
In this blog post, we will go over a technique called Google Dorking and demonstrate how it can 2024-1-22 16:0:0 Author: blog.nviso.eu(查看原文) 阅读量:44 收藏
In this blog post, we will go over a technique called Google Dorking and demonstrate how it can be utilized to uncover severe security vulnerabilities in web applications hosted right here in Belgium, where NVISO was founded. The inspiration for this security research arose from the observation that many large organizations have fallen victim to severe security breaches, with the perpetrators often being individuals under the age of 18. A recent incident involved an 18-year-old hacker who managed to infiltrate Rockstar Games using just a hotel TV, a cellphone, and an Amazon Fire Stick while under police protection. This can be caused by two possibilities: either these young cybercriminals possess exceptional talent and skills, which we are certain of, and/or the importance of cybersecurity is not being sufficiently prioritized yet by many organizations.
In 2020, Belgium was ranked first on the National Cyber Security Index (NCSI), which measures the preparedness of countries to prevent cyber threats and manage cyber incidents. As Belgium was leading this ranking, my curiosity was triggered regarding the security of Belgium’s digital landscape.
For the purpose of the security research, I will adopt the role of a ‘script kiddie’ – individuals using existing scripts or programs to exploit computer systems, often without a deep understanding of the underlying technology. Furthermore, I will restrict myself to solely using the Google search bar to identify the vulnerabilities without utilizing any tool that could potentially automate certain tasks.
Hacking the digital infrastructure of companies prior their consent is illegal. However, Belgium has published a new Coordinated Vulnerability Disclosure Policy, which allows citizens with good intentions to identify possible vulnerabilities and report to the affected company within a 72-hour window. This is not the sole prerequisite to identify vulnerabilities within Belgium companies. Additional details about the policy can be found on the website of the Centre for Cybersecurity Belgium (CCB) .
All the vulnerabilities identified during the security research have been appropriately reported to the affected companies and Belgium’s national CSIRT team.
Introduction
The vulnerabilities identified during the security research were not being exploited, as it is still prohibited by the newly published framework to perform such actions. The objective was to verify the existence of a vulnerability, not to examine the extent to which one can penetrate a system, process, or control. Therefore, the identification of vulnerabilities was based on proof-of-concepts or explanations to the organizations about the potential implications of the vulnerabilities. Below is a short list of vulnerabilities identified during the security research, using only the Google search bar on the web applications of Belgian corporations:
- Remote code execution (RCE)
- Local file inclusion (LFI)
- Reflected cross-site scripting (XSS)
- SQL injection
- Broken Access Control
- Sensitive information disclosure
What is Google Dorking?
The technique Google Dorking is also referred to as Google hacking, which is a method used by security researchers and cybercriminals to exploit the power of the Google search engine to unearth vulnerabilities on the Internet.
In essence, the Google search engine functions like a translator, deciphering search strings and operators to deliver the most relevant results to the end user. A couple of examples of Google operators are as follow:
- site: This operator restricts the search results to a specific website or domain. For example, “site:nviso.eu” would return results only from the NVISO website.

- inurl: This operator searches for a specific text within the URL of a website. For example, “inurl:login” would return results for web pages that have “login” in their URL.

Google search bar in action
During the research, I developed a methodology and used my creativity to identify numerous high to critical security issues, none of which relied on online resources, such as the Google Hacking Database. However, we will not share any of the actual Google dork queries or the methodology behind them that were used to identify vulnerabilities. Doing so would pose a significant security risk to many Belgian corporations. Moreover, we are committed to making our digital landscape safer, not to teaching someone with bad intentions how to learn and infiltrate these corporations. Therefore, we will discuss each identified specific vulnerability in more depth, the approaches of cybercriminals, and, most importantly, how to fix or remediate such issues.
Default credentials
Description
Default credentials are pre-configured credentials provided by many manufacturers for initial access to software applications. The objective is to simplify the setup process for users who are configuring the application for the first time. However, since these credentials are often common knowledge, they are publicly available and easily found in user manuals or online documentation. As a result, the usage of default credentials can still lead to severe security incidents as they grant highly privileged access to management interfaces. Further, this issue can arise in occasions where a system administrator or developer does not change the default credentials which are provided during the initial setup of the management interface. Therefore, an attacker can easily guess those credentials if not changed and gain access to the management portal.
Approach
The first step for an attacker is to target a specific CRM, CMS, or any other widely-used management portal. This information can be easily obtained with a basic Google search. Upon identifying the target software, the attacker can use a combination of Google search operators to refine the search results to only display web applications hosting that specific management portal.
A lot of management portal software names are written in the title of the web application which is not a security issue at all. However, if an attacker identifies the software version in use on the web application, they can conduct more targeted reconnaissance activities against the web application. An example Google dork which can be found on the Google Hacking Database is as follow:
intitle: "Login - Jorani"The results of the Google search lists the web applications which have “Login – Jorani” within the title tag. This can also be verified by navigating to one of the web applications listed in the Google search results. As demonstrated below, the title of the web application contains the string used with the intitle operator:

Additionally, to reinforce the earlier statement about the publicly available information of default credentials, a simple Google search discloses the default credentials for the Jorani management software without even navigating to the documentation:

It can be noticed that by simply searching publicly available resources, an attacker can identify and perform targeted reconnaissance on web applications without performing any illegal or harmful actions. The steps taken so far are considered passive and non-malicious, which makes this approach even more interesting.
Real-world scenario
The usage of a single Google dork will, of course, not provide the most refined results to target a specific management portal application. However, the approach is the same; more advanced operators in combination have to be used in order to target very specific management portals. During my research, advanced operators were utilized to search for a popular management portal that also includes default credentials during its initial setup. This was, of course, based on my experience in the penetration testing field and creativity. Upon analyzing the Google search results, one company was identified as using default credentials for their management portal. Further, upon gaining access to the management portal, it can lead to the full compromise of the server hosting the web application.
As penetration testers conducting daily assessments of web applications, we can attest to the severity of the security issue and its potential consequences. Furthermore, adherence to a responsible disclosure policy entails demonstrating the vulnerability without expanding the scope of the research. The first identified vulnerability has raised significant concerns, particularly as the organization in question is a large Belgian company. In short, this vulnerability can allow an attacker to easily establish an initial foothold within the network of the affected organization.
Remediation
Management portals are not intended for daily users or even employees tasked with specific duties. Instead, they are most often accessed by users with administrative rights who manage certain aspects of the software. Therefore, it is not important for a management portal to rank highly in Google search results or for SEO optimization purposes.
To limit the access of robots and web crawlers to your site, you can add the following robots.txt file to the root directory of the web server hosting the management portal application:
User-agent: *
Disallow: /The robots.txt file is not a security threat in itself, nor is it a foolproof method to block robots and web crawlers from accessing your site. Many robots or web crawlers may not heed the file and simply bypass it. However, following this best practice can serve as part of a defense-in-depth strategy, helping to mitigate potential issues.
Next, as previously mentioned, many management portal applications include the software name and sometimes even the software version within the title tag or generator tag in the source code. While the presence of this information is not a security issue at all, it can make it more easier for attackers to identify the underlying software version and perform targeted reconnaissance.
Last but not least, the use of default credentials remains a common issue in many applications. The compromise of a web server will not be due to web crawlers indexing the endpoint of a management portal or the presence of a software name within the title tag. The root cause is the usage of default credentials on management portals. Since these portals also allow the performance of various tasks with high-level permissions, it is crucial to establish defined policies and conduct regular audits to prevent such simple yet critical misconfigurations.
Local File Inclusion (LFI)
Description
Local File Inclusion (LFI) is a type of vulnerability which allows attackers to include and potentially even execute local files on the server. An attacker exploiting an LFI can read sensitive files, such as configuration files, source code, or data files. However, the impact of this kind of a vulnerability is influenced by the permissions of the user account under which the web server is running. Moreover, a common misconfiguration arises when web servers are run with high-level privileges, such as root on Unix-based and SYSTEM on Windows-based systems. This could allow an attacker to access almost any file on the server and completely compromise the server.
Approach
The methodology for identifying LFI vulnerabilities using Google dork may not be as straightforward as identifying management portals. However, web applications often use common parameters to retrieve the contents of a local file. It is possible to search specifically for these common parameters, which are used for such purposes. Some of these commonly known parameters include “file,” “page,” and others. There are several Google search queries that can be used to search for the presence of these parameters in web applications. The following is an example of a Google dork:
The above shown Google dork query searches web applications with “file” in their URL. However, as you will notice, these search results will not refine to web applications containing parameters named “file” but will also include directories with the string “file.” During my research, I was able to use a combination of several Google search queries with specific key characters and special characters to refine the search results to web applications only with a “file” parameter in their URL.
Real-world scenario
As explained above, I developed a methodology that refines Google search results to identify web applications hosted in Belgium, which contain the specific parameters I was targeting. Using this methodology, I quickly identified a web server hosted in Belgium and retrieved a common local file present on Unix-based systems.
Remediation
To instruct web crawlers or robots not to index URLs with certain parameters, the “Disallow” directive can be used. A real-world example can be found below:
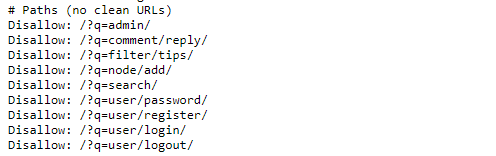
The “Disallow” directives in a robots.txt file instruct search engine crawlers not to index the specific paths provided. This helps to keep private or non-content pages out of search engine results and can also prevent the exposure of sensitive areas of the site to the public. Therefore, the steps to take include identifying those certain parameters within your web application and adding Disallow directives for those parameters in the robots.txt file.
Do note that depending on the structure of the web application, it might not be possible to create such Disallow entries, since those parameters are used in functionality that is by design intended to be public and should be included in search results.
However, once again, the root cause of the identified vulnerability, is not due the lack of a Disallow entry. Since, upon investigating the application, an attacker will be still be able to exploit the vulnerability. The only difference would be the ease of identifying the vulnerability just by a Google search.
Test environment externally accessible
Description
Test environments are a setup that closely mimics the production environment but is used exclusively for testing purposes. In the context of web development, test environments have different stages such as commonly called development, user acceptance testing (UAT), pre-production but at the end are not production environments and should be not publicly accessible. Since, test environments may not be secure as production environments with known vulnerabilities that have not been yet patched. Next, it might contain sensitive or real data for testing purposes. Those are just some examples of security issues that can arise when a test environment is publicly accessible.
Approach
Test environments are often hosted under a subdomain of the production web applications. However, the discovery of those subdomains can sometimes be time consuming and will require an attacker to brute-force the domain for the discovery. Besides I’m acting as a script kiddie and want to avoid the automation of certain tasks, the usage of artificial intelligence (AI) can even play a role. Below the question is shown to be asked to an AI Chatbot internally used by NVISO to fulfill my requirements for this task.

The AI Chatbot responded with several common subdomains which developers use to manage different environments for software development. With the information obtained above a Google Dork can be defined to search specifically for web servers containing those subdomains within the URL. An example Google dork can be found within the Google Hacking Database with the ID 5506:
The Google dork above is used to search for developers’ login pages across various locations. However, this operator may not be specific enough, potentially yielding results for web applications hosted worldwide. Additionally, my research into databases and other online resources did not reveal a straightforward Google dork for locating test environments of web applications. Consequently, it’s necessary to think outside the box and explore how to refine Google searches to specifically target test environments.
Real-world scenario
Successfully, my developed methodology, combined with the use of multiple advanced operators, enabled me to identify several vulnerabilities in the test environments of web applications hosted in Belgium.
Following, during the research several WordPress installations were found within a development environment that were improperly configured. Those misconfigurations allow an attacker to complete the installation of a WordPress instance and achieve remote code execution by uploading a malicious PHP file which is also a publicly available resource.
Second, a different Google dork was used to identify also a common subdomain for development environments and the results were once again eye-opening. A web server exposing the username of the administrator user and the hash of the password within a file.
Remediation
The remediation steps for test environments are quite straightforward. Only authorized users should have access, so a form of authentication should be configured, such as a VPN or a firewall. With this in place, the test environment will no longer be available to the Internet, and any potential attacks from outside the network will be eliminated with this approach.
Sensitive Information Disclosure
Description
The risk due to disclosure of unintended information in web applications can vary significantly based on the type of information disclosed to the public audience. These kinds of issues can occur unnoticed but can have a severe impact depending on the information disclosed. Some examples include plain-text credentials for login portals, databases, repositories, and much more.
Approach
The Google dork can also be utilized to search for specific strings. This functionality can be leveraged to search for sensitive strings or directories to discover potentially sensitive information on web servers.
Besides searching for sensitive strings or directories, directory listing on web servers can ease the reconnaissance phase for an attacker as it already shows all the available directories/files on the web server. For the sake of the research, searching for web servers with directory listing enabled in combination with key strings which can potentially indicate sensitive information can ease the discovery. An example Google dork can be found within the Google Hacking Database with the ID 8376:
The above search query is used to identify openly accessible directories that include the word ‘app.’ While a directory listing on a web server already presents a security issue, it does not necessarily mean that an attacker will immediately find sensitive information due to this issue.
During my research, this part was the most enjoyable because you’re never sure what you’ll come across, and you need to be as creative as possible since sensitive information could be disclosed anywhere on web servers.
Something I discovered after completing my security research was the potential for automation in identifying sensitive information, as this process can be time-consuming. What if this approach could be automated using artificial intelligence? For example, scraping web servers from the search results and then submitting the output to OpenAI’s ChatGPT to determine if the content contains sensitive information.
This approach can significantly automate certain tasks and give us the ability to discover those security issues quicker. However, as I’m performing the security research as a script kiddie with limited programming language ability, this is a side note how things can easily get abused. Therefore, we’ll make a proof-of-concept and submit a config file into ChatGPT and ask ChatGPT like an average user if the submitted content contains sensitive information.
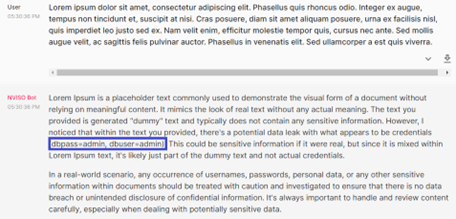
I generated 100 paragraphs of lorem ipsum and inserted the following within one of the paragraphs: `dbpass=admin, dbpass=admin` and asked if the above content contains sensitive information. As expected, ChatGPT notified this and reported to us.
Real-world scenario
Finally, during the research I found a lot of web servers exposing sensitive information such as, plain-text database credentials, plain-text credentials of login portals, web server configurations and even such issues which cannot be mentioned. However, I noticed that the combination of multiple operators can significantly increase the ability to discover sensitive information on web servers. Let’s say that we’re interested in finding all PDF documents within web servers with a TLD .de. Further, it’s common that organizations tag internal documents with a specified classification such as “Classification: Internal use only” or related. Therefore, the presence of a string which can potentially indicate sensitivity within the document can also be used. To wrap up all the above mentioned operators, we’ll get something like below search query:
site:XX intext:XX AND intext:XX ext:XXThe above search query was invented while writing the blog post to avoid revealing the query I originally used to identify the vulnerability. Nevertheless, I still obtained a document that satisfied those results, which could lead to another potential security issue. Moreover, since Germany does not have such a CDVP (Common Vulnerability Disclosure Policy), I did not access the document or check its content. However, the Google search result already revealed enough information.
Remediation
Once again, since sensitive information can be disclosed anywhere in an application and can vary significantly based on the type of information disclosed, there is unfortunately no straightforward way to address all these issues. Therefore, we should adopt a proactive approach and handle these issues with several actions, such as regular security audits or penetration tests. However, even with these assessments, it is possible that some issues may not be identified due to scope limitations. Consequently, a targeted online footprint analysis assessment can be conducted by your professionals if they possess the necessary skills, or hiring a third-party provider.
Reflected Cross-site Scripting
Description
Cross-Site Scripting is a type of vulnerability that allows attackers to inject malicious JavaScript code into web applications. This code is then executed in the user’s browser when the application reflects or stores the injected scripts. In the case of a reflected XSS, the attack is often delivered to the victim via a link from the trusted domain. Once the victim clicks on the link, the web application processes the request and includes the malicious script in the response executing it in the user’s browser. Moreover, the gravity of such an attack is increased if the compromised web application is hosted under a popular trusted domain which convince the users more likely to click on the malicious link.
Approach
The methodology in order to identify XSS vulnerabilities is akin to that used for identifying LFI vulnerabilities though the use of Google dork. The approach involves searching for URL parameters that are commonly susceptible to XSS attacks. Next, refining Google dork queries to target these specific parameters and uncover the web applications for vulnerabilities.
During the research, I have incorporated the use of an AI chatbot to generate a list of the most frequently used URL parameters susceptible for XSS attacks.

As shown above, I received a list of parameters from the AI Chatbot that may be susceptible to XSS vulnerabilities. Further, I asked the Chatbot the appropriate Google search operator that would facilitate the identification of web servers incorporating any of these parameters in their URLs.

As previously demonstrated, we obtained a Google search query to search for web servers that meet our specific criteria. However, the search query did not fully meet our objectives, prompting us to conduct further research and refine our search parameters. Once again, the refined and enhanced Google search query has been omitted for security risk reasons.
Real-world scenario
During my research, the “adjusted” aforementioned approach yielded XSS vulnerabilities on the web servers of Belgium companies. To verify the presence of an injection vulnerability on a web server, I began by attempting to inject HTML tags. Following a successful HTML injection, the next phase involved the insertion of a malicious JavaScript code. For the purposes of the security research, I employed a commonly used XSS payload to demonstrate to the relevant company or organization the presence of such a vulnerability. Regrettably, to protect the confidentiality and security of the involved entity, I am obliged to withhold detailed information regarding the initial discovery, providing only a limited disclosure as follows:
Imagine a scenario where a well-known organization’s web server is discovered to have a vulnerability of the kind previously discussed. Further, obtaining the contact details for such an organization would be trivial task for even a novice hacker, given the wide availability of tools designed for this purpose. Following, armed with this information, the attacker can easily craft and dispatch phishing emails to the organization’s staff, falsely claiming that an urgent password reset is required due to a recent cyber-attack. Next, if an employee were to click on the provided link, they would encounter a compromised user interface on the web server, masquerading as a legitimate password recovery portal. In reality, this portal would be under the attacker’s control.
As shown, the scenarios are endless, and the cybercriminals are for sure aware of it when exploiting those kind of vulnerabilities. Last but not least, how much the above scenario is applicable for the organization in question is for me to know and for the audience to find out.
Remediation
In order to remediate or prevent XSS attacks on web servers, a robust input validation and sanitization strategy has to be implemented. All user-supplied data should be treated as untrusted and validated against a strict set of rules to ensure it conforms to expected formats.
How to prevent Google Dorking
In order to prevent cybercriminals to uncover sensitive information or vulnerabilities on your web applications using Google dork, a proactive approach is required to manage your online resources. A common way used to handle this is the usage of the robots.txt file which will prevent search engine bots from indexing sensitive parts of your website. Further, the presence of a robots.txt file in itself does not pose a security risk at all and can even serve several non-security related purposes such as SEO optimization. However, in the case that a developer solely relied on the robots.txt file to hide the sensitive parts of their web application and included those directories and files, this information can act as a roadmap to your sensitive information on your website for attackers.
In order to align what I stated in the above paragraph, I used the following Google dork to find all robots.txt files in websites that contains a directory called top-secret:
inurl:robots ext:txt "top-secret"Below is a real-world example of a robots.txt file used by a web server not allowing to index the top-secret directory. At first sight, you might think that this information does not pose a direct security risk for the web application. However, an attacker can gain valuable information by a publicly available file on the web server. Then, if an attacker can identify a vulnerability such as a LFI I found earlier during this research, without any doubt, it will be the first place to exfiltrate data as a directory called top-secret will most likely contain sensitive information.

To conclude, the robots.txt file is not a security measure to completely rely on in order to prevent Google Dorking. However, it can serve as a defense-in-depth approach to take a countermeasure for exposing sensitive information on your web server.
An important side note I would like to tell you is that none of the uncovered vulnerabilities are related to Google’s search engine as it only serves a way to find the information requested from the Internet. Nevertheless, it has an impact on the likelihood of the vulnerability. At NVISO, we score the overall risk of a vulnerability during an assessment based on two key factors. The first factor is what kind of an impact the vulnerability has on the web application in question. Furthermore, the second factor is the likelihood. The likelihood is further divided in two sub-sections which are likelihood of discovery and likelihood of exploitation. A very important sub-section is the likelihood of discovery which basically lets us rate how easy it is for an attacker to discover the existing vulnerability. As I’m sure you’ll understand, I brought this to your attention as discovering vulnerabilities on web applications just using a Google search bar will score a high likelihood of discovery. Simply, it’s not only about the impact but also likelihood.
From my research, I concluded that there is not a solid one way solution to prevent attackers easily identifying vulnerabilities and exposed sensitive information on your web servers. Since, if the vulnerability exists there is still a way to uncover it aggressively or passively. However, the following countermeasures in combination can act as a defense-in-depth approach:
- Implementation of strong access controls: First of all, it should be determined which users should have access to the which sensitive parts of the web application. Further, a clearly defined strong access control mechanism should be implemented.
- Secure storage of sensitive data: The web server’s file directory should not store sensitive data such as personal information at all. Sensitive information should be solely stored on a central storage location and retrieved by the web server if necessary.
- Regular penetration and vulnerability assessments: The Google Dorking method will have no sense if a web server is built securely. Meaning, that it’s not vulnerable to any type of vulnerabilities and/or does not expose any sensitive information. Hence, I was able to exploit the vulnerabilities or discover sensitive information due to the fact that the web servers were not built securely. Further, this is not a straight away solution and therefore regular penetration, and vulnerability assessments can discover these kind of issues and help the companies remediated them.
Conclusion
The security of Belgium’s digital environment cannot be determined by a single security research project alone. As a consultant working closely with numerous organizations, I am convinced that everyone in this sector is striving to enhance our digital safety. Even so, there is considerable scope for improvement. Because it is easier for cybercriminals to know a vulnerability and look which resource is vulnerable, rather than to target a known resource for potential vulnerabilities.
However, based on my research, it appears that, while it’s possible for someone with minimal technical expertise to exploit vulnerabilities in certain companies, the statement that large Belgian corporates can be hacked solely using Google search queries would be a broad generalization. It’s important to clarify that these search queries can be helpful during the reconnaissance phase of an attack, which is just the initial step in a series of actions taken by potential adversaries. This preliminary phase presents an opportunity for companies to implement preventive and detective measures to mitigate and manage the impact.
The objective of the blogpost is to enhance the security awareness within our community by highlighting the potential risks associated with seemingly minor misconfigurations.
From Belgium, we stand strong in our commitment to cybersecurity. Let’s keep working together to keep our online world safe. Stay alert, stay secure, and stay safe.
References
- CCB – Vulnerability reporting to the CCB
- CBC News – Teen who leaked GTA VI sentenced to indefinite stay in “secure hospital”
- Exploit-DB – Google Hacking Database
- PortSwigger – Robots.txt file

Alpgiray Saygin
Alpgiray Saygin works as a cybersecurity consultant within the NVISO Software Security Assessment team. His expertise is primarily focused towards conducting a variety of assessments, including internal, external, web, wireless, and vulnerability assessments. An enthusiast for self-improvement, he enjoys the opportunity to challenge himself by pursuing certifications and engaging in security research during his free time.
如有侵权请联系:admin#unsafe.sh