2024.01.01-2024.01.07每周文章分享标题:Achieving domain generalization for underwater object detection by dom 2024-1-6 07:1:51 Author: 网络与安全实验室(查看原文) 阅读量:38 收藏
2024.01.01-2024.01.07
每周文章分享
标题:Achieving domain generalization for underwater object detection by domain mixup and contrastive learning
期刊:Neurocomputing, vol. 528, pp. 20-34, April 2023
作者:Yang Chen, Pinhao Song, Hong Liu, Linhui Dai, Xiaochuan Zhang, Runwei Ding, and Shengquan Li
分享人:河海大学——朱远洋
研究背景
与传统场景相比,复杂的水下环境给水下物体检测带来了巨大挑战,因为在水下环境中经常会发生域转移。例如,一天中的不同时间会导致不同的光照条件,不同地区(如湖泊和海洋)的水质也有很大差异。此外,由于收集和注释水下图像非常困难,因此很难整合具有丰富领域多样性的大型水下数据集。在实际应用中,在领域多样性有限的数据集上训练的探测器要适应不断变化的水下环境是不现实的,这就导致探测器出现领域偏移。因此,大幅提高探测器对域偏移的鲁棒性是必不可少的。在野外的实际应用可以看作是一种领域泛化任务,即在一系列源域上训练模型,并在一个未见过但相关的领域上进行评估。以前的大多数工作都集中在对齐源域上,如最小化最大平均差异(MMD)和使用对抗训练。此外,目前的领域泛化工作主要集中在识别领域,很少有工作涉及检测领域。
关键技术
方法源于两个共同的假设:①增加对领域分布的采样有助于提高对领域偏移的鲁棒性。数据分布Z取决于两个先验分布:域分布D和语义内容分布S。数据集中的少量域无法代表域流形的结构,从而导致域过拟合。如果能抽取更多的域进行训练,检测器就能成功消除域偏移的影响。②理想的特征提取器会将语义内容相同的两个不同领域的特征视为等价,这是一个简单明了的想法。此外,简单地惩罚特征的方差会导致模型判别能力的下降。因此,利用余量和选择的概念,为特征的方差留出空间,以保持判别能力。
本文提出了领域混合和对比学习(DMCL)来解决水下物体检测中的领域泛化问题。首先,提出了名为“条件双边风格转换(CBST)”的风格转换模型,将水下图像从一个源域转换到另一个源域。其次,提出了特征层面上的域混合(DMX),以插值两个不同的域来合成一个新的域。CBST和DMX都增加了训练数据的域多样性。第三,提出了空间选择性边际对比(SSMC)损失,对模型学习到的特定领域特征进行正则化。最后,建立了一个新的基准S-UODAC2020。
算法介绍
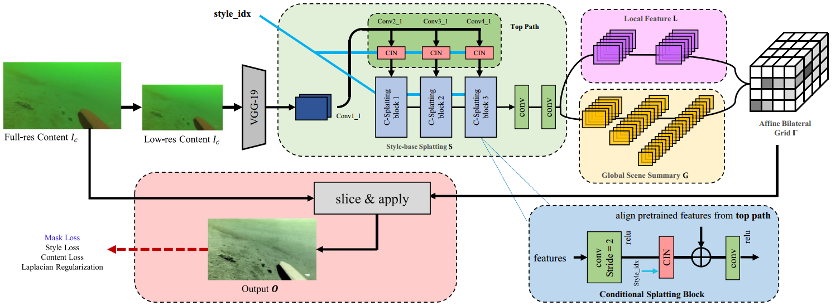
提出的方法概述如图1所示。包含三个部分:CBST、DMX和SSMC损失。首先,从一个源域选择的图像被送入CBST,以转换为另一个源域。第二,由于得到了成对的图像,DMX在训练过程中被应用于特征层面,在源域构造的域凸包内采样新的域。第三,SSMC损失被应用于配对图像的特征,以规范特定领域的特征。
图1 提出方法的框架示意图
(1)有条件的双边风格转移(CBST)
水下图像的形成可以被建模为:
根据上述方程,可以得出这样的结论:水下图像I是由色彩空间上的清晰潜影J线性变换而成的。换句话说,如果两幅水下图像具有相同的清晰潜像,它们可以相互进行线性转换。因此,提出了条件性双边风格转换来合成水下图像。它从低分辨率的风格图像中学习局部仿射色彩变换,并将该变换应用于内容图像。CBST是基于最先进的逼真风格转换模型BST设计的。与BST相比,CBST有两个主要的提升。首先,任意的风格转移是不必要的,原始网络中的所有AdaIN模块被条件实例规范化(CIN)所取代。CIN可以表示为:
受区域损失的启发,引入了mask损失。风格转移可能使图像过于风格化,导致图像内容的改变。然而,如果检测器在风格化的图像上进行训练,而内容又发生了本质的变化,注释的不匹配将导致性能的极大下降。CBST的结构如图2所示。首先,低分辨率的内容图像Clow被送入VGG19,提取特征Fconv1_1、Fconv2_1、Fconv3_1和Fconv4_1。
图2 有条件双边风格转换框架
其次,Fconv1_1被送入三个连续的拼接块。每个拼接块包含一个步长为2卷积层、一个CIN和一个步长为1卷积层。此外,Fconv2_1、Fconv3_1和Fconv4_1在CIN之后分别被添加到三个拼接块的顶部路径中。在三个拼接块之后,又有两个额外的卷积层。
第三,网络被分成两条不对称的路径。学习局部颜色变换从而设置网格分辨率的全卷积局部路径。同时具有卷积层和完全连通层的全局路径考虑了特征的所有像素,以学习场景的摘要,并帮助在空间上正则化变换。结合局部特征和全局场景摘要得到颜色变换A∈R^(16×16×96)。A可被视为16×16×8双边网格,其中每个网格单元包含12个数字,3×4仿射颜色变换矩阵的每个系数对应一个数字,这意味着A_i,j,k∈R^(3×4)。
第四,将全分辨率的内容图像C送入指导图辅助网络,以获得指导图g∈R^(h×w),并利用指导图g对双边网格进行上采样:
第五,对内容图像应用仿生变换。A_x,y可以分成一个颜色映射矩阵Am_x,y∈R^(3×3)和一个颜色偏置Ab_x,y∈R^(3×1),颜色仿射变换可以写为:
CBST的损失函数,提出了Mask loss,以防止重要语义信息的改变:
CBST的总损失函数为:
其中L_c是内容损失,L_sa是风格损失,L_r是双边空间拉普拉斯正则器,这与BST相同。在实验中设置了超参数l_c=0.5、l_sa=1、l_r=0.015、l_mask=1。
(2)域混合(DMX)
CBST可以实现图像层面的数据增强,但在数据集提供的源域中,域的多样性仍然有限。为了进一步丰富域的多样性,可以通过在特征层面上的采样来获得数据集以外的更多域的多样性。通过CBST,可以得到原始图像I1和其对应的生成图像I2。在骨干中,I1和I2的潜在特征包含领域信息和语义信息。由于I1和I2的ground truth相同,它们的潜伏语义信息也相同,而不相关的领域信息则不同。如果I1和I2的潜在特征被内插,语义信息不变,而领域信息被内插。由于域流形在潜伏空间中比在输入空间中更加扁平,线性插值可以在域凸包内产生新的域。
详细来说,假设特征包含两部分:领域不变量特征和特定领域特征,它们被描述成:
其中F_d表示领域不变的特征,F_s表示领域特定的特征。F、F_d、F_s∈R^(H×W×C)。当水下环境发生变化时(光线变化、水质变化等),只有F_d发生变化而F_s保持不变。因此,在理想状态下,F_s足以让探测器做出正确的预测。当对两对特征进行Mixup时:
两个成对的特征具有相同的领域不变的特征。因此,语义信息是不变的,而领域信息是插值的。在实施过程中,考虑到K=[k1, k2, …, kn]是要进行Mixup的骨干层的选择。I1和I2同时被送入主干网(主流和副流)。两个流共享相同的参数。副流的特征被用来增强主流的特征。在主流中,第k层的潜在特征可以表示为:
梯度通过主流和副流进行反向传播。域混合后的特征(第k层的h_(1,k))被用于主流并被送入检测头。
(3)空间选择性边际对角线损失
给定两幅在不同领域具有相同语义内容的图像,可以假设骨干提取的隐藏特征是相同的。利用对比学习的思想来设计空间选择性边缘对比损失(SSMC损失)。详细来说,给定原始图像I1和其对应的图像I2,空间对比损失(SC Loss)可以计算为:
然而,过于约束的正则化可能会对检测器的判别能力产生不利影响。为了解决这个问题,提出了两个解决方案。首先,选择变化较大的像素进行正则化。因此,提出了空间选择性对比损失(SSC损失):
kMaxpooling定义为:
其次,空间选择性边际对比损失(SSMC损失)的设计是为了使空间方差的期望值位于指定的边际d内,而不是接近于零
所提出的SSMC损失可以使特定领域的像素正规化,但允许保留网络的辨别能力的空间。图3显示了SSMC的流程。总之,提出的方法的总损失函数可以计算为:
图3 SSMC损失示意图
实验分析
(1)领域泛化实验设置
DMCL被应用于YOLOv3和带有FPN的Faster R-CNN,它们分别是广泛使用的一阶段检测器和两阶段检测器。两个模型都是在Nvidia GTX 1080Ti GPU上进行训练,并采用PyTorch实现。模型在SUODAC2020训练集(类型1-6)上训练,并在SUODAC2020测试集(类型7)上评估。对于YOLOv3,训练了100个epochs,批次大小为8。采用Adam进行优化,学习率设置为0.001,β1=0.9,β2=0.999。采用多尺度训练。IoU、置信度和NMS阈值分别设置为0.5、0.02和0.5。训练过程中采用累积梯度(每2次迭代)。对来自DarkNet第36、46、55和71层的特征进行混合处理。SSMC损失被应用在DarkNet的第71层。对于Faster R-CNN,对其进行了24个epochs的训练,批次大小为4。采用SGD进行优化,学习率、动力和权重衰减分别设置为0.02、0.9和0.0001。IoU、置信度和NMS阈值分别设置为0.5、0.05和0.5。对ResNet-50的最后三个阶段的特征进行混合。SSMC损失被应用于ResNet的最后阶段。除了水平翻转,其他的数据增强方法都没有使用。
CCSA、MMD-AAE和CIDDG只在R-CNN头的Faster RCNN上实现,在这里检测任务变成了实例分类。在表1中,可以得出结论,提出的方法在YOLOv3(53.34%)和Faster R-CNN(61.36%)中都取得了最高的性能,在YOLOv3(45.34%)和Faster R-CNN(53.87%)中都高于DANN。
表1 不同领域泛化方法的性能
表2显示了训练成本和模型复杂性的比较。为了公平比较,所有的方法都是在Faster R-CNN + FPN + R50框架下实现的。表1中比较的所有DG方法只改变了Faster R-CNN和YOLO的训练范式,并没有修改其原始结构。因此,它们的参数都是一样的。此外,它们的Gflops和FPS与它们的输入大小有关。至于训练成本,DMCL的训练时间与DeepAll、DANN、CCSA和CIDDG相似。更重要的是,与其他方法相比,DMCL花费的内存最少。
表2 不同领域泛化方法的训练成本和模型复杂性
消融研究的结果显示在表3中。如果随机选择源图像和CBST生成的图像进行训练(“Only CBST”),与DeepAll(48.86%)相比,性能急剧增加到58.17%。此外,加入DMX(“CBST + DMX”)进一步提高了性能,达到60.32%,而在输入水平上进行域混合(“DMX_IN”)则将性能降低到54.23%。这证明了潜伏特征空间更加扁平化,因此通过在特征层面上的插值来合成新的域更加合理。此外,在随机选择的层(“CBST + DMX*”)中,在特征层面上的Mixup得到59.30%的mAP,不能达到与“CBST + DMX”相同的性能。与“CBST + DMX”相比,使用Mixup之前的特征进行检测(“Output Before Mixup”)的性能增加不多(58.67%)。还有一种反向传播方式,即只通过Main Stream进行梯度反向传播(“Detach Mixup”)。“Detach Mixup”的性能几乎等同于 “CBST + DMX”,即60.26%。
表3 消融研究
(2)实时风格转移模型的实验
与其他三个实时风格的转移模型做了比较:AdaIN, MST, 和BST。CBST是在Nvidia GTX 1080Ti GPU上训练的,并采用PyTorch实现。用作内容图像的训练数据集是UODAC2020训练集。从S-UODAC2020数据集中的每个源域中随机选择一张图像作为风格图像,这意味着6张固定的风格图像被用于训练。训练后的模型在UODAC2020验证集上得到验证。训练和推理中的输入大小都是512×512。采用Adam进行优化,学习率设置为0.001,β1=0.9,β2=0.999。CBST训练了10个epochs,批次大小为8。对于MST,其训练细节与BST相同。由于AdaIN是开源的,其预训练的模型参数可以直接使用。BST尚未开源,所以在与CBST相同的训练设置下重新实现它,只是S-UODAC2020数据集中的图像被随机选择为风格图像。
图4 提出的方法与三种最先进基线的定性比较
定性比较见图4。AdaIN合成的图像过于风格化,不符合照片的真实性。MST模糊了物体,这可能限制了检测的性能。BST甚至改变了图像的内容,这可能是因为BST需要一个大的数据集和更多的时间来训练。使用CIN而不是AdaIN有助于快速收敛,使用Mask loss有助于保护图像的重要语义信息不受本质的改变。因此,CBST生成了语义内容得到很好保护的清晰图像。此外,从表4中可以看出,当这些风格转换模型被应用于Faster R-CNN的训练时,CBST获得了最高的性能,这与定性比较是一致的,而且它也达到了最快的速度。
表4 512×512图像的速度比较(FPS)和用于在线数据增强时的性能比较
(3)t-SNE的可视化
利用t-SNE投影来可视化特征分布。随机选择300张源域的图像和100张目标域的图像,用不同方法输入Faster R-CNN。ResNet50最后阶段的特征被投影在二维平面上(图5)。蓝点表示来自源域的数据,而红点表示来自目标域的数据。如果红点与蓝点很好地合并,模型就能捕捉到更多的领域不变的特征。从图5中的子图可以很快得出结论,提出的方法消除了域转移的影响,而其他方法在某种程度上捕捉到了虚假的相关性。
图5 不同方法的t-SNE可视化
(4)特征统计的分析
归一化参数(γ, β)和风格之间存在一些联系,这可以解释为模型的特征统计与领域有关。每层的特征图可以被视为服从高斯分布的数据,具有特定的均值和方差。在一个领域不变量模型中,来自不同领域的特征分布将相互接近,这意味着它们在不同领域将有相似的均值和方差。图6显示了特征的统计数据。从每个领域随机选择10张图像,输入YOLOv3,从第12层到第58层提取特征。在图11(a-b)中,X轴表示层指数,左边部分表示特征的平均值,右边部分表示特征的方差。
图6 特征统计的可视化
总结
这篇文章介绍了一种新颖的水下目标检测的域泛化方法,它能够在不同的水下环境中实现高效的目标检测。文章的核心思想是利用风格迁移模型、域混合和对比学习,来增强模型的域多样性和域不变性。文章还提供了一个水下目标检测的域泛化基准数据集,用于评估和比较不同的域泛化方法。文章的实验结果表明,所提出的方法在水下目标检测和物体识别的域泛化任务上都取得了优异的性能,超越了其他的域泛化方法。这篇文章对于水下目标检测的研究和应用具有重要的意义和价值。
END
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh