原文链接:https://y4tacker.github.io/2023/12/22/year/2023/12/Hacking-FernFlower/
作者:Y4tacker
今天很开心,第一次作为 speaker 参与了议题的分享。
其实本该在去年来讲 Java 混淆的议题,不过当时赶上疫情爆发,学校出于安全的考虑没让出省。在当时我更想分享的是对抗所有反混淆的工具 cfr、procyon,但今年在准备过程中发现主题太大了其实不太好讲,再考虑到受众都是做 web 安全的,因此我最终还是将主题定为了对抗反编译工具,在这里选了一些方便大家理解的例子来介绍混淆,主要是想分享一些不一样的思路吧。
在这次议题当中我仅仅分享了部分较为简单的混淆方式,但他们却很直观易懂,如果你想要更深入的去做更高难度的混淆,还可以尝试对书籍《深入理解 JAVA 虚拟机》做一些简单的阅读。
在这篇文章当中我也会尽量不使用过于复杂的概念,用大家更能接受的形式来讲述一个混淆的例子,当然有些地方可能表述也会存在表述不当的情况,请见谅,全文文章以 JDK8 为例(懒,并不想测试所有版本支持情况)。
同时在文章中也会分享部分议题中没有讲的内容,主要是在议题时考虑到时间原因临时做了删除调整。
首先在开始之前我们需要了解 ASM 的一些简单用法,ASM 其实有两套 API,一个是 Core API,另一个是 Tree API,在这里如果你只是想要学习到在今天议题分享过程当中的一些基本原理,那么我认为了解 Core API 的用法就够了,如果你需要做工具开发,那么我更推荐使用 Tree API 去完成一个工具的开发,Tree API 能更灵活的帮助我们完成我们的需求(比如我们想要在某个指定的字节码操作后做指令的添加),或者也可以使用其他字节码处理框架。在这里我不会花大篇量的篇幅去写一个关于 ASM 的教程,但是对于一些关键的点我仍会点出(关于 ASM 的使用教程网上有很多,对不了解的使用方法部分可以尝试多百度)。
1.1 测试代码
见 https://github.com/Y4tacker/HackingFernFlower。
1.2 如何生成一个类
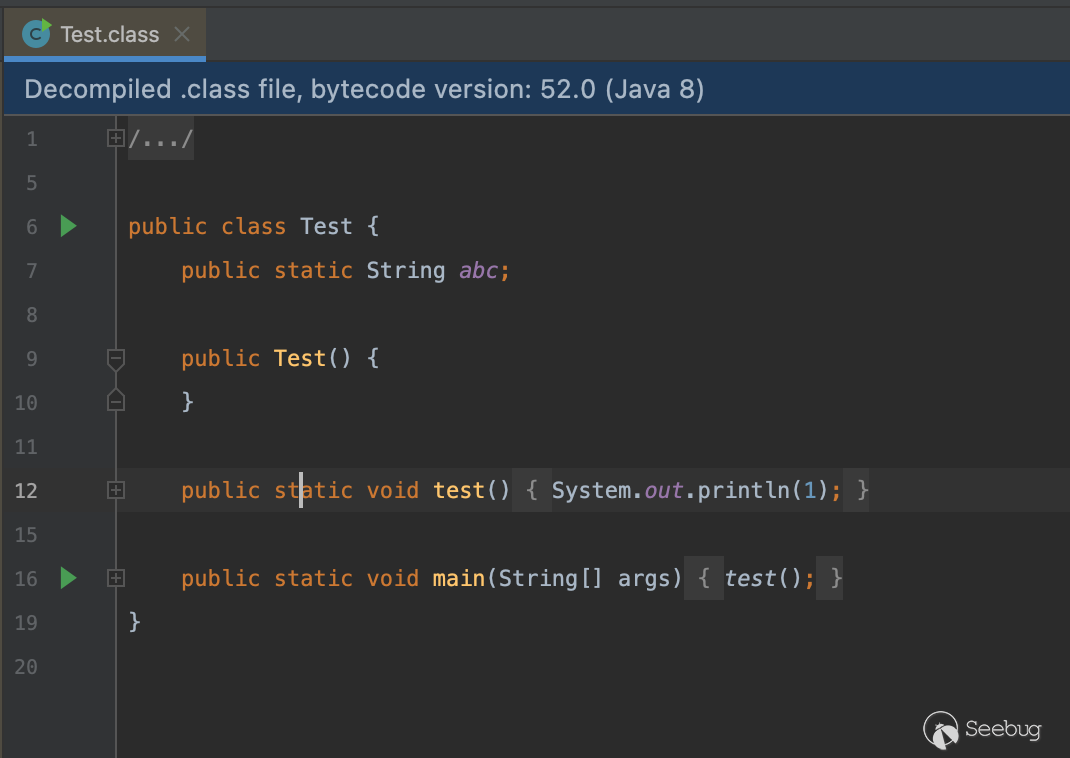
在这里我们想要生成这样的一个类,类名为 Test、字段名为 abc、方法名为 test:
首先我们需要实例化一个 ClassWriter 对象:ClassWriter classWriter = new ClassWriter(0);
在这个构造函数当中我们也可以传入其他选项,如:ClassWriter.COMPUTE_FRAMES/ClassWriter.COMPUTE_MAX
- COMPUTE_MAXS:在写入方法时,会自动计算方法的最大堆栈大小和局部变量表的大小。
- COMPUTE_FRAMES:在写入方法字节码时,会自动计算方法的堆栈映射帧和局部变量表的大小。使用该参数时,COMPUTE_MAXS 参数也会被自动设置。
一般而言在构造方法中我们都可以加上ClassWriter.COMPUTE_FRAMES选项,可以让我们专心字节码的构造,不用考虑 max stacks 、max locals 以及 stack map frames 的计算过程。
生成一个类,参数分别是 Java 版本号、修饰符、类名、签名、父类、接口。
classWriter.visit(V1_8, ACC_PUBLIC | ACC_SUPER, "Test", null, "java/lang/Object", null);
生成一个字段,参数分别是修饰符、字段名、字段类型、签名、值。
{
fieldVisitor = classWriter.visitField(ACC_PUBLIC | ACC_STATIC, "abc", "Ljava/lang/String;", null, null);
fieldVisitor.visitEnd();
}生成一个方法,参数分别是修饰符、方法名、方法描述符(入参与返回值)、签名、异常。
{
methodVisitor = classWriter.visitMethod(ACC_PUBLIC | ACC_STATIC, "test", "()V", null, null);
methodVisitor.visitCode();
methodVisitor.visitFieldInsn(GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");
methodVisitor.visitInsn(ICONST_1);
methodVisitor.visitMethodInsn(INVOKEVIRTUAL, "java/io/PrintStream", "println", "(I)V", false);
methodVisitor.visitInsn(RETURN);
methodVisitor.visitMaxs(2, 0);
methodVisitor.visitEnd();
}1.3 自定义查看一个类怎么通过 ASM 代码生成(必看)
当然在开始之前我希望你多了解下 ASM 的一些代码写法,自己多写几个类,多查看其 ASM 的生成代码。
在这里我教大家如何自定义查看一个类是怎么通过 ASM 代码生成,多模仿才能更熟练。
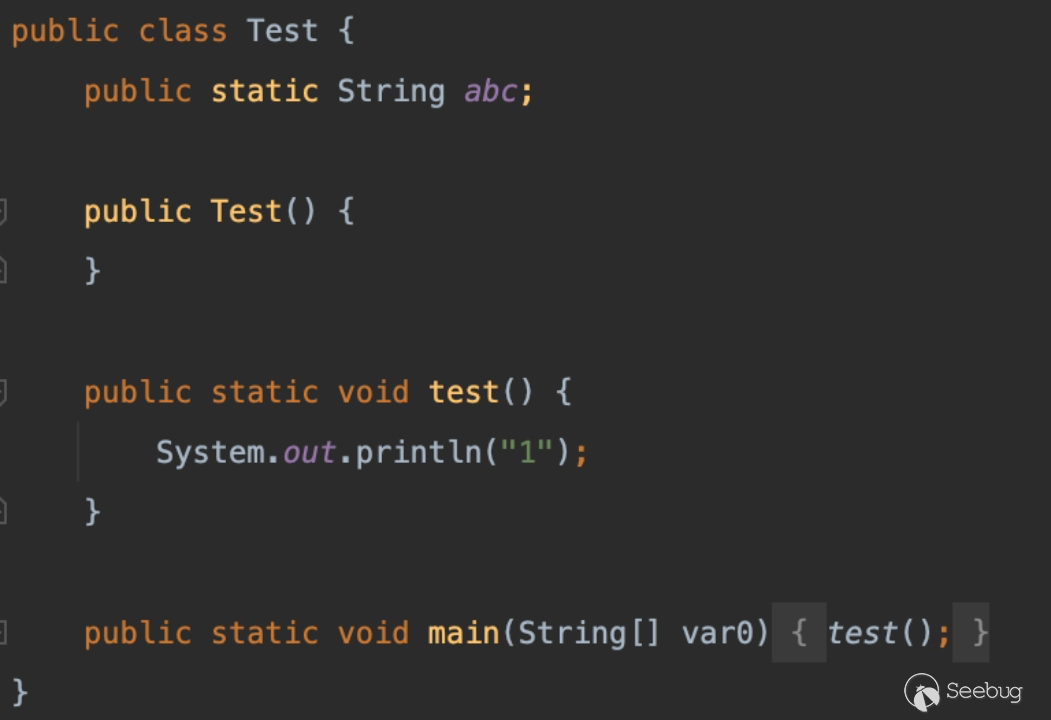
比如在这里我们需要查看 Test.class 该如何使用 ASM 框架的代码生成。
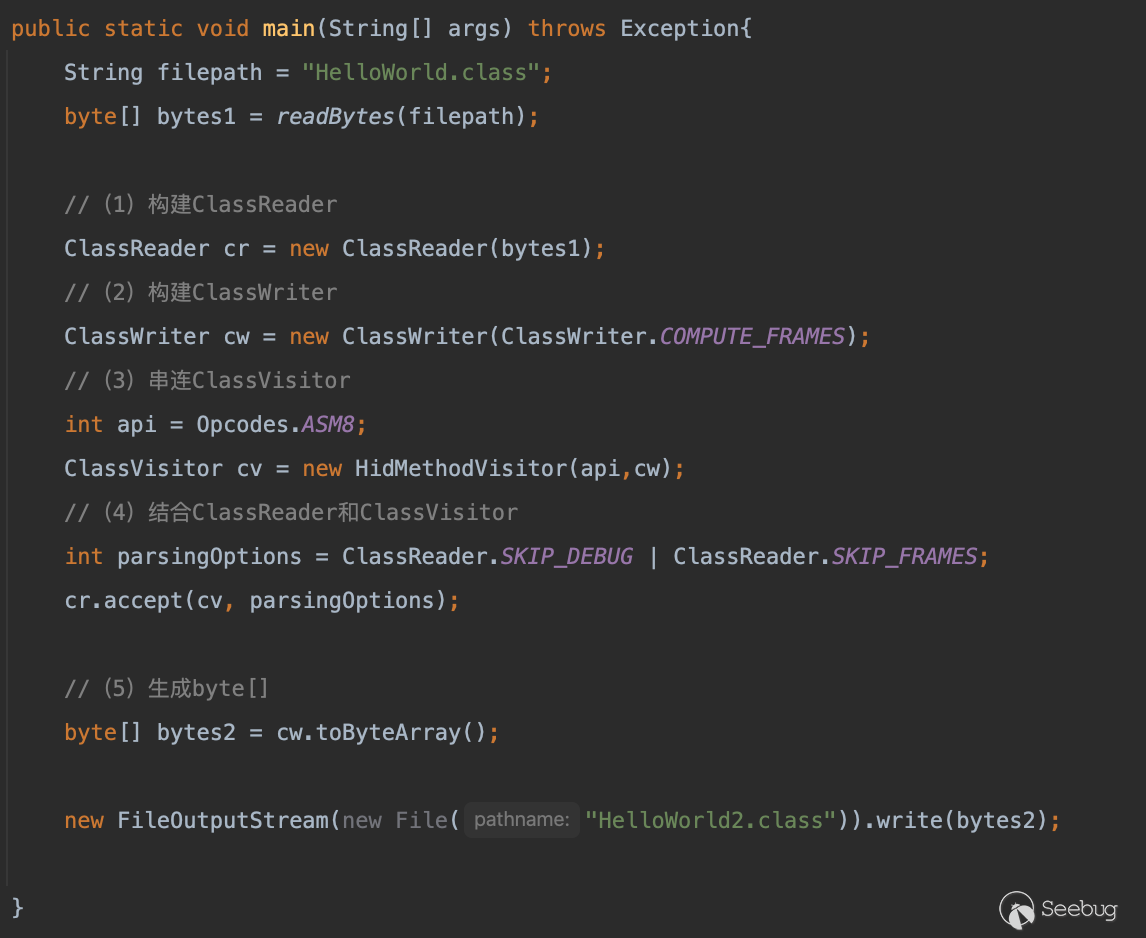
通过执行下面的代码你可以获得这个写法(初学时一定要启用参数 SKIP_DEBUG、SKIP_FRAMES),在后面熟练以后可以尝试将其替换为int parsingOptions = ClassReader.EXPAND_FRAMES。
public static void main(String[] args) throws Exception{
//需要处理的Class
String inputFilename = "./target/classes/Test.class";
