一
基本用法
在面向对象中的用法
class Singleton
{
public:
static Singleton& instance() // 静态方法
{
static Singleton inst; // 静态对象在instance中声明
return inst;
}
int& get() { return value_; }
private:
Singleton() : value_(0) { std::cout << "Singleton::Singleton()" << std::endl; }
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
~Singleton() { std::cout << "Singleton::~Singleton()" << std::endl; }
private:
int value_; // 非静态成员变量
};int value = Singleton::instance().get() // Singleton::instance()返回静态对象inst
在面向过程中的用法
二
新的问题
考虑到静态变量有可能被多次初始化且使用变量初始化,使用的例子如下:
#include <iostream>
#include <thread>
#include <chrono> // std::chrono::secondsusing namespace std;
void func_a();
void func_b(int a, int b);int main()
{
func_a();
thread t1(func_b, 1, 2);
thread t2(func_b, 3, 4);
thread t3(func_b, 5, 6);
thread t4(func_b, 7, 8);std::this_thread::sleep_for(std::chrono::seconds(1));
getchar();
t1.join();t2.join();t3.join();t4.join();
return 0;
}void func_a()
{
static int func_a_value = 0x1234;
cout << "func_a_value => " << func_a_value << ", current function = > " << __FUNCTION__ << endl;
}void func_b(int a, int b)
{
static int res = a + b;
cout << "res => " << res << ", current thread id => " << std::this_thread::get_id() << endl;
}
Windows下的MSVC编译器的实现
静态局部变量func_a_value
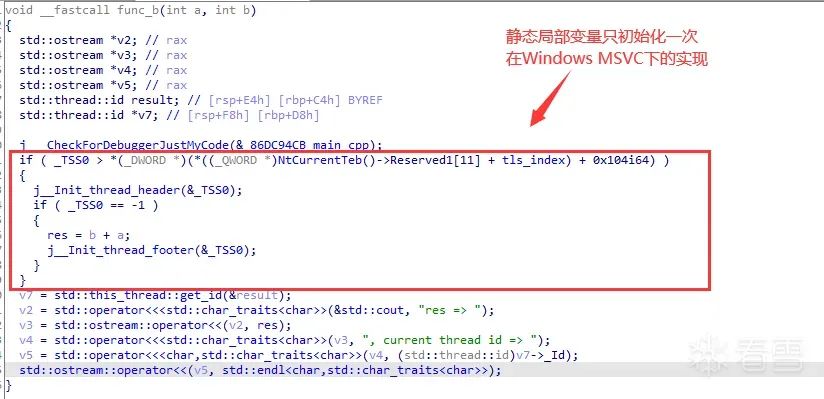
静态局部变量res
if(pOnce > *(int *)(NtCurrentTeb()->ThreadLocalStoragePointer[0] + 0x104) // tls中存储的全局 局部静态变量初始化计数器, 初始值为INT_MIN(0x80000000)
{
_Init_thread_header(&pOnce)
if ( pOnce == -1 )
{
res = b + a; // 初始化代码
_Init_thread_footer(&pOnce);
}
}
// 代码所在的文件为thread_safe_statics.cpp
extern "C" void __cdecl _Init_thread_header(int* const pOnce) noexcept
{
_Init_thread_lock(); // 进入临界区if (*pOnce == uninitialized) // uninitialized = 0
{
*pOnce = being_initialized; // being_initialized = -1
}
else
{
while (*pOnce == being_initialized)
{
// Timeout can be replaced with an infinite wait when XP support is
// removed or the XP-based condition variable is sophisticated enough
// to guarantee all waiting threads will be woken when the variable is
// signalled.
_Init_thread_wait(xp_timeout);if (*pOnce == uninitialized)
{
*pOnce = being_initialized;
_Init_thread_unlock();
return;
}
}
_Init_thread_epoch = _Init_global_epoch; // _Init_global_epoch = INT_MIN
}_Init_thread_unlock(); // 离开临界区
}
// 代码所在的文件为thread_safe_statics.cpp
extern "C" void __cdecl _Init_thread_footer(int* const pOnce) noexcept
{
_Init_thread_lock();
++_Init_global_epoch;
*pOnce = _Init_global_epoch;
_Init_thread_epoch = _Init_global_epoch;
_Init_thread_unlock();
_Init_thread_notify();
}
t2线程进入func_b,此时pOnce = INT_MIN+1,既不是0也不是-1。进入_Init_thread_header之后,pOnce的值不会改变。自然而然,res的值也不会发生改变。t3和t4线程的执行情况同t2线程。
那么此时的执行情况如下:
Linux下的G++编译器的实现
静态局部变量func_a_value
静态局部变量res
__cxa_guard_acquire函数源码
// guard.cc
int __cxa_guard_acquire (__guard *g) // typedef int __guard, 初始值为0
{
if (_GLIBCXX_GUARD_TEST_AND_ACQUIRE (g)) //
return 0;if (__gnu_cxx::__is_single_threaded()) // 调用pthread_create时,__gnu_cxx::__is_single_threaded() 为false
{
// No need to use atomics, and no need to wait for other threads.
int *gi = (int *) (void *) g;
if (*gi == 0)
{
*gi = _GLIBCXX_GUARD_PENDING_BIT; // 0x100
return 1;
}
else
{
throw_recursive_init_exception();
}
}
else
{
int *gi = (int *) (void *) g;
const int guard_bit = _GLIBCXX_GUARD_BIT; // 1
const int pending_bit = _GLIBCXX_GUARD_PENDING_BIT; // 0x100
const int waiting_bit = _GLIBCXX_GUARD_WAITING_BIT; // 0x10000while (1)
{
int expected(0);
if (__atomic_compare_exchange_n(gi, &expected, pending_bit, false,
__ATOMIC_ACQ_REL,
__ATOMIC_ACQUIRE))
{
return 1; // This thread should do the initialization.
}if (expected == guard_bit)
{
// Already initialized.
return 0;
}if (expected == pending_bit)
{
// Use acquire here.
int newv = expected | waiting_bit; // 0x10100
if (!__atomic_compare_exchange_n(gi, &expected, newv, false,
__ATOMIC_ACQ_REL,
__ATOMIC_ACQUIRE))
{
if (expected == guard_bit) // 1
{
// Make a thread that failed to set the
// waiting bit exit the function earlier,
// if it detects that another thread has
// successfully finished initialising.
return 0;
}
if (expected == 0)
continue;
}expected = newv;
}syscall (SYS_futex, gi, _GLIBCXX_FUTEX_WAIT, expected, 0);
}
}
return acquire (g);
}
// guard.cc
extern "C" void __cxa_guard_release (__guard *g) noexcept
{
// If __atomic_* and futex syscall are supported, don't use any global
// mutex.
if (__gnu_cxx::__is_single_threaded())
{
int *gi = (int *) (void *) g;
*gi = _GLIBCXX_GUARD_BIT; // 1
return;
}
else
{
int *gi = (int *) (void *) g;
const int guard_bit = _GLIBCXX_GUARD_BIT;
const int waiting_bit = _GLIBCXX_GUARD_WAITING_BIT;
int old = __atomic_exchange_n (gi, guard_bit, __ATOMIC_ACQ_REL);if ((old & waiting_bit) != 0)
syscall (SYS_futex, gi, _GLIBCXX_FUTEX_WAKE, INT_MAX);
return;
}
set_init_in_progress_flag(g, 0);
_GLIBCXX_GUARD_SET_AND_RELEASE (g);
}
b. t2 线程进入时,因为g = 0x1,t2在__cxa_guard_acquire函数的41行返回,因返回值为0,因此不会对res再次初始化。t3和t4所遇情况,同t2线程。
a. t1线程,__cxa_guard_acquire-> res的初始化流程,此时g = 0x100。
c. 若t3或t4线程同t2线程,也执行func_b函数,则会被syscall(SYS_futex)系统调用阻塞。若t3或t4在t1执行__cxa_guard_release函数后调用func_b,这种情况同CASE ONE下。
总结
看雪ID:baolongshou
https://bbs.kanxue.com/user-home-738427.htm
# 往期推荐
2、在Windows平台使用VS2022的MSVC编译LLVM16
3、神挡杀神——揭开世界第一手游保护nProtect的神秘面纱
球分享
球点赞
球在看
如有侵权请联系:admin#unsafe.sh