2023-12-27 08:0:0 Author: arthurchiao.github.io(查看原文) 阅读量:106 收藏
Published at 2023-12-27 | Last Update 2023-12-27
从几百行 C 代码创建一个 Linux 容器的过程,一窥内核底层技术机制及真实 container runtime 的工作原理。
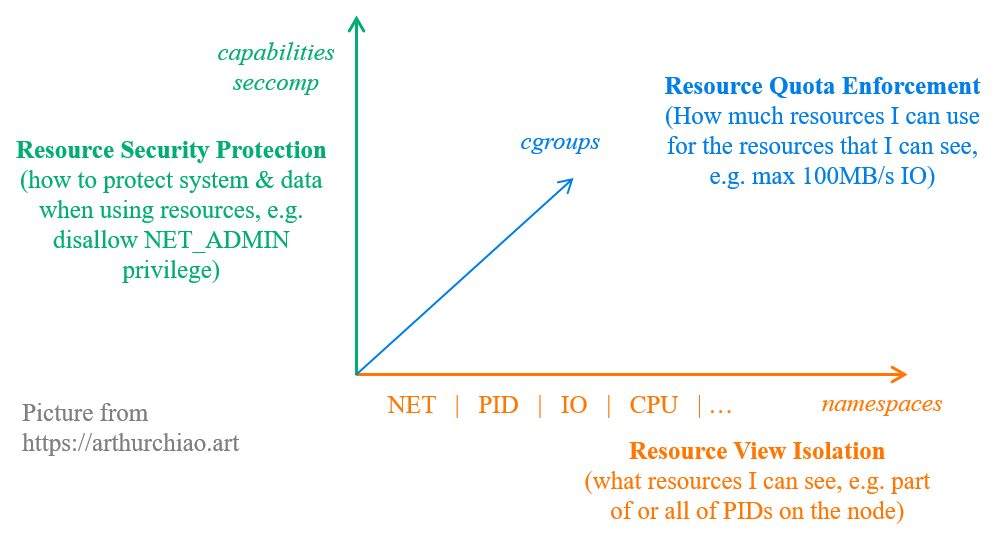
Fig. Kernel machanisms that support Linux containers
本文所用的完整代码见这里。
水平有限,文中不免有错误或过时之处,请酌情参考。
- 1 引言
- 2 500 行 C 代码创建一个容器:
ctn-d.c - 3 测试
- 4 与真实系统对比:
ctn-dvs.containerd+runc - 5 容器
/proc信息不准解决方式 - 6 特殊容器运行时
- 7 结束语
- 参考资料
从以 docker 为代表的 Linux 容器技术开始进入主流视野,到如今 k8s 一统容器编排 (甚至虚拟机编排)领域,容器技术已经在大规模生产环境使用了十年以上。 从基础设施层往上看,容器领域仍然在快速发展,新的项目层出不穷(看看 CNCF landscape 里密密麻麻的几百个项目就知道了); 但如果深入到基础设施内部,特别深入到每台主机内部, 会发现支撑容器的那些最基础技术其实都没怎么变 —— 对于基础设施工程师来说, 排查和解决一些虚拟化相关的线上疑难杂症和偶发问题,需要的正是对这些底层技术的理解和把控。
本文试图通过一段简单但又尽量全面的代码来串联起这些底层核心技术,看看一个容器是如何创建出来的。 有了对这个过程的理解,容器就不再是一个无从下手的黑盒,排查一些线上疑难杂症时也会更有方向。
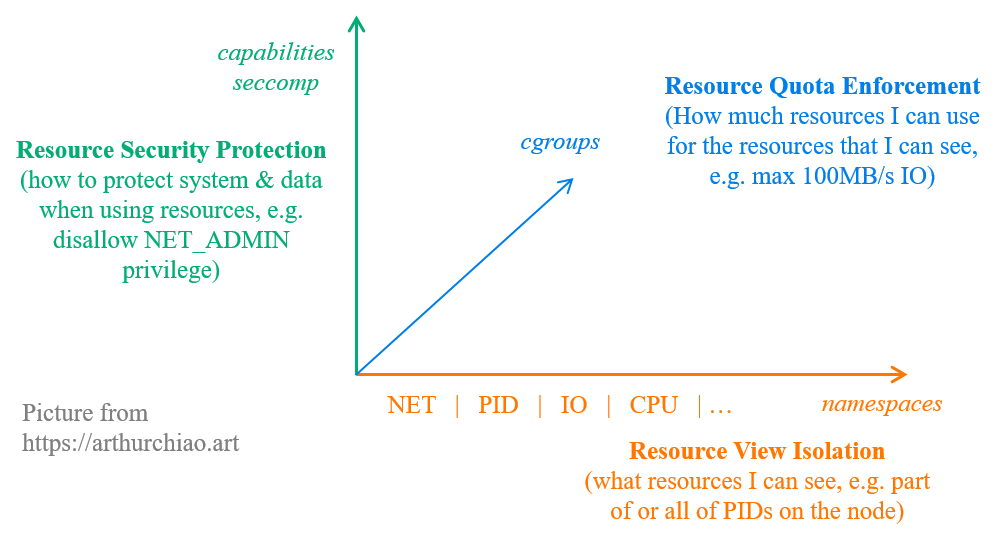
1.1 Linux 容器底层机制:NS/cgroups/Capabilities/Seccomp/...
Fig. Kernel machanisms that support Linux containers
如上图所示,Linux 容器由几种内核机制组成,这里将它们分到了三个维度:
namespace:一种资源视图隔离机制, 决定了进程可以看到什么,不能看到什么;例如,pid namespace 限制了进程能看到哪些其他的进程;network namespace 限制了进程能看到哪些网络设备等等。cgroup:一种限制资源使用量的机制,例如一个进程最多能使用多少内存、磁盘 I/O、CPU 等等。- (译) Control Group v2 (cgroupv2)(KernelDoc, 2021)
setrlimit是另一种限制资源使用量的机制,比cgroups要老,但能做一些 cgroups 做不了的事情。
capabilities:拆分 root privilege,精细化用户/进程权限。-
seccomp:内核的一种安全计算 (secure computation)机制,例如限制进程只能使用某些特定的系统调用。
以上几种机制中,cgroups 是通过文件系统完成的,其他几种都是通过系统调用完成的。
1.2 Namespaces
这里只是简单列下,方面后面理解代码。其实除了 UTS,其他 namespace 都能直接从名字看出用途,
- Mount:挂载空间,例如指定某个目录作为进程看到的系统跟目录、独立挂载
/proc/sys等; - PID:进程空间,例如最大进程数量是独立的;
- Network (netns):网络空间,例如能看到的网络设备是独立的,部分网络参数是独立的;
- IPC (inter-process communication)
UTS (UNIX Time-Sharing):让进程可以有独立的 host name 和 domain name;- User ID:用的不多,例如 ubuntu 22.04 / kernel 6.1 默认还是关闭的。
- cgroup:独立的 cgroup 文件系统和资源管控;
- Time:kernel
5.6+。
这里的代码来自 Linux containers in 500 lines of code (2016)。 原文基于 Kernel 4.6,本文做了一些更新和重构。
2.0 总览:ctn-d.c
int main (int argc, char **argv) {
// Step 1: parse CLI parameters, validate Linux kernel/cpu/..., generate hostname for container
// Step 2: setup a socket pair for container sending messages to the parent process
socketpair(AF_LOCAL, SOCK_SEQPACKET, 0, sockets);
fcntl(sockets[0], F_SETFD, FD_CLOEXEC);
config.fd = sockets[1];
// Step 3: allocate stack space for `execve()`
stack = malloc(STACK_SIZE));
// Step 4: setup cgroup for the container for resource isolation
setup_cgroups(&config);
// Step 5: launch container 将 mount, pid, ipc, network device, hostname/domainname 放到独立的 namespace
int flags = CLONE_NEWNS | CLONE_NEWCGROUP | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWNET | CLONE_NEWUTS;
child_pid = clone(child, stack + STACK_SIZE, flags | SIGCHLD, &config);
// Step 6: error handling and cleanup
}
-
初始化
- 解析命令行参数
- 检查内核版本、CPU 架构等等
- 给容器随机生成一个 hostname
- 创建一个 socket pair,用于容器进程和主进程之间的通信;
- 分配栈空间,供后面
execve()执行容器进程时使用; - 设置 cgroups 资源隔离;
- 通过 clone 创建子进程,在里面通过 namespace/capabilities/seccomp 等技术实现资源管控和安全。
核心科技在 4 和 5。下面分别来看下各步骤做的事情。
另外需要说明,原作者的这段程序主要是为了研究容器安全,因此一些步骤是出于安全目的而做的, 如果忽略安全考虑,要实现类似的“创建一个容器”效果,代码可以短很多,网上也有很多例子。 本文还是基本沿用原作者的版本,但一些安全方面不详细展开,有需要可参考原文 [1]。
2.1 初始化
程序提供了三个命令行参数,
-u <uid>以什么用户权限运行;-m <ctn rootfs path>镜像解压之后的目录;-c <command>容器启动后运行的命令。
程序会给容器随机生成一个 hostname,就像用 docker run 不指定容器名字的话,docker 也会自动生成一个名字。
2.2 创建 socket pair,供容器进程和父进程通信
if (socketpair(AF_LOCAL, SOCK_SEQPACKET, 0, sockets)) {
fprintf(stderr, "socketpair failed: %m\n");
goto error;
}
if (fcntl(sockets[0], F_SETFD, FD_CLOEXEC)) {
fprintf(stderr, "fcntl failed: %m\n");
goto error;
}
config.fd = sockets[1];
子进程(容器进程)需要发消息给父进程,因此初始化一个 socketpair。
容器进程会告诉父进程是否需要设置 uid/gid mappings,
如果需要,就会执行 setgroups/setresgid/setresuid。
这些是权限相关的。
2.3 分配栈空间,供随后 execve() 执行容器启动进程使用
#define STACK_SIZE (1024 * 1024)
char *stack = 0;
if (!(stack = malloc(STACK_SIZE))) {
fprintf(stderr, "=> malloc failed, out of memory?\n");
goto error;
}
这是后面通过 execve() 来执行容器内进程的准备工作,是标准 Linux API,也不展开。
2.4 创建 cgroup,为容器设置资源限额
cgroups 可以限制进程和进程组的资源使用量,避免有问题的容器进程影响整个系统。 它有 v1 和 v2 两个版本,
简单起见,程序里使用的 cgroupv1。
struct cgrp_control {
char control[256];
struct cgrp_setting {
char name[256];
char value[256];
} **settings;
};
struct cgrp_setting add_to_tasks = { // echo 0 > /sys/fs/cgroup/<controller>/<hostname>/tasks
.name = "tasks",
.value = "0"
};
struct cgrp_control *cgrps[] = {
& (struct cgrp_control) {
.control = "memory",
.settings = (struct cgrp_setting *[]) {
& (struct cgrp_setting) {
.name = "memory.limit_in_bytes",
.value = "1073741824"
},
/* & (struct cgrp_setting) { */
/* .name = "memory.kmem.limit_in_bytes", */
/* .value = "1073741824" */
/* }, */
&add_to_tasks,
NULL
}
},
& (struct cgrp_control) {
.control = "cpu",
.settings = (struct cgrp_setting *[]) {
& (struct cgrp_setting) {
.name = "cpu.shares",
.value = "256" // CPU shares
},
&add_to_tasks,
NULL
}
},
& (struct cgrp_control) {
.control = "pids",
.settings = (struct cgrp_setting *[]) {
& (struct cgrp_setting) {
.name = "pids.max",
.value = "64"
},
&add_to_tasks,
NULL
}
},
/* & (struct cgrp_control) { */
/* .control = "blkio", */
/* .settings = (struct cgrp_setting *[]) { */
/* & (struct cgrp_setting) { */
/* .name = "blkio.weight", */
/* .value = "10" */
/* }, */
/* &add_to_tasks, */
/* NULL */
/* } */
/* }, */
NULL
};
int setup_cgroups(struct ctn_config *config) {
for (struct cgrp_control **cgrp = cgrps; *cgrp; cgrp++) {
char dir[PATH_MAX] = {0};
snprintf(dir, sizeof(dir), "/sys/fs/cgroup/%s/%s", (*cgrp)->control, config->hostname);
mkdir(dir, S_IRUSR | S_IWUSR | S_IXUSR);
for (struct cgrp_setting **setting = (*cgrp)->settings; *setting; setting++) {
char path[PATH_MAX] = {0};
int fd = 0;
snprintf(path, sizeof(path), "%s/%s", dir, (*setting)->name);
fd = open(path, O_WRONLY);
write(fd, (*setting)->value, strlen((*setting)->value));
close(fd);
}
}
setrlimit(RLIMIT_NOFILE, & (struct rlimit) {.rlim_max = 64, .rlim_cur = 64,});
return 0;
}
设置 cgroups 的逻辑比较简单,基本上就是创建 cgroup 目录, 以及往 cgroups 配置文件写入配置。 上面的程序配置了以下几个资源限额:
/sys/fs/cgroup/memory/$hostname/memory.limit_in_bytes=1GB:容器进程及其子进程使用的总内存不超过 1GB;/sys/fs/cgroup/memory/$hostname/memory.kmem.limit_in_bytes=1GB:容器进程及其子进程使用的总内存不超过 1GB;/sys/fs/cgroup/cpu/$hostname/cpu.shares=256:CPU 总 slice 是 1024,因此限制进程最多只能占用 1/4 CPU 时间;/sys/fs/cgroup/pids/$hostname/pid.max=64:允许容器进程及其子进程最多拥有 64 个 PID;/sys/fs/cgroup/blkio/$hostname/weight=50:确保容器进程的 IO 优先级比系统其他进程低。- 降低文件描述符的 hard limit。fd 与 pid 类似,都是 per-user 的。这里设置上限之后,
后面还会 drop
CAP_SYS_RESOURCE,因此容器内的用户是改不了的。
另外,程序还通过 add_to_tasks 向 {memory,cpu,blkio,pids}/$hostname/tasks 文件写入 0,即实现下面的效果:
$ echo 0 > /sys/fs/cgroup/<controller>/<hostname>/tasks
tasks 里面存放的是受这个 cgroup 管控的进程 ID(PID)列表,
0 是一个特殊值,表示“执行当前写入操作的进程”。
2.5 clone() 启动子进程,运行容器
fork() 是常见的创建子进程的方式,但它背后调用的是 clone(),后者暴露的细节更多,
也是创建容器的关键技术。
我们创建的子进程要能 mount 自己的根目录、设置自己的 hostname 以及做其他一些事情,
要实现这个效果,需要向 clone() 传递相应的 flags 参数:
int flags = CLONE_NEWNS | CLONE_NEWCGROUP | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWNET | CLONE_NEWUTS;
child_pid = clone(child, stack + STACK_SIZE, flags | SIGCHLD, &config);
flags规定了这个新创建的子进程要有多个独立的 namespace;- x86 平台栈是向下增长的,因此将栈指针指向
stack+STACK_SIZE作为起始位置; - 最后还还加上了
SIGCHLD标志位,这样就能 wait 子进程了。
下面是子进程内做的事情:
int child(void *arg) {
struct ctn_config *config = arg;
sethostname(config->hostname, strlen(config->hostname);
setup_mounts(config);
setup_userns(config);
setup_capabilities();
setup_seccomp();
close(config->fd);
execve(config->argv[0], config->argv, NULL);
}
具体来看下各步骤。
2.5.1 sethostname():感知 UTS namespace
sethostname/gethostname 是 Linux 系统调用,用于设置或获取主机名(hostname)。
hostname 是 UTS namespace 隔离的,
刚才创建子进程时指定了要有独立的 UTS namespace,
因此在这个子进程内设置 hostname 时,影响的只是这个 UTS namespace 内(即这个容器内)所有进程
看到的 hostname。
2.5.2 setup_mounts():安全考虑,unmount 不需要的目录
flags 指定了子进程有独立的 mount namespace 中。
按照最小权限原则,我们应该 unmount 掉子进程不应访问的目录。
int setup_mounts(struct ctn_config *config) {
// remounting everything with MS_PRIVATE...
mount(NULL, "/", NULL, MS_REC | MS_PRIVATE, NULL));
// making a temp directory and a bind mount there...
char mount_dir[] = "/tmp/tmp.XXXXXX";
mkdtemp(mount_dir);
mount(config->mount_dir, mount_dir, NULL, MS_BIND | MS_PRIVATE, NULL);
char inner_mount_dir[] = "/tmp/tmp.XXXXXX/oldroot.XXXXXX";
memcpy(inner_mount_dir, mount_dir, sizeof(mount_dir) - 1);
mkdtemp(inner_mount_dir);
// pivoting root...
syscall(SYS_pivot_root, mount_dir, inner_mount_dir);
char *old_root_dir = basename(inner_mount_dir);
char old_root[sizeof(inner_mount_dir) + 1] = { "/" };
strcpy(&old_root[1], old_root_dir);
// unmounting old_root
chdir("/");
umount2(old_root, MNT_DETACH);
rmdir(old_root);
return 0;
}
步骤:
- 使用
MS_PRIVATE重新挂载所有内容; - 创建一个临时目录,并在其中创建一个子目录;
- 将用户命令行指定的目录(
config->mount_dir)bind mount 到临时目录上; - 使用
pivot_root将 bind mount 作为根目录,并将旧的根目录挂载到内部临时目录上。pivot_root是一个系统调用,允许交换/处的挂载点与另一个挂载点。 - 卸载旧的根目录,删除内部临时目录。
2.5.3 setup_userns()
user namespace 实际中用的还不多,就不展开了。
int setup_userns(struct ctn_config *config) {
// trying a user namespace...
int has_userns = !unshare(CLONE_NEWUSER);
write(config->fd, &has_userns, sizeof(has_userns));
if (has_userns) {
fprintf(stderr, "done.\n");
} else {
fprintf(stderr, "unsupported? continuing.\n");
}
// switching to uid %d / gid %d...", config->uid, config->uid
setgroups(1, & (gid_t) { config->uid });
setresgid(config->uid, config->uid, config->uid);
setresuid(config->uid, config->uid, config->uid);
}
User namespace 是后来引入的一种新 namespace,但 enable user namespace 编译内 核很复杂,另外它在系统层面(system-wide)改变了 capabilities 的语义,相比解决 问题,它会带来更多的问题。更多信息见 Understanding and Hardening Linux Containers 这个功能目前还是默认关闭的。
$ sysctl kernel.unprivileged_userns_clone sysctl: cannot stat /proc/sys/kernel/unprivileged_userns_clone: No such file or directory
2.5.4 setup_capabilities():禁用部分 capabilities
同样,基于最小权限原则,drop 所有不需要的 capabilities,
int setup_capabilities() {
// dropping capabilities...
int drop_caps[] = {
CAP_AUDIT_CONTROL,
CAP_AUDIT_READ,
CAP_AUDIT_WRITE,
CAP_BLOCK_SUSPEND,
CAP_DAC_READ_SEARCH,
CAP_FSETID,
CAP_IPC_LOCK,
CAP_MAC_ADMIN,
CAP_MAC_OVERRIDE,
CAP_MKNOD,
CAP_SETFCAP,
CAP_SYSLOG,
CAP_SYS_ADMIN,
CAP_SYS_BOOT,
CAP_SYS_MODULE,
CAP_SYS_NICE,
CAP_SYS_RAWIO,
CAP_SYS_RESOURCE,
CAP_SYS_TIME,
CAP_WAKE_ALARM
};
size_t num_caps = sizeof(drop_caps) / sizeof(*drop_caps);
// bounding...
for (size_t i = 0; i < num_caps; i++) {
prctl(PR_CAPBSET_DROP, drop_caps[i], 0, 0, 0);
}
// inheritable...
cap_t caps = NULL;
if (!(caps = cap_get_proc())
|| cap_set_flag(caps, CAP_INHERITABLE, num_caps, drop_caps, CAP_CLEAR)
|| cap_set_proc(caps)) {
if (caps) cap_free(caps);
return 1;
}
cap_free(caps);
return 0;
}
2.5.5 setup_seccomp():禁用部分系统调用
这里将一些有安全风险的系统调用都放到了黑名单,这可能不是最好的处理方式,但能够 让大家非常直观地看到底层是如何通过 seccomp 保证计算安全的:
int setup_seccomp() {
scmp_filter_ctx ctx = NULL;
// filtering syscalls...
