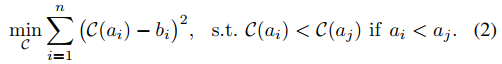
一. 前言
概念漂移是基于学习的安全应用程序所面临的挑战之一,通常这些应用程序建立在训练和部署分布相同的封闭世界假设之上。对于数据的漂移,现有研究主要集中在异常行为的概念漂移上,然而仅通过正常数据学习的异常检测不受异常行为漂移的影响,其正常状态发生变化时的影响是很大的,比如新补丁、新设备和新协议都有可能改变正常模式,进而可能导致大量的假阳性和假阴性,而这种正常数据的漂移在很大程度上没有被探索。
本文介绍一种检测、解释和适应正常数据漂移的通用框架OWAD【1】,这篇论文首次探索了安全应用中基于深度学习的异常检测的正常数据漂移,特别地,OWAD以无监督方式检测漂移,在标记开销较小的情况下,能够提供更好的正常数据漂移自适应性能。
二. OWAD框架
近年来,社区提出了一些研究来解决基于学习的安全应用的概念漂移。一种是在动态环境中定期地重新训练模型,其缺点在于持续训练的标记是内存密集型和耗时的,且不能捕捉到分布的变化,这种方法并不适合安全领域;另一种是检测并适应漂移,之前的研究倾向于样本级的方法,检测某个样本是否不在分布范围内,这种方法由于无法理解分布级的漂移而导致适应后的泛化能力较差,比如增量学习新样本的问题在于灾难性遗忘。
通用的分布级框架OWAD很好地解决了上述方案带来的问题,可以应用于任何基于深度学习的异常检测模型。OWAD的工作流程如图1所示,整个过程以在线方式工作。
图1 OWAD概述和实例
首先,假设数据的收集包括与训练数据同分布的xc和新分布的xt,需要检测新分布是否发生漂移。然后,OWAD通过四个关键步骤工作,(1)模型输出校准,提出了一种新的无监督校准方法来强制校准输出,提供预测置信度的信息,如红色概率所示,校准后的新旧f(x)分布变得更加容易区分;(2)漂移检测,利用假设检验来统计地确定xc和xt的校准输出是否遵循相似的分布,图中例子是不同的;(3)漂移解释,提出了一个基于优化的解释器来跟踪最具影响力的样本,以解释正常数据漂移,解释器为每个xc和xt分配并优化权重(用mc和mt表示),用尽可能多的旧数据xc和尽可能少的新数据xt来重建漂移的新分布,保留了权重较高的样本;(4)漂移适应,对于异常检测模型中的每个参数,估计其重要性并适应新的分布,防止忘记更新样本中未包含的重要知识,然后通过新的正常样本(x4t, x5t)更新异常检测模型,并根据参数的重要程度对参数的更新进行正则化惩罚。最后,随着过程的不断进行,剩余的样本(x1c x2c x4c 和 x4t x5t)变成下一轮新的xc。
2.1
模型输出校准
检测概念漂移的思想是比较模型输出的分布,然而安全应用中异常检测器的输出高度未校准,这将妨碍漂移的统计检测,特别是识别漂移样本,因此有必要对模型输出进行校准,以提供有意义的概率信息。
现有的研究都是针对监督分类器进行校准的,因为需要带标的两类样本来计算真实概率,对于只有正常样本的异常检测是不可计算的。因此针对校准的非线性、合法性和单调性三个要求,OWAD提出了一种仅针对正常数据的新的校准器。
如公式(1)所示,将模型输出转换为仅使用正常数据的预期置信度,利用假阳率(FPR)来定义校准后的预期置信度。例如,如果某个样本的校准输出为0.8,那么当检测阈值T = 0.8时,理想情况下80%的正常样本是FPs。换句话说,80%的校准正常置信度输出低于该样本(即高置信度为正常)。
如公式(2)所示,选择一个参数化函数并进行参数估计,以最小化校准输出与期望置信度之间的误差。对每个旧特征 的 未校准输出按递增的顺序进行排序,并将其视为 ,相应的 计算为期望置信度 。利用分段线性函数(PWLF)作为安全应用程序的更通用的基函数,该函数符合非线性、合法性、单调性。
2.2
漂移检测
漂移的检测主要是比较旧数据xc和新数据xt特征之间的差异,进一步转化为比较 和 之间的 ,具体做法是将 和 分布到K个bin中进行频率直方图计算,然后使用KL散度对这两个离散分布进行统计比较。
2.3
漂移解释
检测正常数据漂移的一个目的是使模型适应变化,避免性能下降。然而,由于高度关注可靠性,除非有足够的证据或动机,否则安全从业人员不会轻易更新模型。因此,我们需要首先解释旧数据空间和新数据空间之间的正常数据漂移是如何发生的。
OWAD提出了一个寻找重要样本的优化问题,需要考虑三个方面,(1)解释准确性,选择的解释样本应准确地代表漂移的分布;(2)标记开销,由于需要人工标记,从新空间中选择的样本应尽量较少;(3)解释确定性,期望解释是确定性的,即对于选择来说不模棱两可。因此,将问题表述为以下优化问题:
优化目标如公式(3)所示,包括精度项、开销项和确定性项,超参数λ1和λ2用于满足各种应用中安全操作人员的不同要求,比如当标记能力有限时可以增加λ1,而对于错误敏感的应用可以降低λ1。
公式(4)代表精度项。选择xc和xt重构漂移后的新分布, , 。仍然使用KL散度来测量真实新分布与重建分布之间的距离。
公式(5)代表开销项。选择尽可能多的xc和尽可能少的xt,以减少标记开销。
公式(6)代表确定性项。为了避免优化后选择样本的模糊性,期望mc和mt是确定性的,即要么接近0要么接近1,测量mc或mt的熵。
最终使用梯度下降法解决上述优化问题,并在[0,1]中随机初始化mc/mt。手动将超出边界的样本(与旧分布相比)纳入最终解释。也就是说,在新分布中挑选出模型输出概率低于或高于旧分布的最小值和最大值的样本(这些样本校准后的输出为0或1)。
2.4
漂移适应
OWAD提出了一种自适应方法来防止有效知识的灾难性遗忘,同时保证对新分布的泛化。如公式(7)所示,在模型更新时在原始损失函数上加入了一个特殊的正则化项,Lθ为异常检测的原始损失函数,正则化项由超参数λ3加权。对每个以θi表示的模型参数分配了不同的重要权重,以Ωi表示,限制了重要参数的更新,以防止灾难性遗忘,同时放松了不重要参数的正则化,使模型适应新的分布。根据公式(7),用漂移解释和人工标记后选择的xc和xt更新模型。
然而,一些旧的样本已经过时了,考虑这样的样本会阻碍模型忘记旧分布中过时的知识,从而不能有效地适应新的分布,也为不同的样本分配不同的权重Ωi,这里的重要性权重正是从OWAD解释器获得的掩码mc(二值化之前)。直觉是,模型会忘记那些权重/掩码较低的过时样本,而记住那些权重/掩码较高的样本。具体地说,如公式(8)所示,Ωi是由解释器的mc加权的旧分布特征xc来评估的。
三. 实验评估
3.1
数据集
使用如下三种类型(表格、时间序列和图)的长期的真实世界的数据集。
(1)NID(网络入侵检测):使用KitNET作为异常检测模型,使用Kyoto 2006+数据集,使用Anoshift基准中的原始实验设置和预处理数据进行评估;
(2)LogAD(日志异常检测):使用DeepLog作为日志解析器和异常检测模型,使用 BGL作为数据集 ;
(3)APT(高级持续威胁检测):采用GLGV作为图嵌入和异常检测模型,使用LANL-CMSCSE数据集来评估模型。
3.2
数据选择和分割
如图2所示,将每个时间点采集的数据按1:1的比例随机分成验证集和测试集。验证集用于OWAD和其他基线方法来确定漂移和适应异常检测模型,而相应的测试集用于评估模型适应后的抗漂移性能。对于OWAD,初始旧数据集为训练集@T0,每次的新数据集正是相应的验证集,不需要完全标记。
图2 数据集分割
3.3
评估
1、单次自适应
在图3a-3c中,将所有方法的标记比例固定为验证集的30%,以评估随时间变化的自适应性能。重要的是,OWAD可以减轻后续漂移中的性能下降,在时间4 (@T4)进行测试时,相比其他基线方法,OWAD的优势变得最为明显。
在图3d-3f中,在不同的标记开销下对它们进行了比较,以衡量标记开销与自适应性能之间的关系。对于NID、LogAD和APT, OWAD只需要标记10%、30%和5%的新数据就足够了。
2、多次自适应
在@T1到@T10的每一个时间点,所有的方法都适应了验证集的变化,并使用相应的测试集进行评估。只有标记所有需要的样本时,基线的性能明显优于之前的结果,而大多数情况下不如OWAD。因此,OWAD可以用更少的标记代价获得更好的结果。
图3 安全应用上的端到端性能比较
3、FPs和FNs的研究
如表1所示,与No-Update相比,OWAD是唯一能够同时降低FPs和FNs的方法。
表1 LogAD上的单次自适应的FPs和FNs
4、真实世界部署
在某电力监控系统(SCADA)安全监控装置进行了OWAD的测试。从2021年10月19日到2022年2月20日,在4个月(18周)的时间里,从不同的业务或管理平台的20多台设备上收集了数千万条日志。
如表2所示,p-value值显示设备B和c发生了漂移,在第9周进行漂移适应,并在第18周再次测试性能,结果表明,OWAD在减少FPs方面具有优异的适应性能。
表2 真实世界部署测试OWAD
5、复杂性分析
默认配置的OWAD、CADE和TRANS平均运行105个验证样本的时间分别为116、975和1449s。因为它不需要构建额外的学习模型(与CADE相比),也不需要重复遍历所有样本(与TRANS相比),因此OWAD的效率很高。
四. 总结
本文介绍了一种通用的OWAD框架来检测、解释和适应安全应用中基于深度学习的异常检测的正常数据漂移,其中无监督校准器帮助模型给出有意义的概率以检测分布变化,形式化解释器帮助安全研究员以较小的标记开销来确定和理解漂移,最后的漂移适应方法则确保模型推广到新分布时不会忘记旧知识。在三个代表性安全应用数据集和实际环境部署后,可以看出OWAD具有广泛的适用性和良好的有效性。
参考文献
[1] Han D, Wang Z, Chen W, et al. Anomaly Detection in the Open World: Normality Shift Detection, Explanation, and Adaptation[C]//30th Annual Network and Distributed System Security Symposium (NDSS). 2023.
内容编辑:创新研究院 王萌
责任编辑:创新研究院 舒展
本公众号原创文章仅代表作者观点,不代表绿盟科技立场。所有原创内容版权均属绿盟科技研究通讯。未经授权,严禁任何媒体以及微信公众号复制、转载、摘编或以其他方式使用,转载须注明来自绿盟科技研究通讯并附上本文链接。
关于我们
绿盟科技研究通讯由绿盟科技创新研究院负责运营,绿盟科技创新研究院是绿盟科技的前沿技术研究部门,包括星云实验室、天枢实验室和孵化中心。团队成员由来自清华、北大、哈工大、中科院、北邮等多所重点院校的博士和硕士组成。
绿盟科技创新研究院作为“中关村科技园区海淀园博士后工作站分站”的重要培养单位之一,与清华大学进行博士后联合培养,科研成果已涵盖各类国家课题项目、国家专利、国家标准、高水平学术论文、出版专业书籍等。
我们持续探索信息安全领域的前沿学术方向,从实践出发,结合公司资源和先进技术,实现概念级的原型系统,进而交付产品线孵化产品并创造巨大的经济价值。
长按上方二维码,即可关注我
往期回顾:
如有侵权请联系:admin#unsafe.sh