One of the most annoying hunting exercises is detecting a sequence of failures followed by a suc 2024-1-2 01:23:21 Author: www.hexacorn.com(查看原文) 阅读量:36 收藏
One of the most annoying hunting exercises is detecting a sequence of failures followed by a success. Brute-force attacks, dictionary attacks, and finally password spray attacks have all this in common: lots of failures, sometimes followed by a success.
The problem is stated clearly, but there is no easy solution.
Why?
Most of logs are stateless. Every log row describes an event, and every row is detached from the others. Combing them, combining them, clustering them and extracting some juice from them is a detection engineering art on its own…
So, yes… it’s actually hard to detect these types of sequences and it’s usually very expensive f.ex. if you use Splunk it offers its transaction command for situations like this, but it’s a very very bad choice: it affects performance too much.
There is a more elegant solution out there though… and I call it bitmap hunting.
Instead of getting fixated on the sequence of the events that fit our narrative (set of failures followed by a success in the above example), we focus on building a bitmap of ALL states registered by the respective telemetry, the one that we can always group by the endpoint name, user, time/time bucket, etc..
Let’s look at an example:
| makeresults | eval endpoint="sys01" | eval username="test" | eval status = 0 | append [| makeresults | eval endpoint="sys01" | eval username="foo" | eval status = 0] | append [| makeresults | eval endpoint="sys01" | eval username="bar" | eval status = 0] | append [| makeresults | eval endpoint="sys01" | eval username="abc" | eval status = 0] | append [| makeresults | eval endpoint="sys01" | eval username="nimda" | eval status = 0] | append [| makeresults | eval endpoint="sys01" | eval username="root" | eval status = 0] | append [| makeresults | eval endpoint="sys01" | eval username="r00t" | eval status = 0] | append [| makeresults | eval endpoint="sys01" | eval username="john.doe" | eval status = 1] | append [| makeresults | eval endpoint="sys02" | eval username="jane.doe" | eval status = 0] | append [| makeresults | eval endpoint="sys02" | eval username="jane.doe" | eval status = 1] | table _time, endpoint, username, status
These SPL commands build a list of fake events for us, where 2 endpoints sys01 and sys02 register their logon events, where the endpoint, username, and status fields/columns include all the info about the set of events occurring. In essence, this is how it looks like (ignore the _time as I didn’t want to clutter the commands above even more):
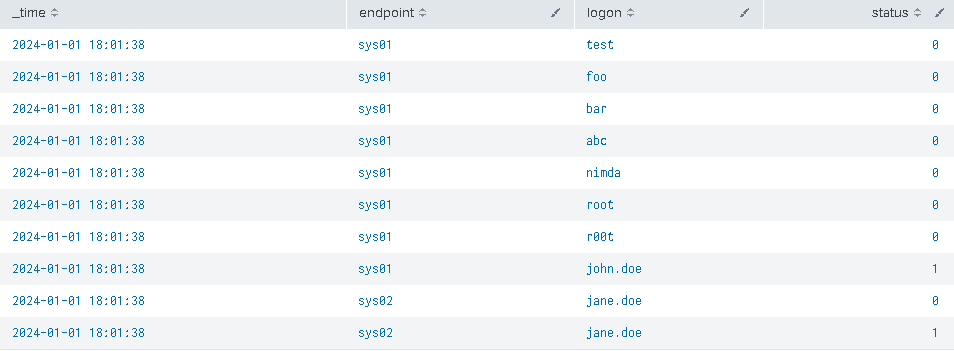
We can use the status of all events (success=1, failure=0) to build a bitmap of all of them by grouping them all together by the endpoint:
| stats list(status) as allstatuses, list(username) as allusernames by endpoint | eval allstatuses_bitmap = mvjoin(allstatuses,"") | table endpoint, allstatuses_bitmap, allusernames
The result gives us this:
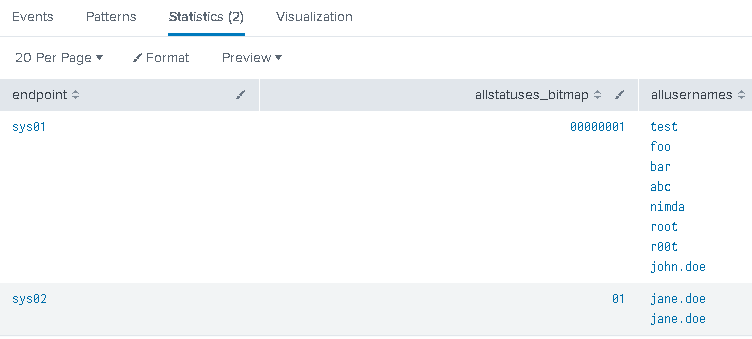
As you can clearly see, it’s pretty easy now to ‘guess’ that sys02 user Jane.doe is just a possible typo or otherwise minor issue that led the user account to be logged in after the first failure, while the sys01 system experienced a barrage of logon attempts with different user names that eventually led to a successful logon. The sys01 should be definitely investigated.
Looking at the bitmap created by all the logon statuses we can quickly devise a logic to detect f.ex. successful password spray attacks:
| stats list(status) as allstatuses, list(username) as allusernames by endpoint
| eval allstatuses_bitmap = mvjoin(allstatuses,"")
| where like(allstatuses_bitmap, "%0001")
| table endpoint, allstatuses_bitmap, allusernames
In the example above, we detect at least 3 failed logons before a successful logon.
And yes, it will hit False Positives too, but at least we now have something to triage…
p.s. logon events are just one example, but you can convert any condition into a bitmap — as such, you can build more complex conditions too (f.ex. more than two specific events present in a sequence of events)
如有侵权请联系:admin#unsafe.sh