if (!(ctx = seccomp_init(SCMP_ACT_ALLOW))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(chmod), 1, SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISUID, S_ISUID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(chmod), 1, SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISGID, S_ISGID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmod), 1, SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISUID, S_ISUID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmod), 1, SCMP_A1(SCMP_CMP_MASKED_EQ, S_ISGID, S_ISGID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmodat), 1, SCMP_A2(SCMP_CMP_MASKED_EQ, S_ISUID, S_ISUID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(fchmodat), 1, SCMP_A2(SCMP_CMP_MASKED_EQ, S_ISGID, S_ISGID))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(unshare), 1, SCMP_A0(SCMP_CMP_MASKED_EQ, CLONE_NEWUSER, CLONE_NEWUSER))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(clone), 1, SCMP_A0(SCMP_CMP_MASKED_EQ, CLONE_NEWUSER, CLONE_NEWUSER))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(ioctl), 1, SCMP_A1(SCMP_CMP_MASKED_EQ, TIOCSTI, TIOCSTI))
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(keyctl), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(add_key), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(request_key), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(ptrace), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(mbind), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(migrate_pages), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(move_pages), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(set_mempolicy), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(userfaultfd), 0)
|| seccomp_rule_add(ctx, SCMP_FAIL, SCMP_SYS(perf_event_open), 0)
|| seccomp_attr_set(ctx, SCMP_FLTATR_CTL_NNP, 0)
|| seccomp_load(ctx)) {
if (ctx) seccomp_release(ctx);
return 1;
}
// all pass, return success
seccomp_release(ctx);
return 0;
}
docker 官方有一些相关文档,感兴趣可移步。
2.5.6 execve():执行指定的容器启动命令
前面资源视图隔离(namespace)、资源限额(cgroups)、文件目录(mount)、权限(capabilities)、安全(seccomp)等工作 都做好之后,就可以启动用户指定的容器进程了(类似于 docker 中的 entrypoint 或 command):
execve(config->argv[0], config->argv, NULL);
至此,如果一切正常,容器进程就起来了。接下来我们还要容器进程与主进程的通信, 类似于真实环境中 containerd 处理来自具体容器的消息。
2.6 处理容器事件:user namespace 相关
#define USERNS_OFFSET 10000
#define USERNS_COUNT 2000
int handle_child_uid_map (pid_t child_pid, int fd) {
int uid_map = 0;
int has_userns = -1;
if (read(fd, &has_userns, sizeof(has_userns)) != sizeof(has_userns)) {
fprintf(stderr, "couldn't read from child!\n");
return -1;
}
if (has_userns) {
char path[PATH_MAX] = {0};
for (char **file = (char *[]) { "uid_map", "gid_map", 0 }; *file; file++) {
if (snprintf(path, sizeof(path), "/proc/%d/%s", child_pid, *file) > sizeof(path)) {
fprintf(stderr, "snprintf too big? %m\n");
return -1;
}
fprintf(stderr, "writing %s...", path);
if ((uid_map = open(path, O_WRONLY)) == -1) {
fprintf(stderr, "open failed: %m\n");
return -1;
}
if (dprintf(uid_map, "0 %d %d\n", USERNS_OFFSET, USERNS_COUNT) == -1) {
fprintf(stderr, "dprintf failed: %m\n");
close(uid_map);
return -1;
}
close(uid_map);
}
}
if (write(fd, & (int) { 0 }, sizeof(int)) != sizeof(int)) {
fprintf(stderr, "couldn't write: %m\n");
return -1;
}
return 0;
}
3.1 下载官方 busybox 容器镜像
3.1.1 下载镜像
这里用 docker 从官方 pull,然后保存为本地 tar 文件:
$ dk pull busybox:1.36
$ dk save busybox:1.36 -o busybox-1.36.tar
3.1.2 解压到本地目录
将 tar 文件解压,
$ sudo tar xvf busybox-1.36.tar
244ed32d6820f8861f94beda2456fa7032a832a4e7ed7e72fa66b802518f9adc/
244ed32d6820f8861f94beda2456fa7032a832a4e7ed7e72fa66b802518f9adc/VERSION
244ed32d6820f8861f94beda2456fa7032a832a4e7ed7e72fa66b802518f9adc/json
244ed32d6820f8861f94beda2456fa7032a832a4e7ed7e72fa66b802518f9adc/layer.tar
f5fb98afcf9f5c6e8e069557f605b15b52643166c82ac5695f49fc6b0be04ee8.json
manifest.json
repositories
其中的 layer.tar 是镜像本身,其他都是元数据。
我们先创建一个目录 ~/busybox-1.36-rootfs(名字随便),
然后将 layer.tar 解压到这个目录:
$ mkdir ~/busybox-1.36-rootfs #
$ tar xvf busybox-1.36/244ed32d6820f8861f94beda2456fa7032a832a4e7ed7e72fa66b802518f9adc/layer.tar -C ~/busybox-1.36-rootfs
得到的就是一个看着像 一台 Linux node 根目录的文件夹了:
$ ls ~/busybox-1.36-rootfs/
bin dev etc home lib lib64 root tmp usr var
我们一会就是用这个目录作为容器根目录来启动容器。
3.2 编译
这里是在 ubuntu22 kernel 6.1 上编译:
$ sudo apt install libseccomp-dev libcap-dev -y
$ gcc -Wl,--no-as-needed -lcap -lseccomp ctn-d.c
得到 a.out。
3.3 测试
3.3.1 运行 /bin/sh:交互式
指定解压之后的 busybox 容器镜像目录作为容器根目录(-m ~/busybox-rootfs-1.36/),
以 root 权限(-u 0)运行 shell(-c /bin/sh):
$ sudo ./a.out -u 0 -m ~/busybox-rootfs-1.36/ -c /bin/sh
=> validating Linux version...6.1.11-060111-generic on x86_64.
=> generating hostname for container ... 1cd132c-ten-of-pentacles done
=> setting cgroups...memory...cpu...pids...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...
=> temp directory /tmp/tmp.j1SPbh
done.
=> pivoting root...done.
=> unmounting /oldroot.p216lf...done.
=> trying a user namespace...writing /proc/3544398/uid_map...writing /proc/3544398/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
/ #
最后一行的命令提示符变了,这就表示已经进入到了容器内的 shell, 接下来可以执行几个 busybox 镜像内有的命令来测试:
/ # whoami # <-- 已经进入到容器内
root
/ # hostname
17bb49-death
/ # ls
bin dev etc home lib lib64 root tmp usr var
最后通过 exit 命令正常退出 shell,由于这是容器主进程,因此 shell 退出之后容器也就退出了:
/ # exit # <-- 退出容器
=> cleaning cgroups...done.
3.3.2 运行 /bin/echo:一次性执行
再测试下直接在容器内执行一段任务(非交互式),运行完就会自动退出:
$ sudo ./a.out -u 0 -m ~/busybox-rootfs-1.36/ -c /bin/echo "hello from inside container"
=> validating Linux version...6.1.11-060111-generic on x86_64.
=> generating hostname for container ... 1cd132c-ten-of-pentacles done
=> setting cgroups...memory...cpu...pids...done.
=> setting rlimit...done.
=> remounting everything with MS_PRIVATE...remounted.
=> making a temp directory and a bind mount there...
=> temp directory /tmp/tmp.j1SPbh
done.
=> pivoting root...done.
=> unmounting /oldroot.p216lf...done.
=> trying a user namespace...writing /proc/3544398/uid_map...writing /proc/3544398/gid_map...done.
=> switching to uid 0 / gid 0...done.
=> dropping capabilities...bounding...inheritable...done.
=> filtering syscalls...done.
hello from inside container # <-- 容器内执行 echo,执行完就退出了
=> cleaning cgroups...done.
3.3.3 将自己的程序放到 busybox 容器中执行
如果你有一些没什么依赖的程序(或者依赖已经在 busybox 中了), 那将这样的程序放到 busybox 容器镜像中也是可以运行的。下面看个 golang 的例子。
源码:
package main
import "fmt"
func main() {
fmt.Println("Hello World from Golang")
}
编译,
$ go build hello-world.go
编译生成的可执行文件没有任何依赖,因此我们将它放到 busybox 容器的可执行文件目录:
$ mv hello-world ~/busybox-rootfs-1.36/bin/
然后在容器 shell 内尝试执行:
/ # hello-world
Hello World from Golang
成功!
通过以上内容,可以看到我们 500 来行的 C 程序可以实现创建和运行(简易版)Linux 容器的功能。 那么,在实际上它对应的是容器技术栈中的哪些组件呢?
4.1 角色和位置
4.1.1 简化版 containerd+runc
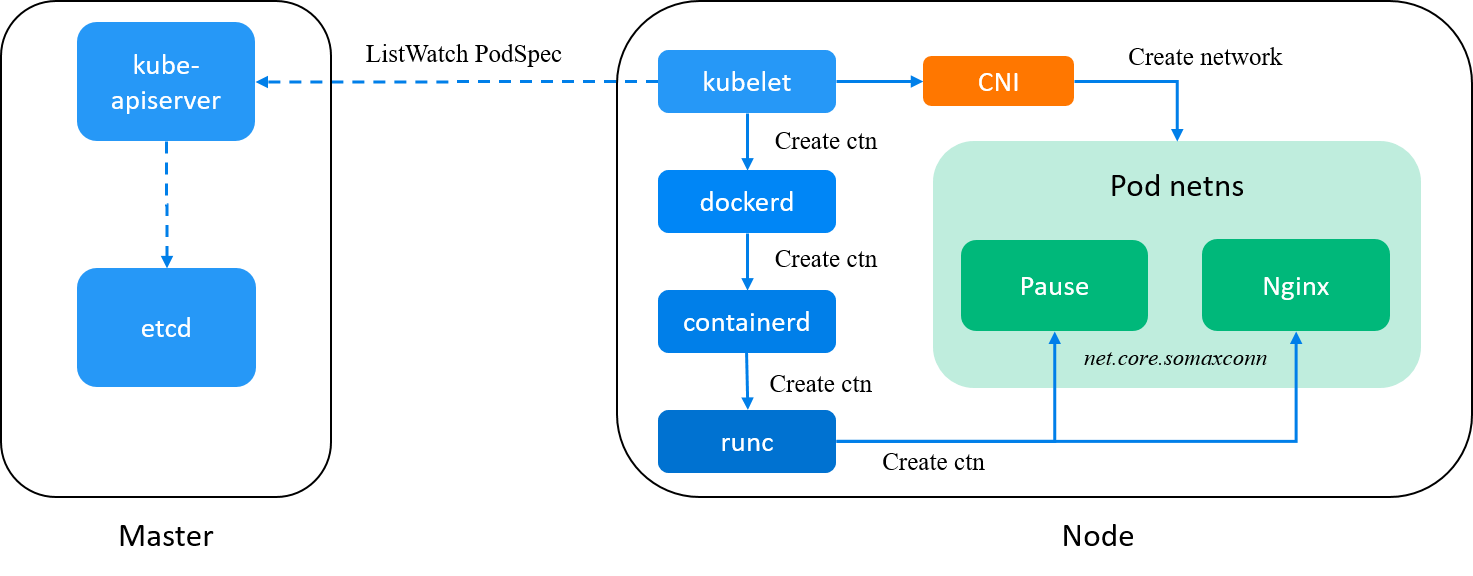
k8s 中容器相关的组件。dockerd 是可选的,较新版本的 k8s 中已经把 dockerd 这一层去掉了。[3]
上图是 k8s 创建 pod 所涉及的一些核心组件,大家对 docker/containerd 比较熟悉,
但其实 containerd 并不是一线干活的,而是跟 kubelet/docker 一样,都是负责管理工作的“经理”(container manager),
真正干活的是更底层的 runc。
从软件栈上来说,本文的程序其实就是一个简化版的 containerd+runc。 参考 [3] 中 k8s 容器的创建过程中可以看到,
runc是基于一个config.json创建容器的,本文程序中的 config 其实就是config.json的一个极其简化版。- k8s 创建容器时,是 containerd 通过 config.json 传给 runc 的;本文的程序也支持这些配置,只是简单起见在程序里 hardcode 了。
下面是一个真实 k8s pod 对应的 config.json:
(node1) $ cat /run/containerd/io.containerd.runtime.v1.linux/moby/eedd6341c/config.json | jq
{
"process": {
"user": {
"uid": 0,
"gid": 0
},
"args": [ ],
...
"memory": {
"limit": 2147483648,
"swap": 2147483648,
},
"cpu": {
"shares": 1024,
"quota": 100000,
"period": 100000,
"cpus": "0-31"
},
"blockIO": {
"weight": 0
},
"cgroupsPath": "/kubepods/besteffort/pod187acdb9/eedd6341c",
"namespaces": [
{
"type": "mount"
},
{
"type": "network"
},
...
],
"maskedPaths": [
"/proc/asound",
"/proc/acpi",
"/proc/kcore",
"/proc/keys",
"/proc/latency_stats",
"/proc/timer_list",
"/proc/timer_stats",
"/proc/sched_debug",
"/proc/scsi",
"/sys/firmware"
],
"readonlyPaths": [
"/proc/bus",
"/proc/fs",
"/proc/irq",
"/proc/sys",
"/proc/sysrq-trigger"
]
}
}
4.1.2 容器运行时(container runtime)
如果根据下面的定义,本文的程序其实就是一个容器运行时:
The container runtime is a software package that knows how to leverage specific features on a supported operating system to create a space to run the specified container image.
4.2 自动解压镜像创建容器
本文创建容器时,是先手动将一个 docker 镜像解压到本地目录,然再指定这个目录创建容器。 这个过程用程序来实现也是很简单的,只需要对我们的程序稍加扩展就行, 就能直接指定 docker 镜像创建容器了。
不过这个过程(镜像打包和解压)很容易引入安全漏洞, 社区的几个相关 bug。
4.3 容器网络
这个要花的篇幅就比较长了,常规网络方案来说分几步:
- 在宿主机上创建一个 Linux bridge;
- 创建一个 veth pair,一端连接到 Linux bridge,一端放到容器的 network namespace 内;
- 配置 IP/MAC/NAT 规则等,让容器网络能连通。
可以用 net_prio cgroup controller 对网络资源进行限额。
编程参考:
// Compile: "gcc -Wall -Werror -static subverting_networking.c"
#define _GNU_SOURCE
#include <stdio.h>
#include <unistd.h>
#include <sched.h>
#include <sys/ioctl.h>
#include <sys/socket.h>
#include <linux/sockios.h>
int main (int argc, char **argv) {
if (unshare(CLONE_NEWUSER | CLONE_NEWNET)) {
fprintf(stderr, "++ unshare failed: %m\n");
return 1;
}
/* this is how you create a bridge... */
int sock = 0;
if ((sock = socket(PF_LOCAL, SOCK_STREAM, 0)) == -1) {
fprintf(stderr, "++ socket failed: %m\n");
return 1;
}
if (ioctl(sock, SIOCBRADDBR, "br0")) {
fprintf(stderr, "++ ioctl failed: %m\n");
close(sock);
return 1;
}
close(sock);
fprintf(stderr, "++ success!\n");
return 0;
}
4.4 特殊目录
我们容器内的目录:
# ls /
bin dev etc home lib lib64 root tmp usr var
就是busybox 镜像解压之后的目录,没有任何新增或减少。 对比宿主机根目录,
# In the container
# ls /
bin dev etc home lib lib64 root tmp usr var
# On the node
$ ls /
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
可以看到,少了 boot/mnt/opt/proc/run/sbin/srv/sys
这几个目录。
这里讨论下其中最重要的两个:/proc 和 /sys,它们不是普通目录,也不是普通文件系统,
所以需要容器运行时单独处理,在创建容器时挂载进去。Linux node 上执行,
$ mount | egrep "(/sys|/proc)"
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
...
可以看到它们是两种不同的特殊文件系统:
/proc:proc类型,但一般也称为procfs;/sys:sysfs类型。
他们都是内核暴露给用户空间的接口,绝大部分都是只读,获取内核信息。
4.4.1 /proc (procfs)
从发展过程来说 [4],先有的 /proc,后有的 /sys。
从 /proc 这个名字上也可以看成,主要用于存储进程信息,例如每个进程都有一个对应的 /proc/<pid>/ 目录,
很多系统工具例如 ps/top/free 之类的,也是通过读取 /proc 来获取系统信息的。
但由于缺乏统一设计和管理,/proc 越来越庞杂,有失控的趋势,
因此后来又设计了一个全新的文件系统,这就是 /sys。
4.4.2 /sys (sysfs)
/sys 更加结构化,组织得更好。
较新的基础设施都是基于 sysfs 的,但开源产品惯性太大,
Linux 惯性尤其大,所以 /proc 还是继续维护和使用的。
4.4.3 容器 /proc 存在的问题或挑战
如果看 docker/containerd/runc 之类的容器运行时,会发现它是把宿主机 /proc 挂载到了容器,
这会导致什么问题呢?
刚才说了,/proc 里面都是进程的统计信息,因此直接把宿主机 /proc 暴露给容器,将带来几方面问题:
- 容器内能看到宿主机以及其他容器的进程信息(虽然原则上是只读的),存在安全风险;
-
容器内读取某些文件,例如
/proc/meminfo,本来是希望得到容器自己的内存信息,但实际上拿到的是宿主机的,因此数据不准,- 人看了或很困惑,但这还是不是最重要的,
- 如果上层应用直接依赖这个数据,比如监控系统或一些 Java 业务应用,那会直接导致业务问题。
- 资源视图错误:结合 1 & 2,容器看到的东西比自己应该看到的多,或者看到的资源量比自己真实能用的资源大;
但要解决这个问题又是比较麻烦的,因为容器的设计目的只是通过必要的资源隔离来完成计算任务, 并不是让它像虚拟机一样作为独立机器提供给用户。 那实际中是怎么解决呢?
5.1 案例研究:为什么容器 /proc/meminfo 对,但 /proc/cpuinfo 不对
我们通过一个真实 k8s 环境中的例子来倒查一下。
5.1.1 查看容器 /proc/cpuinfo 和 /proc/meminfo
在一个 k8s+docker+containerd+runc 的环境,挑一个容器,
$ k get pod -n <ns> <pod> -o yaml
...
resources:
requests:
cpu: 125m
memory: 751619276800m
limits:
cpu: "1"
memory: 1Gi
这里的意思是,这个容器需要 125m = 125/1000 = 1/8 个 CPU,751 MB 内存;
最多能使用 1 个 CPU,1GB 内存。
在容器里面看 /proc 挂载信息:
(container) # cat /proc/mounts | grep proc
proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0
lxcfs /proc/meminfo fuse.lxcfs ro,relatime,user_id=0,group_id=0,allow_other 0 0
lxcfs /proc/diskstats fuse.lxcfs ro,relatime,user_id=0,group_id=0,allow_other 0 0
proc /proc/bus proc ro,relatime 0 0
proc /proc/fs proc ro,relatime 0 0
proc /proc/irq proc ro,relatime 0 0
proc /proc/sys proc ro,relatime 0 0
proc /proc/sysrq-trigger proc ro,relatime 0 0
tmpfs /proc/acpi tmpfs ro,relatime 0 0
tmpfs /proc/kcore tmpfs rw,nosuid,size=65536k,mode=755 0 0
tmpfs /proc/keys tmpfs rw,nosuid,size=65536k,mode=755 0 0
tmpfs /proc/timer_list tmpfs rw,nosuid,size=65536k,mode=755 0 0
tmpfs /proc/sched_debug tmpfs rw,nosuid,size=65536k,mode=755 0 0
tmpfs /proc/scsi tmpfs ro,relatime 0 0
然后通过 /proc 查看 CPU 和内存:
(container) # cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
...
processor : 31 # 32 CPU
vendor_id : GenuineIntel
(container) # cat /proc/meminfo
MemTotal: 1048576 kB # 1GB
MemFree: 893416 kB
MemAvailable: 893416 kB
...
