04/02/2024
9 min read

Welcome to Tuesday – our AI day of Developer Week 2024! In this blog post, we’re excited to share an overview of our new AI announcements and vision, including news about Workers AI officially going GA with improved pricing, a GPU hardware momentum update, an expansion of our Hugging Face partnership, Bring Your Own LoRA fine-tuned inference, Python support in Workers, more providers in AI Gateway, and Vectorize metadata filtering.
Workers AI GA
Today, we’re excited to announce that our Workers AI inference platform is now Generally Available. After months of being in open beta, we’ve improved our service with greater reliability and performance, unveiled pricing, and added many more models to our catalog.
Improved performance & reliability
With Workers AI, our goal is to make AI inference as reliable and easy to use as the rest of Cloudflare’s network. Under the hood, we’ve upgraded the load balancing that is built into Workers AI. Requests can now be routed to more GPUs in more cities, and each city is aware of the total available capacity for AI inference. If the request would have to wait in a queue in the current city, it can instead be routed to another location, getting results back to you faster when traffic is high. With this, we’ve increased rate limits across all our models – most LLMs now have a of 300 requests per minute, up from 50 requests per minute during our beta phase. Smaller models have a limit of 1500-3000 requests per minute. Check out our Developer Docs for the rate limits of individual models.
Lowering costs on popular models
Alongside our GA of Workers AI, we published a pricing calculator for our 10 non-beta models earlier this month. We want Workers AI to be one of the most affordable and accessible solutions to run inference, so we added a few optimizations to our models to make them more affordable. Now, Llama 2 is over 7x cheaper and Mistral 7B is over 14x cheaper to run than we had initially published on March 1. We want to continue to be the best platform for AI inference and will continue to roll out optimizations to our customers when we can.
As a reminder, our billing for Workers AI started on April 1st for our non-beta models, while beta models remain free and unlimited. We offer 10,000 neurons per day for free to all customers. Workers Free customers will encounter a hard rate limit after 10,000 neurons in 24 hours while Workers Paid customers will incur usage at $0.011 per 1000 additional neurons. Read our Workers AI Pricing Developer Docs for the most up-to-date information on pricing.
