Introduction to the Universe of Kafka: A Detailed SynopsisApache Kafka, frequently just labe 2024-1-15 17:34:1 Author: lab.wallarm.com(查看原文) 阅读量:91 收藏
Introduction to the Universe of Kafka: A Detailed Synopsis

Apache Kafka, frequently just labeled as Kafka, is a universally contributed event broadcasting framework, intended to manage live streaming of data. It is engineered to be a bridge for significant volumes of data, offering a mechanism for maneuvering live streams of data events. At its core, Kafka is a powerhouse that marries data generators with end-users via a robust, resilient, and long-lasting platform.
Kafka was an original brainchild of LinkedIn, and later gifted to the Apache Software Foundation. It was built with the principle of managing live data streams while ensuring high-volume data transfer and minimum delay. Kafka was coded in Scala and Java, with an emphasis on speed, scalability, and longevity.
<code class="language-java">import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; // Set up the configuration map for the Kafka Producer Properties settings = new Properties(); settings.put("bootstrap.servers", "localhost:9092"); settings.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); settings.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // Initiate a new Kafka Producer with the given settings KafkaProducer<String, String> producer = new KafkaProducer<>(settings); // Generate a new Producer Record for a designated topic ProducerRecord<String, String> narrative = new ProducerRecord<>("my-topic", "my-key", "my-value"); // Transmit the narrative to the Kafka stocker producer.send(narrative); // Shut down the Kafka Producer producer.close();</code>
This enclosed code piece is an uncomplicated demonstration of how a Kafka producer can be instituted in Java. The producer transfers narratives, constituted of key-value pairs, to a Kafka stocker. The stocker, in turn, preserves these narratives till they are consumed by a Kafka end-user.
Kafka is structured around the idea of themes. A theme is nothing but a label or feed name to which narratives are contributed. Kafka themes are always available for multicasting, that is, a theme can have none, one, or multiple consumers paying attention to the data poured in.
Here is a straightforward contrast table to elaborate on how Kafka stands apart from conventional messaging mechanisms:
| Trait | Conventional Messaging Mechanism | Kafka |
|---|---|---|
| Data Preservation | Generally, when a message is used, it's wiped from the queue. | Data is reserved for a predefined duration, regardless of its consumption status. |
| Data Transfer Rate | Confined by the velocity of the end-users. | Built for superior data transfer rate. |
| End-users | Conventionally, every message can be used just by a single end-user. | It enables multiple end-users to access the same data. |
In the next segments, we'll dive deeper into Kafka's technology, its handling of messages, the real-time processing advantages it offers, and how it fuels high-transfer-rate systems. We'll also discover the benefits of choosing Kafka beyond traditional message exchange, and what should be your subsequent maneuvers post understanding Kafka.
Unraveling Kafka: An Exhaustive Exploration of the Inner Workings Powering its Streams
Proudly bearing the name Kafka, this innovative software platform engages as a distributed system developed distinctively for monitoring and managing the flow of data in real-time. It's an offspring of open-source coding, armed with a robust architectural framework skilled in the management of colossal quantities of event-driven data per time segment. Thus, it’s interesting to dip behind the scenes to unravel the essence of Kafka’s existence and get a grasp on the inner mechanisms contributing to its operational effectiveness.
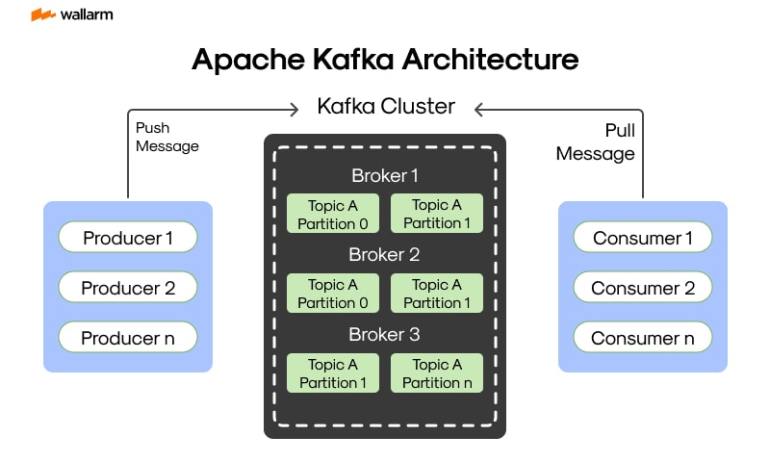
At the heart of Kafka’s operations, three core facets dominate: themes or 'topics', data generators or 'producers', and 'consumers'. In the Kafka vernacular, a 'topic' manifests as a preserve where records reside. These 'producers', as the name implies, serve as the initiators, injecting data into these topics while consumers extract and employ the data derived from these specific topics. Kafka's system runs in networked groups that span across singular or multiple servers. Embedded inside these Kafka formations, one can identify organized sequences of records, categorized into discrete 'topics'.
Let's visualize a Kafka producer-consumer scenario that resonates with user-friendliness:
<code class="language-java">// Working within a Kafka generator
Producer<String, String> producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("our-topic", Integer.toString(i), Integer.toString(i)));
// Operating within a Kafka consumer
Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("our-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}</code>
In the scenario above, the producer dispenses 100 messages to "our-topic", and the consumer subsequently recovers them from its corresponding topic.
Outstanding streaming prowess of Kafka plants its roots in this fundamental trifecta of producers, topics, and consumers. Kafka Streams positions itself as a versatile client-side library, enabling the creation of applications and micro-services. Within this picture, all data transactions occur within the confines of Kafka clusters. It intertwines the ease of developing and managing ordinary Java and Scala applications on the frontend with the advantages drawn from Kafka's backend cluster-mastery.
Here is a straightforward representation of an application capitalizing on Kafka Streams:
<code class="language-java">StreamsBuilder architect = new StreamsBuilder();
KStream<String, String> textualLines = architect.stream("TextLinesSubject");
KTable<String, Long> wordTally = textualLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count(Materialized.as("counts-store"));
wordTally.toStream().to("WordsWithCountsSubject", Produced.with(Serdes.String(), Serdes.Long()));</code>
In this instance, it ingests data from the "TextLinesSubject", processes it, and finally ushers the processed output into the "WordsWithCountsSubject".
Capitalizing on Kafka’s versatile and dynamic stream technology sanctions processing and evaluating data in a real-time milieu. With its purpose embodied in various applications like consolidating logs, processing streams, tracing origin of events, and maintenance of commit logs, it serves various uses.
Kafka establishes itself as a potent tool for navigating the maze of real-time data flows. Its unique architectural design guarantees rapid data transmission rates and near-zero latency, making it an optimum choice for handling large-scale data operations. Deciphering the core technology that fuels Kafka’s streams is seminal in exploiting its full capabilities.
`
`
Decoding Kafka: Your Ultimate Guide to Handling Messages
Primarily understood as a platform that facilitates distributed event streaming, Apache Kafka is essentially an open-source system built to manage data in real-time. This system, noteworthy for being highly resilient and adaptable, boasts an impressive ability to process a multitude of messages every second. But why is Kafka considered the preferred choice for managing messages? Let’s dig into its details.
1. Decoding Kafka's Framework
At the heart of Kafka’s framework rests the notion of a “log," defined as a persistent, totally ordered sequence of records, accessible for appending only. Each entry in the log can be recognized by a distinct offset. Producers push novel records to the log's terminal, and consumers extract records in the sequential order they were placed. This ingenious yet straightforward design enables Kafka to ensure swift and efficient message management.
<code class="language-java"> // Producers' API
ProducerRecord<String, String> entry_content = new ProducerRecord<>("topic", "key", "value");
producer.publish(entry_content);
// Consumers' API
ConsumerRecords<String, String> entries = consumer.fetch(Duration.ofMillis(100));
for (ConsumerRecord<String, String> entry_content : entries) {
System.out.printf("Offset = %d, Key = %s, Value = %s%n", entry_content.offset(), entry_content.key(), entry_content.value());
}</code>
2. Subject and Segments
Kafka categorizes messages into subjects. Each subject can be segmented, forming multiple, orderly, static streams of records, commonly addressed as segments. This segmentation enables Kafka to relay data across an array of nodes, consequently augmenting throughput.
| Theme | Segment | Offset | Bulletin |
|---|---|---|---|
| Theme1 | 0 | 0 | Msg1 |
| Theme1 | 0 | 1 | Msg2 |
| Theme1 | 1 | 0 | Msg3 |
| Theme1 | 1 | 1 | Msg4 |
3. Creator and Reader
Creators generate fresh messages and append them to a specific subject terminal. In contrast, readers retrieve from a designated subject at their leisure, maintaining a record of the last message offset they consumed. This mechanism permits numerous readers to simultaneously read from an identical subject without causing any disruption.
<code class="language-java"> // Creator
creator.publish(new ProducerRecord<>("topic", "key", "value"));
// Reader
reader.follow(Arrays.asList("topic"));</code>
4. Agent and Collective
A Kafka collective comprises multiple agents. Every agent is an independent server responsible for managing the storage of numerous segments. Upon a creator sending a message to a subject, the agent verifies the message to be duplicated across various segments, ensuring resiliency.
<code class="language-bash"> # Kick-off a Kafka agent bin/kafka-server-initiate.sh config/server.properties</code>
5. Reduplication and Resiliency
Kafka safeguards data permanence and system resiliency via reduplication. Each segment within Kafka can be duplicated across a multitude of agents. Consequently, even if a single agent falters, the data persists on the other agents.
<code class="language-bash"> # Generate a theme with reduplication measure 3 bin/kafka-themes.sh --generate --bootstrap-server localhost:9092 --reduplication-factor 3 --segments 1 --theme my-reduplicated-theme</code>
Wrapping up, Kafka's unparalleled framework and foundational principles position it as a formidable resource for managing real-time data streams. Regardless of whether you're tasked with logs combination, stream management, or on-the-spot analytics, Kafka presents a sturdy, scalable solution.
An Insight Into Kafka: Unravel Its Strengths & Practical Implementations

Kafka is carving a niche for itself in the realm of dynamic data administration as a formidable instrument. At its core, it functions as a decentralized message transmission scheme, adept at dealing with copious operations continuously. We will delve into the chief merits and diverse utility of Kafka in the context of real-time data manipulation.
A. Expedited Computation & Negligible Delays
Kafka was conceived with the objective of agile administration and rapid dispatch of significant data portions instantaneously. It possesses the ability to facilitate countless dialogues within seconds, curtailing the lags to least possible extent, thereby underscoring its role in on-the-spot data computation.
<code class="language-java">Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("acks", "all");
properties.put("delivery.timeout.ms", 30000);
properties.put("batch.size", 16384);
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(properties);
for(int index = 0; index < 100; index++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(index), Integer.toString(index)));
producer.close();</code>
The preceding code represents the configuration of a Kafka producer in Java, enabling comprehensive broadcast of messages to a Kafka theme.
B. Superior Scalability
Kafka excels in expandability. It permits unhampered augmentation of your Kafka setup by appending additional nodes, effectively escalating its potential to accommodate numerous participants and archive more data, all without risking operational disruption.
C. Accuracy & Trustworthiness of Information
Kafka conserves and duplicates data within its ecosystem to prevent any information loss. Its robust framework guarantees the preservation of messages for the pertinent period, even during hardware malfunction.
D. Live Functionalities
Kafka’s proficiency in immediate data computation renders it an ideal instrument for real-time data surveillance, acquisition, and inspection. Its live functionalities encompass monitoring web interactions, authenticating IoT sensor data, among other tasks.
E. Harmonious Operation with Extensive Data Technologies
Kafka seamlessly integrates with prevalent extensive data mechanisms like Hadoop, Spark, and Storm. The result is a versatile instrument for administering and interpreting sizeable data volumes without delay.
| Kafka | Conventional Messaging Platforms |
|---|---|
| Exceptional Velocity | Restricted Speed |
| Minimal Lag | Increased Delay |
| Expandable | Scalability Challenges |
| Reliable & Long-lasting | Diminished reliability |
| Facilitates Real-time Apps | Batch Processing Only |
| Synchronizes with Big Data Tech | Limited Scope for Integration |
Kafka’s attributes as demonstrated in the comparison chart above, position it superior to conventional messaging platforms.
Conclusively, Kafka, armed with unrivaled speed, minimum holdup, extensibility, dependability, and command in handling immediate data, emerges as an indispensable aid for instantaneous data computation. Whether it’s scrutinizing user actions on a website or examining data from IoT devices, Kafka is aptly equipped for the task. This understanding will empower you to inform anyone inquisitive about Kafka, by shedding light on its strengths and broad applications in real-time data administration.
Plumbing the Depths: The Mechanisms Behind Kafka's High-Traffic Support
Apache Kafka, a dynamic broadcast technology, is a vital tool when it comes to managing high traffic operations. It's crafted to accommodate quick, real-time data transfer with minimal lag time. But what's the science behind how Kafka accomplishes this? Let's thoroughly explore the intricate design of Kafka to grasp its high-traffic handling potential.
1. The Fabric of Kafka: Constitutes High Traffic Support
The structural makeup of Kafka is optimally designed to process tons of data while enabling rapid data transmission. It employs a distributed model that apportions data among several nodes or servers. This capacity permits it to manage colossal data flows.
Symbolically, here's the basic blueprint of Kafka's fabric:
<code>Data Origin --> Kafka Cluster (Subject (Subdivision1, Subdivision2, ...)) --> Data Recipient</code>
Here, the data origin dispatches data towards the Kafka system, which is subsequently consumed by the data recipient. The information is segmented across multiple subdivisions within a subject, allowing several recipients to access the data concurrently, enhancing the traffic handling capability.
2. Message Pooling: Kafka's Blueprint for High Traffic
A prominent feature that amplifies Kafka's high traffic handling capability is message pooling. Kafka combines various messages into a bunch that can be managed as a singular entity. This strategy drastically diminishes network overload and amplifies the processing speed of messages.
Here's a straightforward code demonstration of how Kafka's message pooling can be set:
<code class="language-java">Properties params = new Properties(); params.put("batch.size", 16384); // The data origin will strive to bundle together records into lesser requests when several records are directed towards the same subdivision. params.put("linger.ms", 1); // This setting introduces a minute intentional delay, enabling the producer to wait for the specified period, allowing additional message records to be pooled together before dispatch. Producer<String, String> producer = new KafkaProducer<>(params);</code>
3. Data Retention and Duplication: Promoting Data Security
Kafka guarantees data retention via its duplication facet. It mirrors each subdivision across several nodes, ensuring that even if a node crashes, the lost data can be retrieved from a backup node. This not only promotes data security but also enables recipients to access data from several nodes, hence improving traffic handling.
Here's the code demonstrating how duplication can be established in Kafka:
<code class="language-java">Properties params = new Properties(); params.put("replication.factor", 3); // This will spawn 3 copies of each subdivision within the Kafka cluster. Producer<String, String> producer = new KafkaProducer<>(params);</code>
4. Disk Input/Output Efficiency: Kafka's Strategy for Storage
All data in Kafka is conserved on the disk. Kafka employs a singular strategy to optimize disk storage — storing messages in a log structure that only permits adding new entries, allowing Kafka to write data sequentially on the disk. This sequential writing operation outperforms random writing in speed and enables Kafka to achieve high disk input/output traffic.
5. Direct Transfer Method: Powers Kafka's Functioning
To transfer data directly from the file system cache to the network socket, bypassing the software's buffer, Kafka uses a method identified as "direct transfer." This approach reduces CPU load and enhances the rate at which data is transferred, thereby improving Kafka's functioning.
In summary, multiple factors such as Kafka's structural design, message pooling, data retention, disk input/output efficiency, and direct transfer method collectively contribute to its capacity to bolster high-traffic operations. Gaining a thorough understanding of these underlying mechanisms can help you to more effectively harness Kafka's abilities in your data-intensive applications.
Beyond Traditional Messaging: The Advantage of Utilizing Kafka
In the sphere of information handling, usual messaging arrangements stood as pillars for a long time. Nevertheless, faced with an astronomical increase in data, these systems faltered trying to maintain pace. The entry of Apache Kafka in this space revolutionised it by providing a powerful and expandable alternative way ahead of customary messaging. Let's scrutinize in-depth to find out what raises Kafka above its competitors.
Born at LinkedIn and later contributed to the open-source community in 2011, Apache Kafka is a decentralized data streaming framework crafted to supervise real-time data streams with outstanding throughput and negligible latency. Mainly, Kafka is used to create instantaneous data streaming pipelines that can effortlessly manage billions of events every day.
Setting itself apart from its predecessors, Kafka works on a model based on publisher-subscriber. This means, entities generating data publish messages to specific topics, and the entities consuming this data subscribe to these topics to get the messages. This scheme ensures enhanced scalability and resistance to failure, making Kafka a suitable contender for extensive data processing tasks.
Let's focus on the primary benefits of opting Kafka over regular messaging systems:
1. Exceptional Throughput: Kafka is engineered to process enormous amounts of data instantaneously. Capable of addressing millions of messages every second, it is an ideal match for large data applications.
<code class="language-java">// Constituting a Kafka Producer Properties settings = new Properties(); settings.put("bootstrap.servers", "localhost:9092"); settings.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); settings.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<>(settings);</code>
2. Scalability: Besides being extremely scalable, Kafka allows for easy augmentation of its capacity by adding more nodes to the existing Kafka cluster. Thus, it's a preferable option for applications with demands growing parallely with your enterprise.
3. Fault Tolerance: Creating replicas of data across different nodes, Kafka ensures data reliability and accessibility, even during node failures.
4. Real-Time Processing: Supporting instantaneous data processing, Kafka paves the way to examine and act on data as it arrives.
<code class="language-java">// Constituting a Kafka Consumer Properties settings = new Properties(); settings.put("bootstrap.servers", "localhost:9092"); settings.put("group.id", "test"); settings.put("key.deserializer", "org.apache.kafka.common.serialization.StringSerializer"); settings.put("value.deserializer", "org.apache.kafka.common.serialization.StringSerializer"); Consumer<String, String> consumer = new KafkaConsumer<>(settings);</code>
5. Durability: By storing data on disk and creating replicas across varied nodes, Kafka assures the safety and durability of your data.
6. Integration: With Kafka, incorporating diverse large data tools like Hadoop, Spark and Storm is straightforward, making it a flexible solution for data processing tasks.
All things considered, Kafka offers stable, expandable and high-performing results for instantaneous data handling. This platform supersedes traditional messaging systems, offering characteristics such as exceptional throughput, failure resistance, and real-time processing. Whether your need is large data applications or just a dependable messaging system, Kafka is a commendable choice.
In the next chapter, we will examine how Kafka enables high-throughput systems further. Stay engaged!
`
`
Closing the Chapter: Next Steps After Understanding Kafka
As we conclude our discussion on the multifaceted Kafka, a platform offering a unique blend of technology perks and practical benefits, it's time to chart the path forward. Acknowledging Kafka and all it embodies merely forms the kickoff of your odyssey. The thrill-inducing pivot comes when you amalgamate Kafka into your contemporaneous data handling frameworks.
1. Apply Kafka into Your Operational Framework
The leap following the comprehension of Kafka revolves around incorporating Kafka into your current processes. Kafka, a highly adaptable toolkit, serves various needs ranging from concurrent data analysis to integrating architectures propelled by events. Here's a basic representation of generating and consuming notes with the aid of Kafka:
<code class="language-java">// Message Source
Properties options = new Properties();
options.put("bootstrap.machines", "localmachine:9092");
options.put("main.serializer", "org.apache.kafka.common.serialization.StringSerializer");
options.put("auxiliary.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> source = new KafkaProducer<>(options);
source.send(new ProducerRecord<String, String>("my-domain", "principal", "data"));
// Message Receiver
Properties options = new Properties();
options.put("bootstrap.machines", "localmachine:9092");
options.put("group.identification", "experimental");
options.put("main.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
options.put("auxiliary.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Consumer<String, String> receiver = new KafkaConsumer<>(options);
receiver.subscribe(Arrays.asList("my-domain"));
while (true) {
ConsumerRecords<String, String> documents = receiver.fetch(100);
for (ConsumerRecord<String, String> document : documents)
System.out.printf("displacement = %d, principal = %s, data = %s%n", document.displacement(), document.principal(), document.data());
}</code>
2. Uncover Kafka's Advanced Capabilities
Kafka extends beyond being a device for messages. It incorporates forward-thinking attributes such as logs compacting and handling streams. Log condensation confirms that Kafka maintains, at minimum, the most recent record for each message’s main in the data log linked to a singular domain partition. This characteristic is key for scenarios demanding system restoration by drawing on Kafka.
Kafka Streams represents a client library geared towards formulating solutions and microservices, within which the input-output data exist in Kafka batches. It interweaves the ease of crafting and implementing standard Java and Scala functions on the client-side with Kafka's dynamic cluster technology on the server-side.
3. Participate in Kafka’s Diverse Network
Kafka’s dynamic community is always eager to welcome newcomers and assist in their discovery journey. By becoming a part of the community, you gain access to invaluable knowledge and expertise to tackle any Kafka-related issues. You can get started by subscribing to Kafka's mailing service, attending Kafka's annual conference, or contributing to the Kafka repository on GitHub.
4. Remain In Sync with Kafka's Progress
As an open-source venture, Kafka is consistently updated, improving and evolving over time. Each iteration introduces new features, rectifies glitches, and enhances performance. Hence, staying up-to-date with Kafka's evolution is critical for making the most of its benefits.
To sum up, familiarizing yourself with Kafka is essential to truly unlocking its potential. The subsequent steps encompass using Kafka in your operations, uncovering its intricate attributes, becoming a part of the Kafka network, and staying informed about its continual transformation. With characteristics like immense processing capacity, resistance to errors, and real-time data processing, Kafka is a formidable component capable of a significant boost to your data handling frameworks.
如有侵权请联系:admin#unsafe.sh