前言
程序员之间往往会这样互相调侃:「所谓编程,只不过是调用各种 API 罢了」。虽是略带自嘲意味的说法,但事实确实如此,不论是被称为「程序员入门的第一行代码的 print("hello world") 」还是拥有复杂交互逻辑的应用软件,API 都在其中扮演着至关重要的角色。
API 是什么
API(Application Programming Interface,应用程序编程接口),它是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码或理解内部工作机制的细节。我们可以用一个生活中的例子来理解,假设家里突然断电了你会怎么做?我想大部分人都是直接拨打「电工的电话号码」,只需简单描述下问题,然后告诉他自己的地址,接下来的修复工作就交给专业的电工来完成即可。
在这个过程中,「拨打电工号码」这个动作相当于调用一次 API,向其传入「维修」「地址」等参数,能够得到「电力恢复正常」的结果,而「电工上门维修」则是这条 API 封装的功能,这个例子可以写一个伪代码表示:
def 拨打电工号码(目的, 地址):
# 电工上门
# 电工维修
return "电力恢复正常"
每当出现电力故障时,我们只需要调用「拨打电工号码」这个函数就可以将电力恢复正常,而无需了解电工上门使用的交通工具和具体的维修过程,API 的概念与此类似,在使用过程中我们关注的只有两点:
- API 的端点和参数
- API 的功能(能达到的目的)
除了上文提到过的「库」和「函数」之外,平日里我们说到 API,大部分时候指的是服务端与客户端通信的一种模式,比如:RESTful、GraphQL、gRPC,它们就像是无形的「丝线」,编织起了互联网的基础。
RESTful、GraphQL、gRPC 都是用于设计和实现 API 的方式,目的是提供一种标准化的方法来定义和访问服务或资源。它们都基于网络协议(如 HTTP 或 HTTP/2)进行通信,使用特定的数据格式(如 JSON、Protocol Buffers)来传输数据,为服务提供者和消费者之间提供了一种约定和规范,促进了系统的互操作性和松耦合性。
至于 API 能为我们带来什么效率提升自然不必多说,相信大家在少数派看过不少使用「API」做文章的高级技巧了,尤其是作者们基于 Notion API 实现各种自动化功能,着实令人眼花缭乱。
不过授人以鱼不如授人以渔,读完这篇文章,你也一定能制作出属于自己的效率工具!
捕获 API
API 虽然无形,可你一定能感知到它们的存在,每当我们轻车熟路地点击一个「按钮」或者敲击一次「回车」,其后都有数条细小的丝线将你需要的内容准确无误地汇聚到浏览器窗口之中。这就意味着只要能捕获这些「丝线」,即使不借助浏览器也能获取需要的资源。
那么该怎么「捕获」这些丝线呢?主要有三种方法:
- 查看官方 API 文档
- 使用 F12 观察网页特点
- 使用抓包工具
查看官方 API 文档
首选的方式当然是查看各大平台的官方网站是否提供 API 文档,比如 Notion、和风天气、讯飞语音都具备详尽的开发者文档,官方贴心地提供了 API 的详细说明,包括如何进行认证、可用的端点(Endpoints)、请求的参数、请求和响应的格式以及错误代码的含义等。
在阅读官方文档时需要关注以下几点:
- 认证机制:大多数 API 都需要经过某种形式的认证,比如
bearer token,可用于标注用户身份以及访问的合法性。 - 端点作用:了解每个 API 端点的作用,注意其 URL、请求方法、必需和可选参数、以及返回的数据结构是正确使用 API 的关键。
- 响应格式:了解 API 的错误响应格式和常见错误代码,这对于调试和异常处理至关重要。
- 访问限制:为避免高并发导致的服务器压力,大部分平台均设置了 API 调用限额与访问频次,提前注意这些信息能避免服务被意外中断。
注意以上几点,能够显著加速开发过程,减少猜测工作,并帮助你避免常见的错误。
使用 F12 观察网页特点
理想很美好,现实很残酷,并非所有平台都会贴心地为你附上一篇详细的 API 文档,平台方自然是出于服务器压力、可维护性等方面的考量,这就需要使用其他途径捕获 API。
现代浏览器内置的开发者工具是探索和理解网页工作原理的宝库,它们允许开发者查看网页的 HTML 结构、CSS 样式、JavaScript 代码以及网络请求和响应(详见: 用好 F12,一键开启浏览器的「上帝模式」)。你可以在开发者工具中打开「网络(Network)」面板,刷新页面以开始捕获网络请求。页面刷新后,网络面板会列出所有发出的网络请求,包括 API 的调用、图片、脚本、CSS 文件等,使用面板顶部的过滤器可以缩小关注点,在本篇内容你只需关注「Fetch/XHR」请求即可,这里面通常包含与 API 交互的相关请求。
点击任何一个请求,你将看到该请求的详细信息,这也是一条网络 API 请求通常会包含的内容:
- 请求方法(HTTP Method):常见的请求方法有 GET、POST、PUT、DELETE 等,用于指定对资源的操作类型。
- 请求 URL(Request URL):指定请求的目标资源的地址,包括协议、域名、端口号(可选)和路径。
- 请求头(Request Headers):包含一些附加信息,如:
Accept:指定客户端可接受的响应内容类型。
Content-Type:指定请求体的内容类型。
Authorization:用于身份验证和授权。
User-Agent:提供客户端的相关信息。
Cookie:包含之前服务器设置的 Cookie 信息。
请求体(Request Body):对于 POST、PUT 等请求方法,请求体包含要提交给服务器的数据,格式可以是 JSON、XML、表单数据等。
- 查询参数(Query Parameters):对于 GET 请求,查询参数附加在 URL 的末尾,以键值对的形式提供额外的数据。
纯理论未免有些晦涩,下面是一个实际的例子:
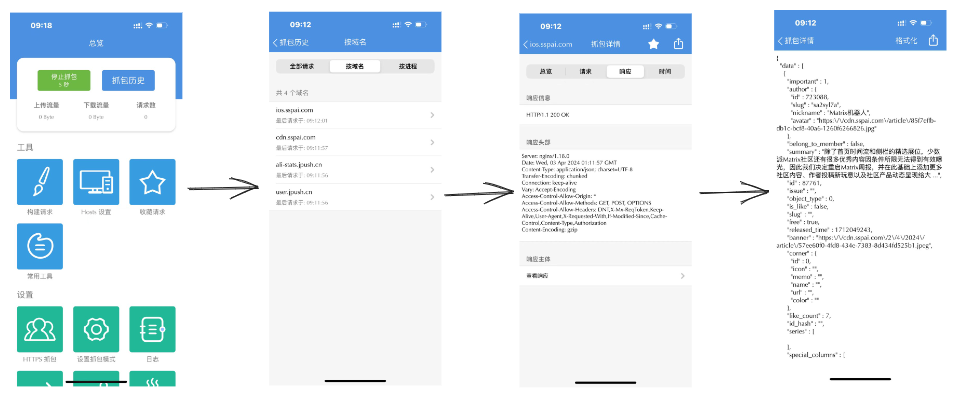
假设我想使用少数派的 API 做一些自动化的工具,而官方又没有提供 API 文档的情况下,此时就可以使用 F12 打开「开发者工具」一探究竟,从中找出需要的内容,
在「开发者工具」选中「Network」下的「Fetch/XHR」标签,使用少数派的搜索功能搜索一个关键词。

上图所列出的就是这个网页背后的「丝线」,你在页面上看到的所有数据(譬如文章数量、文章标题、文章概要以及右侧边栏的热门文章)都是通过这些「丝线」进行传递的。
随便点进其中一条 API 的详情页,可以看到完整的 URL 为:https://sspai.com/api/v1/search/article/page/get?free=1&title=%E6%B5%8F%E8%A7%88%E5%99%A8&stime=0&offset=0&limit=8 ,遗憾的是官方并没有提供详细的使用文档,具体的功能和使用方式还得观察和测试之后才能得知。
在 URL 规范中「?」用于区分路径和参数,「?」前面代表的是请求的基本网址,即 https://sspai.com/api/v1/search/article/page/get,这是由开发者定义的 API 端点,通过英文单词也可知道其功能是搜索文章,并且需要使用「get」方法。 而「?」后用「&」区分的就是一个个传递给服务端的参数,具体的参数列表如下:
free=1:这个参数的意义暂时未知,不过从单词意思来看的话,可能用于判断文章是付费内容还是免费内容。title=%E6%B5%8F%E8%A7%88%E5%99%A8:这是搜索的关键词,但正如上文所述 URL 不能直接包含中文,所以这是编码后的字符,我们可以使用一些在线解码工具解码,比如「在线 url 网址编码、解码(ES JSON 在线工具)」,可以发现 %E6%B5%8F%E8%A7%88%E5%99%A8 是 「浏览器」三个字的 URL 编码形式。stime=0:这个参数可能表示搜索的开始时间,0 可能表示从最早的记录开始搜索。offset=0:这个参数可能表示分页。limit=8:这个参数可能是用于限制返回结果的数量,这里设置为最多返回 8 篇文章。
先称赞一下少数派网站的开发者,API 的可读性不错,我们仅凭单词释义就将这条 URL 的功能猜了个七七八八,不过至于猜的到底对不对呢,这里推荐使用 Postman 测试,使用方法也很简单,只需要填写基础网址,改动几个参数的值就能轻松发送请求和查看响应,上面还剩下几个不确定的参数就留给读者朋友们自己测试啦。
知晓 API 的参数和功能之后我们就可以使用 API 做一些有趣的事情,这里我编写了一个简单的示例代码(适用于 windows)用于获取少数派的首页文章,各位可以在本地建立一个名为:test.txt 的文件,将代码拷贝至其中。
@echo off
SetLocal EnableDelayedExpansion
set "outputFile=titles.txt"
powershell -Command "$response = Invoke-RestMethod -Uri 'https://sspai.com/api/v1/article/index/page/get?limit=10&offset=0&created_at=0'; $titles = $response.data | ForEach-Object { $_.title }; [array]::Reverse($titles); $titles" > %outputFile%
保存后将该文件的后缀名改为 bat ,直接点击 test.bat 你就可以得到一个包含最近十篇首页文章标题的 titles.txt 文件。
使用抓包工具
网页端我们可以使用 F12 进行抓包,可占据了互联网半壁江山的 app 却很少提供相应的 web 版本,所以如果想在移动端 app 上捕获 API 就要借助一些抓包工具,比如安卓端的 Fiddler、苹果端的 Stream。不过与直接在浏览器的开发者工具中查看网络响应不同,使用抓包工具需要手动配置 CA 证书才能捕获 HTTPS 的流量。
这是由于二者捕获数据的原理有差异,我们都知道 HTTPS 传输的是加密后的数据,而抓包工具本质上是捕获网络中传输的数据包(网络层),以分析网络通信过程中的数据交换细节,直接抓包只能看到加密后的数据。而开发者工具中则是在查看浏览器已经解密之后的 HTTPS 通信数据(应用层),因为浏览器作为受信任的客户端已经与服务器建立了安全的 TLS 连接。

所以需要额外安装抓包工具的证书,这样,抓包工具就可以作为中间人解密来自手机的数据包,再加密后发送给服务器;同时也能解密服务器的响应,再加密后发送回手机。具体细节此处不细探讨,有关 HTTPS 的更多知识推荐看 B 站的这个视频:「HTTPS 是什么?加密原理和证书,SSL/TLS 握手过程」。
看不懂没关系,大部分抓包 app 都在下载时贴心地准备了安装证书的教程,以苹果端的 Stream 为例,初次打开软件便会提示你需要安装 CA 证书。

接着按照上图流程,在「设置 - 通用 - VPN 与设备管理」中安装下载的描述文件(对应的描述文件的名称中包含「CA」字样),安装完成后还需在「设置 - 通用 - 关于本机 - 证书信任设置」中将该证书设置为信任。
提示:尽量选择你信任的抓包软件,随意安装 CA 证书可能会带来风险。
配置完成后,只要按下「开始抓包」按钮,此期间产生的网络交换信息都可以轻松捕捉到。

通过以上三种途径足以捕获大部分平台的 API 信息,之后我们就可以使用这些API实现效率提升,下面便是一个实际的例子。
巧用 API 打造「私人信息中心」
在信息爆炸的时代,我们常常面临着一个困境:海量的信息散落在各大平台,如微博、知乎、少数派等。每天,我们都需要在这些平台之间不断切换,以获取自己感兴趣的内容。这无疑耗费了大量的时间和精力,降低了信息获取的效率。
面对这种情况,我们迫切地需要一种更高效、更便捷的信息获取方式。一个理想的解决方案是:在个人笔记或博客的一个页面中聚合多个平台的热门内容,实现信息的一站式浏览。
说到这,相信大家心里一定有想法了:如果能够抓取各大平台的热门文章 API,从接口获取对应的热榜信息,是不是就能实现一个「私人信息中心」呢。
当然每个人的兴趣各异,常逛的论坛也不同,那么第一步就是需要获取你感兴趣的平台中与「热门文章」有关的 API。
以知乎为例,通过浏览其网页版发现,热榜信息会在「首页 - 热榜」这一标签下展示,打开 F12 观察一下这个网页的特点。

我们发现热榜信息是通过这条 API https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total 获取的,观察一下「Headers」中的信息,可以发现该API使用的是 「GET」方法,附加的参数也很简单,只有两个:
- limit - 返回的结果数量
- desktop - 是否为桌面端
不过直接访问 API 的话只能得到一个复杂的 JSON 格式的数据,在 Postman 查看返回值能知道其大致结构如下:
{
"data": [
{
"target": {
"id": 1234567890,
"title": "文章标题",
"url": "https://api.zhihu.com/questions/1234567890",
// 其他字段
},
// 其他字段
},
// 更多数据项
]
}
试想一下,「私人信息中心」中最需要的是什么数据?必不可少的是今日热榜的标题和链接,换成 HTML 中的表达来说就是一个具有 href 属性和文本的 标签:
/
*这是一条热榜信息的基本单元*
/
<a href="https://baidu.com" target="_blank" rel="nofollow">百度</a>
接下来就要从 API 的返回值中获取我们需要的信息:标题和链接,从上文的 JSON 中可以看到标题信息保存在 data.target.title ,这一部分我们直接获取即可,但data.target.url 中的链接格式却不是很理想,回到网页端的知乎,我们随便点击一条热榜查看该页面的地址栏,可以看到有效的 URL 格式为: https://www.zhihu.com/question/1234567890,所以还需将JSON的对应字段转为正确可访问的 URL。
此外,返回值里面还有很多有趣的信息,比如热榜的概要、热度、图片等,如果你需要的话,也可以获取这些内容。
下面是一个使用 nodejs 写的一个示例:
const axios = require('axios')
async function getZhihuHotList() {
const hotList = {}
let num = 0
const response = await axios.get('https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total')
const data = response.data.data
data.forEach((ele) => {
hotList[num] = {
title: ele.target.title,
link: ele.target.url.replace("api","www").replace("questions","question") //将 URL 替换为正确可访问的地址
}
num += 1
})
return hotList
}
以上代码可以将知乎 API 的返回值精简为一个只包含标题和链接的 JSON,以供后续使用。接下来各位可以尝试自己获取一下少数派和微博的热榜数据。
前文的例子中我们已经编写了一个
test.bat文件用于获取少数派的首页文章,在其中使用的 API 端点为:https://sspai.com/api/v1/article/index/page/get,但其实少数派也有一个「热门」板块,不过我更关注的是近期「首页」的文章,所以选择了这条 API。
获取这些必要的信息后,我们就可以在个人博客中搭建一个「私人信息中心」页面,将这些内容整合在一起方便日常浏览。我使用的是 Trilium 笔记的 Ankia 博客系统,下文便以此为例。
- Trilium 是一款开源可部署的笔记软件,拥有一个可运行的 nodejs 环境;
- Ankia 是一款基于 Trilium 的博客主题,能够直接将 Trilium 中的笔记转换为博客。
Trilium 支持直接运行 nodejs 环境的代码,那么把上文中的示例稍微修改一下,并将精简后的 JSON 保存在一个名为「今日热榜」的笔记属性中。
然后通过 EJS 模板获取 「今日热榜」笔记中的相关属性,将其渲染为通用的 HTML。
<h1>知乎热榜</h1>
<ul>
<% zhihuHotList.forEach(function(item) { %>
<li><a href="<%= item.link %>" target="_blank" rel="nofollow"><%= item.title %></a></li>
<% }); %>
</ul>
辅以 EJS 模板的渲染,最终实现的效果如下,你也可以前往这里查看实际效果。

最后一步,既然聚合是各大平台热榜,那么定时更新热榜信息也是重要的一环,在 Trilium 中可以轻松实现脚本的定时运行,只需在脚本笔记添加: #run=hourly 属性就可以让其每小时自动运行一次,以确保信息的及时有效。
当然,以上只是一个简单的示例,这是你的「私人信息中心」,可以根据自己的需求对其进行扩展和定制,比如增加更多的内容源、添加分类和标签功能、优化页面样式等。
结语
在网络世界,API 就像是一把潜行者的「利刃」,让我们在数字世界游刃有余,无论是通过查阅官方文档,还是使用 F12 开发者工具和抓包软件,我们都可以发现 API 的踪迹,稍微思考一番,你也可以利用它们来实现自己的创意。
最后,请在遵守法律法规的前提下爬取和使用 API,作者不鼓励或支持任何违反法律的行为,做到尊重他人的知识产权,保护用户的数据安全和隐私,不从事任何违法犯罪活动是每一个网民应该遵守的基本原则。
> 下载少数派 客户端、关注 少数派小红书,感受精彩数字生活 🍃
> 实用、好用的 正版软件,少数派为你呈现 🚀
© 本文著作权归作者所有,并授权少数派独家使用,未经少数派许可,不得转载使用。
如有侵权请联系:admin#unsafe.sh