Universal Projection Module):与现有的基于模态投影的工作不同,提出了一个通用投影模块,将任何模态投影到 LLM 的嵌入空间中。由 K 个投影专家组成,其中每个专家都是在图像文本数据上预训练的一堆transformer层。尽管一位专家还可以实现任何模态到 LLM 的投影,但实证结果表明,多个专家更有效和可扩展。当扩展到更多模态时,只需要添加几个并行专家。
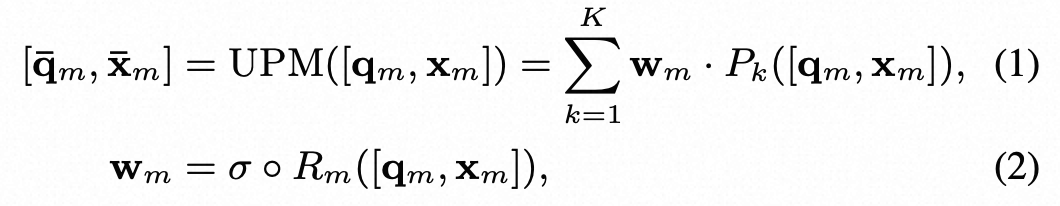
- LLM:采用开源LLaMA2作为框架中的LLM。LLM的输入包括投影的模态标记和单词嵌入后的文本提示。为了简单起见,本文对应的模态标记总是放在输入序列的开头。然后LLM被要求以模态标记和文本提示为条件生成适当的响应。
0x2:Progressive Multimodal Alignment
多模态对齐的简单方法是在多模态文本数据上联合训练模型。然而,由于数据规模的不平衡,直接在多模态数据上训练模型会导致模态之间的偏差表示。
本文训练了一个图像到文本模型作为初始化,并将其他模式逐步接地到LLM中(包括图文对齐、多模态-文本对齐)。
- 图像-文本对包括LAION-400M和LAION-COCO。
- 视频、音频和视频的训练数据分别为WebVid-2.5M、WavCaps和Cap3D。由于没有大规模的deep/normal map数据,使用预训练的 DPT 模型来生成deep/normal map。
- 对于IMU-text对,使用Ego4D的IMU传感器数据。
- 对于fMRI-text对,使用来自NSD数据集的 fMRI 信号,并将与视觉刺激相关的字幕作为文本注释。
0x3:Unified Multimodal Instruction Tuning
在多模态-文本对齐之后,OneLLM 成为一个多模态字幕模型,可以为任何输入生成简短的描述。
为了充分释放OneLLM的多模态理解和推理能力,本文策划了一个大规模的多模态指令微调数据集来进一步微调OneLLM。
在指令调优阶段,完全微调LLM并保持其余参数冻结。尽管最近的工作通常采用参数高效的方法,但凭经验表明,完整的微调方法更有效地利用 OneLLM 的多模态能力,特别是利用较小的 LLM(例如LLaMA2-7B)。
0x1:Implementation Details
1、架构
- 通用编码器是在LAION上预训练的CLIP VIT Large
- LLM 是 LLAMA2-7B
- UPM有K=3个投影专家,每个专家有8个transformer块和88M个参数
2、训练细节
使用AdamW优化器,β1=0.9,β2==0.95,权重衰减为0.1。
- 在前2K次迭代中应用了线性学习速率预热。
- 对于阶段I,在16个A100 GPU上训练OneLLM 200K次迭代。有效批量大小为5120。最大学习率为5e-5。
- 对于第II阶段,在8个GPU上训练 OneLLM 200K,有效批量大小为1080,最大学习率为1e-5。
- 在指令调优阶段,在8个gpu上训练OneLLM 1 epoch,有效批大小为512,最大学习率为2e-5。
0x2:Quantitative Evaluation
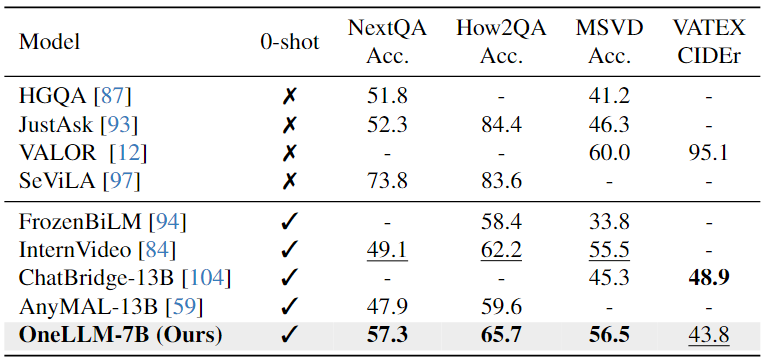
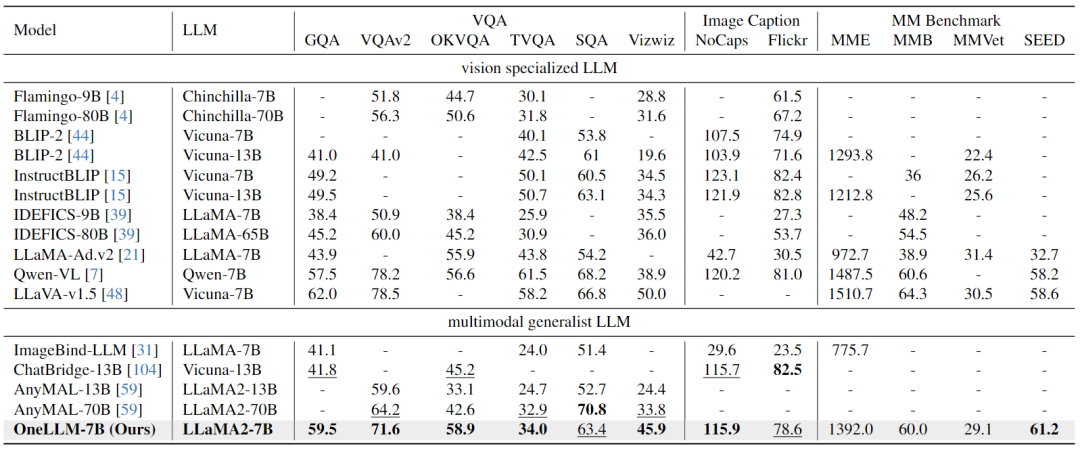
Image-Text Evaluation:下表结果表明,OneLLM还可以在视觉专门的LLM中达到领先水平,MLLM和视觉LLM之间的差距进一步缩小。
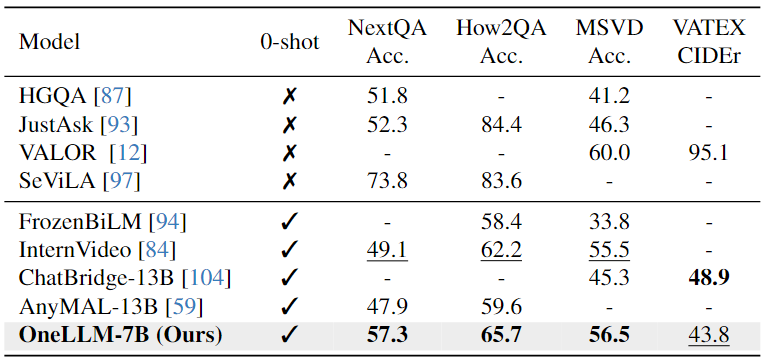
Video-Text Evaluation:下表可以看出,本文模型在相似的 VQA 数据集上进行训练明显增强了其跨模态能力,有助于提高视频QA任务的性能
Audio-Text Evaluation:对于Audio-Text任务,结果显示,在Clotho AQA上的zero-shot结果与完全微调的Pengi相当。字幕任务需要更多特定于数据集的训练,而QA任务可能是模型固有的零样本理解能力更准确的度量。

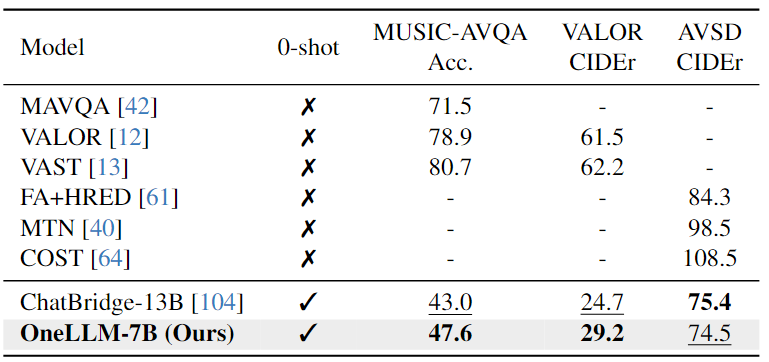
Audio-Video-Text Evaluation:下表结果表明,OneLLM-7B在所有三个数据集上都超过了 ChatBridge-13B。由于 OneLLM 中的所有模态都与语言很好地对齐,因此在推理过程中可以直接将视频和音频信号输入到 OneLLM。
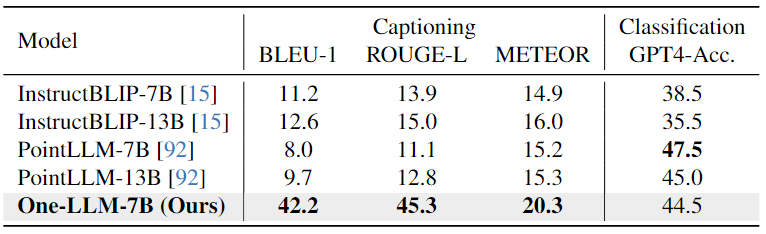
Point Cloud-Text Evaluation:从下表中可以看出,由于精心设计的指令提示在任务之间切换,OneLLM可以实现出色的字幕结果,而InstructBLIP和PointLLM 难以生成简短而准确的字幕。在分类任务中,OneLLM也可以获得与 PointLLM 相当的结果。
Depth/Normal Map-Text Evaluation:如下表中所示,与CLIP相比,OneLLM实现了优越的zero-shot分类精度。这些结果证实,在合成deep/normal map-text数据上训练的OneLLM可以适应现实世界的场景。

0x3:Qualitative Analysis
下图中给出了 OneLLM 在八种模态上的一些定性结果。展示了 OneLLM 可以
- (a)理解图像中的视觉和文本内容
- (b)利用视频中的时间信息
- (c)基于音频内容进行创造性写作
- (d)理解3D形状的细节
- (e)分析fMRI数据中记录的视觉场景
- (f)基于运动数据猜测人的动作
- (g)-(h)使用deep/normal map进行场景理解

以下是OneLLM框架更多的定性分析结果。

0x4:Local Demo
1、Install packages
pip install -r requirements.txt # install pointnet cd model/lib/pointnet2 python setup.py install
1、Model Download
git clone https://github.com/csuhan/OneLLM.git mkdir model_weight cd model_weight git clone https://huggingface.co/csuhan/OneLLM-7B
2、Start Local Demo
python3 demos/multi_turn_mm.py --gpu_ids 0 --tokenizer_path config/llama2/tokenizer.model --llama_config config/llama2/7B.json --pretrained_path /data_vdb1/OneLLM/model_weight/OneLLM-7B/consolidated.00-of-01.pth
参考链接:
https://huggingface.co/spaces/csuhan/OneLLM https://huggingface.co/csuhan/OneLLM-7B/tree/main
在这项工作中,本文介绍了 OneLLM,这是一种 MLLM,它使用一个统一的框架将八种模式与语言对齐。
最初,训练一个基本的视觉LLM。在此基础上,设计了一个具有通用编码器、UPM 和 LLM 的多模态框架。通过渐进式对齐pipelines,OneLLM 可以使用单个模型处理多模态输入。
此外,本文工作策划了一个大规模的多模态指令数据集,以充分释放OneLLM的指令跟踪能力。
最后,在 25 个不同的基准上评估 OneLLM,显示出其出色的性能。
如有侵权请联系:admin#unsafe.sh