2024-1-4 17:26:40 Author: securityboulevard.com(查看原文) 阅读量:10 收藏
Introduction
This is not a beginner’s blog post. As such, we will not tell you about the importance of securing your Kubernetes infrastructure (it’s important). However, if you are here to learn about increasing the efficiency of your security work and the blind spots you may have, you have come to the right place.
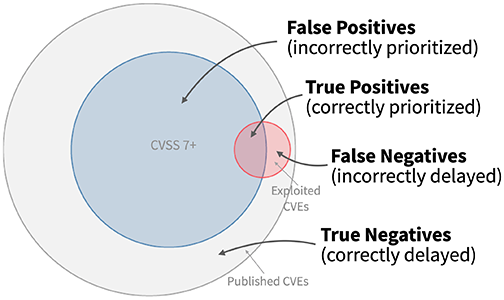
You may have heard of and are already using CVSS as your gold standard for vulnerability prioritization. This is probably the result of how open-source and commercial scanners provide results to you. However, as you read this, I’d like you to keep in mind that CVSS was never intended to be that end-all software vulnerability scoring system. The following graphic tells this story well.
In this post, we will talk about two additional scoring systems: EPSS and KEV. Together with CVSS, these systems are all available and complement each other. Every scoring system has limitations. Looking at all of them together gives a more complete and less noisy result from scanners.
We will conclude the post by analyzing real data from ARMO customers. We will show that layering different scoring systems and adding runtime context, optimizes the scanner signal to noise ratio. This will ensure that the security work you do actually makes a difference in your security posture, while avoiding false positives (noise) and preventing alert fatigue (or CVE Shock).

Get ARMO Platform
An end-to-end Kubernetes
security platform
powered by Kubescape
Introducing the metrics
CVSS (Common Vulnerability Scoring System)
CVSS is a commonly used vulnerability metric. It helps convey the severity of vulnerabilities. CVSS allows organizations to assess vulnerabilities in a standardized way. This helps them compare and prioritize vulnerabilities based on severity scores.
Limitations and blind spots
- Doesn’t reflect actual risk – CVSS provides a base score that represents the inherent severity of a vulnerability in isolation. However, it doesn’t take into account your specific environment, assets, and threat landscape. A vulnerability with a high CVSS score might not pose a significant risk to your organization if it doesn’t affect any critical systems or data.
- Ignores temporal factors – The base score assumes the vulnerability is actively exploited, which may not be the case. The availability of exploits, patches, and workarounds impacts the actual risk.
- Lacks context specificity – CVSS doesn’t consider the specific assets and systems affected by a vulnerability. A vulnerability affecting a critical system has a much higher impact than one affecting a non-essential service. This lack of context specificity can lead to misleading prioritization decisions.
- Relies on subjective assessments – Certain CVSS metrics, like “environmental score,” involve subjective judgments about attacker intent and exploitable likelihood. This can lead to inconsistencies and discrepancies in scoring, making comparisons across different vulnerabilities challenging.
- Evolving threat landscape – The cyber threat landscape is constantly changing, and new vulnerabilities emerge frequently. CVSS depends on accurate and timely vulnerability data, which can be a challenge to maintain. Outdated or incomplete data can lead to inaccurate assessments.
Exploit Prediction Scoring System (EPSS)
EPSS is a data-driven, community-led initiative. It estimates the probability of a software vulnerability being exploited in the wild. EPSS gives each vulnerability a probability score from 0 to 1 (or 0-100%) to show how likely it is to be exploited in the next 30 days. This system helps security practitioners prioritize fixing vulnerabilities.
Limitations and blind spots
- Overreliance on Exploitability – EPSS places a lot of importance on how likely a vulnerability is to be exploited. This means that a vulnerability with an accessible exploit may receive a high score, even if it is not very impactful. This can lead to prioritizing patching based on exploitable vulnerabilities alone, neglecting broader concerns like data sensitivity and attack vectors.
- Limited Attack Surface Focus: EPSS primarily focuses on vulnerabilities exploitable directly through the Kubernetes attack surface. This might undervalue vulnerabilities in container images, host systems, or dependencies, creating blind spots in your risk assessment.
- Subjectivity in Scoring – EPSS includes subjective factors such as attacker intent and the likelihood of successfully exploiting the system. This can cause scoring inconsistencies. It depends on how the assessor interprets it. As a result, comparisons and prioritization become less reliable.
- Lack of Standardization – EPSS lacks widespread adoption and standardization compared to CVSS.
- Limited Data Availability – The accuracy of EPSS relies on comprehensive and timely data about Kubernetes-specific vulnerabilities. Lack of proper data or outdated information can lead to inaccurate scoring and mislead risk assessments.
- Static Scoring – PSS currently presents a static score. This doesn’t readily capture the evolving threat landscape and may not reflect the actual risk over time.
KEV (Known Exploited Vulnerabilities)
KEV is a vulnerability catalog created by CISA. It provides the cybersecurity community with an authoritative source of vulnerabilities that have been exploited in the wild. This helps all organizations in effectively handling vulnerabilities and staying updated on threat activity. The public database serves as an indicator, signaling whether a vulnerability is currently being exploited in real-world scenarios. The KEV catalog should be used as an input to their vulnerability management prioritization framework.
Limitations and blind spots
- Incomplete database – KEV databases are not exhaustive and rely on reporting from various sources. Vulnerabilities discovered internally, unpublished exploits, and zero-day attacks might not be included. KEV contains less than 2000 vulnerabilities globally.
- Focus on known exploits – KEVs prioritize vulnerabilities with existing exploits, neglecting those for which exploits haven’t been publicly developed. This leaves potentially dangerous vulnerabilities off the radar until an exploit emerges.
- Static nature – KEVs change dynamically as new exploits are discovered or patches are released. Organizations relying solely on static KEV lists might miss newly exploitable vulnerabilities.
- Indirect vulnerabilities – Complex attack chains leveraging multiple vulnerabilities, including unknown ones, can bypass KEV-based defenses.
As you can see, every metric has its strengths and its blind spots. As a result, no metric can be the single one to rule them all.
By applying all of these metrics, you can reduce the number of vulnerabilities you must fix immediately by up to 95%
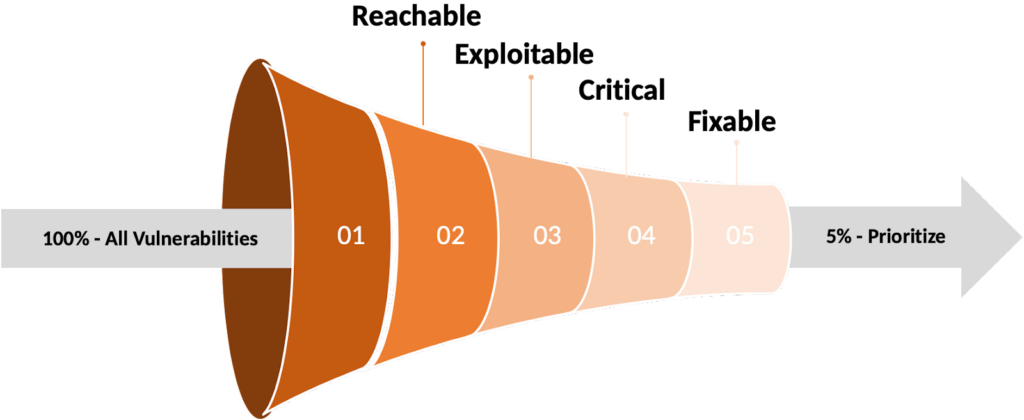
But enough with the background and academic conclusions. Let’s look at the results of the ARMO research team when studying the volume of vulnerabilities for a select subset of customers.
Welcome to the real world
To show how these vulnerability metrics can perform in practice, let’s look at real-world examples. The data set is based on anonymized production data of ARMO customers gathered in the last 12 months. This allowed our researchers to use both a large and a current data set. Additional assumptions used here:
P0 – anything that can be found in the KEV database.
P1 – anything with a combined score of EPSS >=0.1 & CVSS >= 7.0
These are the fires that security practitioners need to run to. The rest of the vulnerabilities can be classified as fires they can walk to.
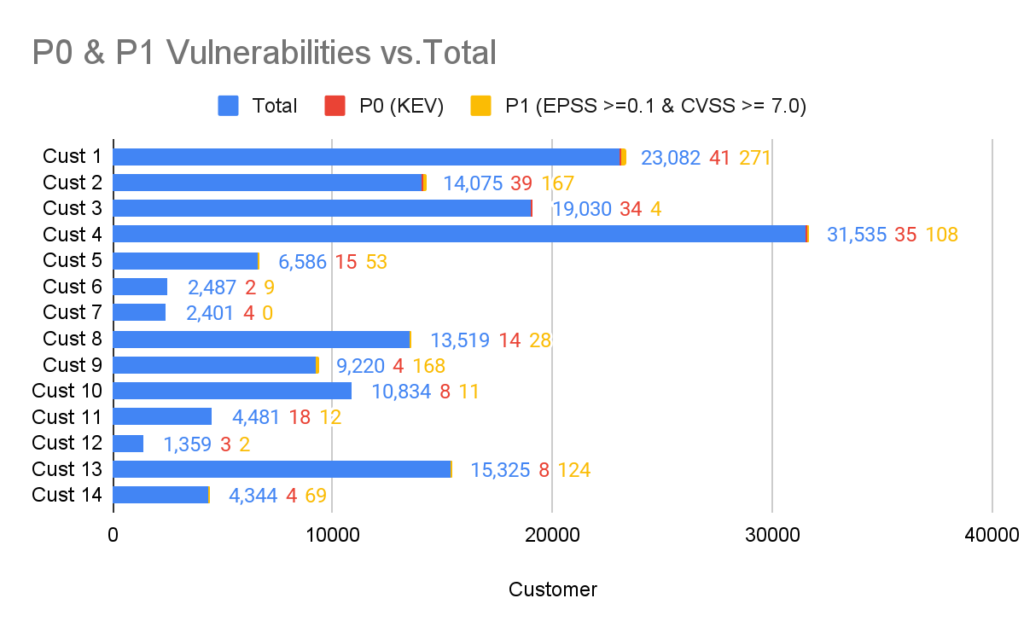
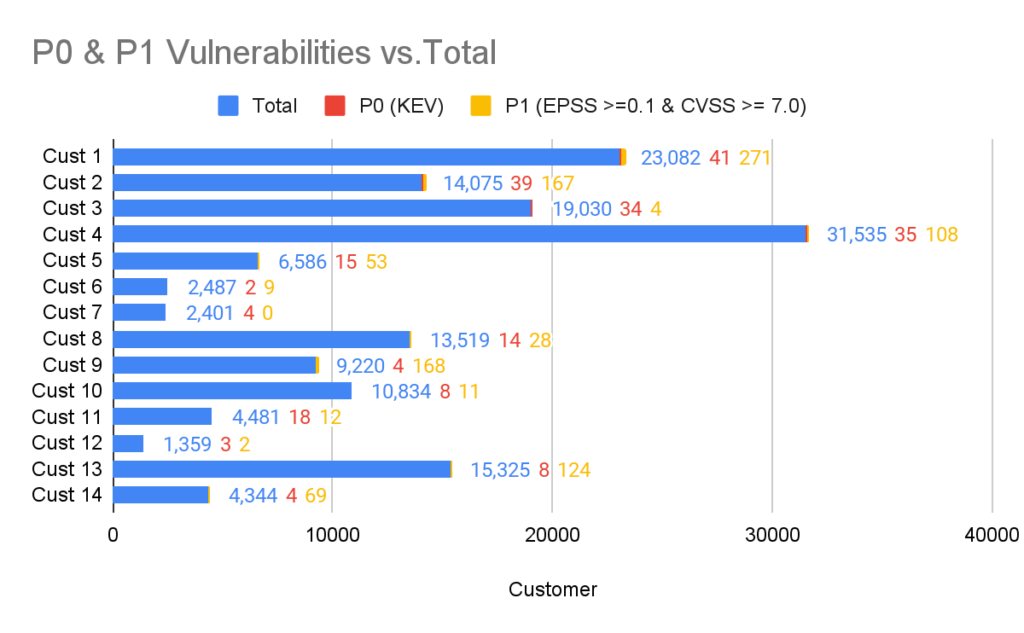
In the chart below you can see the breakdown of P0 and P1 vulnerabilities of different ARMO customers in relation to the total number of vulnerabilities identified by the Kubescape Vulnerability scanner.
The analysis included testing the total vulnerabilities against KEV to identify P0 vulnerabilities. P1 vulnerabilities were identified by crossing those with an EPSS score of 0.1 or larger and a CVSS score of 7.0 or larger (i.e. Critical and High).
When visualizing these vulnerabilities the number of P0 and P1 vulnerabilities (signal) is minuscule in relation to the total number of vulnerabilities (noise). With a signal to noise ratio of between 0.16% and 1.86%.
You can also clearly see the disparity between KEV and the EPSS/CVSS combo. This gives us an idea of the (in)completeness of the KEV database at the time of writing.
Context – the missing ingredient
Having said that, everything discussed to this point lacks a critical component and that is context. Specifically runtime context. The point is that the prioritization of security work that security practitioners need to decide on is heavily dependent on what’s really happening in their unique environment. If a vulnerable package is not used in runtime, or in a production environment, this could also have an impact on the priority of fixing it.
At ARMO we strive to give you all of this in a single place. Users of ARMO Platform can get the results of naive scanning (i.e. all scan results, which as we see above, are in the thousands). They can then filter for criticality, reachability and access to the internet. ARMO Platform’s roadmap involves integrating EPSS and KEV to provide users with a clear indication of the most critical vulnerabilities. This enables users to swiftly address these issues, saving time that would otherwise be spent researching and prioritizing vulnerabilities.
Additional context can come from crossing vulnerabilities and configuration. For example, let’s consider a scenario where an attacker gained code execution on the container from a web vulnerability and now he is running as the www-data user, which is a common user used in web servers, now, the attack wants to elevate his privileges to root and he spots the sudoedit binary in a vulnerable version (CVE-2023-22809) present on the machine, allowing him to escalate his privileges to root.
That’s a critical exploitable vulnerability! We must run to fix it!
However, let’s say you could cross-reference the vulnerability with configuration. In this example the configuration only allows the container to run as NonRoot and bars privilege escalation. As you can see in the YAML below:
apiVersion: v1 kind: Pod metadata: name: my-pod spec: securityContext: runAsNonRoot: true allowPrivilegeEscalation: false containers: - name: my-container image: my-image securityContext: runAsUser: 1000 # Specify a non-root user ID
In this case, the configuration has mitigated the vulnerability and in this specific case, there is no need to patch the vulnerability immediately.
Conclusion
Vulnerability metrics play a crucial role in assessing and prioritizing security risks in Kubernetes and cloud-native environments. By considering factors such as exploitability, prevalence, severity, scope, and impact, organizations can effectively prioritize their remediation efforts and safeguard their systems against evolving threats. However, since today, no single metric is comprehensive enough to cover everything, it is necessary to consider vulnerabilities based on multiple frameworks.
In addition, ALL security metrics lack the context of your Kubernetes infrastructure and runtime information of your application. These are crucial to whittling down the number of vulnerabilities and getting to the positives that should really concern you.
If you would like to increase the efficiency and speed of your vulnerability scanning, try ARMO Platform today.
Kubernetes security platform
{powered by Kubescape}. Free forever.
Experience effective, end-to-end, from dev to production, Kubernetes protection:
Manage Kubernetes role-based-access control (RBAC) visually
Eliminate misconfigurations and vulnerabilities from your CICD pipeline – from YAML to cluster
Full Kubernetes security compliance in a single dashboard
The post Don’t get hacked! Apply the right vulnerability metrics to Kubernetes scans appeared first on ARMO.
*** This is a Security Bloggers Network syndicated blog from ARMO authored by Oshrat Nir. Read the original post at: https://www.armosec.io/blog/kubernetes-vulnerability-metrics/
如有侵权请联系:admin#unsafe.sh