
04/01/2024
9 min read

Making full-stack easier
Today might be April Fools, and while we like to have fun as much as anyone else, we like to use this day for serious announcements. In fact, as of today, there are over 2 million developers building on top of Cloudflare’s platform — that’s no joke!
To kick off this Developer Week, we’re flipping the big “production ready” switch on three products: D1, our serverless SQL database; Hyperdrive, which makes your existing databases feel like they’re distributed (and faster!); and Workers Analytics Engine, our time-series database.
We’ve been on a mission to allow developers to bring their entire stack to Cloudflare for some time, but what might an application built on Cloudflare look like?
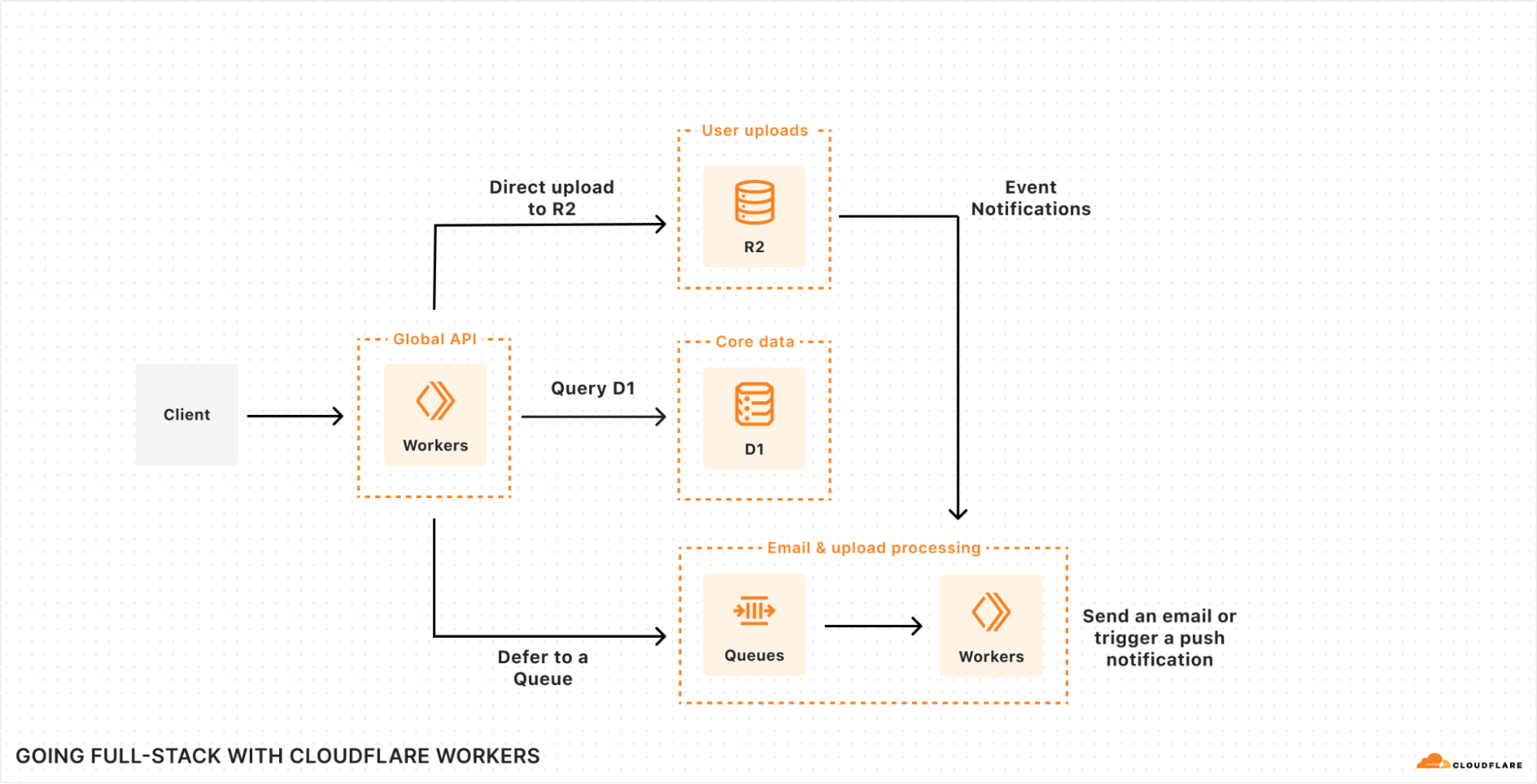
The diagram itself shouldn’t look too different from the tools you’re already familiar with: you want a database for your core user data. Object storage for assets and user content. Maybe a queue for background tasks, like email or upload processing. A fast key-value store for runtime configuration. Maybe even a time-series database for aggregating user events and/or performance data. And that’s before we get to AI, which is increasingly becoming a core part of many applications in search, recommendation and/or image analysis tasks (at the very least!).
Yet, without having to think about it, this architecture runs on Region: Earth, which means it’s scalable, reliable and fast — all out of the box.
D1 GA: Production Ready

Your core database is one of the most critical pieces of your infrastructure. It needs to be ultra-reliable. It can’t lose data. It needs to scale. And so we’ve been heads down over the last year getting the pieces into place to make sure D1 is production-ready, and we’re extremely excited to say that D1 — our global, serverless SQL database — is now Generally Available.
The GA for D1 lands some of the most asked-for features, including:
- Support for 10GB databases — and 50,000 databases per account;
- New data export capabilities; and
- Enhanced query debugging (we call it “D1 Insights”) — that allows you to understand what queries are consuming the most time, cost, or that are just plain inefficient…
… to empower developers to build production-ready applications with D1 to meet all their relational SQL needs. And importantly, in an era where the concept of a “free plan” or “hobby plan” is seemingly at risk, we have no intention of removing the free tier for D1 or reducing the 25 billion row reads included in the $5/mo Workers Paid plan:
Plan | Rows Read | Rows Written | Storage |
Workers Paid | First 25 billion / month included | First 50 million / month included | First 5 GB included + $0.75 / GB-mo |
Workers Free | 5 million / day | 100,000 / day | 5 GB (total) |
For those who’ve been following D1 since the start: this is the same pricing we announced at open beta
But things don’t just stop at GA: we have some major new features lined up for D1, including global read replication, even larger databases, more Time Travel capabilities that will allow you to branch your database, and new APIs for dynamically querying and/or creating new databases-on-the-fly from within a Worker.
D1’s read replication will automatically deploy read replicas as needed to get data closer to your users: and without you having to spin up, manage scaling, or run into consistency (replication lag) issues. Here’s a sneak preview of what D1’s upcoming Replication API looks like:
export default {
async fetch(request: Request, env: Env) {
const {pathname} = new URL(request.url);
let resp = null;
let session = env.DB.withSession(token); // An optional commit token or mode
// Handle requests within the session.
if (pathname === "/api/orders/list") {
// This statement is a read query, so it will work against any
// replica that has a commit equal or later than `token`.
const { results } = await session.prepare("SELECT * FROM Orders");
resp = Response.json(results);
} else if (pathname === "/api/orders/add") {
order = await request.json();
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session.prepare("INSERT INTO Orders VALUES (?, ?, ?)")
.bind(order.orderName, order.customer, order.value);
.run();
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
//
// D1's new Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session.prepare("SELECT COUNT(*) FROM Orders")
.run();
resp = Response.json(results);
}
// Set the token so we can continue the session in another request.
resp.headers.set("x-d1-token", session.latestCommitToken);
return resp;
}
}
Importantly, we will give developers the ability to maintain session-based consistency, so that users still see their own changes reflected, whilst still benefiting from the performance and latency gains that replication can bring.
You can learn more about how D1’s read replication works under the hood in our deep-dive post, and if you want to start building on D1 today, head to our developer docs to create your first database.
Hyperdrive: GA

We launched Hyperdrive into open beta last September during Birthday Week, and it’s now Generally Available — or in other words, battle-tested and production-ready.
If you’re not caught up on what Hyperdrive is, it’s designed to make the centralized databases you already have feel like they’re global. We use our global network to get faster routes to your database, keep connection pools primed, and cache your most frequently run queries as close to users as possible.
Importantly, Hyperdrive supports the most popular drivers and ORM (Object Relational Mapper) libraries out of the box, so you don’t have to re-learn or re-write your queries:
// Use the popular 'pg' driver? Easy. Hyperdrive just exposes a connection string
// to your Worker.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
// Prefer using an ORM like Drizzle? Use it with Hyperdrive too.
// https://orm.drizzle.team/docs/get-started-postgresql#node-postgres
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
const db = drizzle(client);
But the work on Hyperdrive doesn’t stop just because it’s now “GA”. Over the next few months, we’ll be bringing support for the other most widely deployed database engine there is: MySQL. We’ll also be bringing support for connecting to databases inside private networks (including cloud VPC networks) via Cloudflare Tunnel and Magic WAN On top of that, we plan to bring more configurability around invalidation and caching strategies, so that you can make more fine-grained decisions around performance vs. data freshness.
As we thought about how we wanted to price Hyperdrive, we realized that it just didn’t seem right to charge for it. After all, the performance benefits from Hyperdrive are not only significant, but essential to connecting to traditional database engines. Without Hyperdrive, paying the latency overhead of 6+ round-trips to connect & query your database per request just isn’t right.
And so we’re happy to announce that for any developer on a Workers Paid plan, Hyperdrive is free. That includes both query caching and connection pooling, as well as the ability to create multiple Hyperdrives — to separate different applications, prod vs. staging, or to provide different configurations (cached vs. uncached, for example).
Plan | Price per query | Connection Pooling |
Workers Paid | $0 | $0 |
To get started with Hyperdrive, head over to the docs to learn how to connect your existing database and start querying it from your Workers.
Queues: Pull From Anywhere
The task queue is an increasingly critical part of building a modern, full-stack application, and this is what we had in mind when we originally announced the open beta of Queues. We’ve since been working on several major Queues features, and we’re launching two of them this week: pull-based consumers and new message delivery controls.
Any HTTP-speaking client can now pull messages from a queue: call the new /pull endpoint on a queue to request a batch of messages, and call the /ack endpoint to acknowledge each message (or batch of messages) as you successfully process them:
// Pull and acknowledge messages from a Queue using any HTTP client
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/pull" -X POST --data '{"visibilityTimeout":10000,"batchSize":100}}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
// Ack the messages you processed successfully; mark others to be retried.
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/ack" -X POST --data '{"acks":["lease-id-1", "lease-id-2"],"retries":["lease-id-100"]}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
A pull-based consumer can run anywhere, allowing you to run queue consumers alongside your existing legacy cloud infrastructure. Teams inside Cloudflare adopted this early on, with one use-case focused on writing device telemetry to a queue from our 310+ data centers and consuming within some of our back-of-house infrastructure running on Kubernetes. Importantly, our globally distributed queue infrastructure means that messages are retained within the queue until the consumer is ready to process them.
Queues also now supports delaying messages, both when sending to a queue, as well as when marking a message for retry. This can be useful to queue (pun intended) tasks for the future, as well apply a backoff mechanism if an upstream API or infrastructure has rate limits that require you to pace how quickly you are processing messages.
// Apply a delay to a message when sending it
await env.YOUR_QUEUE.send(msg, { delaySeconds: 3600 })
// Delay a message (or a batch of messages) when marking it for retry
for (const msg of batch.messages) {
msg.retry({delaySeconds: 300})
}
We’ll also be bringing substantially increased per-queue throughput over the coming months on the path to getting Queues to GA. It’s important to us that Queues is extremely reliable: lost or dropped messages means that a user doesn’t get their order confirmation email, that password reset notification, and/or their uploads processed — each of those are user-impacting and hard to recover from.

Workers Analytics Engine is GA
Workers Analytics Engine provides unlimited-cardinality analytics at scale, via a built-in API to write data points from Workers, and a SQL API to query that data.
Workers Analytics Engine is backed by the same ClickHouse-based system we have depended on for years at Cloudflare. We use it ourselves to observe the health of our own services, to capture product usage data for billing, and to answer questions about specific customers’ usage patterns. At least one data point is written to this system on nearly every request to Cloudflare’s network. Workers Analytics Engine lets you build your own custom analytics using this same infrastructure, while we manage the hard parts for you.
Since launching in beta, developers have started depending on Workers Analytics Engine for these same use cases and more, from large enterprises to open-source projects like Counterscale. Workers Analytics Engine has been operating at production scale with mission-critical workloads for years — but we hadn’t shared anything about pricing, until today.
We are keeping Workers Analytics Engine pricing simple, and based on two metrics:
- Data points written — every time you call writeDataPoint() in a Worker, this counts as one data point written. Every data point costs the same amount — unlike other platforms, there is no penalty for adding dimensions or cardinality, and no need to predict what the size and cost of a compressed data point might be.
- Read queries — every time you post to the Workers Analytics Engine SQL API, this counts as one read query. Every query costs the same amount — unlike other platforms, there is no penalty for query complexity, and no need to reason about the number of rows of data that will be read by each query.
Both the Workers Free and Workers Paid plans will include an allocation of data points written and read queries, with pricing for additional usage as follows:
Plan | Data points written | Read queries |
Workers Paid | 10 million included per month
| 1 million included per month
|
Workers Free | 100,000 included per day | 10,000 included per day |
With this pricing, you can answer, “how much will Workers Analytics Engine cost me?” by counting the number of times you call a function in your Worker, and how many times you make a request to a HTTP API endpoint. Napkin math, rather than spreadsheet math.
This pricing will be made available to everyone in coming months. Between now and then, Workers Analytics Engine continues to be available at no cost. You can start writing data points from your Worker today — it takes just a few minutes and less than 10 lines of code to start capturing data. We’d love to hear what you think.
The week is just getting started
Tune in to what we have in store for you tomorrow on our second day of Developer Week. If you have questions or want to show off something cool you already built, please join our developer Discord.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.