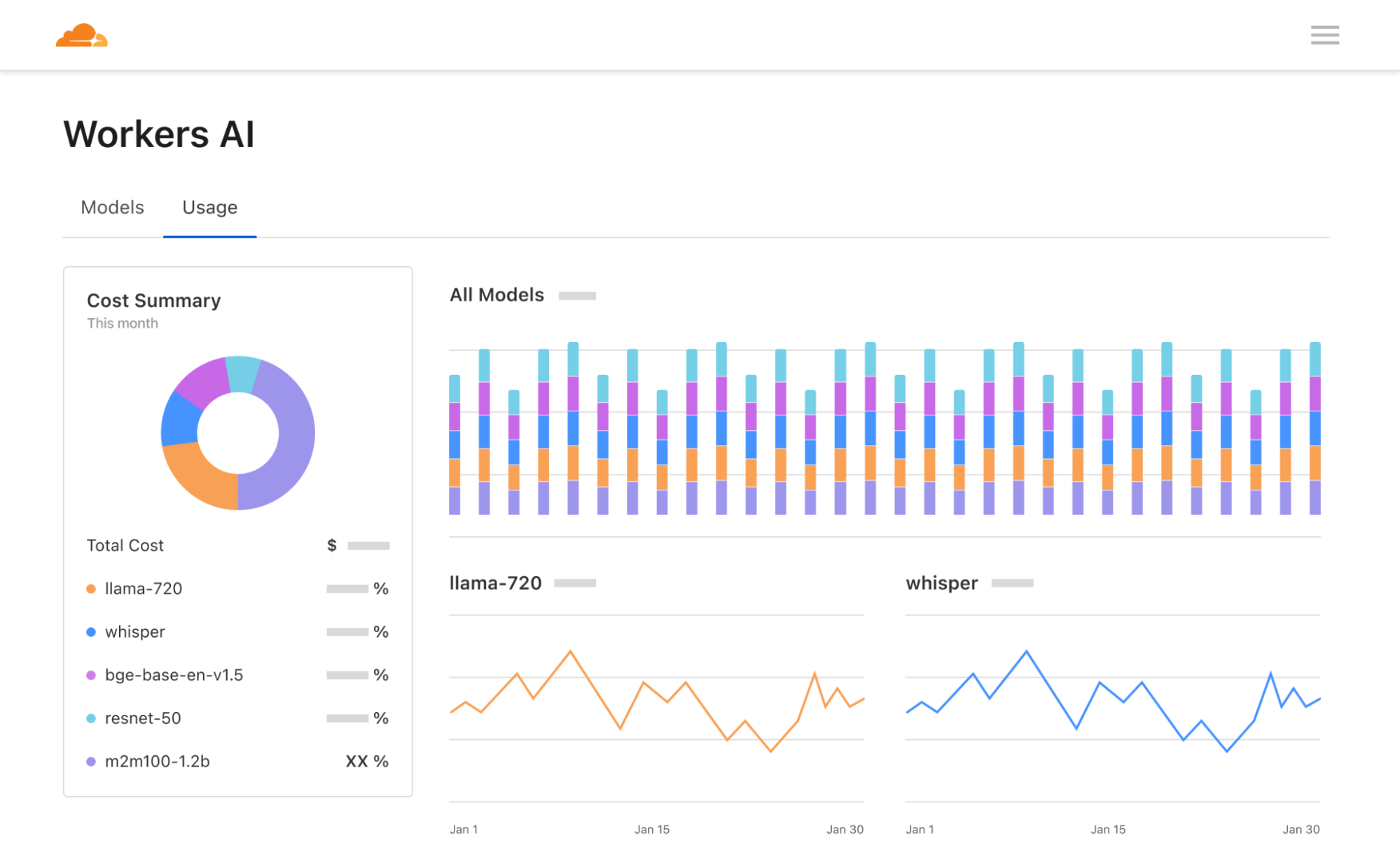
New dashboard and playground
Lastly, we’ve revamped our Workers AI dashboard and AI playground. The Workers AI page in the Cloudflare dashboard now shows analytics for usage across models, including neuron calculations to help you better predict pricing. The AI playground lets you quickly test and compare different models and configure prompts and parameters. We hope these new tools help developers start building on Workers AI seamlessly – go try them out!
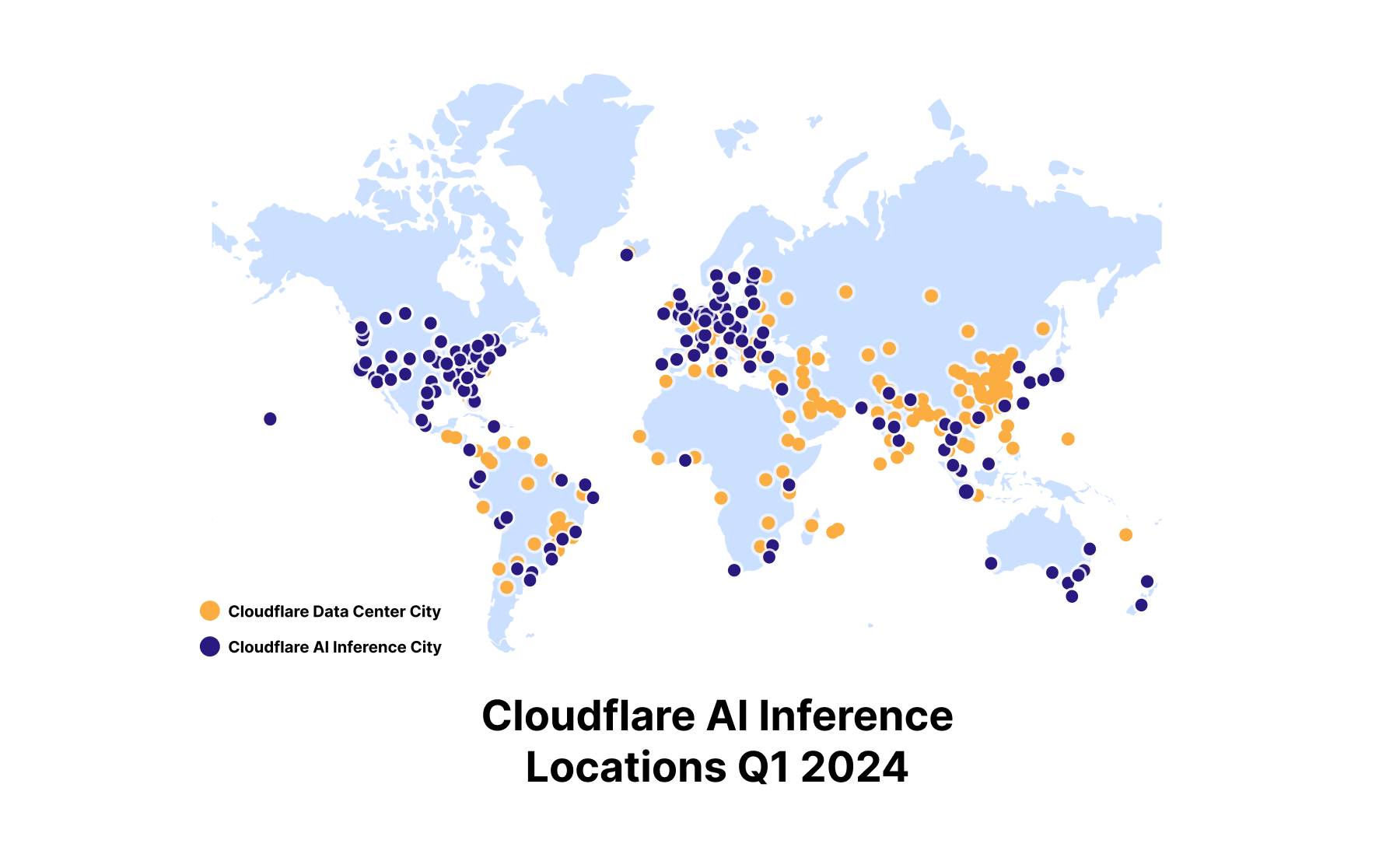
Run inference on GPUs in over 150 cities around the world
When we announced Workers AI back in September 2023, we set out to deploy GPUs to our data centers around the world. We plan to deliver on that promise and deploy inference-tuned GPUs almost everywhere by the end of 2024, making us the most widely distributed cloud-AI inference platform. We have over 150 cities with GPUs today and will continue to roll out more throughout the year.
We also have our next generation of compute servers with GPUs launching in Q2 2024, which means better performance, power efficiency, and improved reliability over previous generations. We provided a preview of our Gen 12 Compute servers design in a December 2023 blog post, with more details to come. With Gen 12 and future planned hardware launches, the next step is to support larger machine learning models and offer fine-tuning on our platform. This will allow us to achieve higher inference throughput, lower latency and greater availability for production workloads, as well as expanding support to new categories of workloads such as fine-tuning.
Hugging Face Partnership

We’re also excited to continue our partnership with Hugging Face in the spirit of bringing the best of open-source to our customers. Now, you can visit some of the most popular models on Hugging Face and easily click to run the model on Workers AI if it is available on our platform.
We’re happy to announce that we’ve added 4 more models to our platform in conjunction with Hugging Face. You can now access the new Mistral 7B v0.2 model with improved context windows, Nous Research’s Hermes 2 Pro fine-tuned version of Mistral 7B, Google’s Gemma 7B, and Starling-LM-7B-beta fine-tuned from OpenChat. There are currently 14 models that we’ve curated with Hugging Face to be available for serverless GPU inference powered by Cloudflare’s Workers AI platform, with more coming soon. These models are all served using Hugging Face’s technology with a TGI backend, and we work closely with the Hugging Face team to curate, optimize, and deploy these models.
“We are excited to work with Cloudflare to make AI more accessible to developers. Offering the most popular open models with a serverless API, powered by a global fleet of GPUs is an amazing proposition for the Hugging Face community, and I can’t wait to see what they build with it.”
- Julien Chaumond, Co-founder and CTO, Hugging Face
You can find all of the open models supported in Workers AI in this Hugging Face Collection, and the “Deploy to Cloudflare Workers AI” button is at the top of each model card. To learn more, read Hugging Face’s blog post and take a look at our Developer Docs to get started. Have a model you want to see on Workers AI? Send us a message on Discord with your request.
Supporting fine-tuned inference - BYO LoRAs
Fine-tuned inference is one of our most requested features for Workers AI, and we’re one step closer now with Bring Your Own (BYO) LoRAs. Using the popular Low-Rank Adaptation method, researchers have figured out how to take a model and adapt some model parameters to the task at hand, rather than rewriting all model parameters like you would for a fully fine-tuned model. This means that you can get fine-tuned model outputs without the computational expense of fully fine-tuning a model.
We now support bringing trained LoRAs to Workers AI, where we apply the LoRA adapter to a base model at runtime to give you fine-tuned inference, at a fraction of the cost, size, and speed of a fully fine-tuned model. In the future, we want to be able to support fine-tuning jobs and fully fine-tuned models directly on our platform, but we’re excited to be one step closer today with LoRAs.
const response = await ai.run(
"@cf/mistralai/mistral-7b-instruct-v0.2-lora", //the model supporting LoRAs
{
messages: [{"role": "user", "content": "Hello world"],
raw: true, //skip applying the default chat template
lora: "00000000-0000-0000-0000-000000000", //the finetune id OR name
}
);
BYO LoRAs is in open beta as of today for Gemma 2B and 7B, Llama 2 7B and Mistral 7B models with LoRA adapters up to 100MB in size and max rank of 8, and up to 30 total LoRAs per account. As always, we expect you to use Workers AI and our new BYO LoRA feature with our Terms of Service in mind, including any model-specific restrictions on use contained in the models’ license terms.
