原文标题:AUTOMATED CVE ANALYSIS FOR THREAT PRIORITIZATIONAND IMPACT PREDICTION原文作者:Ehsan Aghaei, Ehab A 2023-12-28 23:4:31 Author: 安全学术圈(查看原文) 阅读量:24 收藏
原文标题:AUTOMATED CVE ANALYSIS FOR THREAT PRIORITIZATION AND IMPACT PREDICTION
原文作者:Ehsan Aghaei, Ehab Al-Shaer, Waseem Shadid, Xi Niu
发表会议:arxiv预发表
原文链接:https://arxiv.org/abs/2309.03040
主题类型:漏洞治理
笔记作者:ALKA
主编:黄诚@安全学术圈
作者认为手动为CVE评级太慢了,决定实现CVE评级的自动化,CVSS打分自动化,以及VT分类自动化
文章实现了利用CVE为数据集,使用通用脆弱性评分系统(CVSS)自动评估其攻击严重程度,并将其映射到通用弱点枚举(CWE),以进行潜在的缓解识别。
方法是提出了一种名叫CVEDrill的工具,它准确地估计了CVSS向量,用于精确的威胁缓解和优先级排序,并无缝地自动化了将CVEs分类到适当的CWE层次结构类中。
简单来说就是实现了CVE的自动分类和评分(和CVE-DRIVEN ATTACK TECHNIQUE PREDICTION WITH SEMANTIC INFORMATION EXTRACTION AND A DOMAIN-SPECIFIC LANGUAGE MODEL这篇论文的内容未免也太相似了)
论文主要贡献有三点:
实现了CVE评级的自动化 CVEDrill:实现了轻量级的语言模型,解决了chatgpt造价昂贵的缺点 SecureBERT:将专门针对于网络安全的burt模型与CVE结合,
SecureBERT:是BERT的一个衍生品,已经在大量的网络安全文档上进行了再训练
CVSS预测
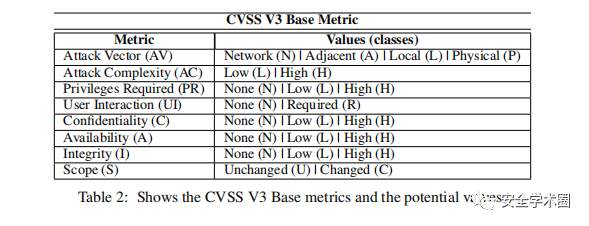
作者预测采用的是v3的CVSS其需要输入的向量如下图所示
目前CVSS都是手动评分,作者反复强调效率很差,来凸显自动评分的优越性
上图V3版本的CVSS一个八个指标,作者开发了8个独立的模型。这些模型利用漏洞的CVE描述作为输入,并生成相应的CVSS度量的投影值作为输出
使用TF-IDF模块解决数据不均衡问题
首先遇到的第一个问题就是数据不均衡。作者将预先训练过的SecureBERT模型作为基础框架,并引入了一个额外的TF-IDF模块来解决数据不平衡的问题。
使用TFIDF分数旨在提高该模型在训练过程中识别少数关键字的能力,这包括提取签名字,并将它们转换为向量,以便与SecureBERT的输出进行集成。
作者设定了一个阈值,将TFI-DF值过低,也就是没那么重要的值删去,并形成字典M,Dict (M)包含关于每个度量中少数值的高度信息。
这样的话,当拿到一个CVE语句时,作者的模型首先会将字典与语句取交集
下图为CVE输入和TF-IDF输出过程针对有没有使用TF-IDF,作者也进行了实验对比,发现这东西确实不错。
SecureBERT实现了80%−96%的预测加权精度,80%−95%的微观水平,73%−91%的宏观水平的f1分数。基于性能结果,结合TF-IDF模块的模型比替代模型表现出优越的性能。
自动从CVE到CWE和VT的分类
分类挑战
一个CVE可能会映射到不同的CWE CVE手动映射到CWE既不可扩展也不可靠。
基于SecureBERT和CWE层次树的解决方案
作者在SecureBERT之上创建了一个分层分类层作为下游任务。该模型将一个CVE描述作为输入。
值得注意的是作者开发了一种自上而下的策略,在CWE层次树中的每个节点(类)上训练一个分类器。将模型的注意力引导到兄弟姐妹节点之间的共性和对比上。这有助于降低模型的复杂性。这个树的实现图如下。
这样的话,每一个结点就只需要注意是否与兄弟姐妹相似就可以了。
这个CWE树的主要作用就是为了提高运行效率。
模型整体如下
最终提出的模型的命中率(准确率)的成功率为90.77%~97.51%,F1-score的成功率为84.91%~96.08%。这些结果表明,由于可用于训练模型的样本数量较高,因此对属于前25位的CVEs的分类成功率更高。
与此同时对VT的预测准确率也达到了较高的水平
个人感想
这篇文章和上一篇卡耐基梅隆大学的文章有着很相似的地方,同样是对CVE进行分类,也同样是利用SecurityBERT,但细节确实完全不同,上一篇文章的重点在于CVE中的语义提取和上下文关联,这篇文章重点则是通过TF-IDF获取关键字,并使用自创的CWE层次树来对其进行分类。
这篇文章的细节讲述的比较少,但篇幅依旧很长,比如CWE层次树的具体实现本文没有过多提及。看完文章也不能够完整复现出来。
这篇文章对比上一篇可以感觉到工作量大了几倍。但主要还是基于SecurityBERT。大体框架是没有太大变化的。感觉SecurityBERT框架结合点其他网络安全的问题再与chatgpt对比一下就比较容易发论文。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh