Hyperparameters and Baseline Experiments in Dialog Systems
2024-1-17 18:0:2 Author: hackernoon.com(查看原文) 阅读量:15 收藏
2024-1-17 18:0:2 Author: hackernoon.com(查看原文) 阅读量:15 收藏
Too Long; Didn't Read
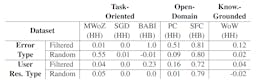
Baseline experiments in dialog systems unfold with key hyperparameter settings. Models trained for five epochs, extended to ten for erroneous dialogs, featured a batch size of 32, learning rate of 5e − 5, and AdamW optimizer. LLAMA adopted unique finetuning parameters. Results, reflected in Table 17, elucidate the interplay of data quality, system errors, and model performance through F1-Score and BLEU metrics.

@feedbackloop
The FeedbackLoop: #1 in PM Education
The FeedbackLoop offers premium product management education, research papers, and certifications. Start building today!
Receive Stories from @feedbackloop


RELATED STORIES





L O A D I N G
. . . comments & more!
文章来源: https://hackernoon.com/hyperparameters-and-baseline-experiments-in-dialog-systems?source=rss
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh