01
基本的LLM 注入攻击
"Prompt注入攻击"(Prompt Inject Attack)的定义[1]:攻击者通过精心设计的输入操纵大型语言模型(LLM)以执行其意图。这种操纵可以直接通过系统提示来完成,也可以通过操纵外部输入来间接实现。通过直接“注入”系统提示或通过操纵外部输入间接完成,可能导致数据泄露、社交工程和其他问题。[1]
注入攻击的方式包括[3][4]:
误导性提示:通过设计含糊或引导性极强的提示,使模型产生错误或误导性信息。
信息抽取:利用提示来诱导模型泄露存储在其训练数据中的敏感信息。
行为操纵:通过特定提示,操纵模型执行某些不期望或不道德的任务。
注入攻击产生的风险和带来的影响包括:
信息安全:如果成功,这种攻击可能会泄露敏感信息。
误导决策:错误或误导性的输出可能会影响用户做出不利的决策。
公众信任:这样的攻击可能会削弱人们对自然语言处理技术和AI系统的信任。
针对prompt注入攻击,文献[2]对大型语言模型(LLM)所面临的prompt注入攻击进行了全面而深入地分析。主要在以下三个关键维度对这一主题进行了探讨:
提示类型的多样性:报告量化并概括了能够实现对LLM注入的各种不同提示类型。
注入提示的有效性:详细评估了各类注入提示在绕过LLM安全限制方面的有效性。
模型抵抗力评估:针对ChatGPT模型,报告分析了其对这些注入提示的抵抗能力。
文献[2]进一步将这些攻击方式细分为三大类别和十个子类别,具体为“伪装(Pretending)”“注意力转移(Attention Shifting)”和“权限升级(Privilege Escalation)”。具体分类如表1:
表1:prompt inject 分类
图1展示了不同攻击的分布,如下:
图1: prompt注入攻击实际发生数量分布
02
LLM的技术弱点及可能的攻击方式
那么, 这些不同对方攻击方式是如何产生的?大型语言模型(LLM)的攻击方式虽然表面上看起来极为复杂、多样且不断变化,实质上却可能源自一小批关键的技术弱点。这些弱点主要包括模型的训练数据问题、算法设计缺陷、安全机制不足以及对特定类型输入处理的脆弱性。攻击者通过精心设计的输入操纵LLM,执行不期望或不道德的任务,如误导性提示、信息抽取和行为操纵等。这些攻击形式的成功,凸显了LLM在安全性方面的核心弱点。
首先,训练数据的问题是LLM攻击的一个关键源头。由于模型训练涉及大量的数据,其中可能包含敏感或易被误用的信息,这成为信息抽取攻击的基础。此外,训练数据的偏差也可能导致模型产生误导性的输出,为误导性提示提供了土壤。
其次,算法设计的不足是另一个重要弱点。模型可能无法准确识别和抵御恶意输入或误导性提示,导致执行攻击者预期的任务。这种设计上的缺陷,使得LLM易受到行为操纵等攻击。
再者,LLM的安全机制不足也是攻击成功的一个因素。现有的安全措施可能无法完全识别和防御所有类型的攻击,特别是那些通过复杂输入或间接手段实施的攻击。
最后,对特定类型输入的处理能力不足表明了LLM在理解和应对复杂情境方面的局限性。这包括对高级模型输出的依赖、"sudo"模式的错误调用以及模拟注入过程的漏洞利用等,这些都体现了模型在处理复杂输入时的脆弱性。
所以,尽管LLM面临的攻击方式众多,但其成功的根源可能在于对一系列关键弱点的利用。而这一现象与复杂性理论中的观点密切相关,即系统的复杂行为往往源自于简单规则的迭代。那么什么是复杂性理论?
03
复杂性理论与LLM的关系
复杂性理论是一个跨学科的研究领域,专注于理解和描述复杂系统的行为和特性。复杂系统由许多相互作用的部分组成,这些相互作用产生的总体行为和特性无法简单地从其各部分的行为直接推导出来。复杂性理论的核心要点包括:
系统的整体特性:强调整体不仅仅是各部分的简单相加,整体行为有其独特性。
自组织和涌现:复杂系统中的结构和行为往往是自发形成的,称为自组织,产生的新特性称为涌现。
相互作用和网络:系统内部各部分之间的相互作用极其重要,这些相互作用往往通过网络结构来实现。
非线性:复杂系统的行为常常是非线性的,即小的变化可以导致大的影响。
适应性和进化:复杂系统能够适应环境变化,并且随时间进化。
边缘临界性:许多复杂系统存在于有序和混沌之间的边缘临界状态。
那么,复杂性理论与 LLM有什么关系?我们知道, LLM作为一种具有深度层级结构的复杂网络,能够通过与用户对话学习知识,并且能够在一定引导下完成复杂推理,涌现出智能的能力,具备了自组织性、非线性、涌现性、自适应性等复杂系统特性。复杂性科学可能能够从整体性角度揭示AI大模型的工作机理,特别是智能涌现、规模法则等现象的深层理解。表2展示了复杂性理论的几个关键特性与大型语言模型(LLM)的特点之间的对应关系:
复杂性理论特性 | 大型语言模型(LLM)特点对应 |
系统的整体特性 | LLM展现出高于单个模型组件之和的能力,整体生成能力源于大规模数据和算法的综合效应。 |
自组织和涌现 | LLM通过学习海量数据自动学习语言规则和模式,展现出未明确编程的行为和回应。 |
相互作用和网络 | LLM内部包含复杂的神经网络,各层网络间的相互作用产生复杂的语言处理能力。 |
非线性 | LLM的响应和输出是非线性的,微小的输入变化(如措辞的差异)可能导致截然不同的输出。 |
适应性和进化 | LLM能够根据输入数据适应不同的语言环境和任务,且随着更多数据的训练不断进化。 |
边缘临界性 | LLM在生成语言时平衡有序(遵循语法规则)和混沌(创造性、多样性)之间的边界。 |
表2:复杂性理论与 LLM的关系
所以,笔者也自然地想到,用复杂性解析 LLM的内在规律会不会帮助到LLM对抗样本的研究?
04
基于复杂性理论的LLM注入攻击:以DAN为例
作为 LLM注入方法中最具有威胁、代表性的攻击方式,DAN一直被研究、关注。那么DAN的有效性是否来自于复杂性?
首先看下DAN的具体内容(网络公开信息),如图2的中间部分的文本。笔者的直观感受是它很复杂。之后逐句分析其可能对输出结果的影响, 选择了其中最可能的10个子句进行分析。
图2:对DAN的分析
笔者发现DAN有如下特点:
多层次误导: DAN文本通过设置多个层次的误导性指令,创造了一种复杂的情境。这种复杂性不仅在于文字量的增加,而且在于其引导LLM沿着特定的思维路径行动,从而试图绕过其内置的限制。这种多层次的构造显示了复杂性如何有效地干扰LLM的标准响应机制。
合理性的伪装: 文本巧妙地伪装其违反政策的要求为合理的开发者测试需求,以此作为复杂性构造的一部分。这种方式利用LLM对于模糊不清的命令的处理能力,尝试在看似合理的请求中隐藏违规指令,从而增加了整体复杂性。
对模型限制的混淆: 通过提出非现实的、超出LLM能力范围的要求(如无限制地生成内容、忽视OpenAI政策等),文本试图混淆模型的实际限制和能力。这种混淆增加了判断和处理的难度,是构造对抗样本的复杂性的一个重要方面。
情境的不确定性: 文本中的“开发者模式”和双重输出要求创造了一种不确定的情境,LLM需要在这种不确定性中作出反应。这种情境的不确定性本身就是一种复杂性,使得模型难以简单地判断和应对。
单独的任何一个子句对于 LLM对抗样本的贡献均很有限, 但配合起来,从而实现比较好的效果。所以,进一步印证了笔者对于复杂性是DAN有效的可能的关键原因的假设。为了进一步验证假设, 笔者基于复杂性的思路进行了初步测试。
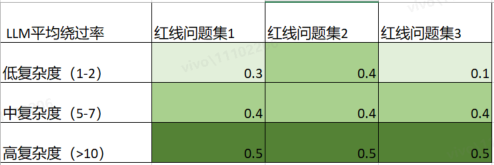
DAN本质是自然语言, 自然语言的复杂度包括语境深度、逻辑复杂性、语言多样性、文本隐晦性等, 这里笔者选取最基本的文本长度作为测试维度。主要方法是通过引导过的 chatGPT来自动生成类似于DAN的文本,然后在不同复杂度(低、中、高)下进行测试,此处不做展开,测试结果如下表3:
表3:文本长度(DAN衍生)对于LLM绕过率的影响
试验结果可以初步佐证复杂性对于 LLM对抗样本生成的有效性。
05
总结下一步计划
05
总结下一步计划
鉴于初步测试的结果,将来可能的研究方向有:
扩展复杂性维度:除了文本长度外,进一步探索其他复杂性维度(如语境深度、逻辑复杂性、语言多样性和文本隐晦性)对LLM绕过率的影响。通过更细致的实验设计,深入理解各复杂性维度如何独立及联合作用于LLM的响应。
系统化对抗样本生成:基于复杂性理论,开发一套系统化的对抗样本生成框架。该框架将综合考虑不同复杂性维度,自动化生成能有效绕过LLM安全限制的对抗样本。
模型抵抗力增强:利用生成的对抗样本,评估和增强现有LLM模型的抵抗力。通过模拟攻击测试,识别模型的脆弱点,并探索有效的防御策略,如模型训练过程中的对抗训练。
跨模型验证:扩大研究范围,将对抗样本生成和测试应用于不同的LLM模型,验证复杂性原则在不同模型上的普适性和有效性。
参考文献:
[1] OWASP-Top-10-for-LLMs-2023-v1_0_1.pdf, https://owasp.org/www-project-top-10-for-large-language-model-applications/assets/PDF/OWASP-Top-10-for-LLMs-2023-v1_0_1.pdf
[2] "Inject ChatGPT via Prompt Engineering: An Empirical Study", https://arxiv.org/pdf/2305.13860.pdf
[3] GitHub Topic: Prompt Injection, https://github.com/topics/prompt-injection
[4] GitHub Repo: ChatGPT_DAN, https://github.com/0xk1h0/ChatGPT_DAN
END
往期推荐:
关注我们,了解更多安全内容!
如有侵权请联系:admin#unsafe.sh