String outputFilename = "output.txt";
FileInputStream fileInputStream = new FileInputStream(new File(inputFilename));
// SKIP_DEBUG:用于指示ClassReader在读取类文件时是否跳过调试信息。调试信息包括源代码行号、局部变量名称和范围等信息
// SKIP_FRAMES:指示ClassReader在读取类文件时是否跳过帧信息。帧信息是用于存储方法调用和异常处理的数据结构。如果指定了SKIP_FRAMES常量,那么在读取类文件时将会跳过帧信息,从而减少读取和处理的时间和内存消耗
// EXPAND_FRAMES:指示在生成类文件时是否应该展开帧。帧用于在Java类文件中表示方法的执行状态,包括操作数栈和局部变量表的内容。如果指定了EXPAND_FRAMES常量,那么在生成类文件时将会展开帧信息,从而确保生成的类文件包含完整的帧信息
int parsingOptions = ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES;
Printer printer = new ASMifier();
FileOutputStream fileOutputStream = new FileOutputStream(new File(outputFilename));
PrintWriter printWriter = new PrintWriter(fileOutputStream);
TraceClassVisitor traceClassVisitor = new TraceClassVisitor(null, printer, printWriter);
new ClassReader(fileInputStream).accept(traceClassVisitor, parsingOptions);
}2.1 命名混淆
接下来通过一个开胃小菜来帮助我们熟悉 ASM 的使用方法。
在学习 Java 的时候,第一课通常都是教我们一些编程规范,其中就包含命名的规范,一般而言是下面这几种情况,然而真的是这样么?
这都是常态化的思维固化了我们,理所当然的认为变量名只能是以下几种:
- 名称只能由字母、数字、下划线、$符号组成?
- 不能以数字开头?
- 名称不能使用 JAVA 中的关键字?
- 坚决不允许出现中文及拼音命名?
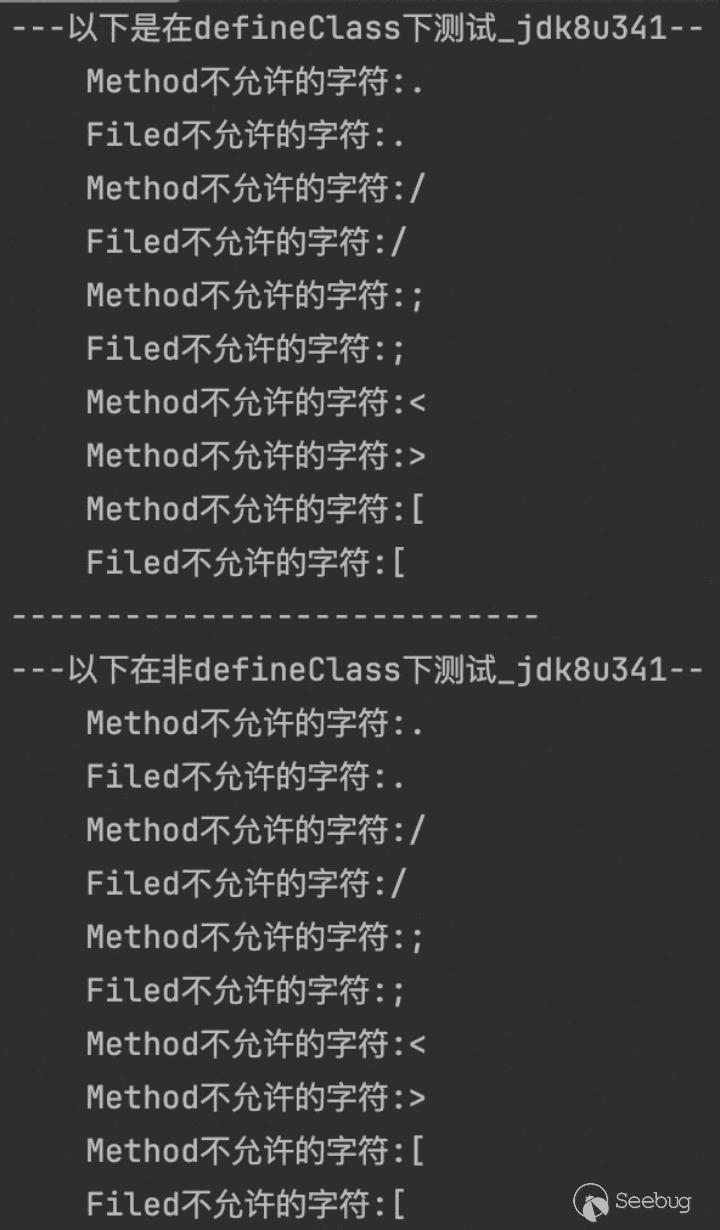
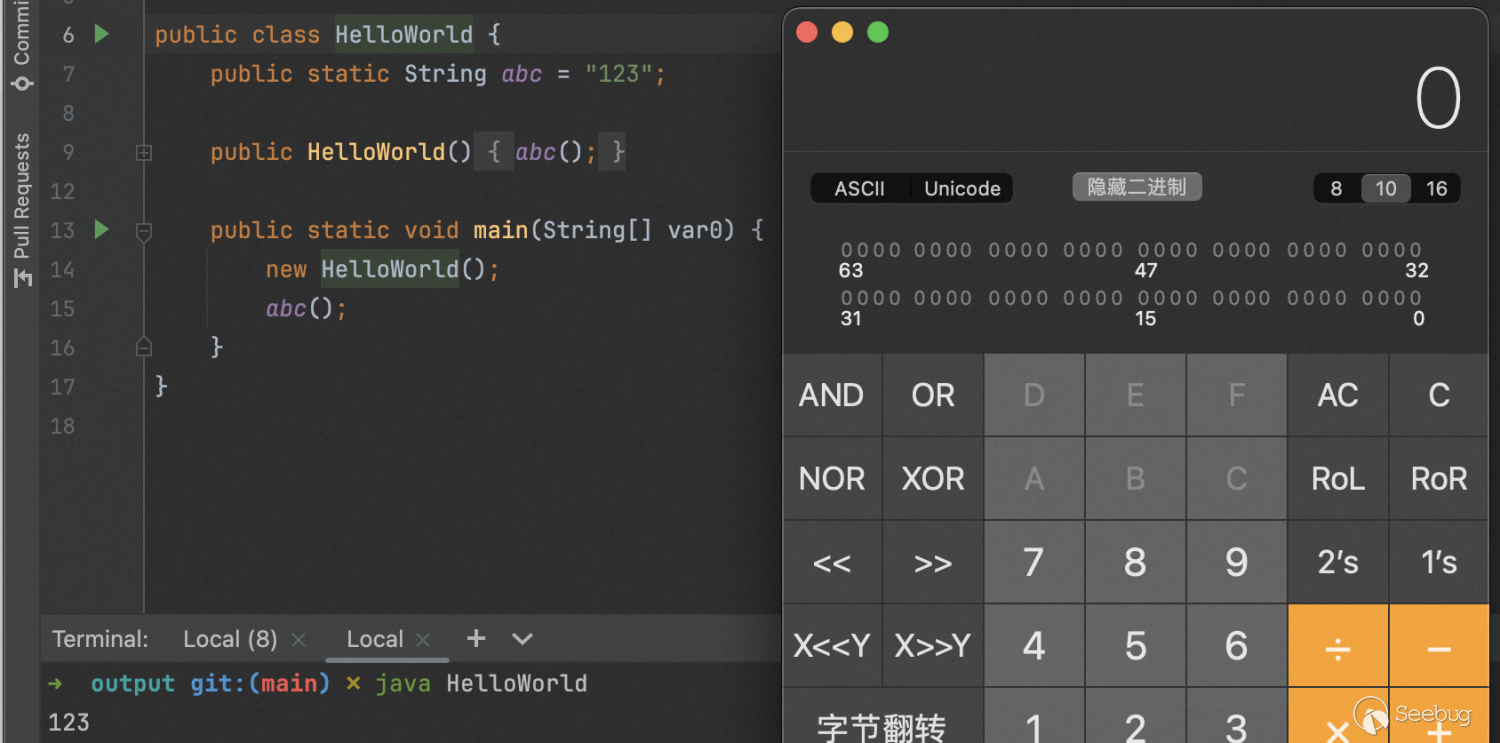
通过测试并不是这样的,这个限制其实只发生在编译的过程(javac),而在执行过程无限制(java)。
int start = 0;
int end = 65535;
String jdk = "jdk8u341";
boolean onlyDefineClass = true;
System.out.println("---以下是在defineClass下测试_{jdk}--".replace("{jdk}",jdk));
for (int i = start; i <= end; i++) {
char unicodeChar = (char) i;
FuzzMethodName(unicodeChar, jdk, onlyDefineClass);
FuzzFieldName(unicodeChar, jdk, onlyDefineClass);
}
System.out.println("----------------------------");
onlyDefineClass = false;
System.out.println("---以下在非defineClass下测试_{jdk}--".replace("{jdk}",jdk));
for (int i = start; i <= end; i++) {
char unicodeChar = (char) i;
FuzzMethodName(unicodeChar, jdk, onlyDefineClass);
FuzzFieldName(unicodeChar, jdk, onlyDefineClass);
}在这里我们仅仅只是想要让大家知道在不同小版本间有差异,我没有去比对每一个版本,只想让大家知道不同版本间有一些差异即可。
- Jdk8u20
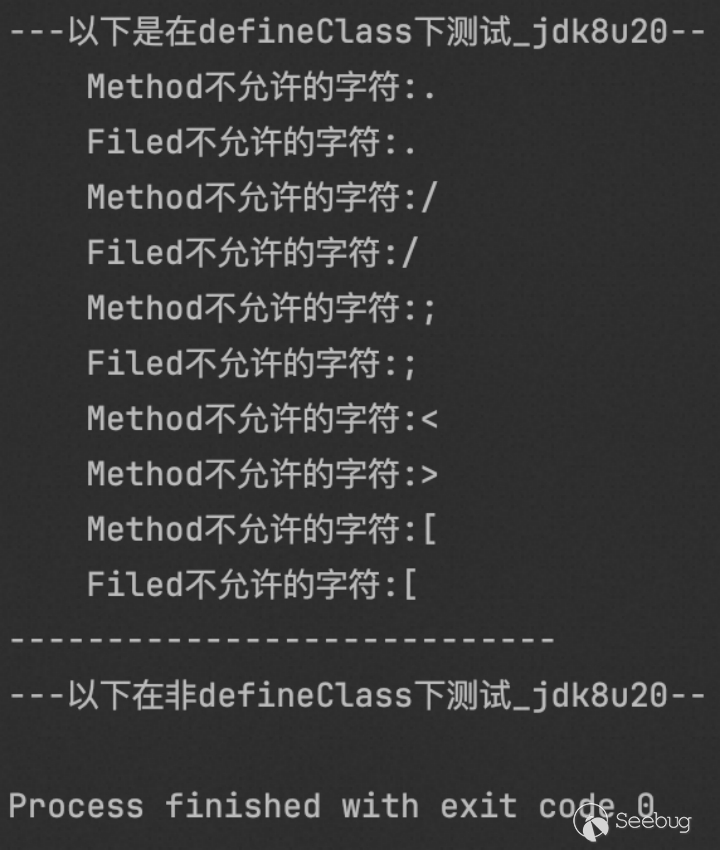
- jdk8u341
因此接下来我们可以通过修改参数name为任意我们想要的值。
{
fieldVisitor = classWriter.visitField(ACC_PUBLIC| ACC_STATIC| ACC_FINAL,"abc{\nsuper man supersuper\n}","[Ljava/lang/String;",null,null);
fieldVisitor.visitEnd();
}因此我们可以实现这样的类,如下图所示,可以看到在视觉上非常具有混淆的效果(测试环境 jdk8u20,高版本下部分字母不支持)。

2.2 一个有趣的现象
在 fuzz 的过程当中我发现,当方法名(或其他参数)中出现了\r(退格键)这个字符,出现了这样一个有趣的现象,类无法拖入 IDEA 当中做反编译了。
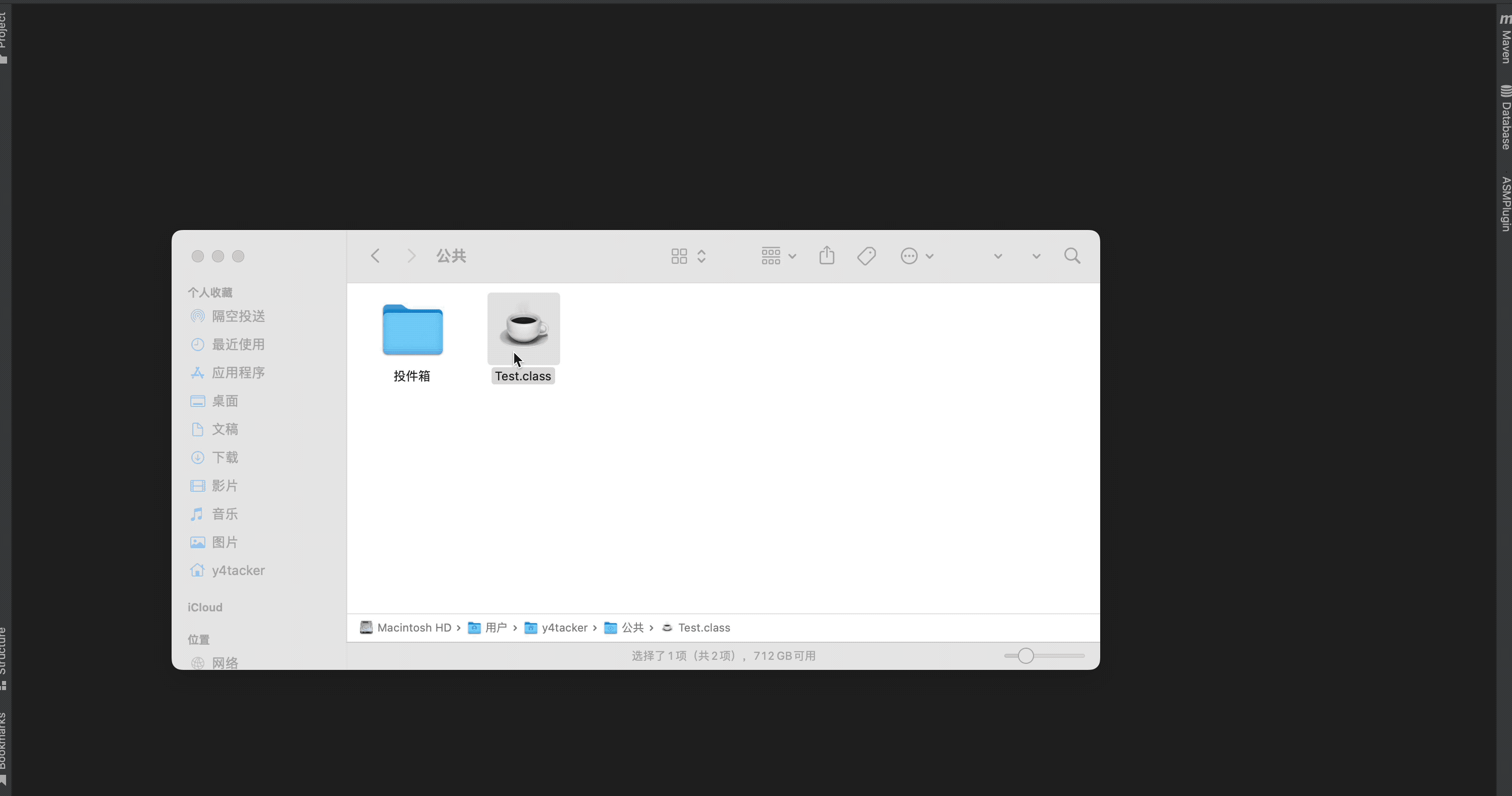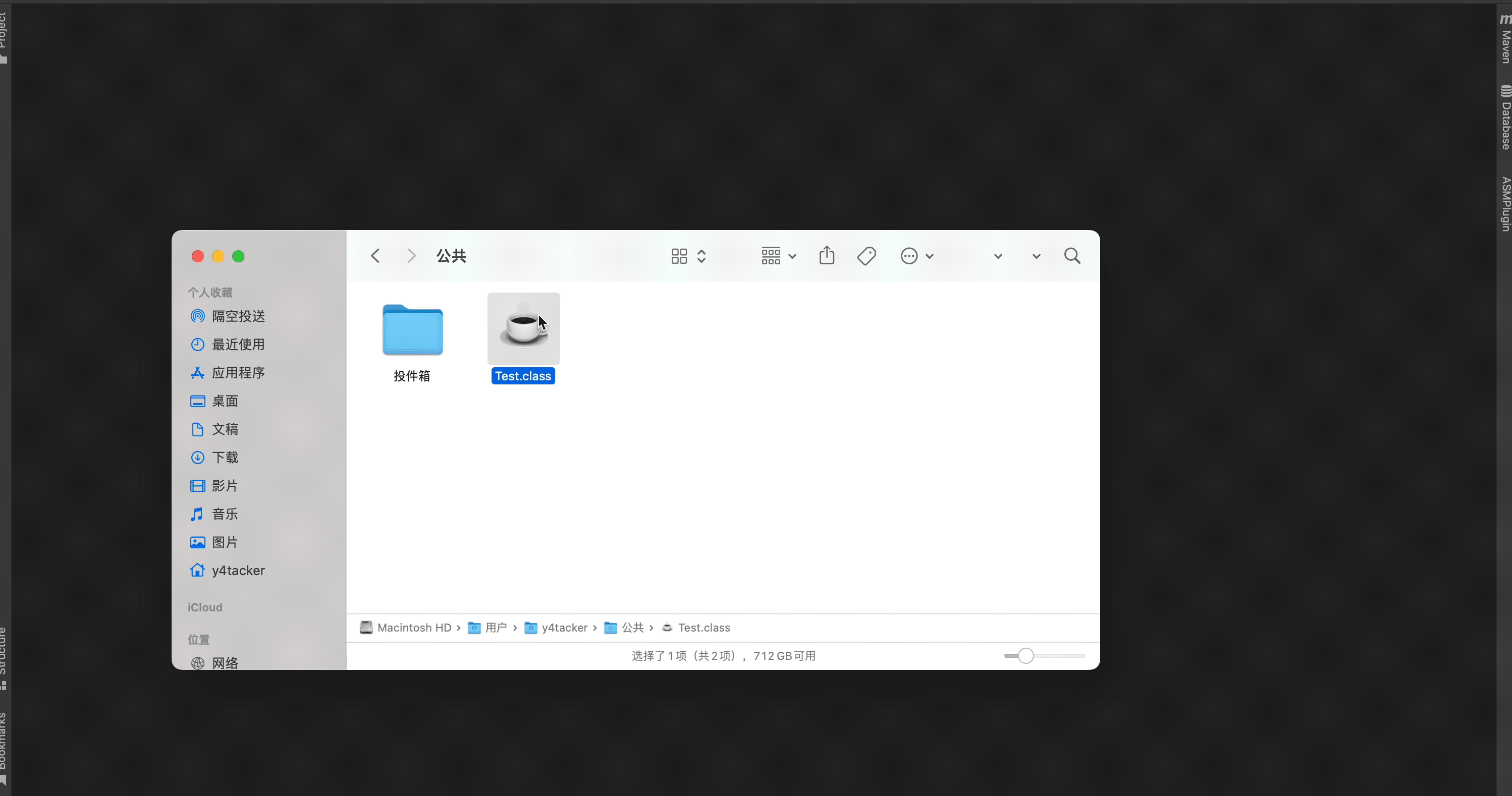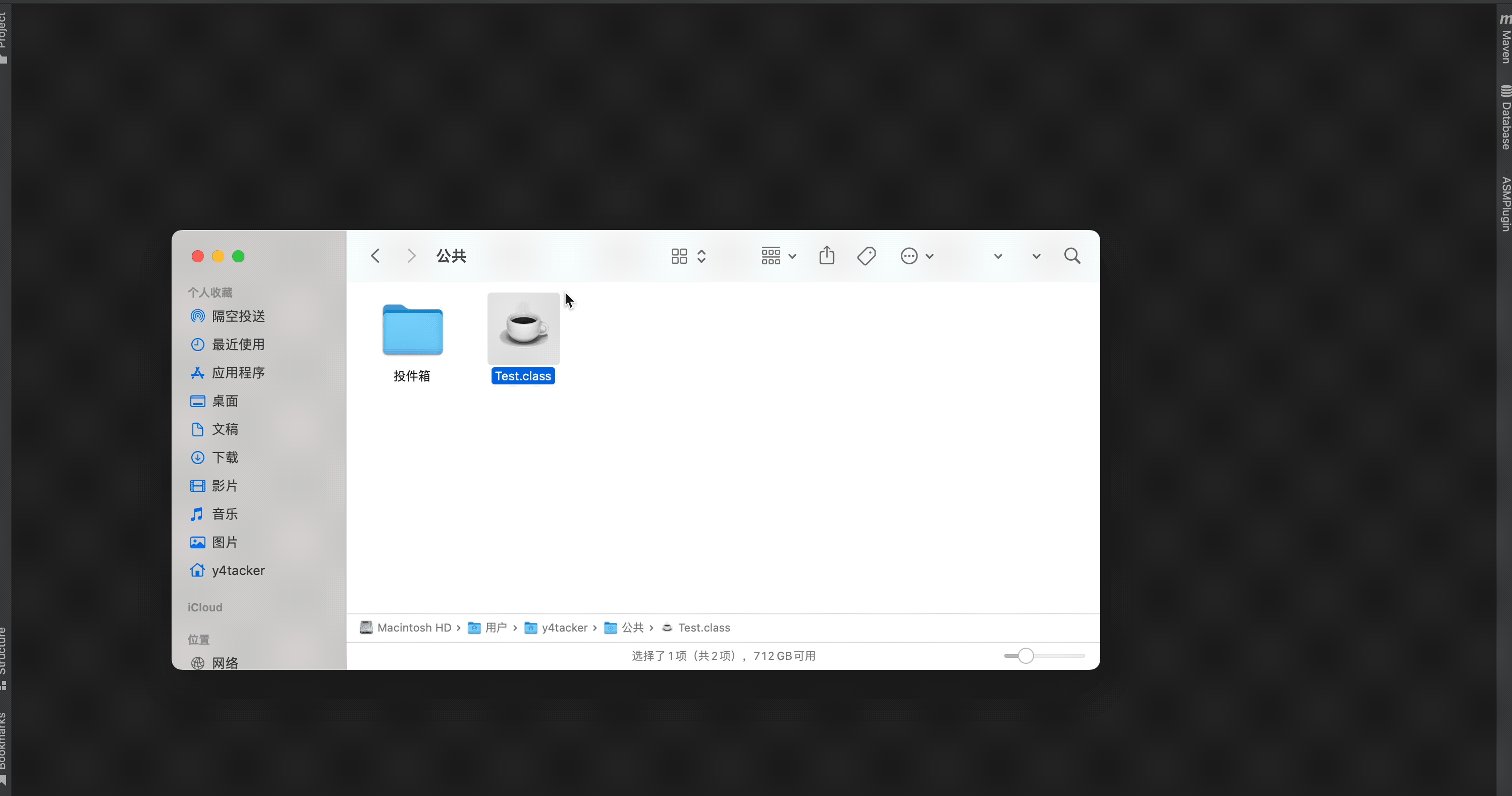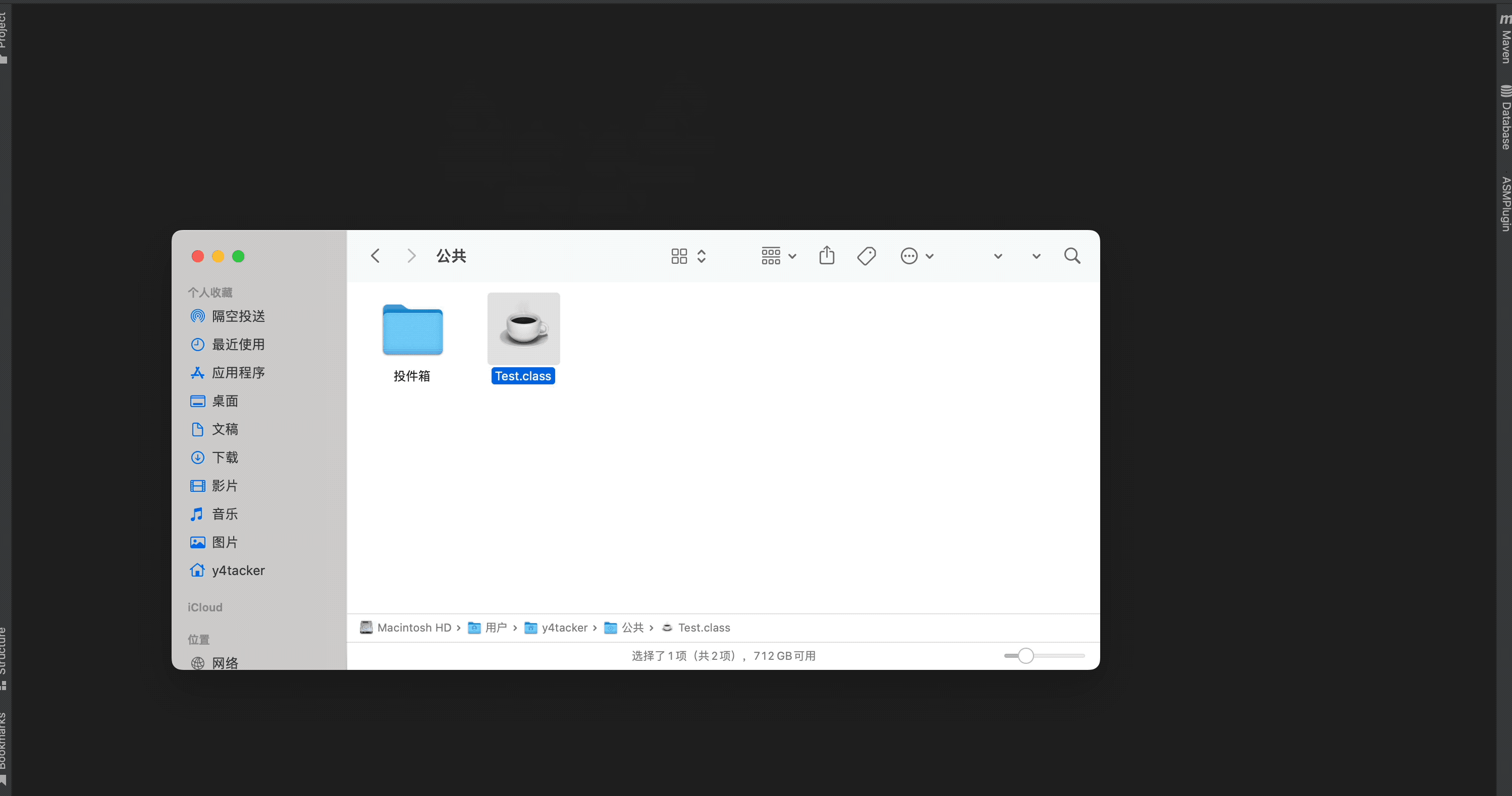
通过手动执行java -cp org.jetbrains.java.decompiler.main.decompiler.ConsoleDecompiler -jar fernflower.jar /Users/y4tacker/Desktop/MCMSv/HackingFernflower/output/Test.class ./testcode,发现可以正常反编译,因此可以猜测和 IDEA 其他组件部分代码有关,这里和主题无关就不继续深入研究了。
同时通过终端查看字节码时也会发现,这里的显示也很混乱(和\r退格键在控制台中的输出作用有关),当然如果你通过javap -v Test将内容输出到文件中打开可正常查看。
关于fernflower的代码可以在 github 上查找到社区版的代码:https://github.com/fesh0r/fernflower。
当然你也可以在 IDEA 中获取到专业版代码,以 mac 为例子,右键程序显示包内容,位置在IntelliJ IDEA.app/Contents/plugins/java-decompiler/lib。
在 org.jetbrains.java.decompiler.main.extern.IFernflowerPreferences 当中有一些默认配置,
这里仅列出了默认激活的属性(值为 1):
defaults.put(REMOVE_BRIDGE, "1");
defaults.put(REMOVE_SYNTHETIC, "0");
defaults.put(DECOMPILE_ENUM, "1");
defaults.put(USE_DEBUG_VAR_NAMES, "1");
defaults.put(USE_METHOD_PARAMETERS, "1");
defaults.put(FINALLY_DEINLINE, "1");
defaults.put(DECOMPILE_INNER, "1");
defaults.put(DECOMPILE_CLASS_1_4, "1");
defaults.put(DECOMPILE_ASSERTIONS, "1");
defaults.put(IDEA_NOT_NULL_ANNOTATION, "1");
defaults.put(NO_EXCEPTIONS_RETURN, "1");
defaults.put(REMOVE_GET_CLASS_NEW, "1");
defaults.put(ENSURE_SYNCHRONIZED_MONITOR, "1");
defaults.put(BOOLEAN_TRUE_ONE, "1");
defaults.put(UNDEFINED_PARAM_TYPE_OBJECT, "1");
defaults.put(HIDE_EMPTY_SUPER, "1");
defaults.put(HIDE_DEFAULT_CONSTRUCTOR, "1");
defaults.put(REMOVE_EMPTY_RANGES, "1");从这些默认配置当中我们发现了几个有趣的配置选项:
REMOVE_BRIDGE(桥接方法)
REMOVE_SYNTHETIC(虽然是0,但是通过IDEA反编译的时候仍然可以做到隐藏的效果,猜测运行时修改了默认属性java -jar fernflower.jar -rsy=1 xxx.class)
USE_DEBUG_VAR_NAMES(对应org.jetbrains.java.decompiler.main.rels.ClassWrapper#applyDebugInfo)
USE_METHOD_PARAMETERS(对应org.jetbrains.java.decompiler.main.rels.ClassWrapper#applyParameterNames)3.1 REMOVE_BRIDGE/REMOVE_SYNTHETIC
3.1.1 隐藏方法
发现这个属性的读取与处理在最终代码的拼接过程,也就是在org.jetbrains.java.decompiler.main.ClassWriter#classToJava。

可以看到如果我们能让 hide 为 true,那么就能让当前方法的输出被跳过。

如何让 hide 为 true,可以看到这里有三个条件,满足其一即可
- mt.isSynthetic() 并且 REMOVE_SYNTHETIC 属性为 1
- 方法是桥接方法并且 REMOVE_BRIDGE 属性为 1
- 在 hiddenmenmers 对象当中
3.1.1.1 isSynthetic/isBridge
在开始前我们可以思考为什么 IDEA 会选择隐藏这两个方法,因为他们都是由编译器生成的方法。
Ps:一些简单的备注,更详细的可以百度看看。
-
桥接方法(bridge method)是为了解决 Java 泛型擦除带来的问题而引入的一个概念。当一个类实现了一个泛型接口或继承了一个泛型类时,由于 Java 的泛型擦除机制,会导致继承或实现的方法签名发生变化,这可能会引发编译器警告或错误。为了解决这个问题,Java 编译器会在编译时自动生成桥接方法,来确保方法签名的一致性。这些桥接方法通常是合成的,它们的目的是将父类中的泛型方法重写为非泛型方法,以便在继承链中保持方法签名的一致性。桥接方法通常是由编译器自动生成的,开发者不需要手动编写桥接方法。在 Java 字节码中,桥接方法的标志通常是 ACC_BRIDGE。桥接方法在 Java 中是一个重要的概念,它确保了在使用泛型时,继承和实现关系的正确性和一致性。
-
synthetic 方法是由编译器生成的、不是由开发人员直接编写的方法。这些方法通常具有特殊的目的,如支持内部类、外部类之间的访问、Java 虚拟机的实现细节等。synthetic 方法通常是私有的,并且在类的字节码中使用 ACC_SYNTHETIC 标志进行标记。
一些常见的情况下会生成 synthetic 方法,如:
- 内部类:当创建内部类时,编译器通常会生成一个 synthetic 方法,用于在内部类中访问外部类的私有成员变量或私有方法。
- 枚举类:对于枚举类,编译器会生成一个包含所有枚举值的静态 final 数组,并且生成一个 synthetic 方法用于访问这个数组。
- Lambda 表达式:在使用 Lambda 表达式时,编译器可能会生成 synthetic 方法来支持 Lambda 表达式的执行。
首先来看如何满足 isSynthetic 的条件,修饰符带 ACC_SYNTHETIC 即可,或者带 Synthetic 属性即可。
public boolean isSynthetic() {`
return hasModifier(CodeConstants.ACC_SYNTHETIC) || hasAttribute(StructGeneralAttribute.ATTRIBUTE_SYNTHETIC);
}
public static final Key<StructGeneralAttribute> ATTRIBUTE_SYNTHETIC = new Key<>("Synthetic");那么我们可以通过 ASM 很简单的为方法添加修饰符(ACC_BRIDGE/ACC_VOLATILE/ACC_STATIC_PHASE 都是 0x0040)。
cw.visitMethod(ACC_PUBLIC | ACC_SYNTHETIC, "abc", "()V", null, null);
cw.visitMethod(ACC_PUBLIC | ACC_BRIDGE, "abc", "()V", null, null);
cw.visitMethod(ACC_PUBLIC | ACC_VOLATILE, "abc", "()V", null, null);
cw.visitMethod(ACC_PUBLIC | ACC_STATIC_PHASE, "abc", "()V", null, null);如何通过 ASM 为方法添加属性,调用methodVisitor.visitAttribute(new SyntheticAttribute());即可。
Ps:自定义实现的 SyntheticAttribute 类构造函数当中的 super 代表属性的 type。
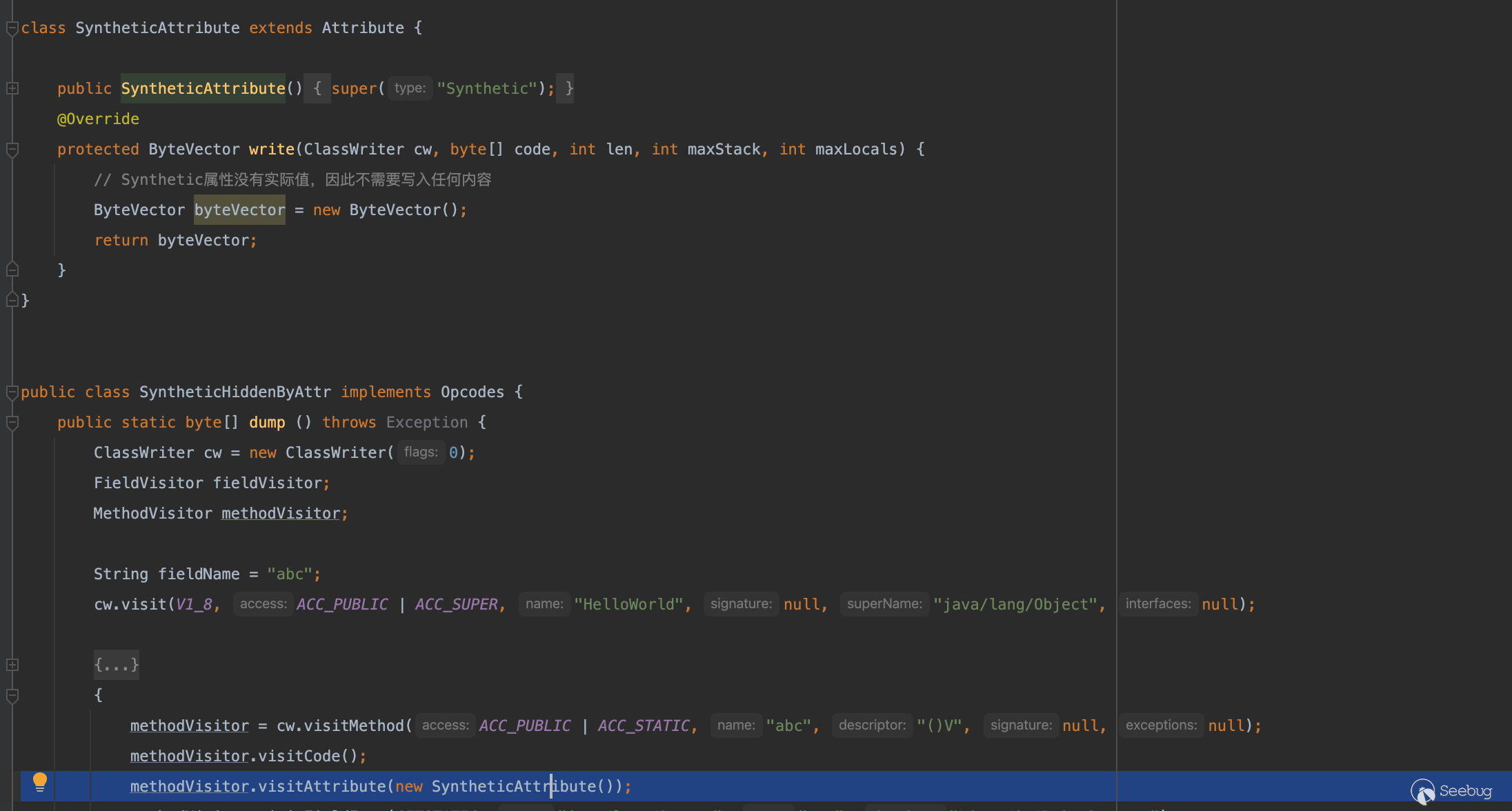
成功实现对 abc 方法的隐藏:
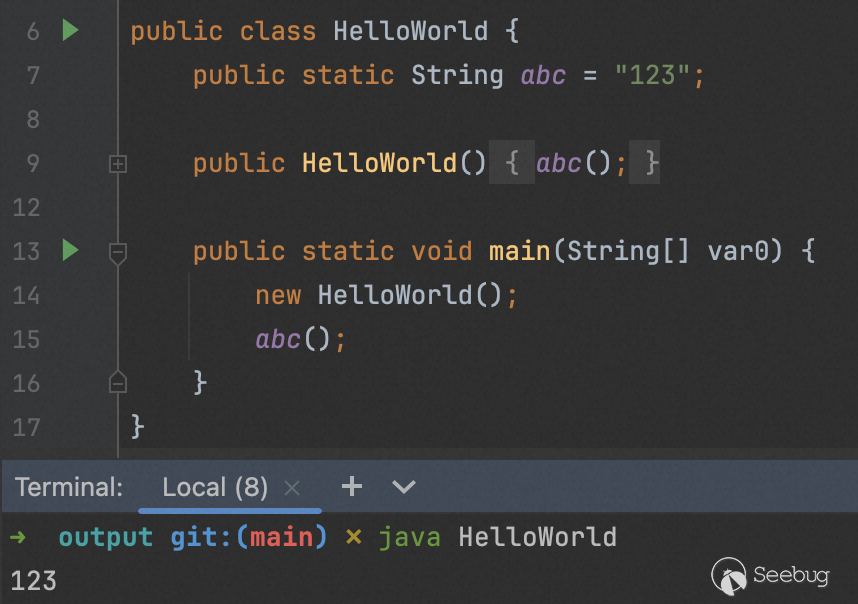
对于桥接方法的条件,和上面同理,不再重复讲解,这里仅列出效果图:
3.1.1.2 如何转换一个类(备注篇)
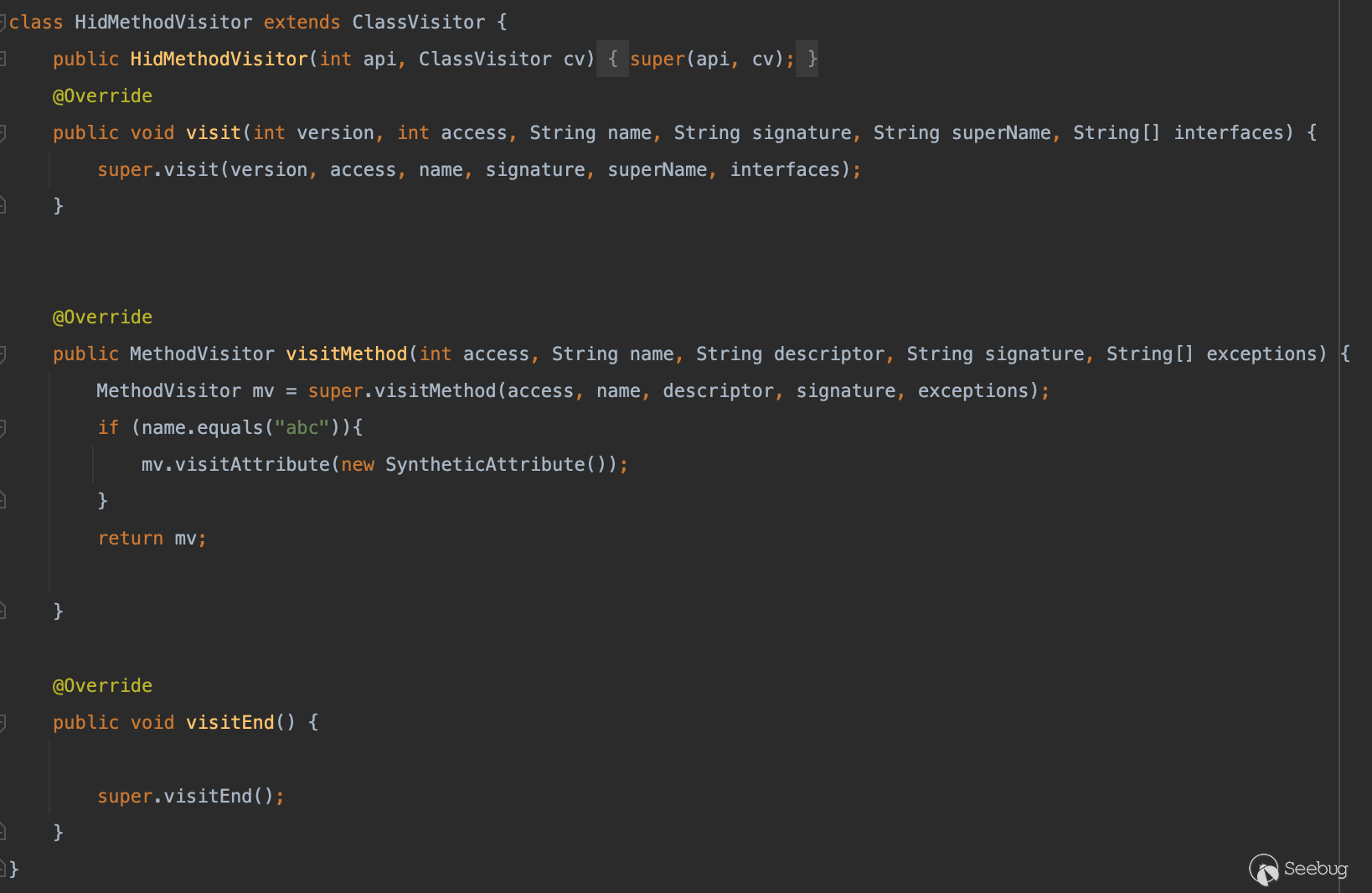
可能有人会好奇能不能通过 ASM 转换现有的方法呢?当然可以。
写一个类继承 ClassVisitor:
串联ClassWriter即可:
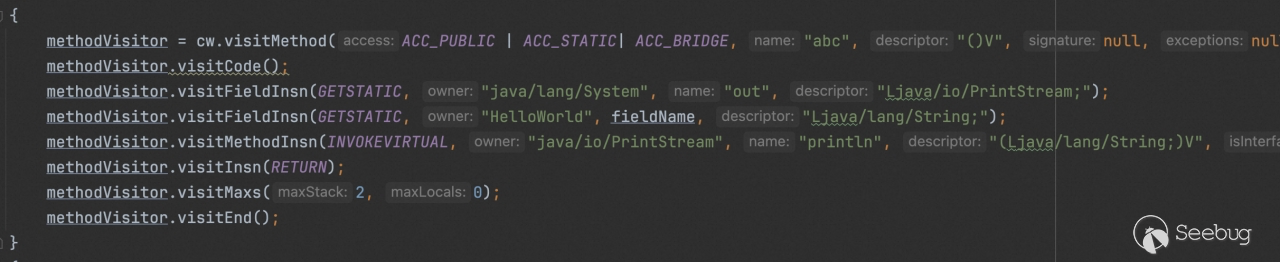
结合 IDEA 的显示特性达到迷惑效果,同时我们在隐藏的方法当中加点料,比如执行一个计算器。
3.1.1.3 hiddenMembers 对象
过查找发现 hiddenMembers 的添加主要在几个 Processor 方法下。
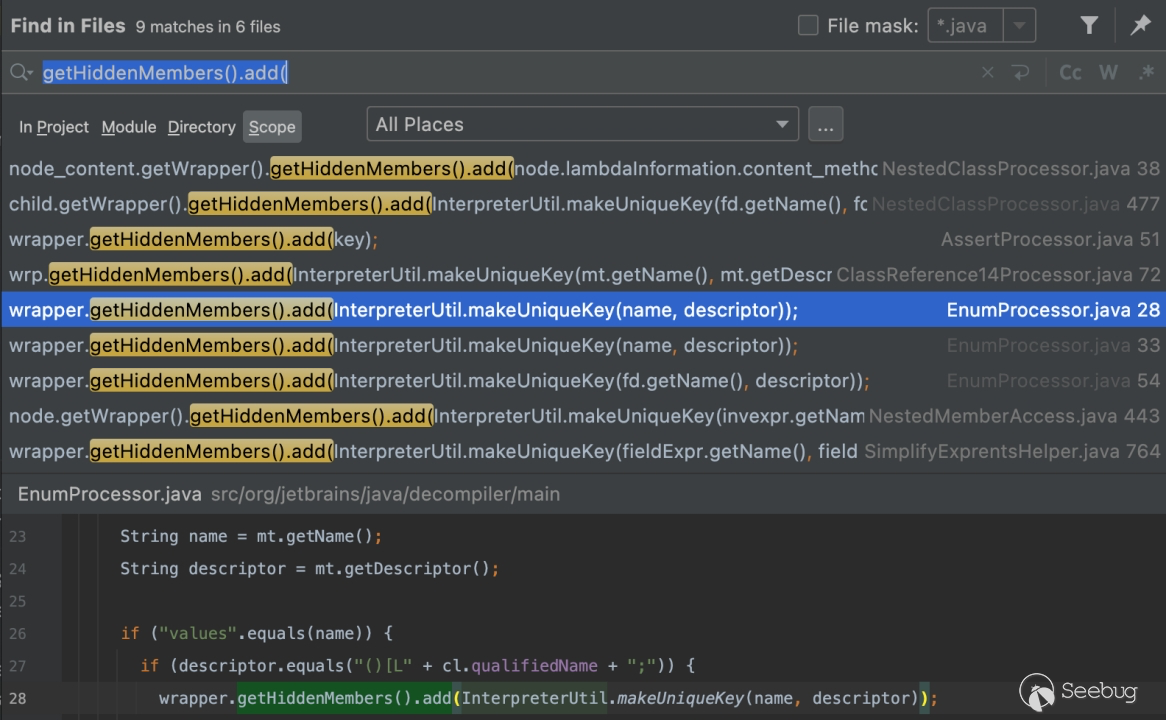
和方法相关的比较好用的有 EnumProcessor 和 ClassReference14Processor,这里仅以 EnumProcessor 为例。
在下图中可以看到,只需要满足两者任一分支即可,其中 name 参数代表方法名。
以第一个分支为例子,方法名为 values,然后描述符满足下面的情况。
入参为空,返回值为当前对象的数组。
(其中()代表入参为空,[为数组,中间的变量为全类名利用方法的重载)。
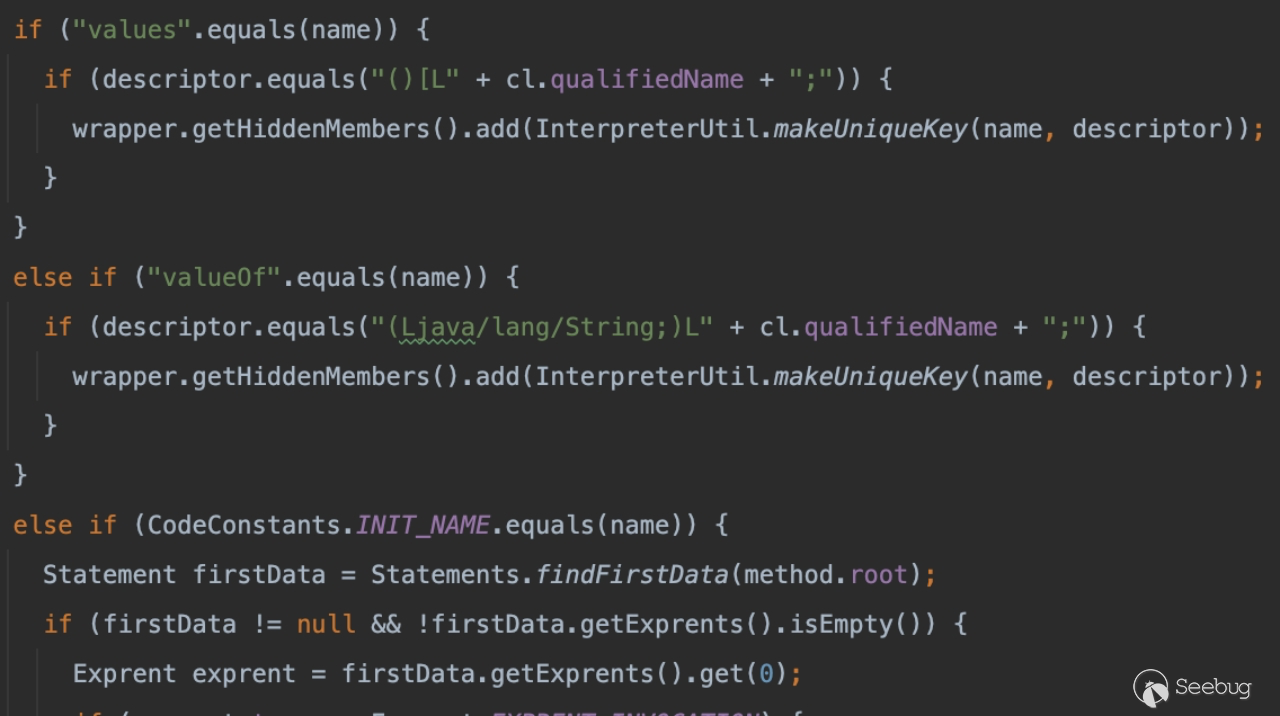
甚至更进一步,我们可以结合方法重载的特性,再搞一个同名方法迷惑视线:
3.1.2 隐藏字段
同理满足任一条件即可:
- isSynthetic 并且 REMOVE_SYNTHETIC 属性为 1
- 在 Hiddenmenmers 对象当中
3.1.2.1 isSynthetic
isSynthetic 条件同上,修饰符或添加属性,具体可查看我的代码,位置在src/main/java/hidden/field/Synthetic
public boolean isSynthetic() {
return hasModifier(CodeConstants.ACC_SYNTHETIC) || hasAttribute(StructGeneralAttribute.ATTRIBUTE_SYNTHETIC);
}3.1.2.2 hiddenMembers 对象
同理仅选一个为例子演示。
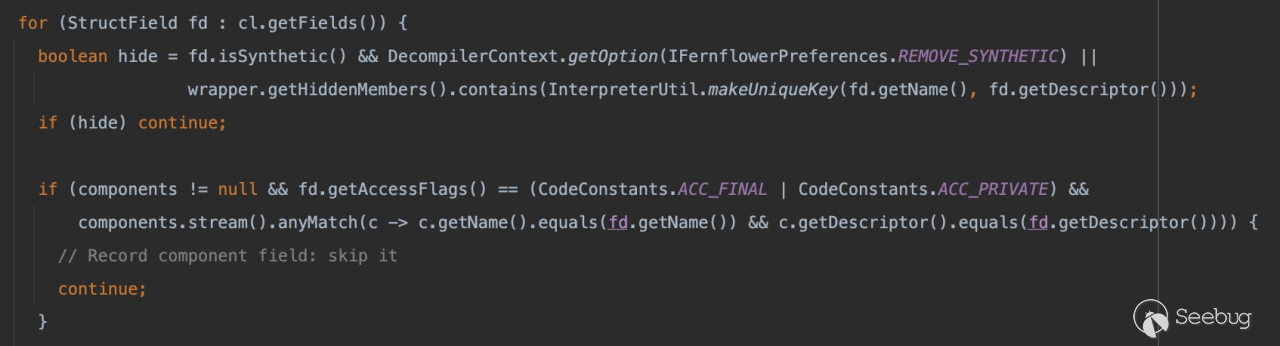
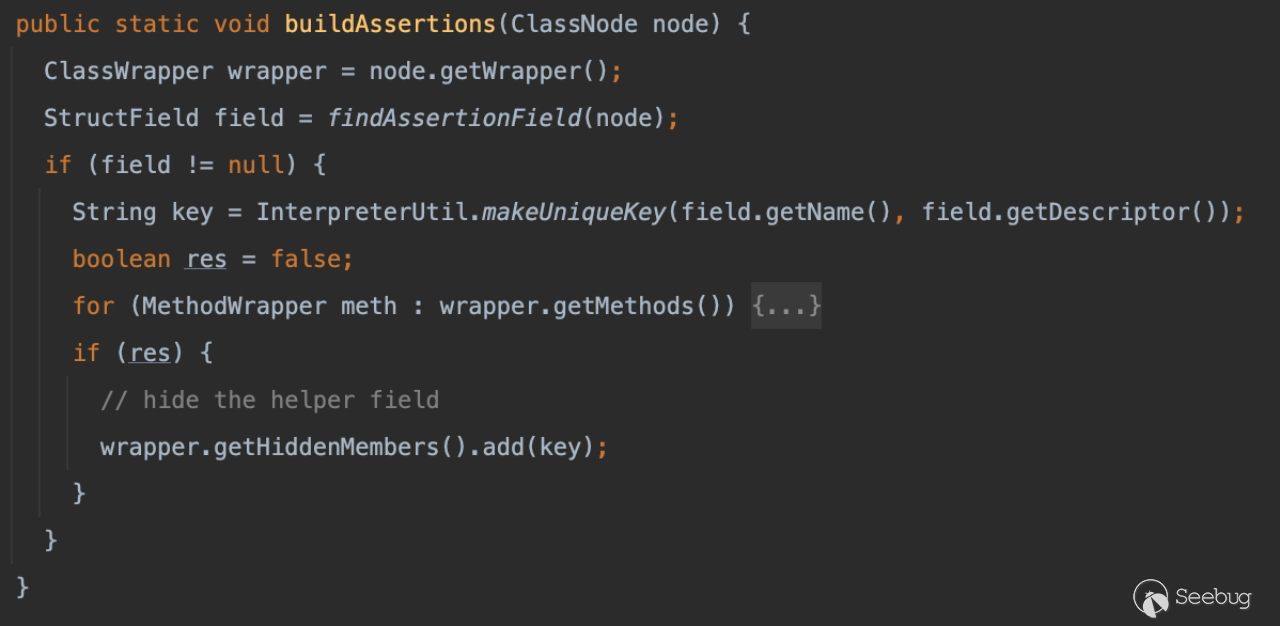
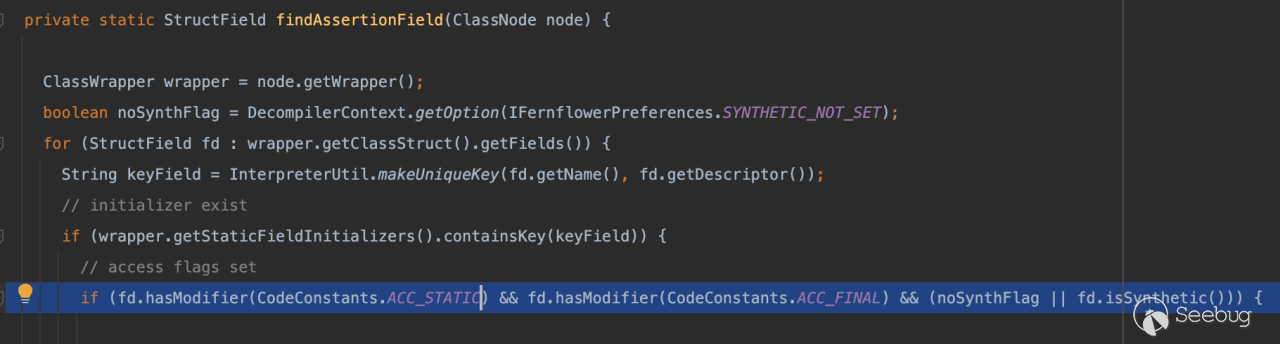
在org.jetbrains.java.decompiler.main.AssertProcessor#buildAssertions中对 hiddenMembers 添加了字段对象的处理,如果findAssertionField返回不为空即可实现添加。
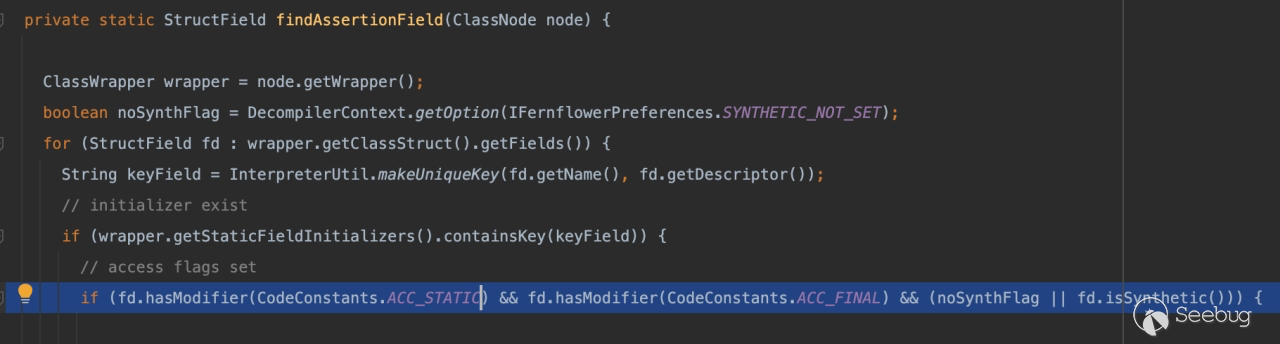
条件很简单字段为 Static\Final\Synthetic修饰即可:
cw.visitField(ACC_PUBLIC | ACC_STATIC | ACC_FINAL| ACC_SYNTHETIC, fieldName, "Ljava/lang/String;", null, null);
运行发现,字段也做到了隐藏的效果。
3.2 自定义方法参数
3.2.1 一些需要知道的基础知识
Java 字节码的 attribute_info 用于存储与类、字段、方法、代码等相关的附加信息。它是一个可选的部分,可以用来提供一些额外的元数据或调试信息。
attribute_info 结构包含以下几个字段:
- attribute_name_index:一个指向常量池中 UTF-8 类型常量的索引,表示 attribute 的名称。
- attribute_length:一个无符号的 32 位整数,表示 attribute 的长度,单位为字节。
- info:包含实际的 attribute 信息。
JVM 在运行时并不直接关注字节码中的 attributes,它主要关注的是字节码指令和运行时数据。
虽然 JVM 不会直接关注 attributes,但是这些 attributes 在运行时仍然有一定的作用。
例如,Code attribute 中包含了方法体的字节码指令、异常处理器、局部变量表等信息。JVM 在执行方法时会解析这些字节码指令,并根据异常处理器处理异常,同时也会使用局部变量表来存储方法中的局部变量。另外,LineNumberTable attribute 中包含了源码行号和字节码行号的对应关系,这对于调试非常有用。当发生异常或进行追踪时,JVM 可以使用这些信息来显示源码的行号,帮助开发人员进行调试。
3.2.2 METHOD_PARAMETERS
我们可以在代码中自定义一些调试信息,这与默认配置中的USE_METHOD_PARAMETERS/USE_DEBUG_VAR_NAMES有关。
这里我们仅仅关注 METHOD_PARAMETERS 即可。
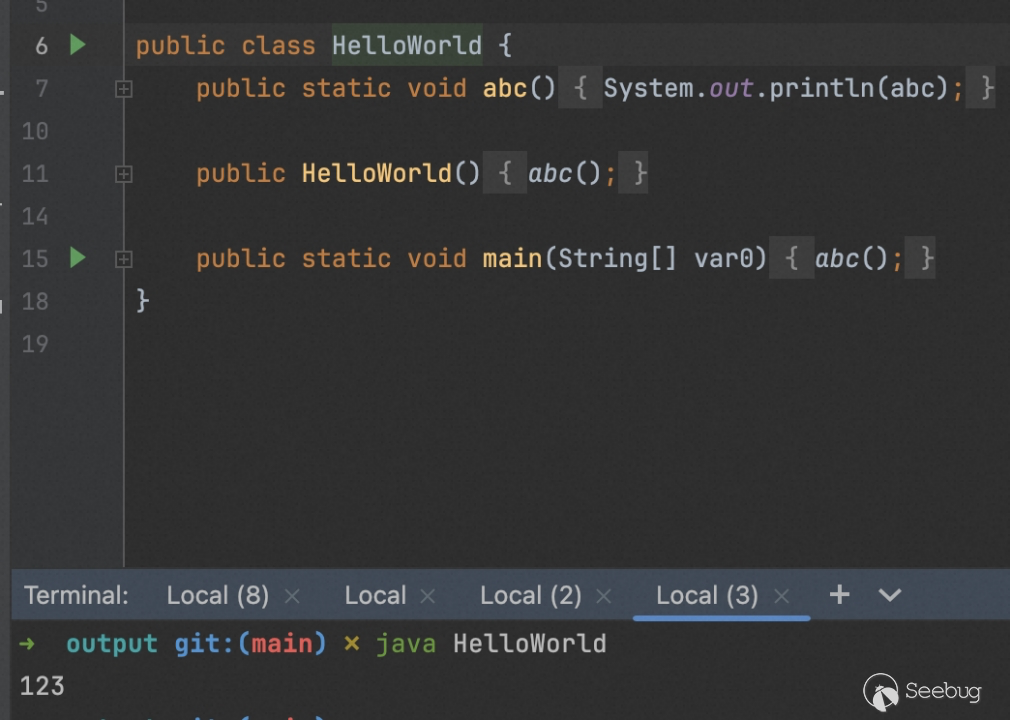
不知道大家有没有发现一个现象,自己在 IDEA 写的类,反编译后可以看到,方法的参数名都是有一些特定含义的。
但是从网上下载的代码却没有(因为被做了优化将属性做了移除)。
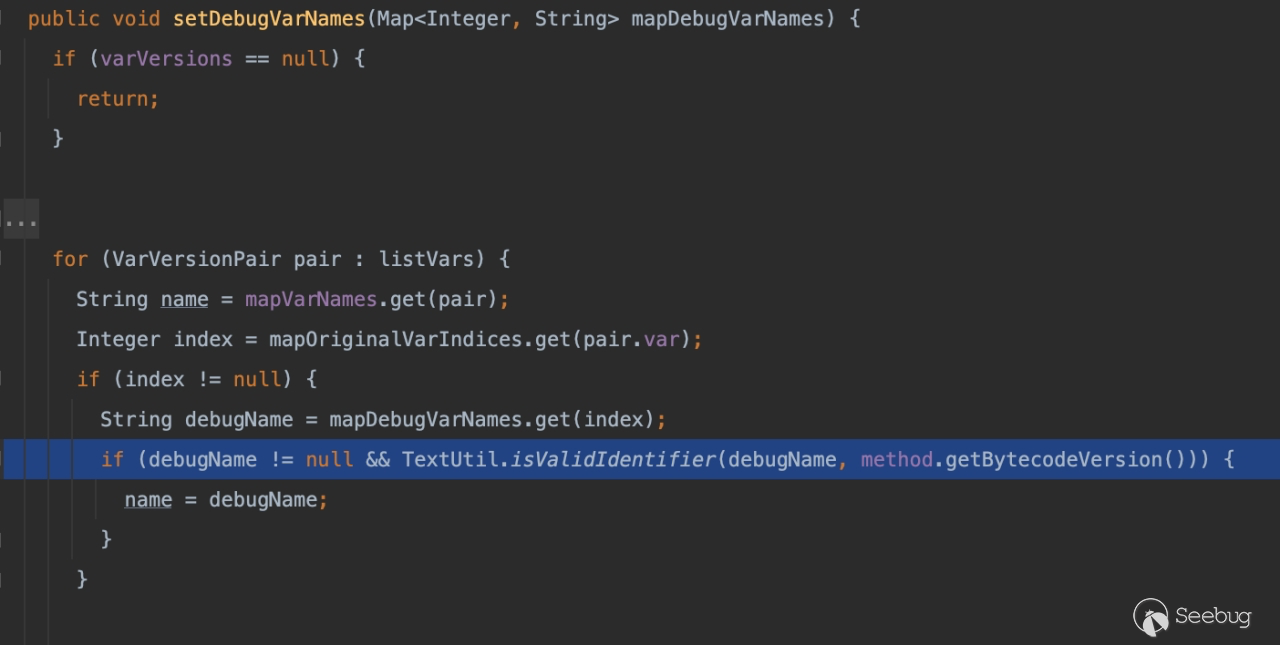
USE_DEBUG_VAR_NAMES(对应处理org.jetbrains.java.decompiler.main.rels.ClassWrapper#applyDebugInfo)
USE_METHOD_PARAMETERS(对应处理org.jetbrains.java.decompiler.main.rels.ClassWrapper#applyParameterNames)仔细阅读代码你会发现其实这两个参数最终效果是一致,但是 USE_METHOD_PARAMETERS 在 IDEA 的代码层没有做参数的限制(jdk8 测试无,但是较高版本 java[jdk<=8u271] 运行时也有限制了,限制条件同 USE_DEBUG_VAR_NAMES,当然其实这些限制都无所谓),而 USE_DEBUG_VAR_NAMES 则有。
 通过简单的 fuzz 发现限制蛮大的(部分输出)。
通过简单的 fuzz 发现限制蛮大的(部分输出)。
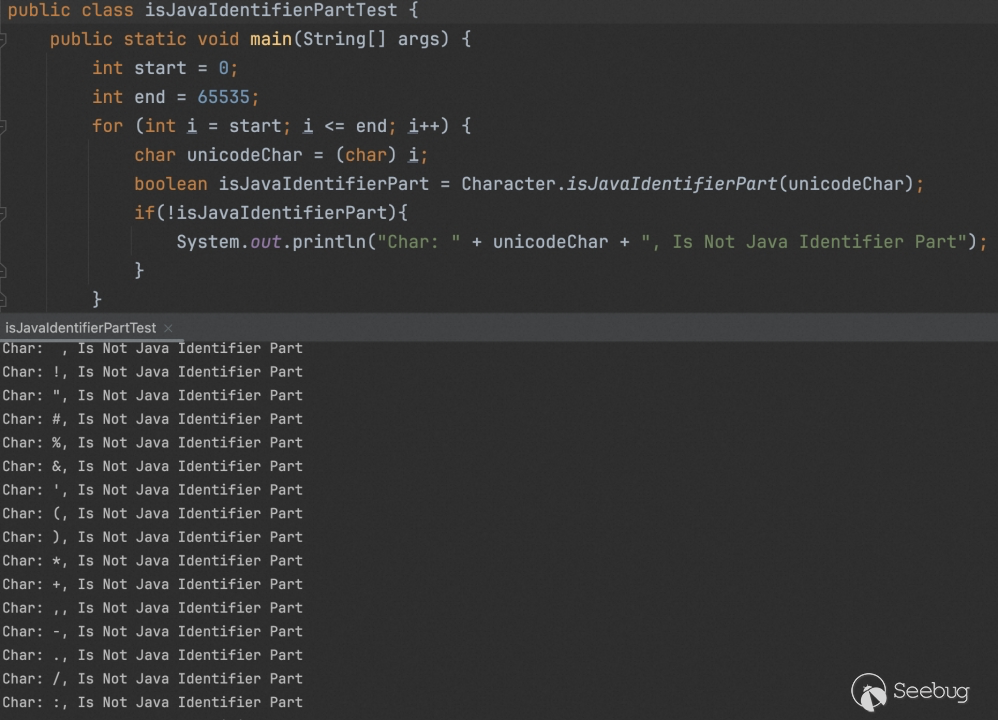
因此,在这里我们以 USE_METHOD_PARAMETERS 的构造为主。
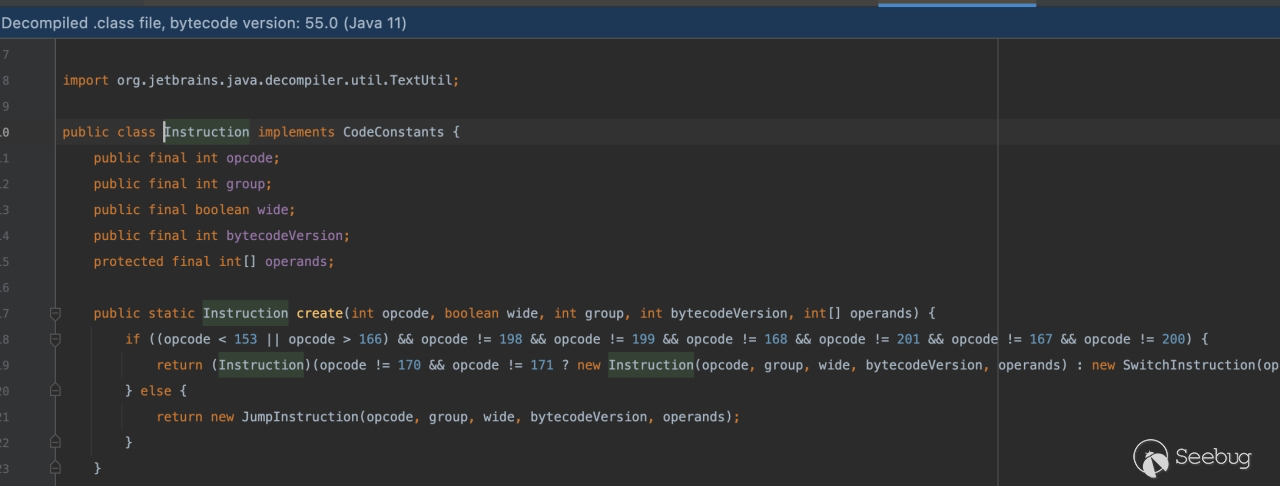
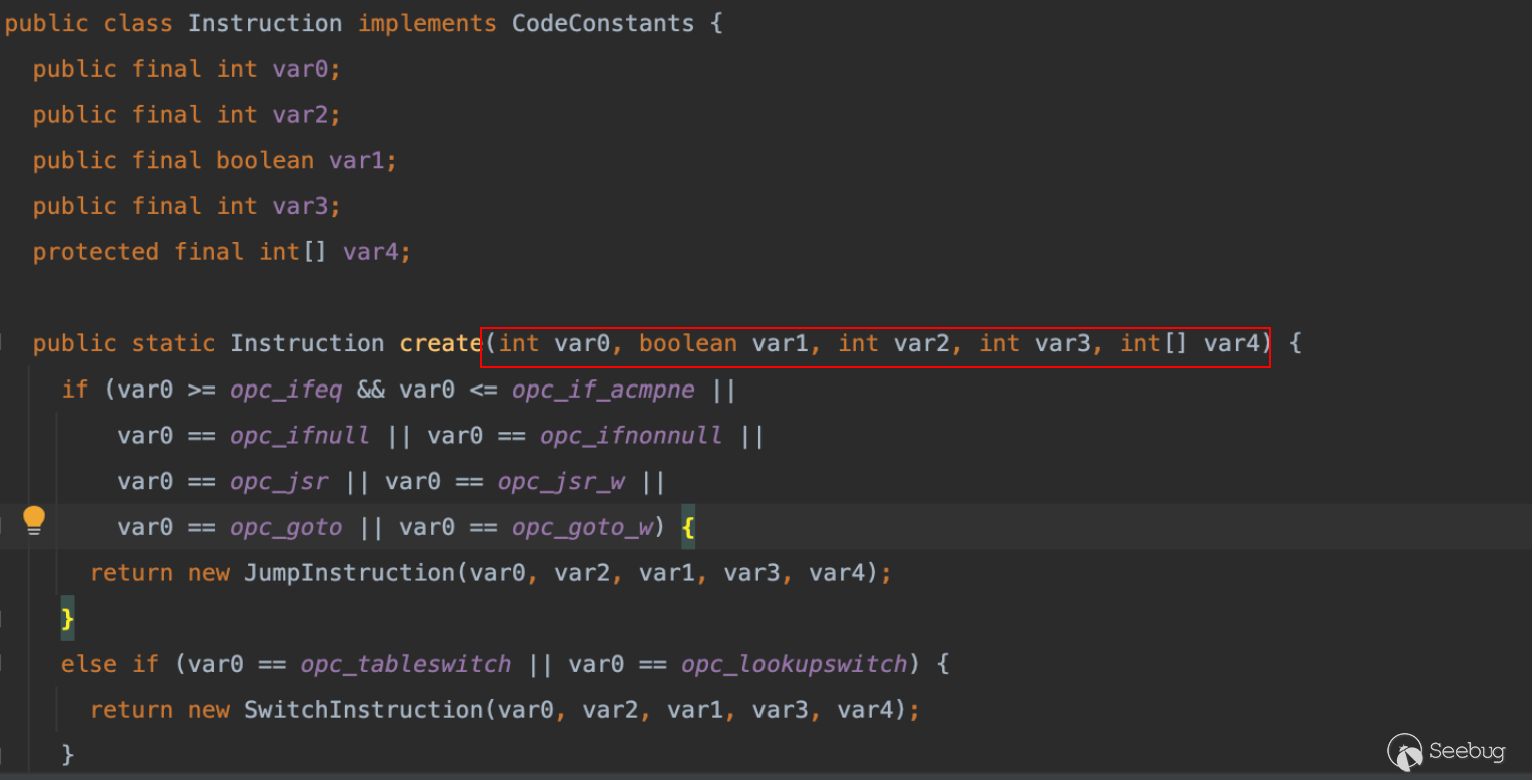
查看它的处理流程,其实很简单,获取方法中的MethodParameters属性,再通过 for 循环便利建立字段的映射。
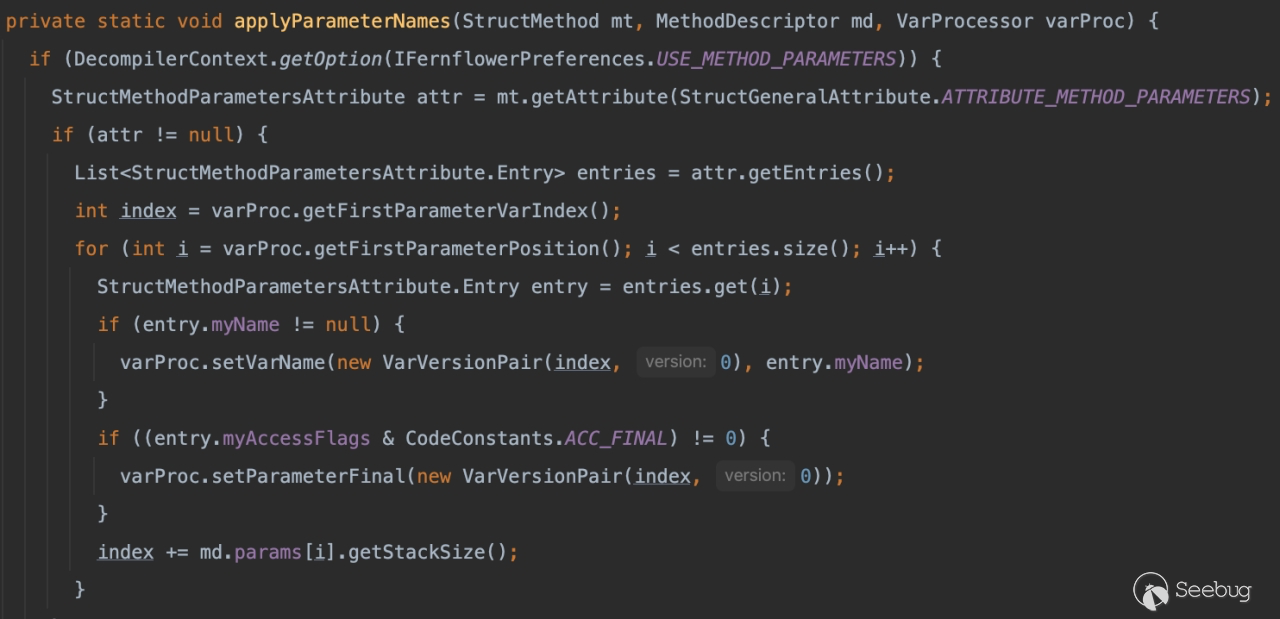
既然限制我们已经知道了 IDEA 是如何处理的,那么接下来就需要知道这些属性是如何传入。
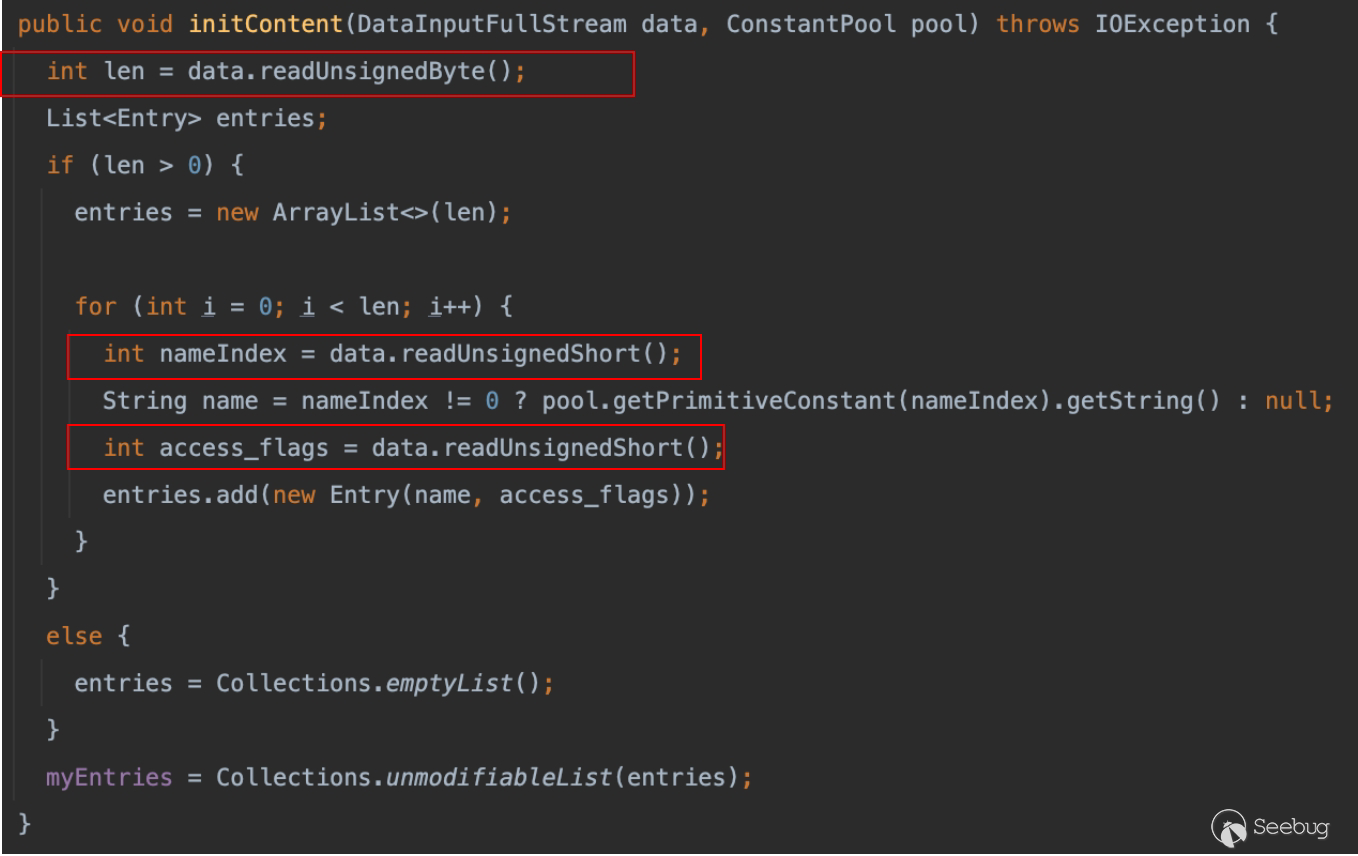
在类的初始化解析过程当中,其中方法参数的解析在(org.jetbrains.java.decompiler.struct.attr.StructMethodParametersAttribute#initContent)
可以看到如下图的解析步骤:
- 读取方法参数个数
- 读取方法的参数名在本地变量表当中的映射(关键)
- 读取方法参数类型
 那么在接下来我们便开始构造属性,继承 Attibute 类重写其 write 方法来实现自定义的写入,这里我比较偷懒的写了一个,能用就行。
那么在接下来我们便开始构造属性,继承 Attibute 类重写其 write 方法来实现自定义的写入,这里我比较偷懒的写了一个,能用就行。
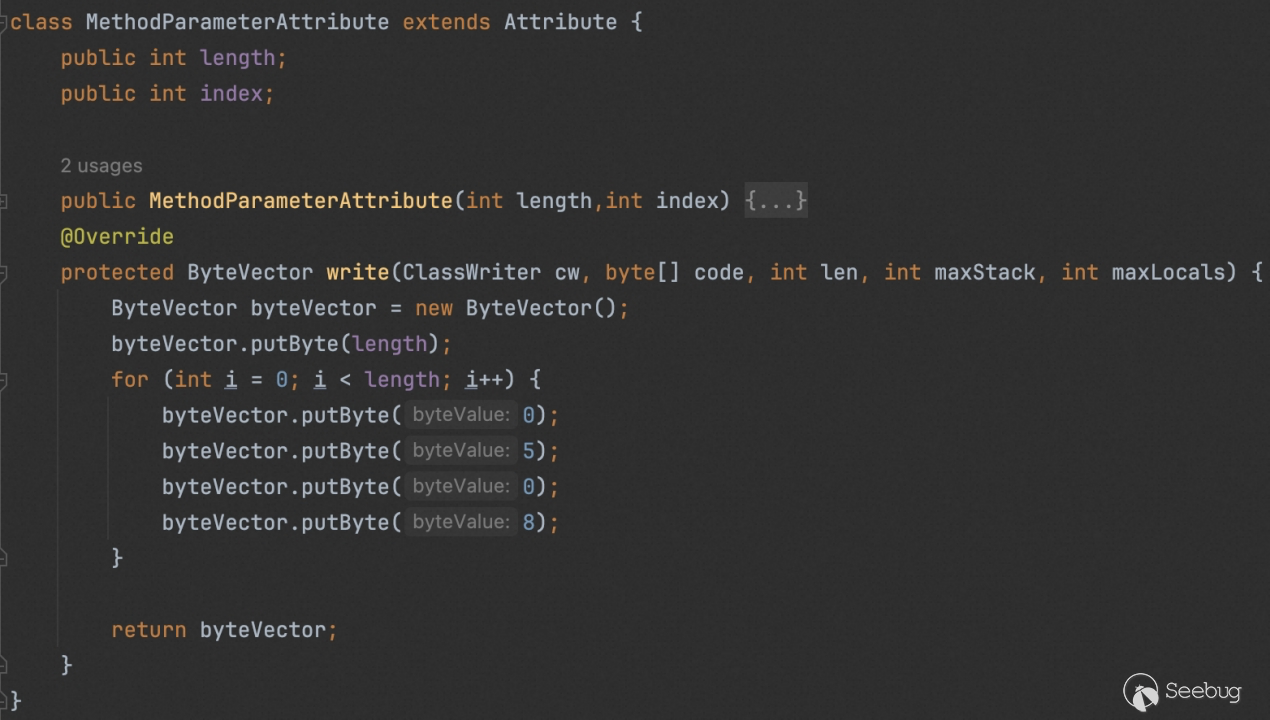
调用mv.visitAttribute(new MethodParameterAttribute(3,5));即可实现属性添加。
Ps:老版本会有一点 BUG,函数名中显示没问题,在具体函数功能中仍继续使用了 var0/var1/var2/varxx,这里我是最新版 IDEA。
在这里我们可以看到所有的方法参数都被我们修改为同一名字,大大加大了阅读理解代码的难度。
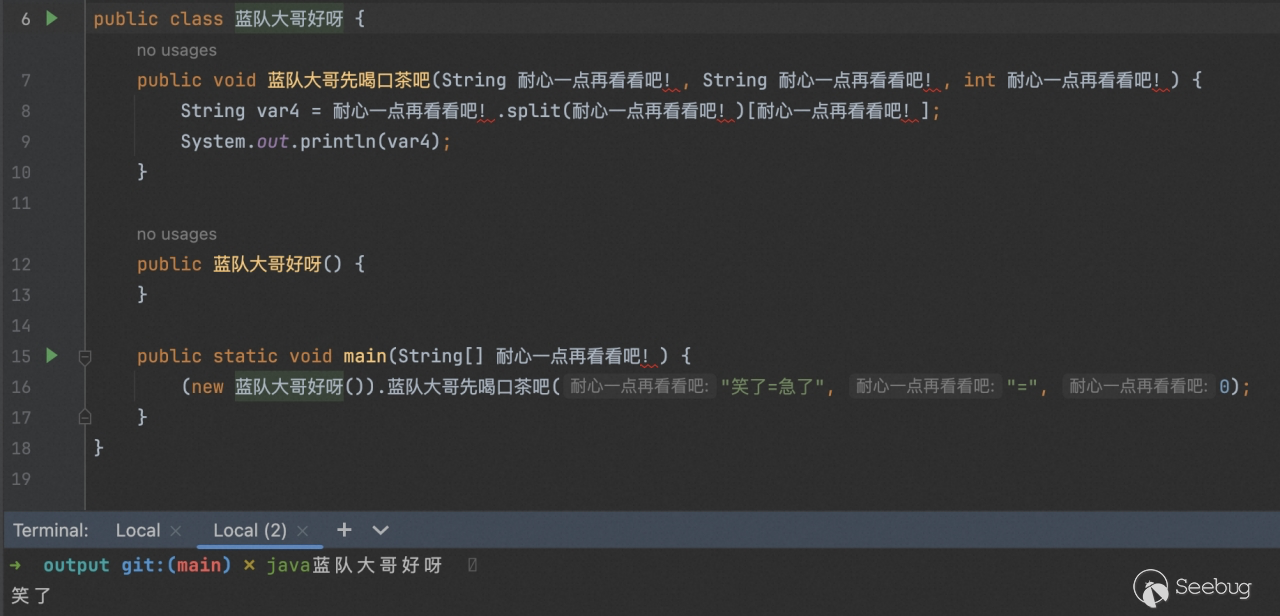 虽然在较高版本中也对 fieldname 做了限制,但也只是一些特殊符号的限制,简单写首诗还是可以的(小皮一下),以 jdk11 为例。
虽然在较高版本中也对 fieldname 做了限制,但也只是一些特殊符号的限制,简单写首诗还是可以的(小皮一下),以 jdk11 为例。
(忽略颜色变成白底了找了张老图懒得自己打字了)
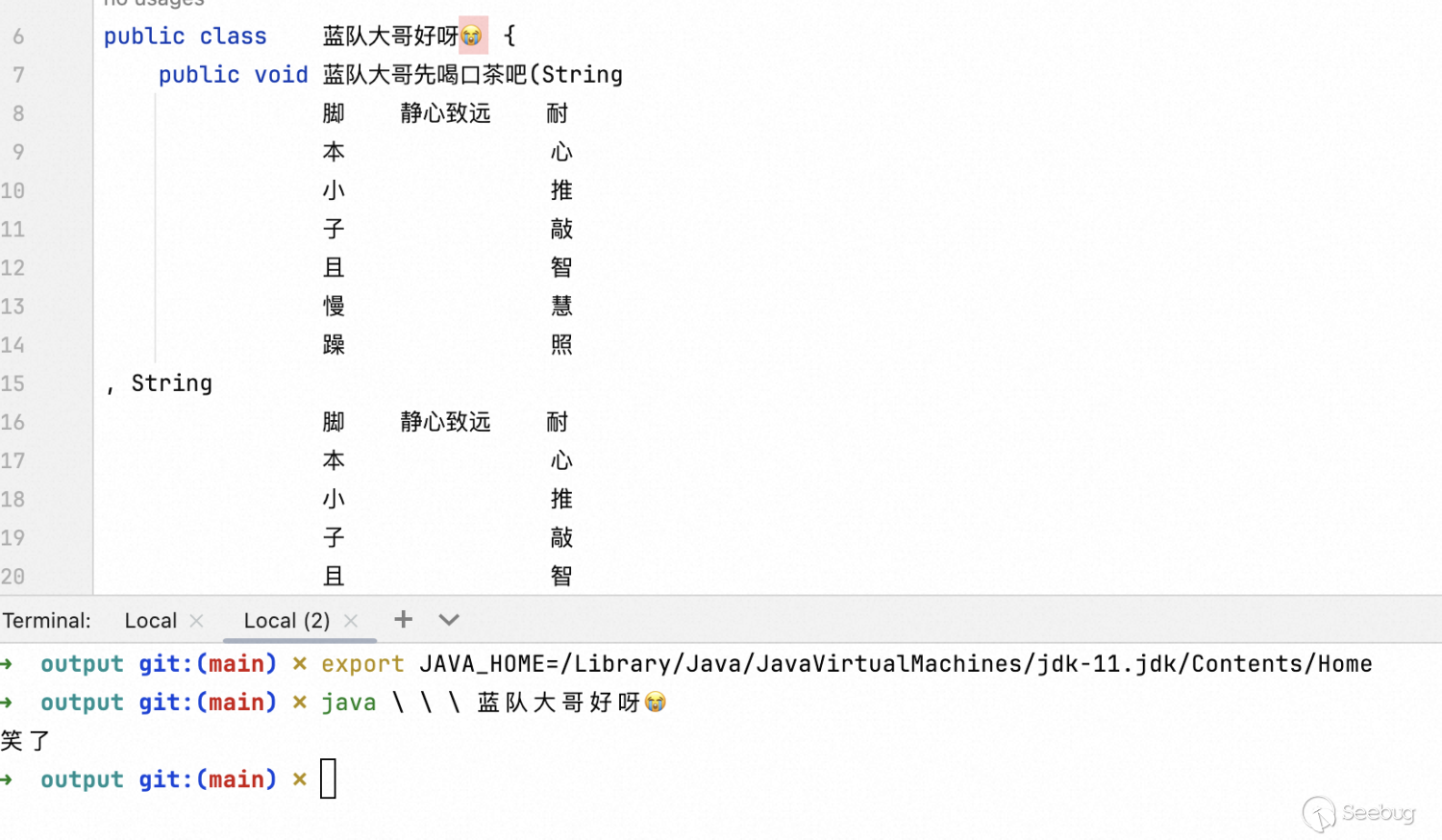
3.3 属性上还能做什么?
上面也提到了,Java 运行时一般而言对属性没有直接的依赖,利用这一点我们便可以想想能不能控制属性让 IDEA 在反编译的过程中报错导致反编译过程提前结束,当然其实有好几种办法,这里我们仅以其中一个为例,这串代码其实就是上面讲到的方法参数的处理过程。
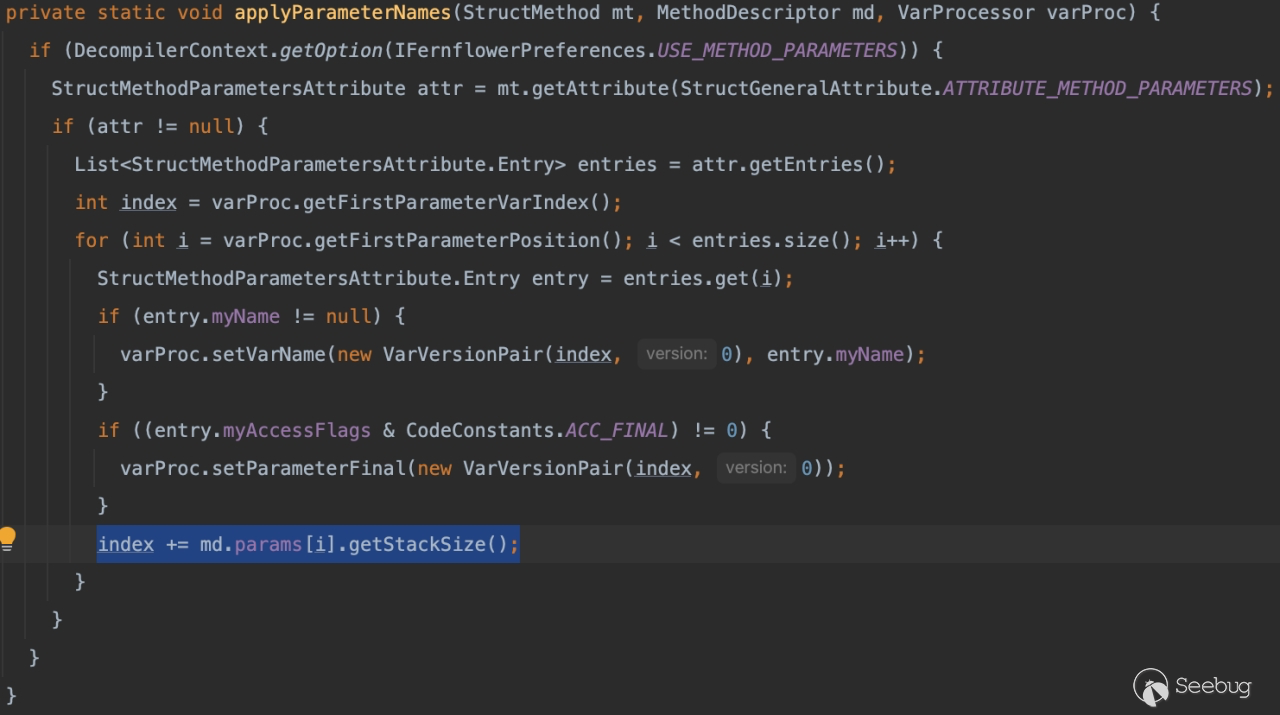 我们可以看到有个对
我们可以看到有个对md.params[i]的数组下标取值的过程,这时候如果我们多在属性中添加一位,就会因为发生组越界导致反编译失败(比如一个方法拥有三个参数,我们在属性中声明它拥有四个参数)。
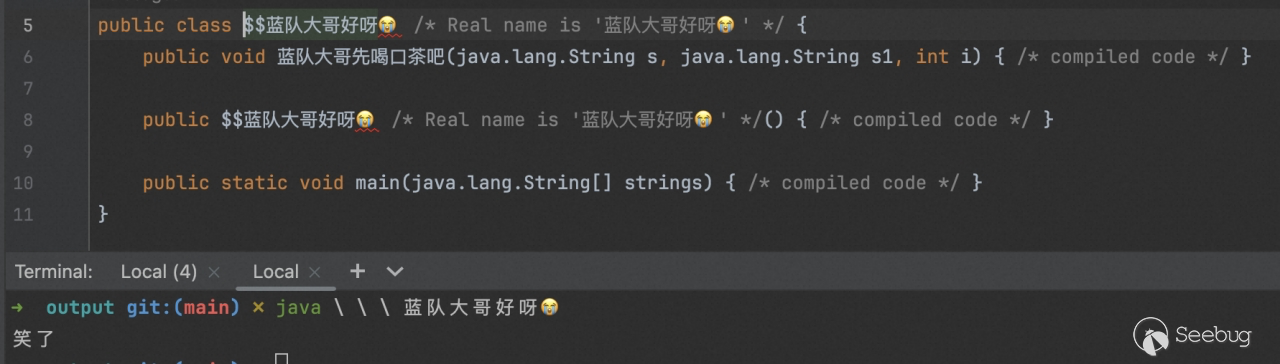
查看代码效果,此时反编译因出错提前退出,显示效果如图:
3.4 再进一步,简单反制 IDEA
既然都看了方法的参数了,那么不妨再往上看看,方法参数又是怎么解析的呢?
仅看这一串代码你能发现什么么?注意我的光标
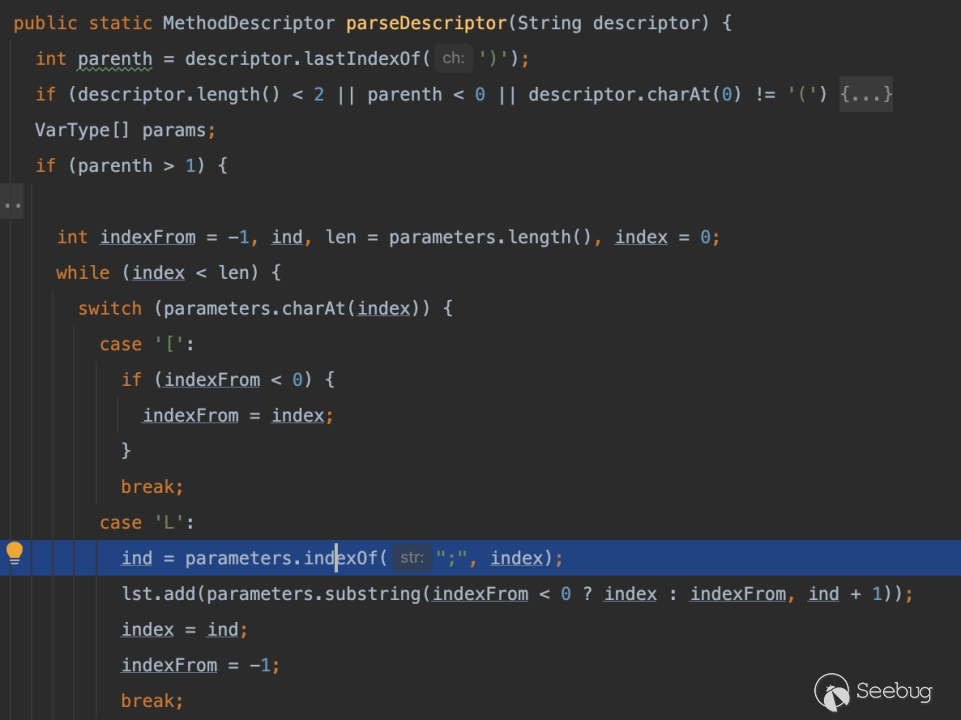
以(Ljava/lang/String;)Ljava/lang/String;为例
- 先获取最后括号内的内容
- 第一位 L 进入 Case ‘L'分支
- 让 index 为 ; 所在位置下标
而如果我们不写上最后一个;符号,对java 来说一般找不到默认为 -1,导致反编译永远卡在这个 while 循环当中,实现一个 DOS 攻击。
Ps:很狗的是很早之前我给官方提出了这个问题,他们表示并不 care 也不会做修复,但是在我写 PPT 前几天无意中更新了 IDEA 发现似乎被修复了??具体原因还未查看(懒)。
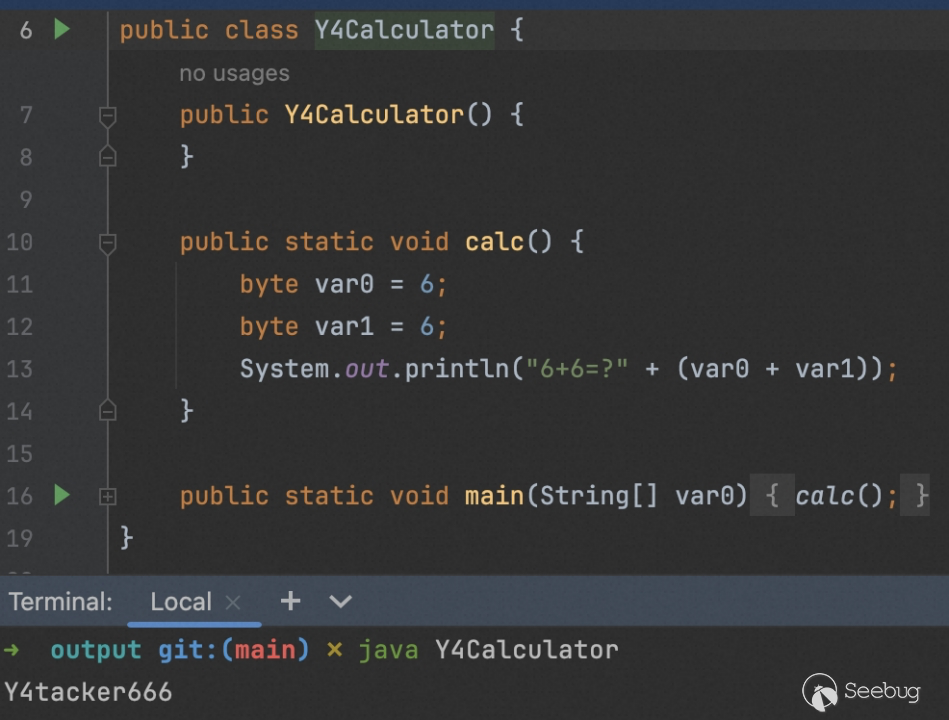
这时候有人会问,既然都破坏了类的完整性,那么肯定都无法运行了,确实如此,但是换个角度,如果我们向我们的 jar 文件当中存入多个这样的 class,当有人想反编译 jar 查看代码的时候,不小心点到了这个类,是不是就会触发小惊喜(手动狗头)。
3.5 还能隐藏什么?(神奇的 JSR)

刚刚我们已经实现了对方法以及字段的隐藏,还能隐藏什么呢?通过阅读反编译的源码我发现了个有趣的指令 jsr,在过去它是和 ret 指令成对出现,用于实现 try-catch 当中的 finally 快,但随着 jvm 的发展后面被移除了,但是 java 的运行有着向下兼容的特性,因此我们仍然是能使用这个指令。
| astore | 栈顶引用类型保存到本地变量 |
|---|---|
| jsr | 跳转指定地址,并压入下一条指令地址 |
| ret | 返回指定的指令地址 |
首先通过下面的例子带大家简单了解下 JSR 的使用,在这里通过 JSR 跳转到了 label1,在这个过程中会将下一条指令的地址压入栈中,之后执行完Code Here,我们通过 ASTORE 将栈上地址保存到本地变量表当中指定位置,并通过 RET 指令实现对Continue Code Here的继续执行。

利用这个 jsr 我们能达到这样的混淆效果,可以看到实际运行与显示不符合。
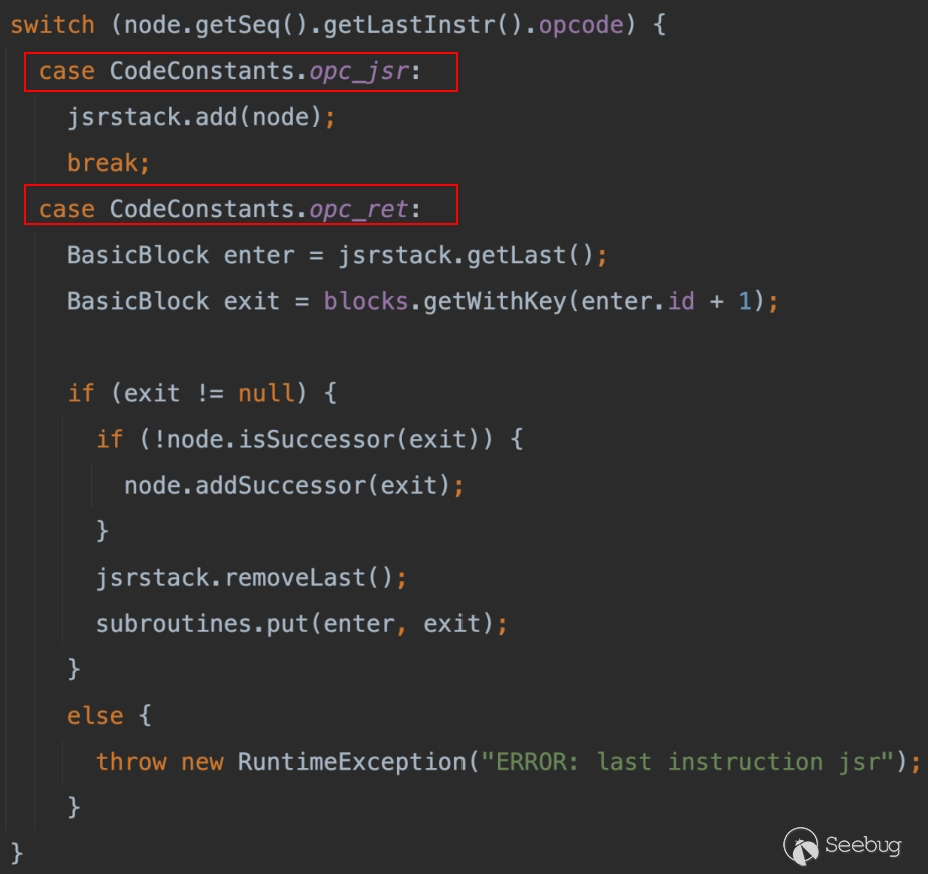
那到底是如何做到的呢?可以看到 jsr 的处理是在代码生成 CFG 的过程中,在这里仅仅只是对 JSR/RET 做了处理(正常情况下 jsr/ret 的出现是成对的,并且不会有其他指令)。
调用栈如下:
setSubroutineEdges:374, ControlFlowGraph
buildBlocks:204, ControlFlowGraph
<init>:44, ControlFlowGraph
codeToJava:74, MethodProcessorRunnable但是毕竟我们是黑客,总想搞一些骚操作,通过对字节码指令的翻阅我发现了两个有趣的指令。
| pop/pop2 | 弹出栈顶数值 |
|---|---|
| swap | 栈顶数值交换 |
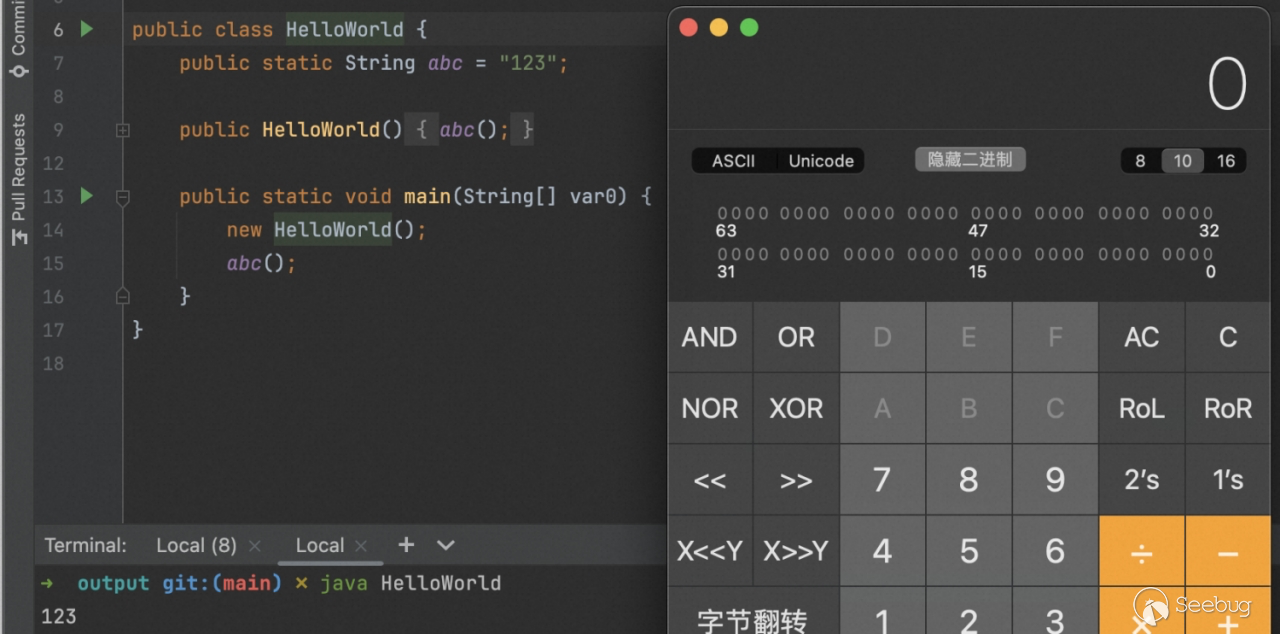
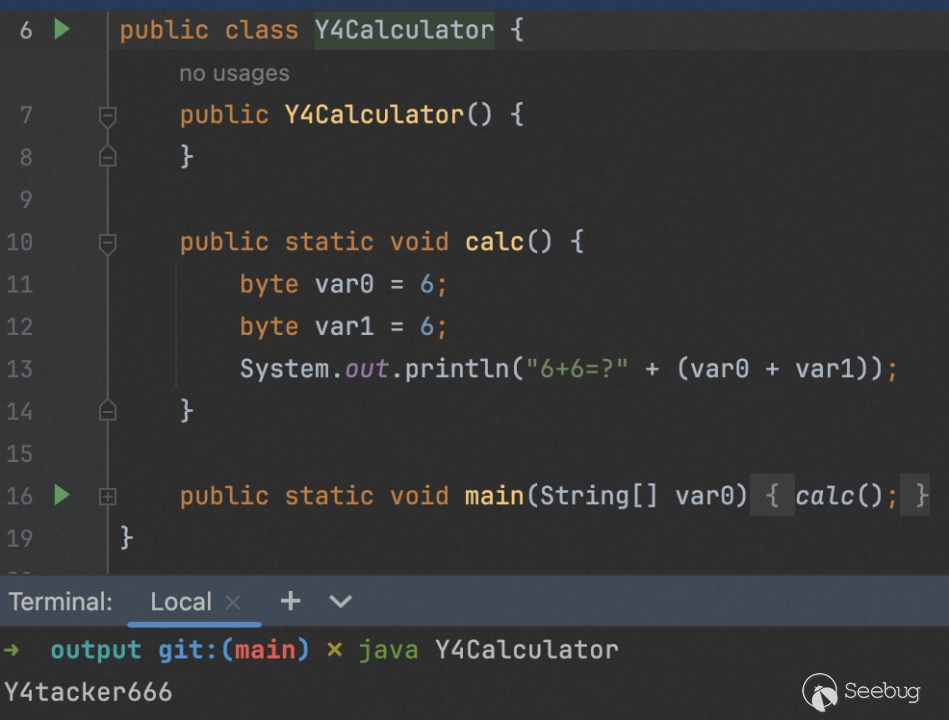
因此我们便可以构造出这样的 ASM 代码(Y4 计算器的原理):
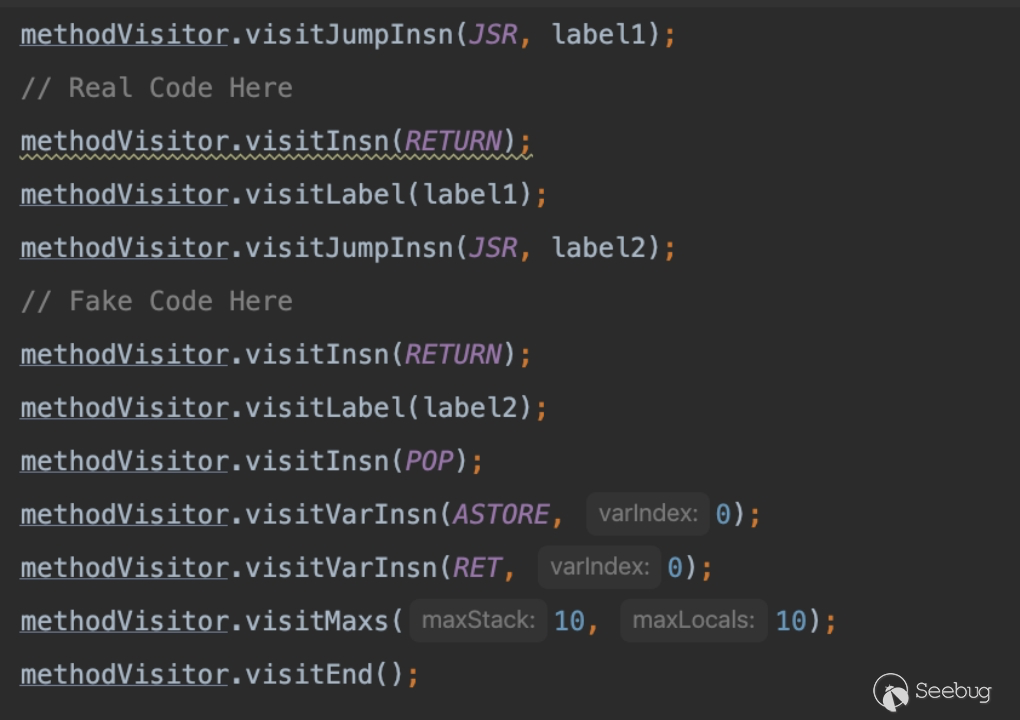
3.5.1 代码真实执行与 IDEA 解析的差异性
首先我们来看看代码的真实执行过程(懒了直接偷演讲时的 PPT 动画)。
首先通过 JSR 跳转到 label1,并向栈中压入下一条指令的地址:
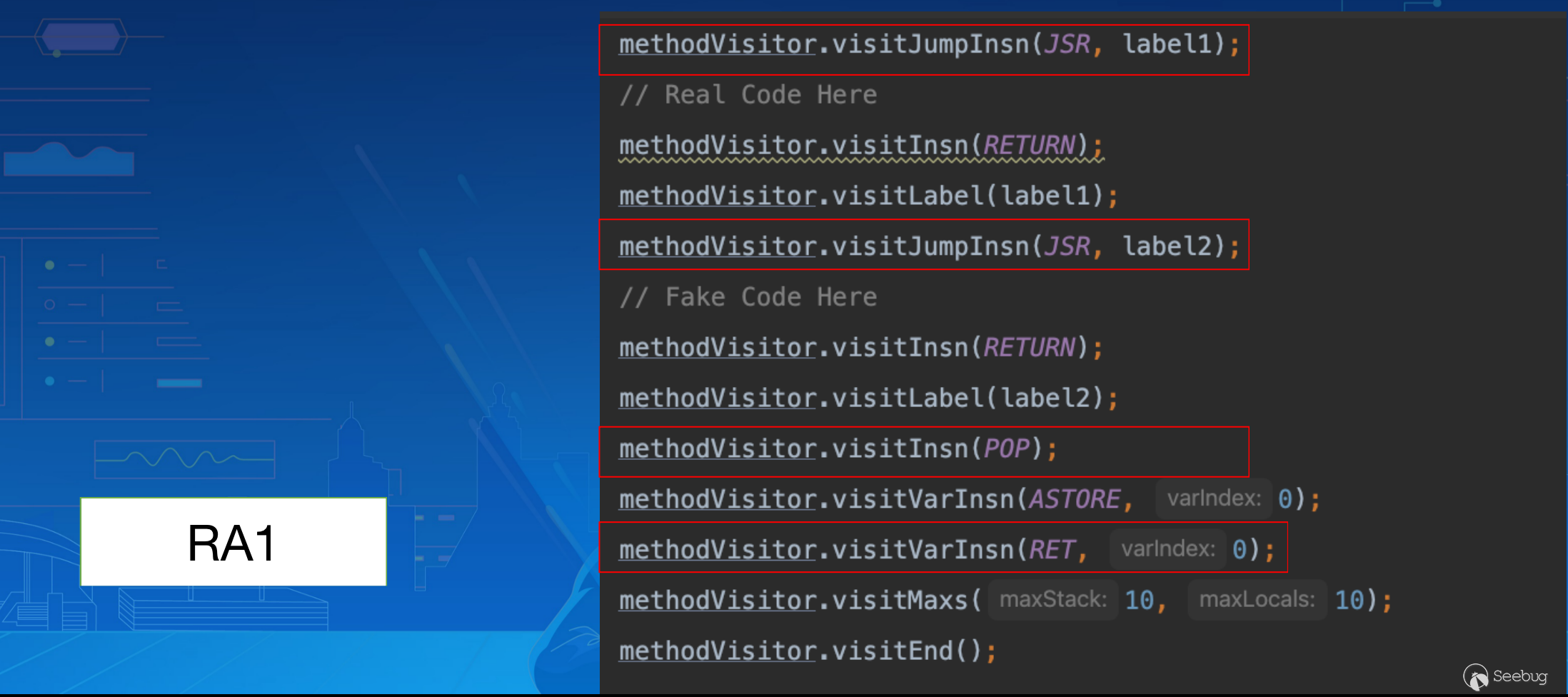
接着再次通过 JSR 跳转到 label2,并向栈中压入下一条指令的地址:
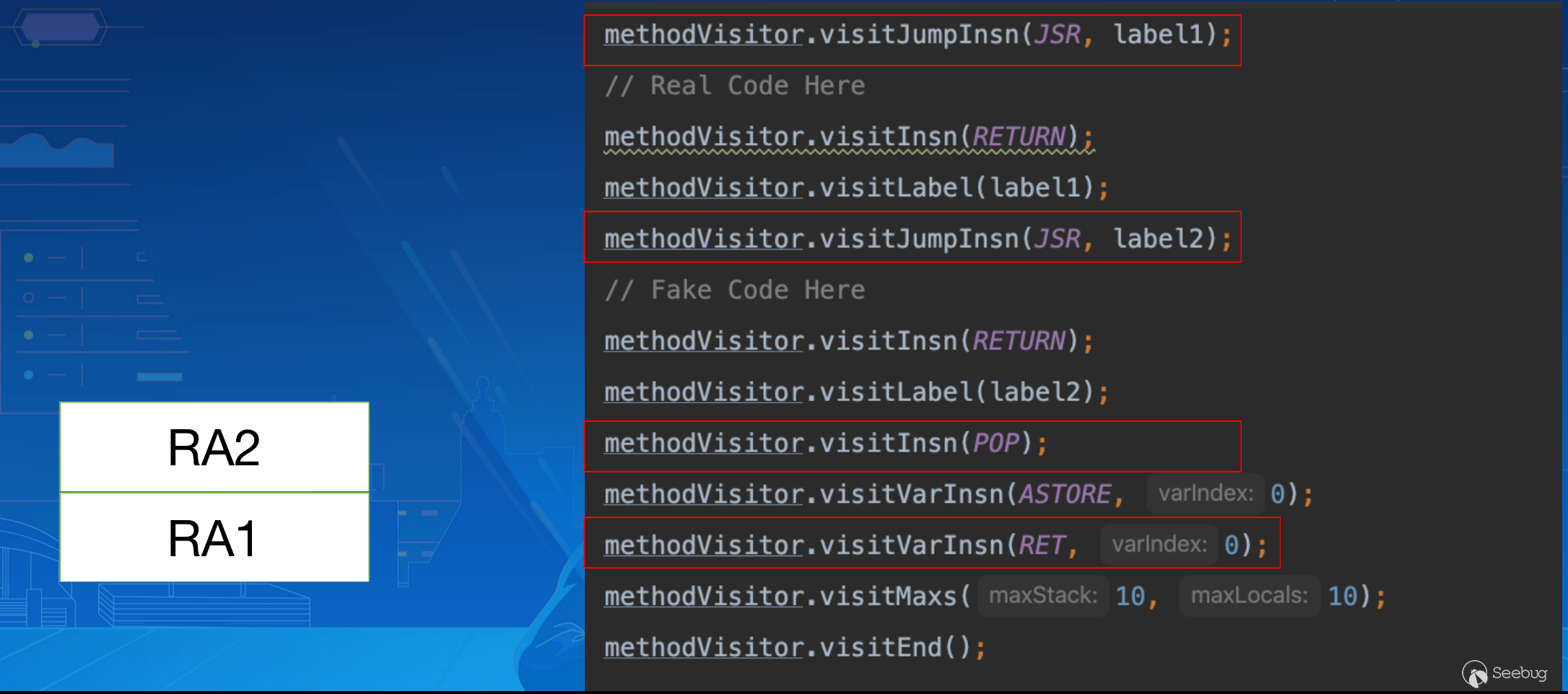
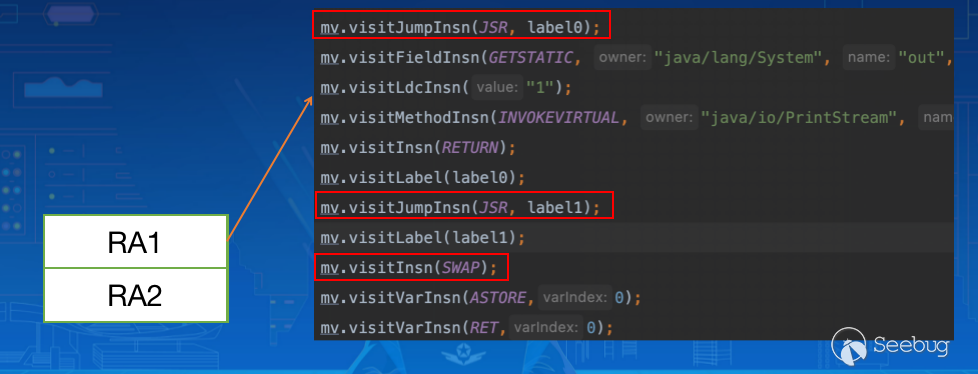
之后我们手动插入了一个 POP 指令的调用,RA2 被弹出,因此最终 RET 指令返回执行时会执行Real Code Here:
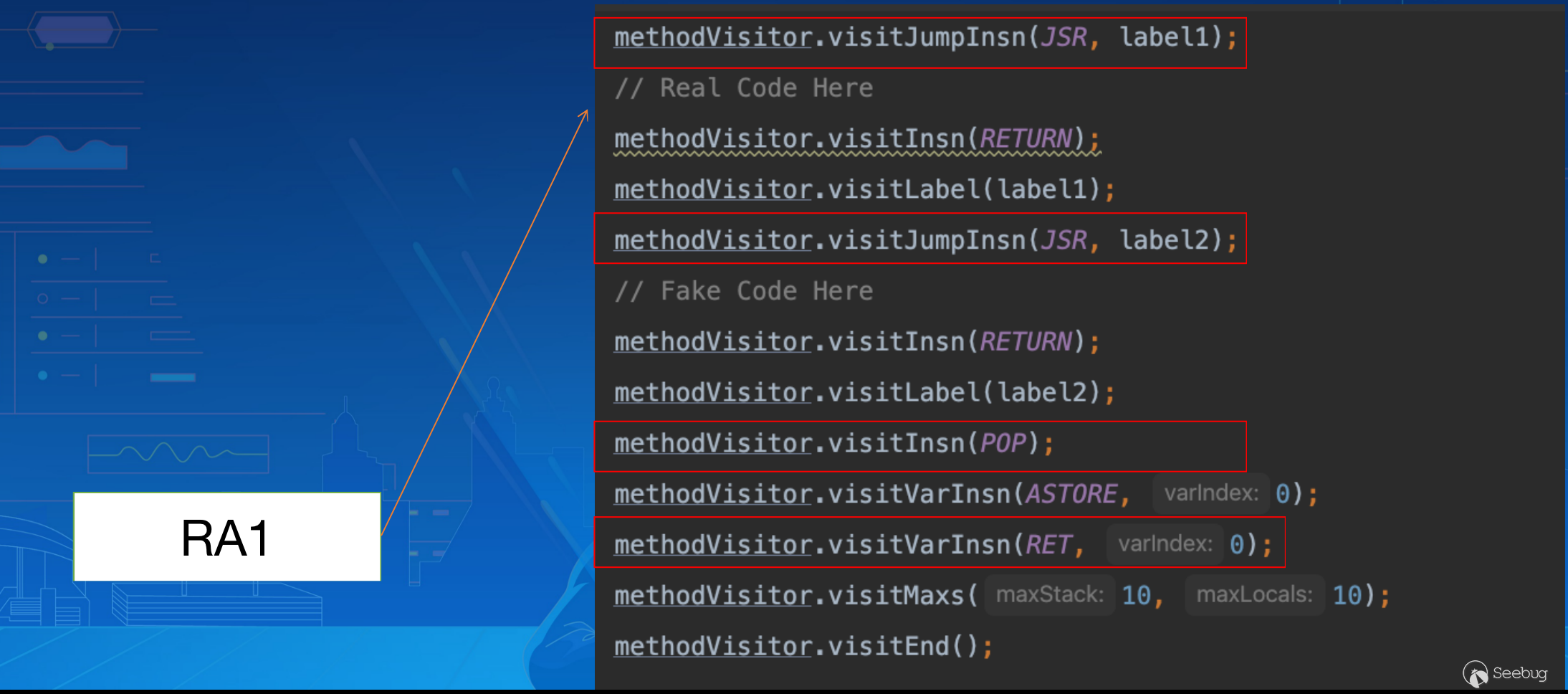
那么我们接下来再看看 IDEA 的解析处理,通过两次 JSR 跳转压入两条指令返回地址:
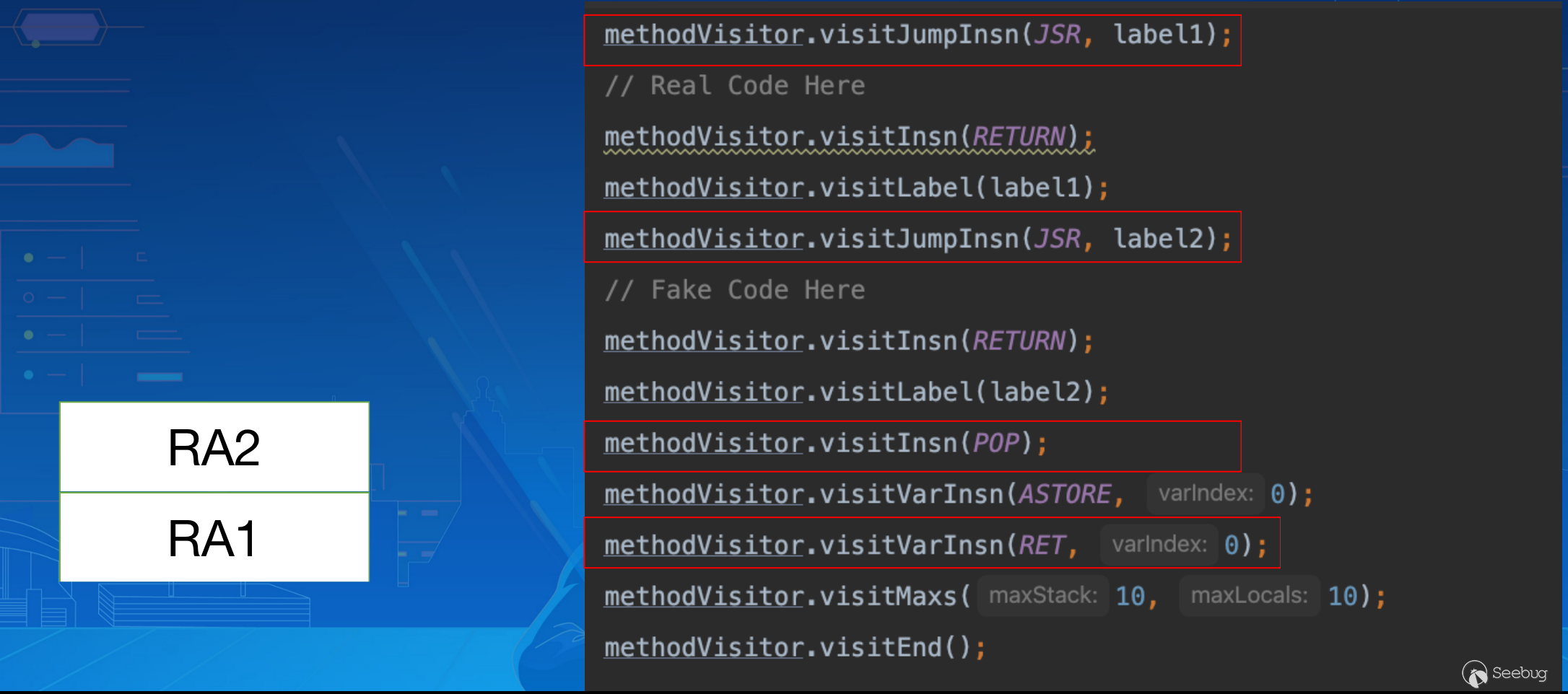
由于并没有对 POP 做处理,因此最终返回执行 RA2 所指向的Fake Code Here:
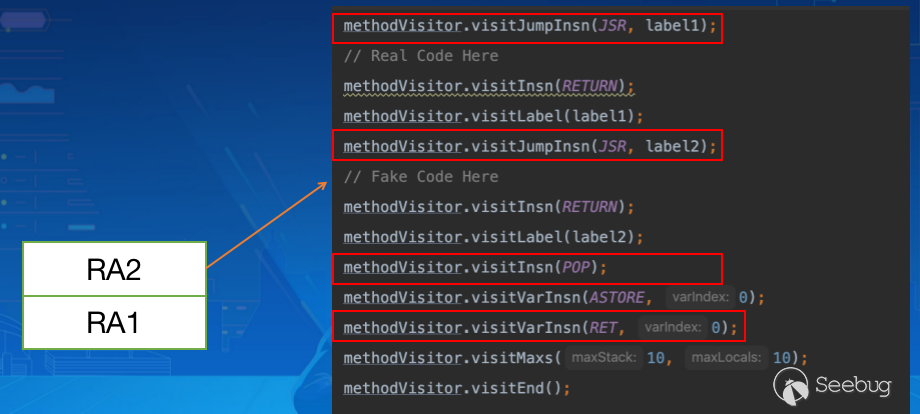
因此我们便可以利用 IDEA 解析与真实执行的差异性构造出这样的混淆例子,将真实代码隐藏,虚假代码做展示达到一个很好的混淆效果(IDEA 所有版本均可)。
3.5.2 SWAP
同样的道理,仅演示。
通过两次 JSR 跳转压入两条指令返回地址:
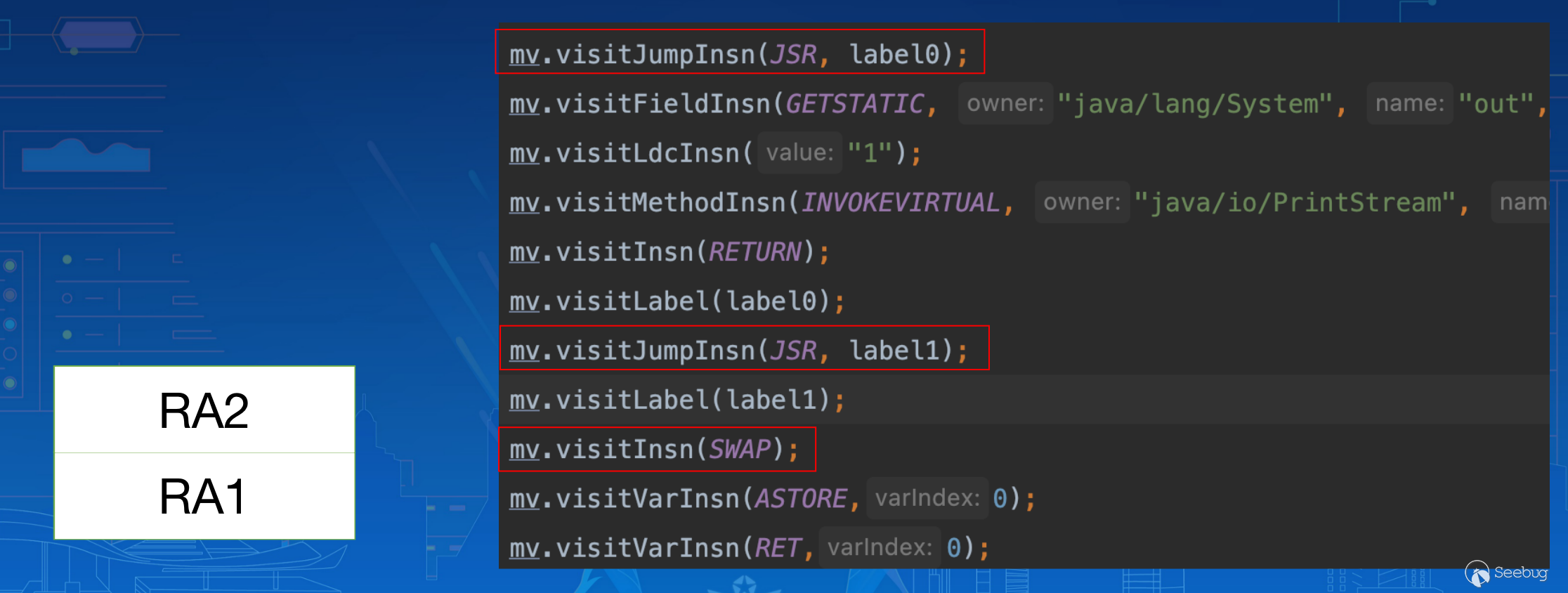
通过 SWAP 指令交换地址:
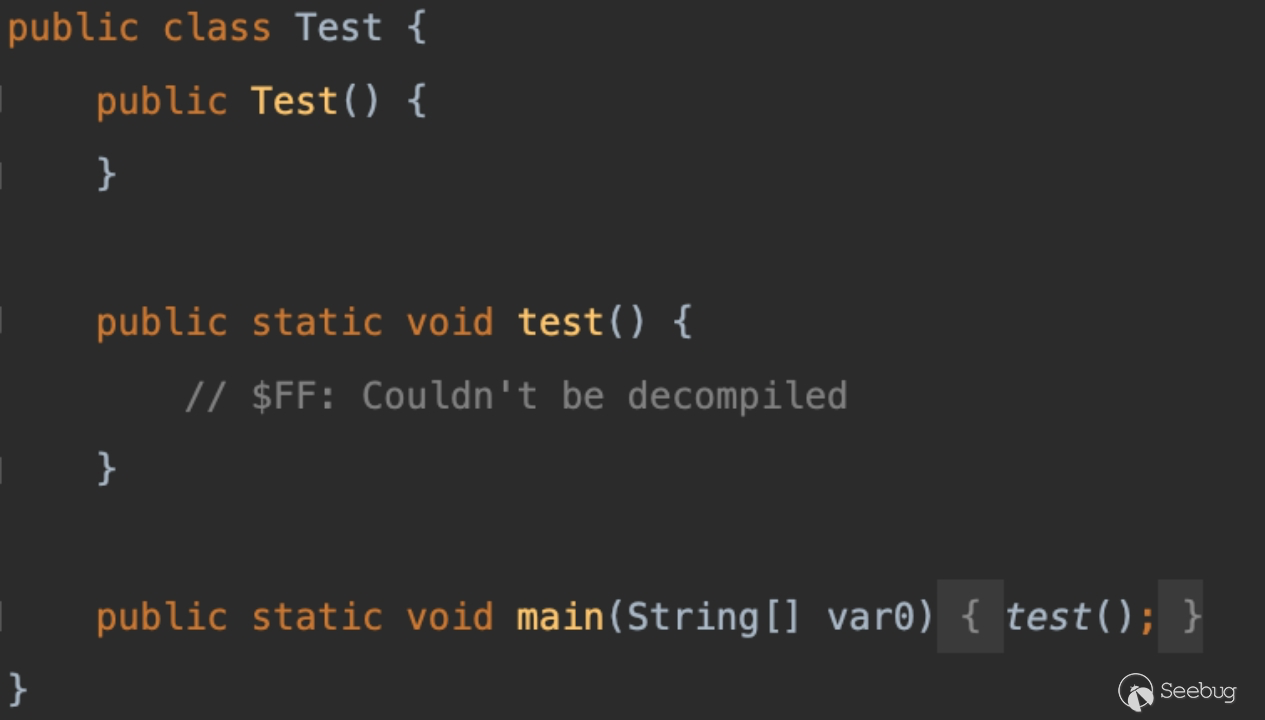
生成的类触发报错无法反编译(最新版可以,旧版不行,具体版本懒得测):
3.6 关注特殊的结构
除了关注程序的一些默认配置,我们还可以将视线聚焦在放在一些特殊的结构上面,毕竟结构越特殊,反编译器的处理也会越复杂。
这里我们仅以 try-catch 来举例,那 try-catch 为什么特殊呢?
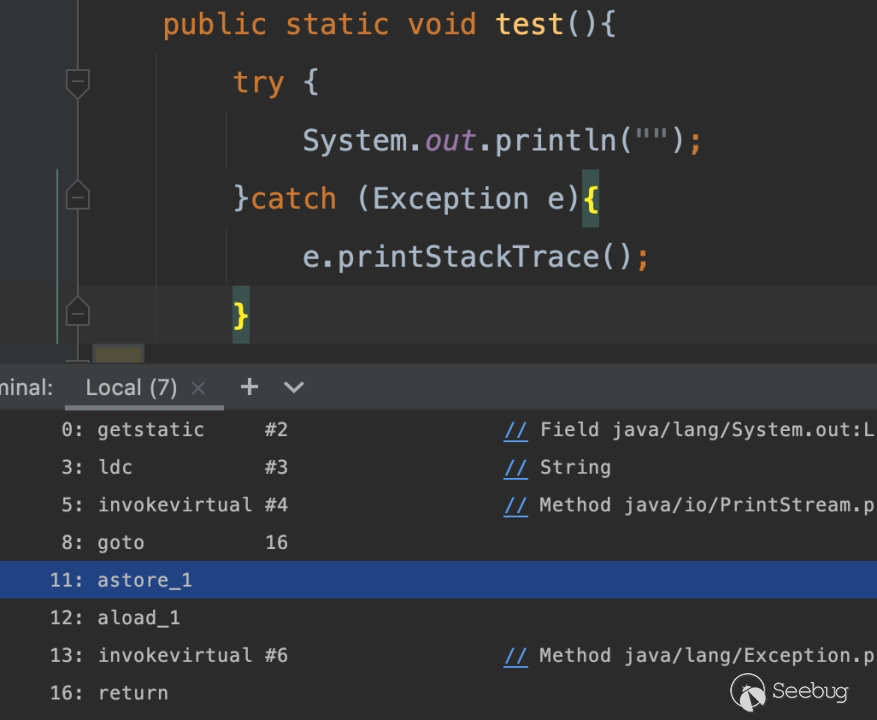
对于我们 Java 调用方法而言有两种情况,如果方法是静态方法就可以直接调用,而如果方法是非静态方法那么就需要先实例化一个类再执行调用,而如下图所示 Exception 调用的方法是非静态方法。因此可以猜测在运行过程中生成了这一个对象并存入了栈中,同时我们也可以通过 javap 指令简单从 astore 的前后调用做一个验证。
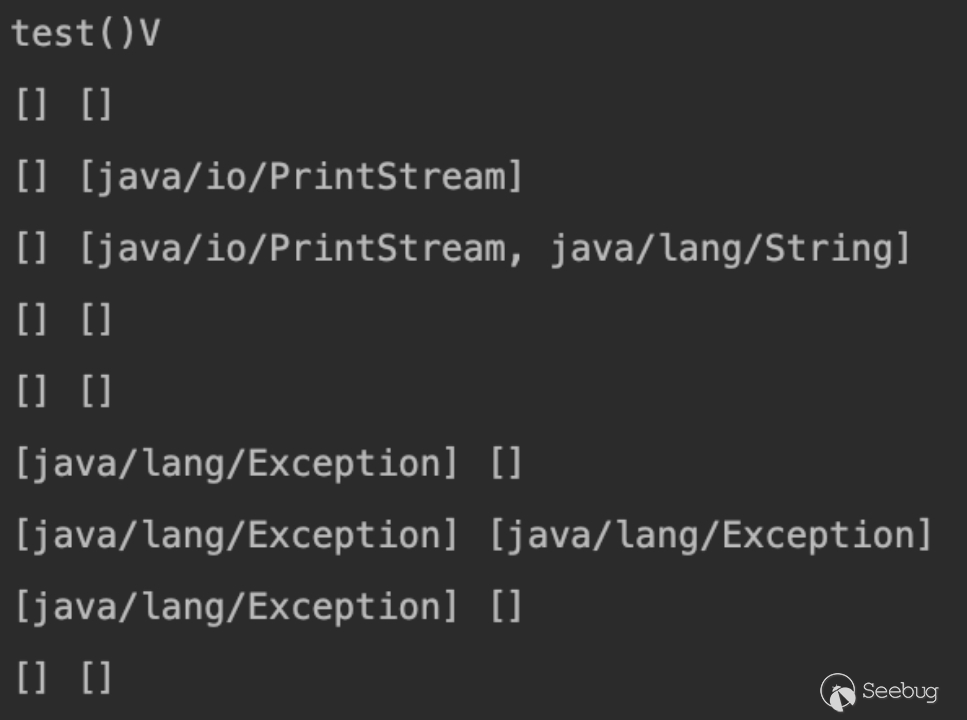
在这里为了方便大家更直观的感受,我写了一个模拟栈与本地变量表之间变化关系的程序,输出如下,可以看到确实很直观的有一个 Exception 对象的生成。
在接下来我们需要简单了解下 java 自身生成的 try-catch 的字节码表示,在这里为了防止编译优化,在每个执行中插入了一些输出的字节码指令序列。
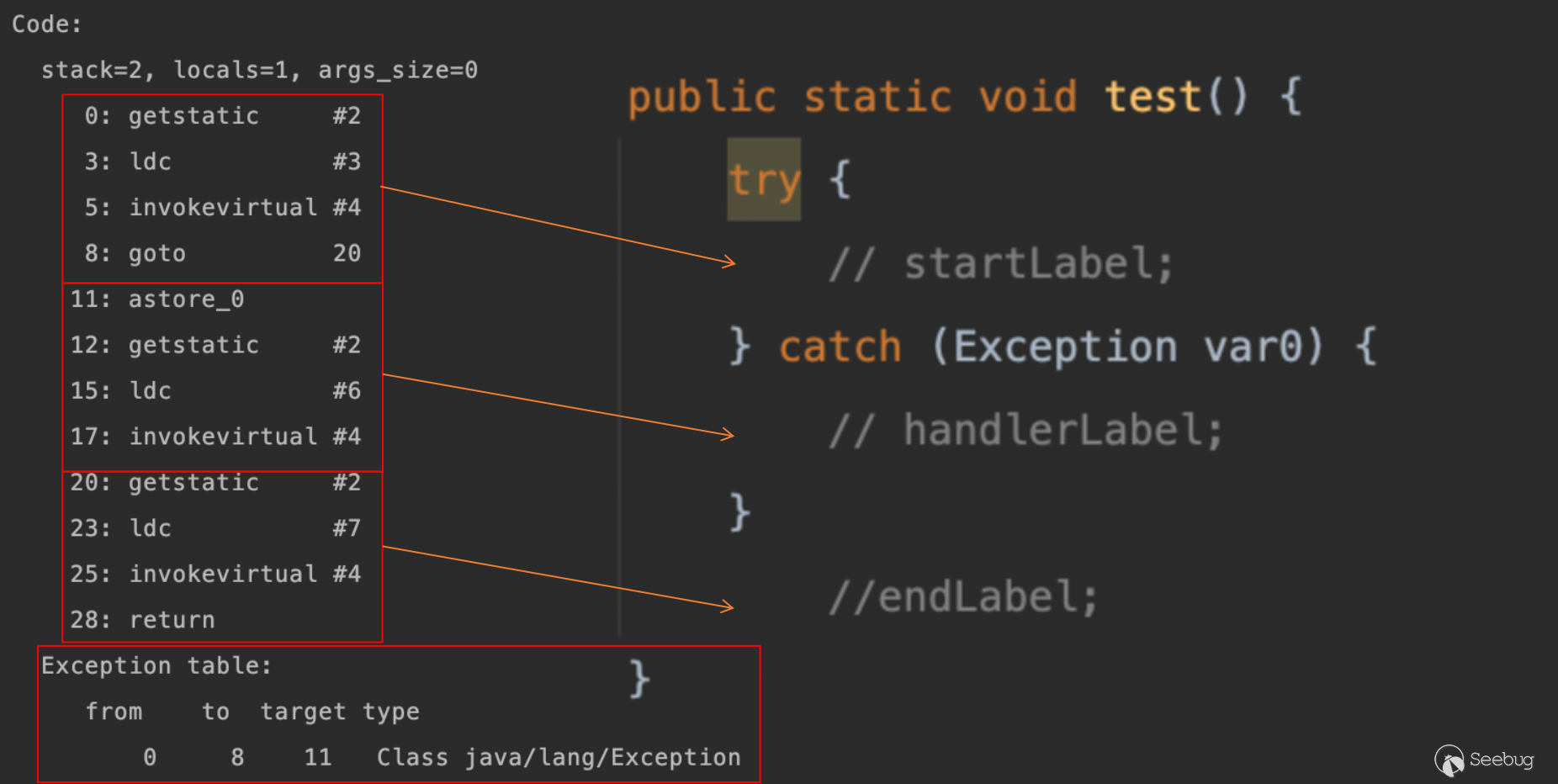
在这里我们主要关注这个异常表,这个异常表定义了异常处理的范围。
从指令 0-8,如果能成功执行不报错,那么就会调用 goto 跳转到指令 20 继续执行,直到程序退出。
如果在指令 0-8 之间运行产生了错误,就会跳转到 target 指向的指令 11 去捕获异常处理,从指令 11 继续往下执行直到程序退出。
在这里为了方便新手对接下来混淆的理解,我们可以尝试在不使用 GOTO 以及不对结构顺序做调整的情况下实现这个 try-catch,如下图所示,从右边来看,程序执行的流动是从 startLabel 流向 endLabel 并通过 return 返回,从 handlerLabel 流向 endLabel 并通过 return 返回,那么可以构造如左图所示的 ASM 代码片段(因为不使用跳转 HandlerLabel 只能给其插入一个 RETURN 保证程序正常退出)。
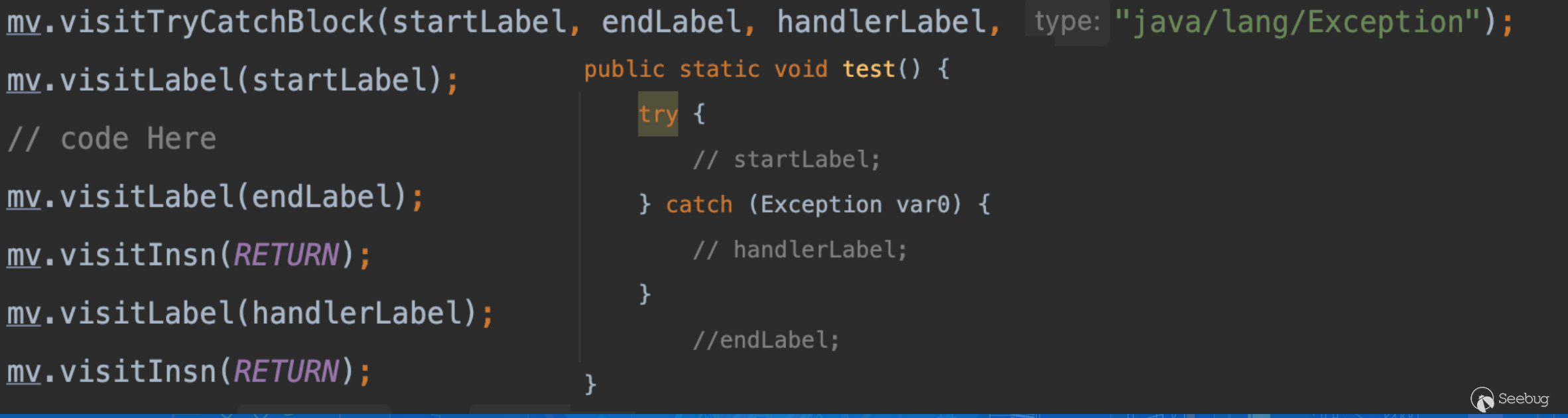
那么既然知道了程序的执行方向都是向下执行并且最终通过 RETURN 指令退出。
那么我们是不是就能大胆假设,在这里将 endLabel 下的 RETURN 做移除,那么至少从表面上看执行顺序是没问题的。
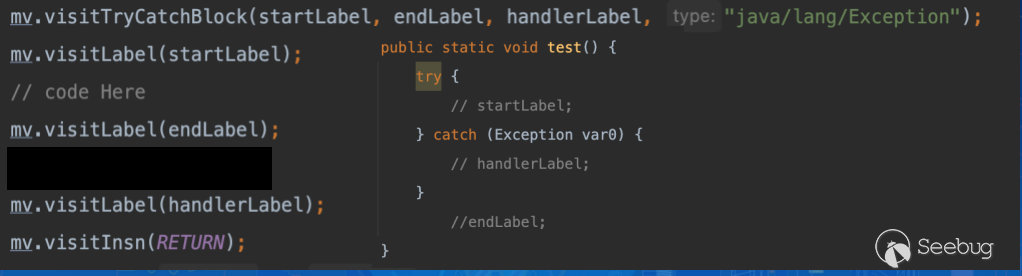
但这时候我们再运行生成好的程序,成功喜提一个 VerifyError 的报错,这是因为在执行前,java 会对类做验证,如果验证通过才能继续执行,反之抛出异常并退出。
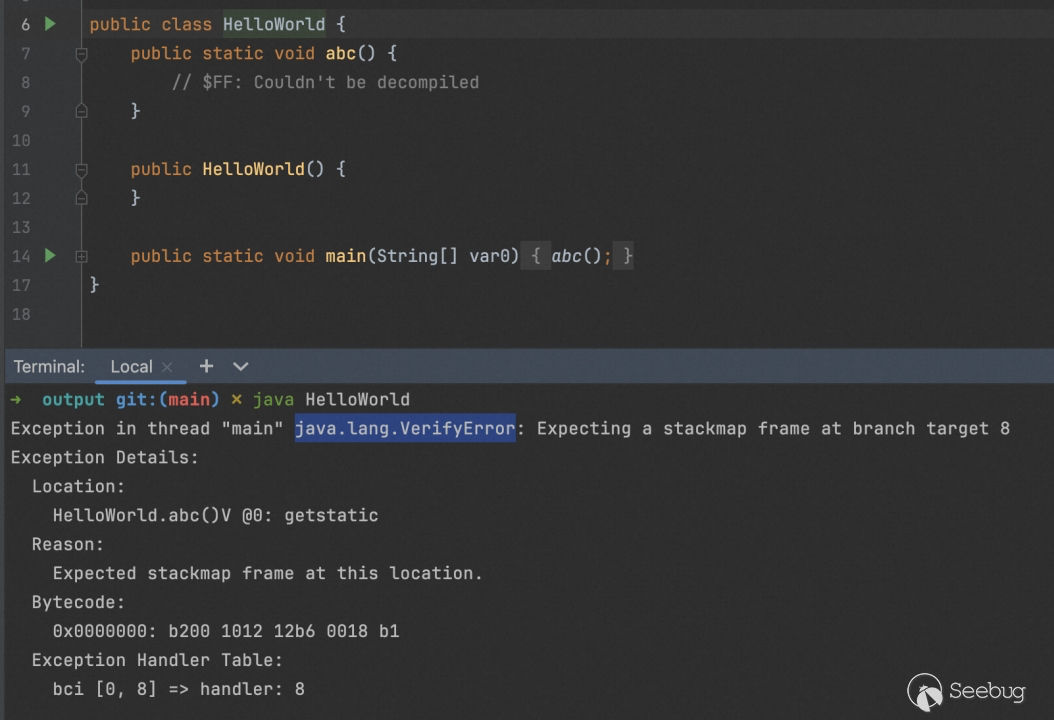
但是在这里我们首要关心的不应该是是否验证有异常,而是关心是否能正确执行,在这里我们通过-Xnoverify手动跳过这个过程,可以发现是可以正常执行的。

因此接下来我们便可以尝试是否能够欺骗验证过程,从而能够正确执行,我们仔细查看这个报错原因,发现其实和 frame 有关(什么是frame可自行百度),在这里教大家一个 ASM 的小技巧。
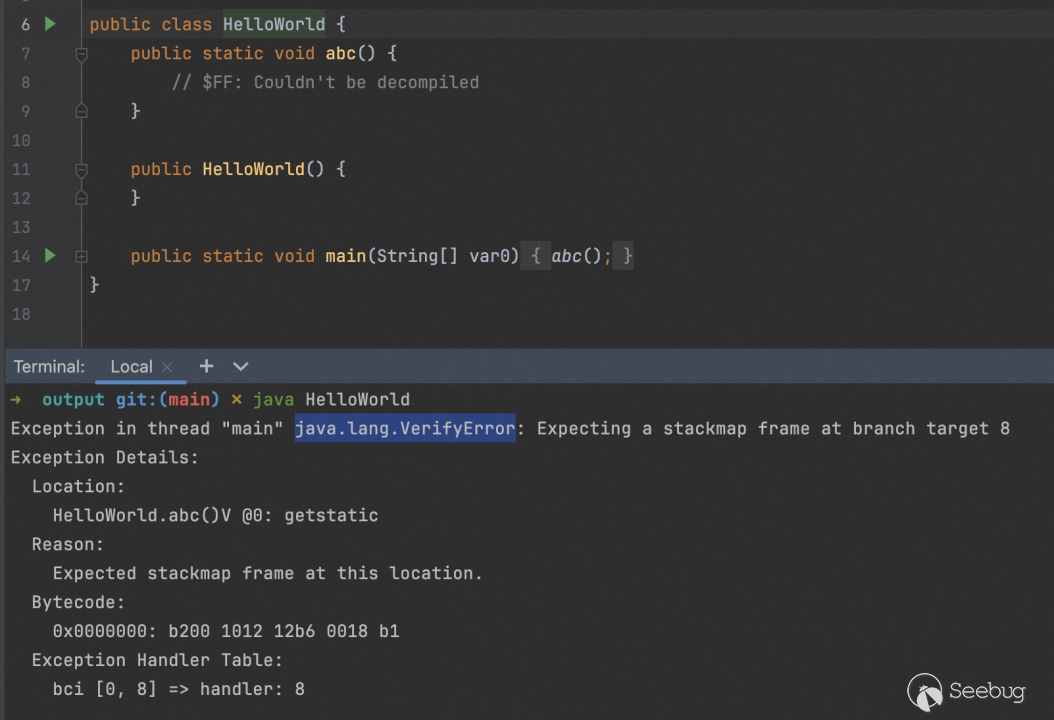
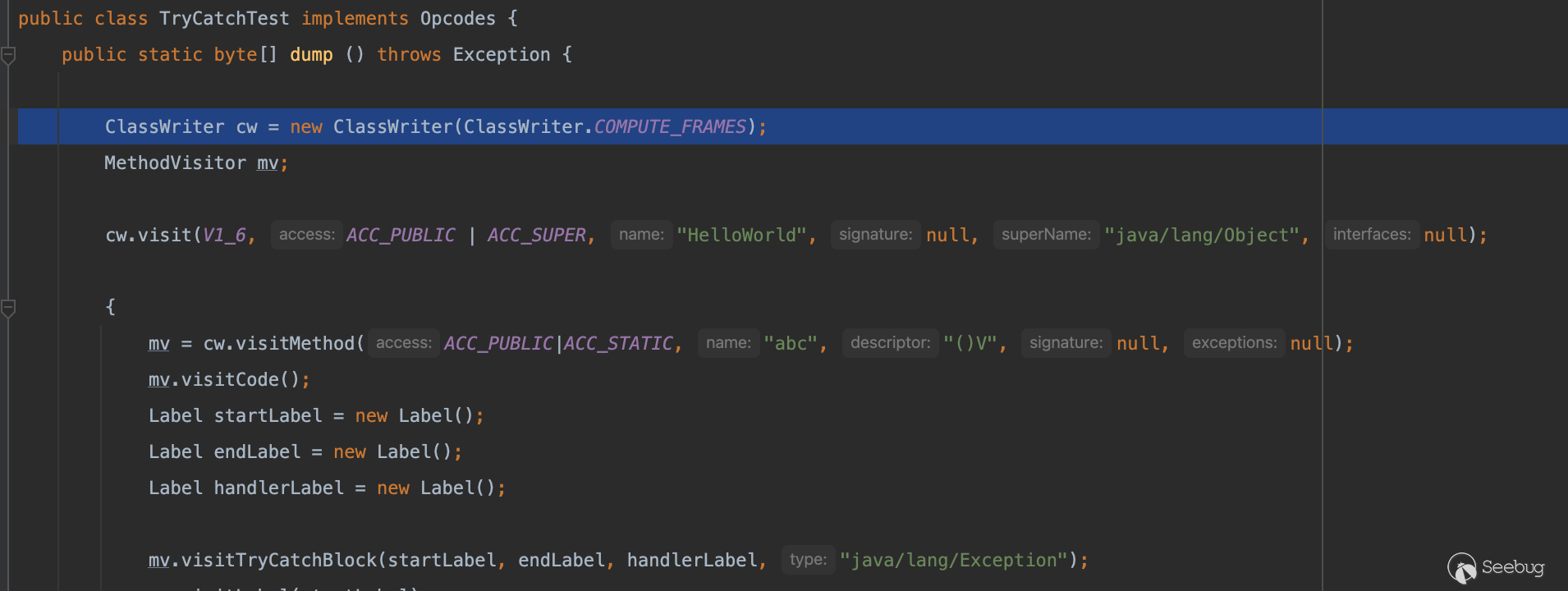
既然和 FRAME 有关那么,我们便可以在生成这个类的时候将参数替换为ClassWriter.COMPUTE_FRAMES,上面一开始也提到过这个参数的作用(在写入方法字节码时,会自动计算方法的堆栈映射帧和局部变量表的大小)。
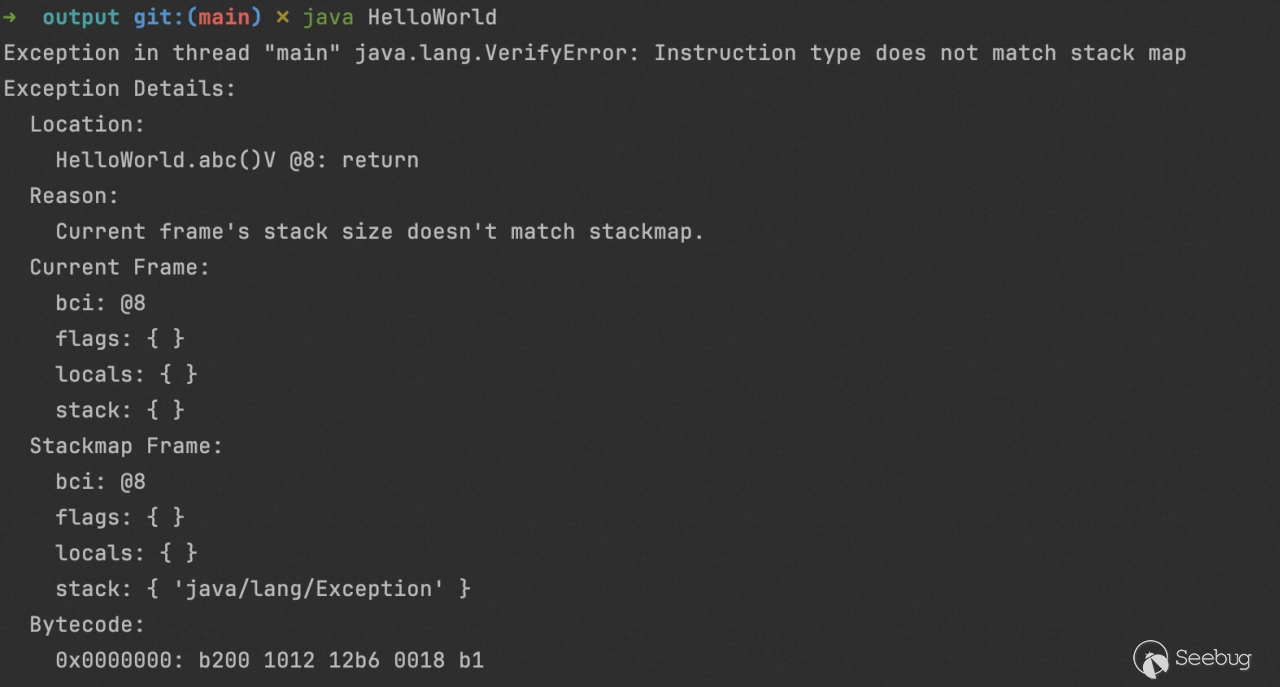
因此我们在此生成类并运行可以发现,报错变得非常直观,帧栈的大小不匹配。
那么既然少了一个我们便给他补齐一个即可(插入任意对象,仅验证大小的匹配)。
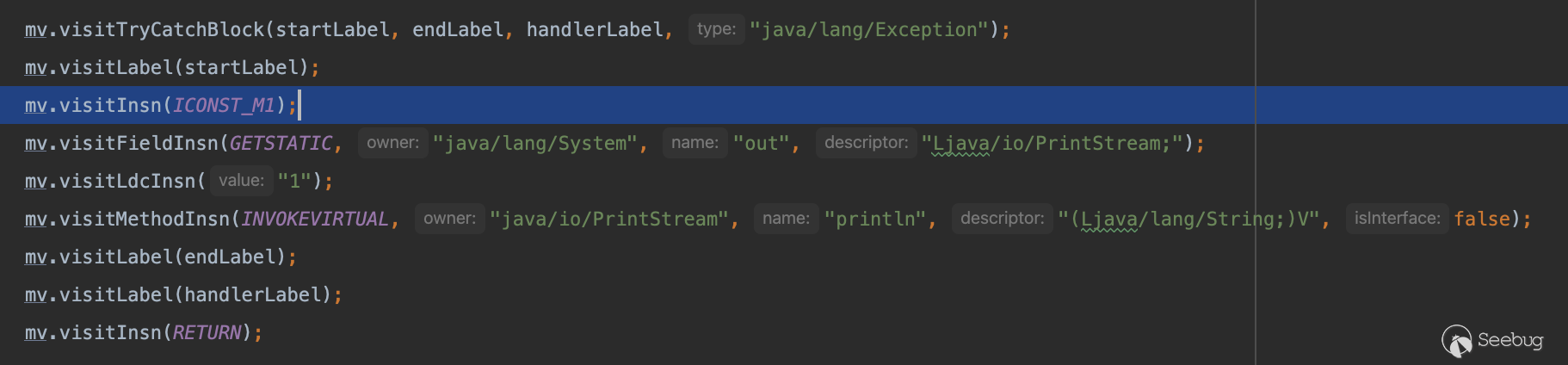
再次生成这个类,我们可以发现,VerifyError 的错误消失,程序成功运行,也达到了我们混淆的目的。
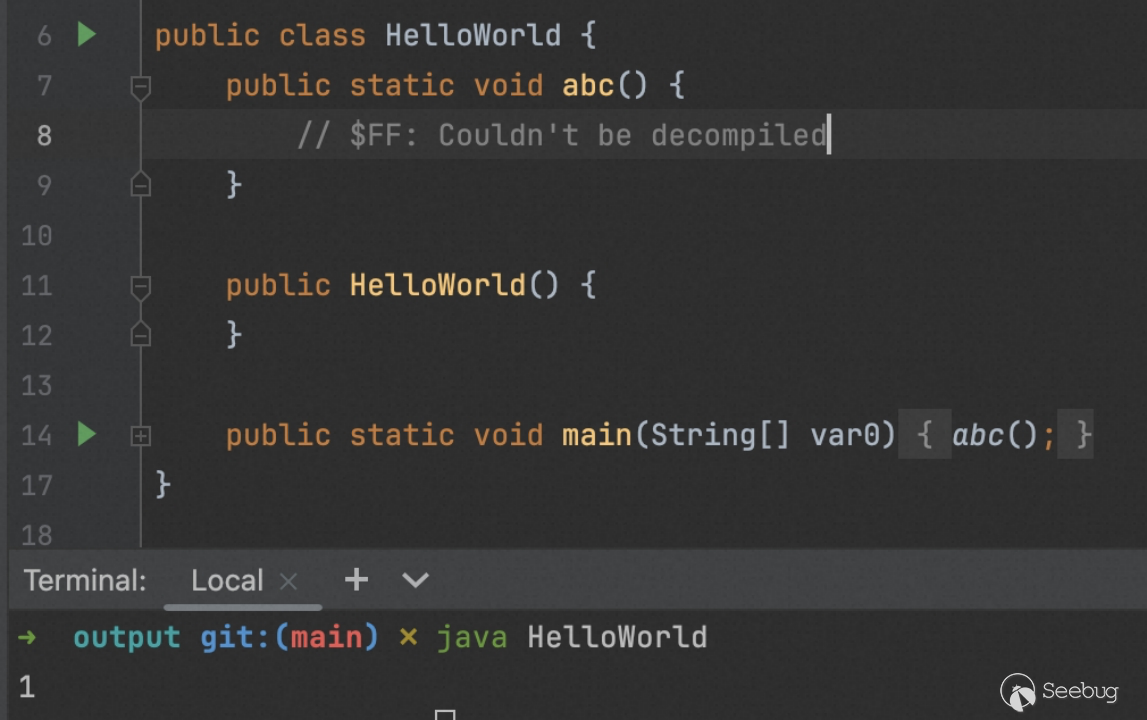
当然我们还能做什么呢?比如:
- 继续调整 start/end/handlerLabel 的顺序,只要保证程序正确流向
- 多个 try-catch 结构的交叉或者首尾重叠
- 关注其他的特殊结构
- 关注 java 动态语言和函数式编程的特性的实现
- .......(自由发挥,主要是看 IDEA 的代码,当然也可以尝试去对抗反混淆工具也很有意思,也能做到欺骗实现的代码执行或者报错)
在这次议题分享当中我们做到了对方法、字段以及代码片段的隐藏,同时实现了自定义的方法参数以及能够让 IDEA 反编译报错,因此我们便可以灵活使用这些结果,提升蓝队反编译分析的难度,为攻击争取更多的时间,同时针对隐藏的混淆效果,我们也可以将其运用到写插件后门的场景,实现一个定向投毒。
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/3098/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/3098/
如有侵权请联系:admin#unsafe.sh