04/02/2024
10 min read

Inference from fine-tuned LLMs with LoRAs is now in open beta
Today, we’re excited to announce that you can now run fine-tuned inference with LoRAs on Workers AI. This feature is in open beta and available for pre-trained LoRA adapters to be used with Mistral, Gemma, or Llama 2, with some limitations. Take a look at our product announcements blog post to get a high-level overview of our Bring Your Own (BYO) LoRAs feature.
In this post, we’ll do a deep dive into what fine-tuning and LoRAs are, show you how to use it on our Workers AI platform, and then delve into the technical details of how we implemented it on our platform.
What is fine-tuning?
Fine-tuning is a general term for modifying an AI model by continuing to train it with additional data. The goal of fine-tuning is to increase the probability that a generation is similar to your dataset. Training a model from scratch is not practical for many use cases given how expensive and time consuming they can be to train. By fine-tuning an existing pre-trained model, you benefit from its capabilities while also accomplishing your desired task. Low-Rank Adaptation (LoRA) is a specific fine-tuning method that can be applied to various model architectures, not just LLMs. It is common that the pre-trained model weights are directly modified or fused with additional fine-tune weights in traditional fine-tuning methods. LoRA, on the other hand, allows for the fine-tune weights and pre-trained model to remain separate, and for the pre-trained model to remain unchanged. The end result is that you can train models to be more accurate at specific tasks, such as generating code, having a specific personality, or generating images in a specific style. You can even fine-tune an existing LLM to understand additional information about a specific topic.
The approach of maintaining the original base model weights means that you can create new fine-tune weights with relatively little compute. You can take advantage of existing foundational models (such as Llama, Mistral, and Gemma), and adapt them for your needs.
How does fine-tuning work?
To better understand fine-tuning and why LoRA is so effective, we have to take a step back to understand how AI models work. AI models (like LLMs) are neural networks that are trained through deep learning techniques. In neural networks, there are a set of parameters that act as a mathematical representation of the model’s domain knowledge, made up of weights and biases – in simple terms, numbers. These parameters are usually represented as large matrices of numbers. The more parameters a model has, the larger the model is, so when you see models like llama-2-7b, you can read “7b” and know that the model has 7 billion parameters.
A model’s parameters define its behavior. When you train a model from scratch, these parameters usually start off as random numbers. As you train the model on a dataset, these parameters get adjusted bit-by-bit until the model reflects the dataset and exhibits the right behavior. Some parameters will be more important than others, so we apply a weight and use it to show more or less importance. Weights play a crucial role in the model's ability to capture patterns and relationships in the data it is trained on.
Traditional fine-tuning will adjust all the parameters in the trained model with a new set of weights. As such, a fine-tuned model requires us to serve the same amount of parameters as the original model, which means it can take a lot of time and compute to train and run inference for a fully fine-tuned model. On top of that, new state-of-the-art models, or versions of existing models, are regularly released, meaning that fully fine-tuned models can become costly to train, maintain, and store.
LoRA is an efficient method of fine-tuning
In the simplest terms, LoRA avoids adjusting parameters in a pre-trained model and instead allows us to apply a small number of additional parameters. These additional parameters are applied temporarily to the base model to effectively control model behavior. Relative to traditional fine-tuning methods it takes a lot less time and compute to train these additional parameters, which are referred to as a LoRA adapter. After training, we package up the LoRA adapter as a separate model file that can then plug in to the base model it was trained from. A fully fine-tuned model can be tens of gigabytes in size, while these adapters are usually just a few megabytes. This makes it a lot easier to distribute, and serving fine-tuned inference with LoRA only adds ms of latency to total inference time.
If you’re curious to understand why LoRA is so effective, buckle up — we first have to go through a brief lesson on linear algebra. If that’s not a term you’ve thought about since university, don’t worry, we’ll walk you through it.
Show me the math
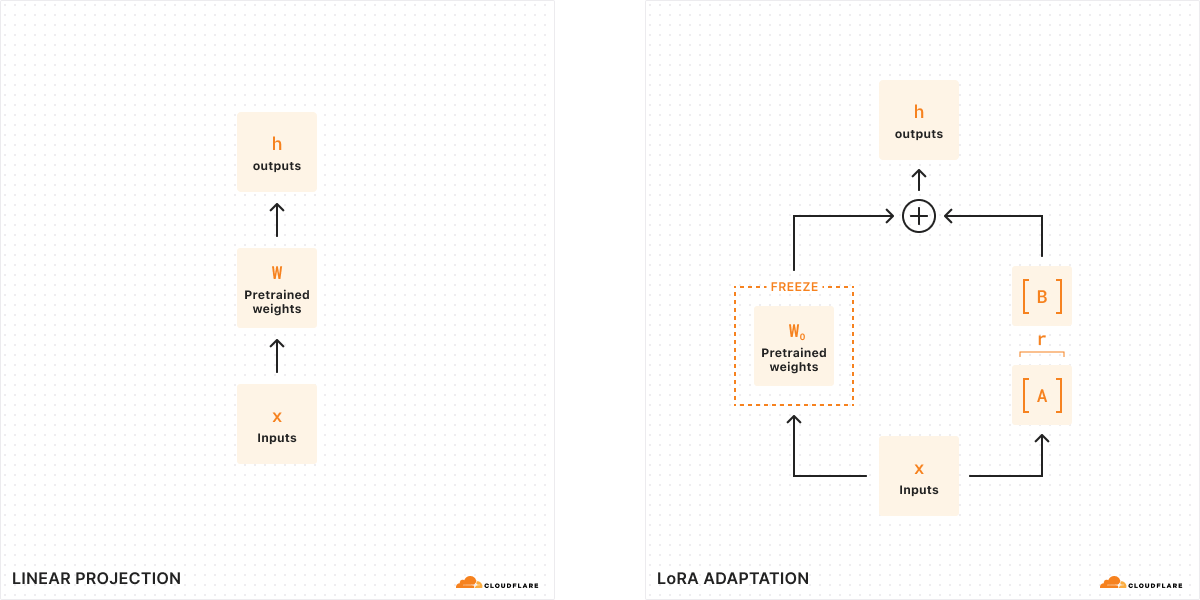
With traditional fine-tuning, we can take the weights of a model (W0) and tweak them to output a new set of weights — so the difference between the original model weights and the new weights is ΔW, representing the change in weights. Therefore, a tuned model will have a new set of weights which can be represented as the original model weights plus the change in weights, W0 + ΔW.
Remember, all of these model weights are actually represented as large matrices of numbers. In math, every matrix has a property called rank (r), which describes the number of linearly independent columns or rows in a matrix. When matrices are low-rank, they have only a few columns or rows that are “important”, so we can actually decompose or split them into two smaller matrices with the most important parameters (think of it like factoring in algebra). This technique is called rank decomposition, which allows us to greatly reduce and simplify matrices while keeping the most important bits. In the context of fine-tuning, rank determines how many parameters get changed from the original model – the higher the rank, the stronger the fine-tune, giving you more granularity over the output.
According to the original LoRA paper, researchers have found that when a model is low-rank, the matrix representing the change in weights is also low-rank. Therefore, we can apply rank decomposition to our matrix representing the change in weights ΔW to create two smaller matrices A, B, where ΔW = BA. Now, the change in the model can be represented by two smaller low-rank matrices. This is why this method of fine-tuning is called Low-Rank Adaptation.
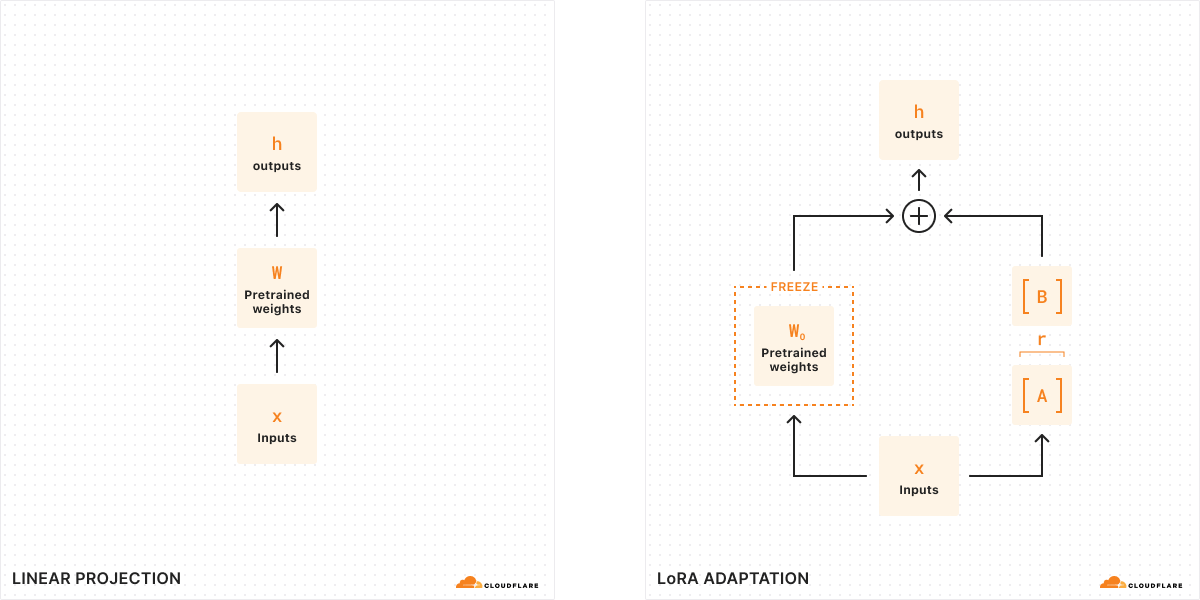
When we run inference, we only need the smaller matrices A, B to change the behavior of the model. The model weights in A, B constitute our LoRA adapter (along with a config file). At runtime, we add the model weights together, combining the original model (W0) and the LoRA adapter (A, B). Adding and subtracting are simple mathematical operations, meaning that we can quickly swap out different LoRA adapters by adding and subtracting A, B from W0.. By temporarily adjusting the weights of the original model, we modify the model’s behavior and output and as a result, we get fine-tuned inference with minimal added latency.
According to the original LoRA paper, “LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times”. Because of this, LoRA is one of the most popular methods of fine-tuning since it's a lot less computationally expensive than a fully fine-tuned model, doesn't add any material inference time, and is much smaller and portable.
How can you use LoRAs with Workers AI?
Workers AI is very well-suited to run LoRAs because of the way we run serverless inference. The models in our catalog are always pre-loaded on our GPUs, meaning that we keep them warm so that your requests never encounter a cold start. This means that the base model is always available, and we can dynamically load and swap out LoRA adapters as needed. We can actually plug in multiple LoRA adapters to one base model, so we can serve multiple different fine-tuned inference requests at once.
When you fine-tune with LoRA, your output will be two files: your custom model weights (in safetensors format) and an adapter config file (in json format). To create these weights yourself, you can train a LoRA on your own data using the Hugging Face PEFT (Parameter-Efficient Fine-Tuning) library combined with the Hugging Face AutoTrain LLM library. You can also run your training tasks on services such as Auto Train and Google Colab. Alternatively, there are many open-source LoRA adapters available on Hugging Face today that cover a variety of use cases.
Eventually, we want to support the LoRA training workloads on our platform, but we’ll need you to bring your trained LoRA adapters to Workers AI today, which is why we’re calling this feature Bring Your Own (BYO) LoRAs.
For the initial open beta release, we are allowing people to use LoRAs with our Mistral, Llama, and Gemma models. We have set aside versions of these models which accept LoRAs, which you can access by appending -lora to the end of the model name. Your adapter must have been fine-tuned from one of our supported base models listed below:
@cf/meta-llama/llama-2-7b-chat-hf-lora@cf/mistral/mistral-7b-instruct-v0.2-lora@cf/google/gemma-2b-it-lora@cf/google/gemma-7b-it-lora
As we are launching this feature in open beta, we have some limitations today to take note of: quantized LoRA models are not yet supported, LoRA adapters must be smaller than 100MB and have up to a max rank of 8, and you can try up to 30 LoRAs per account during our initial open beta. To get started with LoRAs on Workers AI, read the Developer Docs.
As always, we expect people to use Workers AI and our new BYO LoRA feature with our Terms of Service in mind, including any model-specific restrictions on use contained in the models’ license terms.
How did we build multi-tenant LoRA serving?
Serving multiple LoRA models simultaneously poses a challenge in terms of GPU resource utilization. While it is possible to batch inference requests to a base model, it is much more challenging to batch requests with the added complexity of serving unique LoRA adapters. To tackle this problem, we leverage the Punica CUDA kernel design in combination with global cache optimizations in order to handle the memory intensive workload of multi-tenant LoRA serving while offering low inference latency.
The Punica CUDA kernel was introduced in the paper Punica: Multi-Tenant LoRA Serving as a method to serve multiple, significantly different LoRA models applied to the same base model. In comparison to previous inference techniques, the method offers substantial throughput and latency improvements. This optimization is achieved in part through enabling request batching even across requests serving different LoRA adapters.
The core of the Punica kernel system is a new CUDA kernel called Segmented Gather Matrix-Vector Multiplication (SGMV). SGMV allows a GPU to store only a single copy of the pre-trained model while serving different LoRA models. The Punica kernel design system consolidates the batching of requests for unique LoRA models to improve performance by parallelizing the feature-weight multiplication of different requests in a batch. Requests for the same LoRA model are then grouped to increase operational intensity. Initially, the GPU loads the base model while reserving most of its GPU memory for KV Cache. The LoRA components (A and B matrices) are then loaded on demand from remote storage (Cloudflare’s cache or R2) when required by an incoming request. This on demand loading introduces only milliseconds of latency, which means that multiple LoRA adapters can be seamlessly fetched and served with minimal impact on inference performance. Frequently requested LoRA adapters are cached for the fastest possible inference.
Once a requested LoRA has been cached locally, the speed it can be made available for inference is constrained only by PCIe bandwidth. Regardless, given that each request may require its own LoRA, it becomes critical that LoRA downloads and memory copy operations are performed asynchronously. The Punica scheduler tackles this exact challenge, batching only requests which currently have required LoRA weights available in GPU memory, and queueing requests that do not until the required weights are available and the request can efficiently join a batch.
By effectively managing KV cache and batching these requests, it is possible to handle significant multi-tenant LoRA-serving workloads. A further and important optimization is the use of continuous batching. Common batching methods require all requests to the same adapter to reach their stopping condition before being released. Continuous batching allows a request in a batch to be released early so that it does not need to wait for the longest running request.
Given that LLMs deployed to Cloudflare’s network are available globally, it is important that LoRA adapter models are as well. Very soon, we will implement remote model files that are cached at Cloudflare’s edge to further reduce inference latency.
A roadmap for fine-tuning on Workers AI
Launching support for LoRA adapters is an important step towards unlocking fine-tunes on our platform. In addition to the LLM fine-tunes available today, we look forward to supporting more models and a variety of task types, including image generation.
Our vision for Workers AI is to be the best place for developers to run their AI workloads — and this includes the process of fine-tuning itself. Eventually, we want to be able to run the fine-tuning training job as well as fully fine-tuned models directly on Workers AI. This unlocks many use cases for AI to be more relevant in organizations by empowering models to have more granularity and detail for specific tasks.
With AI Gateway, we will be able to help developers log their prompts and responses, which they can then use to fine-tune models with production data. Our vision is to have a one-click fine-tuning service, where log data from AI Gateway can be used to retrain a model (on Cloudflare) and then the fine-tuned model can be redeployed on Workers AI for inference. This will allow developers to personalize their AI models to fit their applications, allowing for granularity as low as a per-user level. The fine-tuned model can then be smaller and more optimized, helping users save time and money on AI inference – and the magic is that all of this can all happen within our very own Developer Platform.
We’re excited for you to try the open beta for BYO LoRAs! Read our Developer Docs for more details, and tell us what you think on Discord.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.