可以看到,Memory 是对的,CPU 不对,实际上是宿主机的 CPU 数量。 我们接下来是看看为什么会这样。
5.1.2 定位容器 /proc/cpuinfo 和 /proc/meminfo 挂载来源:/var/lib/lxcfs/
在宿主机上查看容器的 config.json 文件,
前面提到过,runc 就是根据这个文件创建容器的,
$ cat /run/containerd/io.containerd.runtime.v1.linux/moby/d32b1bf.config.json | jq .
里面能看到文件的挂载信息:
{
"destination": "/proc/meminfo",
"type": "bind",
"source": "/var/lib/lxcfs/proc/meminfo",
"options": [
"rbind",
"ro",
"rprivate"
]
},
{
"destination": "/proc/diskstats",
"type": "bind",
"source": "/var/lib/lxcfs/proc/diskstats",
"options": [
"rbind",
"ro",
"rprivate"
]
},
可以看到有 meminfo 的挂载,但是没有 cpuinfo 的挂载。
这个配置是从 k8s 一路传下来的,因此我们去 k8s 里再看看 pod spec。
5.1.3 查看 Pod lxcfs 路径挂载
$ k get pod xxx -n <ns> <pod> -o yaml
volumeMounts:
- mountPath: /proc/meminfo
name: meminfo
readOnly: true
- mountPath: /proc/diskstats
name: diskstats
readOnly: true
volumes:
- hostPath:
path: /var/lib/lxcfs/proc/meminfo
type: File
name: meminfo
- hostPath:
path: /var/lib/lxcfs/proc/diskstats
type: File
name: diskstats
确实是 pod 里面指定的,而且只有 meminfo 的挂载,没有 cpuinfo 的挂载。
到这里答案基本就猜到了:
- 信息正确的
/proc/meminfo,是通过 lxcfs 挂载来实现的; /proc/cpuinfo不正确是因为没有配置 lxcfs 或者不支持。
5.2 解决方式总结
前面已经分析了 /proc 不准的问题,以及把它搞准所面临的挑战。
实际中怎么解决的呢?分两种。
5.2.1 从上层解决:应用主动适配 cgroup
应用程序主动适配 cgroup,需要的信息都去容器的
/sys/fs/cgroup 目录读取,不要去容器的 /proc/ 目录读。
很多监控采集程序都是这么做的,比如 k8s 用的 cadvisor,采集 cpuload,
5.2.2 从底层解决:tmpfs/lxcfs
为了兼容用户程序,用 tmpfs/lxcfs 等特殊文件系统挂载来模拟部分 /proc 文件,也是一种解决方式。
5.3 tmpfs
tmpfs (Temporary File System) 是很多 Unix-like 操作系统都支持的一种临时文件存储方案。
- 看起来是挂载的文件系统(mounted file system);
- 但数据在内存(非持久存储),
类似的还有 RAM disk, 看起来是一个虚拟磁盘,有磁盘文件系统,但其实数据在内存中。
从上面容器的输出可以看成,下面的文件都是用 tmpfs 覆盖的,
(container) # cat /proc/mounts | grep proc
..
tmpfs /proc/acpi tmpfs ro,relatime 0 0 # 只读
tmpfs /proc/kcore tmpfs rw,nosuid,size=65536k,mode=755 0 0 # 读写
tmpfs /proc/keys tmpfs rw,nosuid,size=65536k,mode=755 0 0 # 读写
tmpfs /proc/timer_list tmpfs rw,nosuid,size=65536k,mode=755 0 0 # 读写
tmpfs /proc/sched_debug tmpfs rw,nosuid,size=65536k,mode=755 0 0 # 读写
5.4 lxcfs
5.4.1 lxcfs+fuse 基本工作原理
lxcfs 是一个简单的用户空间文件系统,设计目的就是 workaround 当前的一些 Linux 内核限制。 提供两个主要东西:
- 一些文件:能
bind-mount到/proc,做到 CGroup-aware; - 一个 cgroupfs-like tree:container aware。
代码基于 libfuse 用纯 C 编写。
上面的容器输出里:
(container) # cat /proc/mounts | grep proc