Read the technical deep dive blog post and developer docs to get started.
Write Workers in Python
Python is the second most popular programming language in the world (after JavaScript) and the language of choice for building AI applications. And starting today, in open beta, you can now write Cloudflare Workers in Python. Python Workers support all bindings to resources on Cloudflare, including Vectorize, Workers AI, D1, KV, R2 and more.
LangChain is the most popular framework for building LLM‑powered applications, and like how Workers AI works with langchain-js, the Python LangChain library works on Python Workers on day one, as do other Python packages like FastAPI.
Workers written in Python are just as simple as Workers written in JavaScript:
from js import Response
async def on_fetch(request, env):
return Response.new("Hello world!")
…and are configured by simply pointing at a .py file in your wrangler.toml:
name = "hello-world-python-worker"
main = "src/entry.py"
compatibility_date = "2024-03-18"
There are no extra toolchain or precompilation steps needed. The Pyodide Python execution environment is provided for you, directly by the Workers runtime, mirroring how Workers written in JavaScript already work.
There’s lots more to dive into — take a look at the docs, and check out our companion blog post for details about how Python Workers work behind the scenes.
AI Gateway now supports Anthropic, Azure, AWS Bedrock, Google Vertex, and Perplexity

Our AI Gateway product helps developers better control and observe their AI applications, with analytics, caching, rate limiting, and more. We are continuing to add more providers to the product, including Anthropic, Google Vertex, and Perplexity, which we’re excited to announce today. We quietly rolled out Azure and Amazon Bedrock support in December 2023, which means that the most popular providers are now supported via AI Gateway, including Workers AI itself.
Take a look at our Developer Docs to get started with AI Gateway.
Coming soon: Persistent Logs
In Q2 of 2024, we will be adding persistent logs so that you can push your logs (including prompts and responses) to object storage, custom metadata so that you can tag requests with user IDs or other identifiers, and secrets management so that you can securely manage your application’s API keys.
We want AI Gateway to be the control plane for your AI applications, allowing developers to dynamically evaluate and route requests to different models and providers. With our persistent logs feature, we want to enable developers to use their logged data to fine-tune models in one click, eventually running the fine-tune job and the fine-tuned model directly on our Workers AI platform. AI Gateway is just one product in our AI toolkit, but we’re excited about the workflows and use cases it can unlock for developers building on our platform, and we hope you’re excited about it too.
Vectorize metadata filtering and future GA of million vector indexes
Vectorize is another component of our toolkit for AI applications. In open beta since September 2023, Vectorize allows developers to persist embeddings (vectors), like those generated from Workers AI text embedding models, and query for the closest match to support use cases like similarity search or recommendations. Without a vector database, model output is forgotten and can’t be recalled without extra costs to re-run a model.
Since Vectorize’s open beta, we’ve added metadata filtering. Metadata filtering lets developers combine vector search with filtering for arbitrary metadata, supporting the query complexity in AI applications. We’re laser-focused on getting Vectorize ready for general availability, with an target launch date of June 2024, which will include support for multi-million vector indexes.
// Insert vectors with metadata
const vectors: Array<VectorizeVector> = [
{
id: "1",
values: [32.4, 74.1, 3.2],
metadata: { url: "/products/sku/13913913", streaming_platform: "netflix" }
},
{
id: "2",
values: [15.1, 19.2, 15.8],
metadata: { url: "/products/sku/10148191", streaming_platform: "hbo" }
},
...
];
let upserted = await env.YOUR_INDEX.upsert(vectors);
// Query with metadata filtering
let metadataMatches = await env.YOUR_INDEX.query(<queryVector>, { filter: { streaming_platform: "netflix" }} )
The most comprehensive Developer Platform to build AI applications
On Cloudflare’s Developer Platform, we believe that all developers should be able to quickly build and ship full-stack applications – and that includes AI experiences as well. With our GA of Workers AI, announcements for Python support in Workers, AI Gateway, and Vectorize, and our partnership with Hugging Face, we’ve expanded the world of possibilities for what you can build with AI on our platform. We hope you are as excited as we are – take a look at all our Developer Docs to get started, and let us know what you build.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.