前言
在上周的更新中,Yakit的v1.3.1sp1版本和Yaklang v1.3.1,我们推出新版的 Codec 模块,替代了之前比较简陋的编解码页面。
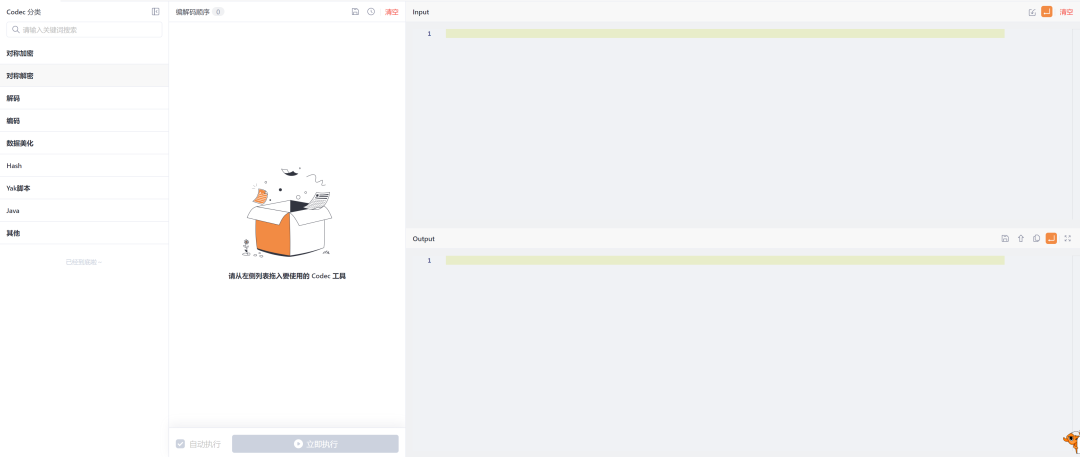
新版Codec界面介绍
新版的Codec页面在设计上借鉴了编解码工具的优秀前辈:CyberChef。采用的”序列形式“的编解码形式,支持配置一条多种编解码组合而成的序列,达成一键处理一些复杂的编解码情况。
这里序列的意义是 将若干个Codec方法按照顺序组合起来,前一个Codec方法作为后一个Codec方法的输入,依次串联起来。
左边栏:所有支持的Codec方法
中间栏:当前使用的”Codec序列“
右边栏:上部是当前的输入栏,下部是Codec的结果
新版Codec使用
快速上手
以 Hello Yakit Codec作为原始数据。
先使用一个比较常见的编码组合:Base64编码 + URL编码。从左侧Codec方法列表将对应的方法模块拖到中间的配方区域,即可构造出需要的Codec序列。
base64编码:支持两种字符集 常用的 standard字符集 和 URL安全字符集
URL编码:可选是否全部编码
点击执行即可获取需要的编码结果,十分简单易用。
Codec 方法列表
目前新版Codec支持的方法主要分 编解码、加解密、数据美化、Hash、Yak脚本、Java几种类型。其中Yak脚本类型是Yakit特有的方便工具,本文的后面会重点介绍。
对于普通的Codec方法的支持有:
加解密:AES、DES、SM4、TripleDES
编解码:HTM、URL、Unicode、base64、十六进制
Hash:MD5、SHA-1、SHA-2、SM3
为了方便用户的使用,Codec方法列表栏支持关键字搜索,可以在上方的搜索框中搜索想使用的Codec方法。
除此之外,每一条Codec方法的右侧都有收藏按钮,点击即可将其加入收藏,在顶部可以直接找到
Codec 序列
中部的Codec序列,可以随意上下拖动每一条Codec方法,改变Codec序列的执行顺序。
除此以外,还支持一些简单的流程控制,可以做到禁用不执行某个Codec方法和 执行到某个Codec方法后停止执行Codec序列的功能:
禁用Codec方法:
点击此禁用按钮,即可在序列里跳过执行此Codec方法。
停止执行Codec序列:
点击此断点按钮,即可使序列执行到此Codec方法后(包括此方法)停止执行。
为了方便用户的使用,这部分还配备了保存序列的功能,可以将一些常用的序列保存下来,需要使用时即可一点恢复。
Codec 输入输出
新版的Codec输入输出框,相对于老版添加支持了常见的操作按钮,方便用户的使用。
将结果保存到文件
将输出转到输入
复制输出
从文件导入输出
Yak 脚本 Codec
在上面有提到过,Yak脚本类型的Codec是 Yak的一大特点,因为有Yaklang的支持,所以Codec序列可以快捷方便的DIY需要的功能,而不是死板地只能调用固定的中方法。
此类型有两种Codec方法:临时Codec插件和本地Codec插件。
临时Codec插件:此处可以编写简单的临时Codec 插件,进行一些特殊小工作。比如下面的例子是向输入的字符串后面一个”ok”。
本地Codec插件:此处可以搜本地已有的Codec插件直接使用。当然也可以到Yakit插件商店里下载社区师傅分享的Codec插件使用。
联动 OpenAI
值得一提的是,在之前的一次更新中,我们上线了配置全局OpenAI KEY的功能,支持配置key来通过Yak代码使用OpenAI。
而对于Codec更新来说,Yak脚本类型Codec方法可以作为桥梁借助AI的能力,来做一些之前对于传统Codec来说比较困难的事情。
下面通过两个案例来展示这部分更新的能力。
案例一:编码检测
现有的插件商店里,有团队师傅写的 OpenAI - 检测编码 插件案例。
先对 Hello Yakit Codec 进行base64+URL编码,再使用编码检测来识别它。
可以看到插件成功识别到进行两次深度的编码。
案例二:语言检测
还有一个案例,借由AI来识别某段文本输入是什么语言,比如识别一些网页是否是中文网页,之前的识别问题在网页往往有大量的HTML等计算机语言作为干扰,难以识别到真正的自然语言,不过AI识别可以一定程度上提高识别的准确性和宽容度。
这里以百度首页的响应为例,手动编写一个插件:
handle = func(origin /*string*/) {question = f`Which language is the most likely natural language for the following text? It is necessary to exclude some interference information from computer languages.Note that it must be natural language, not computer language.You only need to tell me the language name without any other unnecessary description.\n text:\`\`\`${origin}\`\`\`\n\n`result, err = openai.ChatEx([openai.userMessage(question)])if err != nil {return "解析失败,错误: %v" % err}return result}
可以看到通过短短几行的代码成功识别了一段HTML代码里的中文文本。
END
YAK官方资源
Yak 语言官方教程:
https://yaklang.com/docs/intro/
Yakit 视频教程:
https://space.bilibili.com/437503777
Github下载地址:
https://github.com/yaklang/yakit
Yakit官网下载地址:
https://yaklang.com/
Yakit安装文档:
https://yaklang.com/products/download_and_install
Yakit使用文档:
https://yaklang.com/products/intro/
常见问题速查:
https://yaklang.com/products/FAQ
如有侵权请联系:admin#unsafe.sh