...
lxcfs /proc/meminfo fuse.lxcfs ro,relatime,user_id=0,group_id=0,allow_other 0 0 # 只读
lxcfs /proc/diskstats fuse.lxcfs ro,relatime,user_id=0,group_id=0,allow_other 0 0 # 只读
用 lxcfs 接管了 /proc/meminfo 和 /proc/diskstats,但是没有接管 /proc/cpuinfo,这也是为什么
我们前面看到 Memory 是对的,CPU 数量不对。
lxcfs 工作原理说起来非常简单:node 上起一个 daemon 进程,
劫持容器内的 /proc 读操作,
通过 fuse 文件系统转到对容器 cgroupfs 的读写,然后将信息返回给请求方,如下图所示:
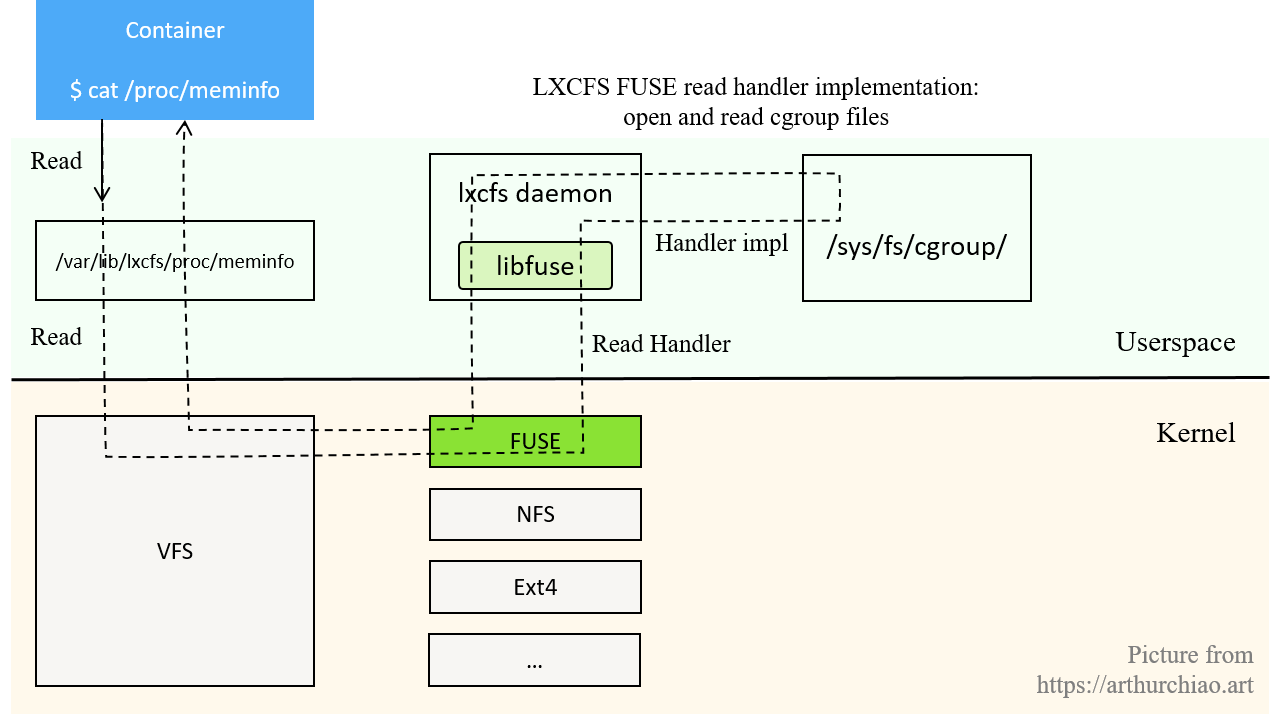
Fig. lxcfs/fuse workflow: how a read operation is handled
5.4.2 组件
只有一个 daemon 进程,运行在每个 node 上:
(node) $ systemctl status lxcfs
● lxcfs.service - FUSE filesystem for LXC
Loaded: loaded (/usr/lib/systemd/system/lxcfs.service; enabled; vendor preset: disabled)
Active: active (running)
查看配置:
$ cat /usr/lib/systemd/system/lxcfs.service
[Unit]
Description=FUSE filesystem for LXC
ConditionVirtualization=!container
Before=lxc.service
Documentation=man:lxcfs(1)
[Service]
ExecStart=/usr/bin/lxcfs /var/lib/lxcfs/
KillMode=process
Restart=on-failure
ExecStopPost=-/bin/fusermount -u /var/lib/lxcfs # <-- fuse 挂载路径
Restart=always
RestartSec=3
Delegate=yes
5.4.3 提供的目录挂载范围
默认 fuse 挂载路径 /var/lib/lxcfs/,
$ tree /var/lib/lxcfs/ -L 2
/var/lib/lxcfs/
├── cgroup
│ ├── blkio
│ ├── cpu,cpuacct
│ ├── cpuset
│ ├── devices
│ ├── freezer
│ ├── hugetlb
│ ├── memory
│ ├── name=systemd
│ ├── net_cls,net_prio
│ ├── perf_event
│ ├── pids
│ └── rdma
└── proc
├── cpuinfo
├── diskstats
├── meminfo
├── stat
├── swaps
└── uptime
这里列几个生产环境在用但又比较特殊的容器运行时。
6.1 NVIDIA container runtime
老的 nvidia-docker 已经不再维护,官方建议用新方案 github.com/NVIDIA/nvidia-container-toolkit:
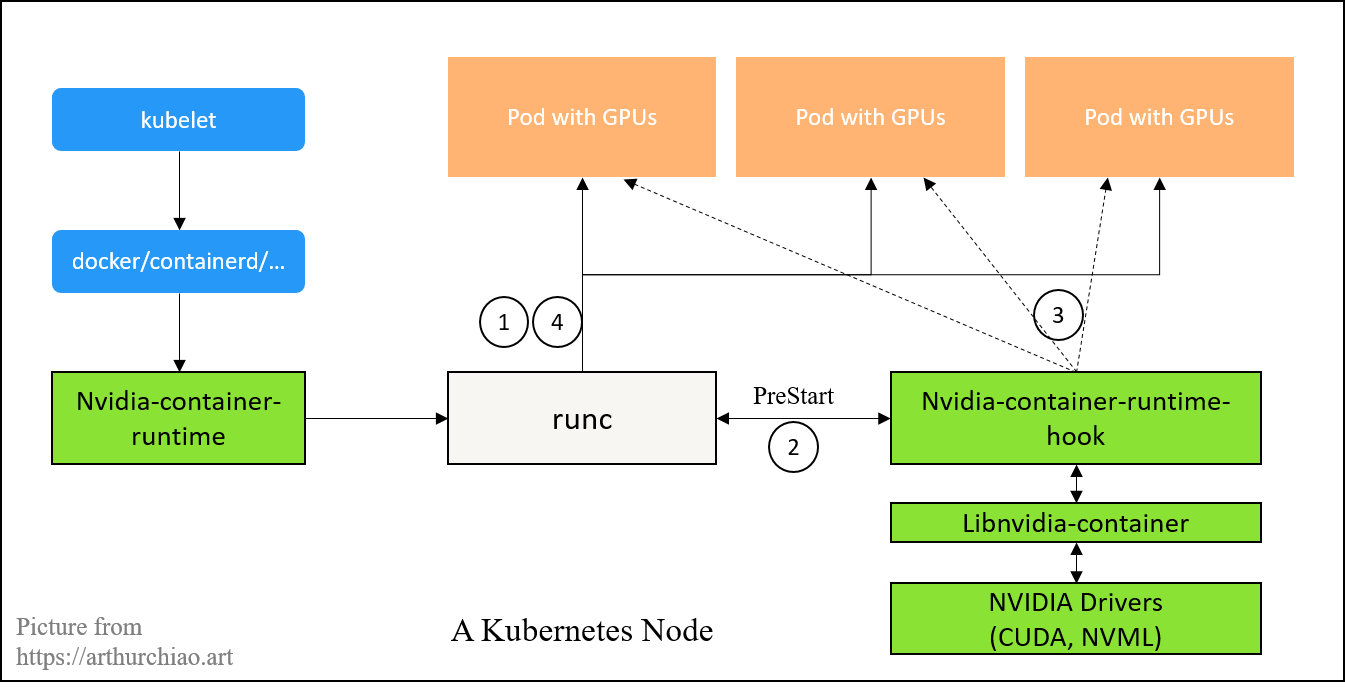
Fig. A Kubernetes node with nvidia container runtime
注册了 runc 的 PreStart hook,在这一步去修改容器的 config.json
(runc 创建容器用到的容器配置文件),例如插入 GPU 相关配置。
更多信息见官方 Architecture Overview。
同样是百行代码(创建一个基本容器的代码还可以大幅缩减),创建一个 VM 的过程就跟创建一个容器就非常不同。
VM 的事情基本是内核一次性做的,更像一个黑盒,因此虚拟机时代基础设施开发者能做的事情更上层一些, 更多地是基于 KVM API 来做一些更上层的资源和状态管理工作,而深入到 KVM 内部的机会和需求都比较少,粒度更粗。
到了容器时代,上面已经看到,它不再是内核封装好的一个“黑盒”,而像是拼积木一样, 基于几种内核机制拼出来的一个东西。它在某些方面跟虚拟机很像,但通过本文应该看到, 二者又有本质的差别,尤其是在隔离和安全性方面。
实际上,关于容器的好处和场景业界都已经达成高度一致,大规模的生产部署也验证了这个方向的正确性, 但关于什么是容器现在似乎仍然没有一个普遍接受的定义 —— 也说明并不是那么重要。
希望本文能给基础设施研发/运维带来一些帮助和启发。
如有侵权请联系:admin#unsafe.sh