
阅读: 41
BPF通过一种软件定义的方式,将内核的行为和数据暴露给用户空间,开发者可以通过在用户空间编写BPF程序,加载到内核空间执行,进而实现对内核行为的灵活管理和控制。
摘要
BPF通过一种软件定义的方式,将内核的行为和数据暴露给用户空间,开发者可以通过在用户空间编写BPF程序,加载到内核空间执行,进而实现对内核行为的灵活管理和控制。
在计算机系统中,包过滤器通常有一个特定的用途,那就是提供给应用程序来监控系统的网络与内核运行的相关信息。这些监控程序对于系统的开发者、运维者、或者是安全管理者,都有着重要的意义。
有了更加细粒度的网络数据和内核运行数据,对于开发者来说,就可以根据当前系统的运行情况,合理的优化程序,提高程序的性能同时降低资源开销;对于系统运维者来说,能够拿到精确全面的系统运行数据,可以更好的对系统进行监控,保证系统的可靠性与高可用性;对于安全管理者来说,可以从这些网络和内核行为中,发现异常,进而在攻击行为发生的早期,发现攻击并且能够快速的进行响应和修复。
BPF(Berkeley Packet Filter)就是这样的一种包过滤器,从其诞生之初,就引起了人们的广泛关注与应用,尤其是近年来,随着微服务和云原生的发展和落地,BPF更是成为了内核开发者最受追捧的技术之一。
1. BPF概述
BPF(BSD Packet Filter)是很早就有的Unix内核特性,最早可以追溯到1992年发表在USENIX Conference上的一篇论文[1]。作者描述了他们如何为Unix内核实现一个网络包过滤器,这种实现甚至比当时最先进的包过滤技术快20倍。
随后,得益于如此强大的性能优势,所有Unix系统都将BPF作为网络包过滤的首选技术,抛弃了消耗更多内存和性能更差的原有技术实现。后来由于BPF的理念逐渐成为主流,为各大操作系统所接受,这样早期“B”所代表的BSD便渐渐淡去,最终演化成了今天我们眼中的BPF(Berkeley Packet Filter)。比如我们熟知的Tcpdump,其底层就是依赖BPF实现的包过滤。
关于BPF的发展历史,网上已经有很多文章进行了比较详尽的解释和描述,本文就不再过多的进行介绍,感兴趣的读者可以自行搜索,或者参照参考文献[2]。
本文重点要介绍的是自2014年,对传统的BPF进行扩展进化后的BPF。得益于BPF在包过滤上的良好表现,Alexei Starovoitov对BPF进行彻底的改造,并增加了新的功能,改善了它的性能,这个新版本被命名为eBPF(extended BPF),新版本的BPF全面兼容并扩充了原有BPF的功能。因此,将传统的BPF重命名为cBPF(classical BPF),相对应的,新版本的BPF则命名为eBPF或直接称为BPF(后文所有的eBPF,均简化描述为BPF)。Linux Kernel 3.15版本开始实现对eBPF的支持。
BPF针对现代硬件进行了优化和全新的设计,使其生成的指令集比cBPF解释器生成的机器码更快。这个扩展版本还将BPF VM中的寄存器数量从两个32位寄存器增加到10个64位寄存器。寄存器数量和寄存器宽度的增加为编写更复杂的程序提供了可能性,开发人员可以自由的使用函数参数交换更多的信息。这些改进使得BPF比原来的cBPF快四倍。这些改进,主要还是对网络过滤器内部处理的BPF指令集进行优化,仍然被限制在内核空间中,只有少数用户空间中的程序可以编写BPF过滤器供内核处理,比如Tcpdump和Seccomp。
除了上述的优化之外,BPF最让人兴奋的改进,是其向用户空间的开放。开发者可以在用户空间,编写BPF程序,并将其加在到内核空间执行。虽然BPF程序看起来更像内核模块,但与内核模块不同的是,BPF程序不需要开发者重新编译内核,而且保证了在内核不崩溃的情况下完成加载操作,着重强调了安全性和稳定性。BPF代码的主要贡献单位主要包括Cilium、Facebook、Red Hat以及Netronome等。

BPF使得更多的内核操作可以通过用户空间的应用程序来完成,这恰恰是与软件定义的架构和理念不谋而合。软件定义强调将系统的数据平面和控制平面进行分离,控制平面实现各种各样的控制和管理逻辑,而数据平面则专注于高效快速的执行,控制平面和数据平面通过特定的接口或协议进行通信。
因此,笔者认为,BPF正是设计和实现了一种对内核进行软件定义(Software Define Kernel)的方式。控制平面是用户空间的各种BPF程序,实现BPF程序在内核的跟踪点以及执行逻辑;数据平面则是内核各种操作的执行单元,这些跟踪点可以是一个系统调用,甚至是一段确定的实现代码;控制平面和数据平面通过bpf()系统调用进行通信,将用户空间的控制平面逻辑,加在到内核空间数据平面的准确位置。
这种软件定义内核的设计和实现,极大的提高了内核行为分析与操作的灵活性、安全性和效率,降低了内核操作的技术门槛。尤其在云原生环境中,对于云原生应用的性能提升、可视化监控以及安全检测有着重要的意义。
2. BPF原理与架构
众所周知,Linux内核是一个事件驱动的系统设计,这意味着所有的操作都是基于事件来描述和执行的。比如打开文件是一种事件、CPU执行指令是一种事件、接收网络数据包是一种事件等等。BPF作为内核中的一个子系统,可以检查这些基于事件的信息源,并且允许开发者编写并运行在内核触发任何事件时安全执行的BPF程序。

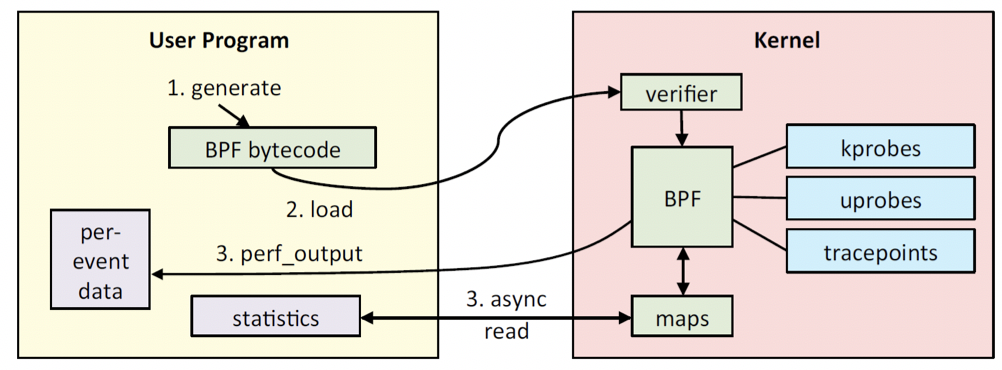
图3简要描述了BPF的架构及基本的工作流程。首先,开发者可以使用C语言(或者Python等其他高级程序语言)编写自己的BPF程序,然后通过LLVM或者GNU、Clang等编译器,将其编译成BPF字节码。Linux提供了一个bpf()系统调用,通过bpf()系统调用,将这段编译之后的字节码传入内核空间。
传入内核空间之后的BPF程序,并不是直接就在其指定的内核跟踪点上开始执行,而是先通过Verifier这个组件,来保证我们传入的这个BPF程序可以在内核中安全的运行。经过安全检测之后,Linux内核还为BPF字节码提供了一个实时的编译器(Just-In-Time,JIT),JIT将确认后的BPF字节码编译为对应的机器码。这样就可以在BPF指定的跟踪点上执行我们的操作逻辑了。

那么,用户空间的应用程序怎么样拿到我们插入到内核中的BPF程序产生的数据呢?BPF是通过一种MAP的数据结构来进行数据的存储和管理的,BPF将产生的数据,通过指定的MAP数据类型进行存储,用户空间的应用程序,作为消费者,通过bpf()系统调用,从MAP数据结构中读取数据并进行相应的存储和处理。这样一个完整BPF程序的流程就完成了。
3. BPF Hello World
下面我们通过一个Hello World例子,来对上述各个步骤进行展开介绍。这个示例将完成下面的操作:当内核执行某一系统调用时,打印“Hello, BPF World!”字符串。
首先我们先使用C语言编写一段完成上述功能的BPF代码bpf_program.c:
1 #include <linux/bpf.h>2 #define SEC(NAME) __attribute__((section(NAME), used)) 34 SEC("tracepoint/syscalls/sys_enter_execve")5 int bpf_prog(void *ctx) {6 char msg[] = "Hello, BPF World!";7 bpf_trace_printk(msg, sizeof(msg));8 return 0;9 }1011 char _license[] SEC("license") = "GPL";
首先,我们需要声明BPF程序什么时候执行,这里有一个跟踪点(Tracepoints)的概念,跟踪点是内核二进制代码中的静态标记,允许开发人员注入代码来检查内核的执行。代码的第4行就是指出我们这个BPF程序的跟踪点是什么。在BPF的语法中,使用SEC标识跟踪点,在本例中,我们将在检测到执行execve系统调用时运行这个BPF程序。
代码的5—9行,定义了我们在这个追踪点需要执行的操作,也就是每当内核检测到一个程序执行另一个程序时,将打印消息“Hello, BPF World!”
然后我们将使用clang将这个程序编译为成一个ELF二进制文件,这是内核能够识别的一种文件格式。clang -O2 -target bpf -c bpf_program.c -o bpf_program.o。
下面将这个已经编译好的BPF程序加载到内核中,现在我们已经编译了第一个BPF程序,我们使用内核提供的load_bpf_file方法,将上述编译好的bpf_program.o加载到内核。如下loader.c。
1 #include <stdio.h>2 #include <uapi/linux/bpf.h>3 #include "bpf_load.h"4 int main(int argc, char **argv) {5 if (load_bpf_file("hello_world_kern.o") != 0) {6 printf("The kernel didn't load the BPF program\n"); 7 return -1;8 }9 read_trace_pipe();10 return 0; 11 }
使用如下方法编译我们loader文件。
TOOLS=/kernel-src/samples/bpfINCLUDE=/kernel-src/tools/libPERF_INCLUDE=/kernel-src/tools/perf KERNEL_TOOLS_INCLUDE=/kernel-src/tools/include/clang -o loader -lelf\-I${INCLUDE} \-I${PERF_INCLUDE} \-I${KERNEL_TOOLS_INCLUDE} \-I${TOOLS} \${TOOLS}/bpf_load.c \loader.c
然后运行sudo ./loader,我们的BPF程序就已经加载到内核中了。当我们停止这个loader程序时,上述BPF程序实现自动从内核中卸载。
4. BPF程序类型
通过上面的Hello World示例,我们已经对BPF程序有了一个初步的认识,那么接下来我们看一下,我们都能够用BPF来做什么?Linux内核当前提供了对哪些BPF程序类型的支持。
这里可以简单的将BPF程序的类型分为两个方面:内核追踪(Tracing)和内核网络(Networking)。
4.1 内核追踪(Tracing)
第一类是内核跟踪。开发者可以通过BPF程序更清晰的了解系统中正在发生的事情。从前文中的介绍可以看出,BPF可以通过各种类型的追踪点(TracePoint)访问与特定程序相关的内存区域,并从正在运行的进程中提取信息并执行跟踪。这样开发者就可以获取关于系统的行为及其所运行的硬件的直接信息,甚至还可以直接访问为每个特定进程分配的资源,包括从文件描述符到CPU和内存使用情况。

BPF对内核行为的追踪,可以通过静态的追踪点,kprobes或者是uprobes等动态的追踪点,实现整个系统的可观察性(Observability),进而可以进行系统的性能分析、调试以及安全的检测与发现。

在安全检测上,我们可以将BPF程序的追踪点加载到一些关键并且不是很频繁的内核行为上,比如一个新的TCP/UDP会话的创建、启动了新的进程、特权提升等,这样就可以通过对这些行为的监控,进行异常检测。

4.2 内核网络(Networking)
第二类程序是对内核网络的操作。BPF程序允许开发者监控并且操作计算机系统中的网络流量,这也是BPF原始设计时的核心功能点。BPF允许过滤来自网络接口的数据包,甚至完全拒绝这些数据包。不同类型的BPF程序可以加载到内核网络中不同的处理阶段。
比如,开发者可以在网络驱动程序收到包时立即将BPF程序附加到这一网络事件上,并根据特定的过滤条件,对符合条件的数据包进行处理。这种数据包的处理和过滤可以直接下沉到物理网卡上,利用网卡的处理单元(Network Processor),进一步降低主机在数据包处理上的资源开销。
当然,这种灵活的数据包处理方式有优点也有缺点。一方面,当收到数据包之后,我们在越早的阶段处理,可能在资源消耗上越有优势,但是这个时候,内核还没有将足够的信息提供我们,我们对这个数据包的信息了解的就很少,这对下一步的处理决策有着一定的影响。另一方面,我们也可以在网络事件传递到用户空间之前将BPF程序加载到网络事件上,这时,我们将拥有关于数据包的更多信息,并且有助于做出更明智的决策,但这就需要支付完全处理数据包的成本。
这里我们简单举个例子,如下图所示,在容器等虚拟化环境中,我们可以将BPF程序附着在包括物理和虚拟的网络设备上,这样就能够根据实际的业务场景以及网络通信需求,实时动态的设置和更新网络通信规则,实现对数据包的过滤。而这种包过滤,当前容器网络更多的是通过Iptables来实现的,那么一旦规模达到一定量级之后,不论是在规则管理上,还是在资源消耗上,都将带来巨大的负担和隐患。

BPF在网络数据包的处理上,通常会与Linux内核的另外一个重要功能XDP一起来实现。XDP(Express Data Path)是一个安全的、可编程的、高性能的、内核集成的包处理器,它位于Linux网络数据路径中,当网卡驱动程序收到包时,就会执行BPF程序,XDP程序会在尽可能早的时间点对收到的包进行删除、修改或转发到网络堆栈等操作。XDP程序是通过bpf()系统调用控制的,使用BPF程序实现相应的控制逻辑。

5. BPF工具
当前BPF贡献者以及使用者,已经开发并且开源了许多实用的BPF工具。这将给我们进行BPF开发和使用带来极大的便利性。
5.1 BCC
前文的介绍中我们提到了,对于一个C语言实现的BPF程序,可以通过Clang、LLVM将其编译成BPF字节码,然后通过加载程序,将BPF字节码通过bpf()系统调用加载到内核中。这种用户动态的编译、加载比较麻烦,因此IO Visor开发实现了一个BPF程序工具包BCC[3]。
BCC(BPF Compiler Collection)是高效创建BPF程序的工具包,BCC把上述BPF程序的编译、加载等功能都集成了起来,提供友好的接口给用户,进而方便用户的使用。它使用了(Python + Lua + C++)的混合架构,底层操作封装到C++库中,Lua提供一些辅助功能,对用户的接口使用Python提供,Python和C++之间的调用使用ctypes连接。因为使用了Python,所有抓回来的数据分析和数据呈现都非常方便。
除此之外,BCC还提供了一套现成的工具和示例供开发者使用,下图展示了当前BCC提供的各种类型的工具,当我们安装完BCC之后,进入”/usr/share/bcc/tools” 和”/usr/share/bcc/examples/”目录就可以使用这些工具。

/usr/share/bcc/tools# ./syscount -L
Tracing syscalls, printing top 10… Ctrl+C to quit.
^C[21:22:45]
SYSCALL COUNT TIME (us)
futex 1122 1321885751.331
select 673 229961581.277
poll 219 171994374.042
pselect6 48 21627700.875
epoll_wait 33 14026746.897
wait4 120 10169962.613
read 4177 1662075.764
fsync 4 364937.128
nanosleep 337 48387.145
openat 2809 25358.704
5.2 其他工具
BPFTool是一个用于检查BPF程序和MAP存储的内核实用程序。这个工具在默认情况下不会安装在任何Linux发行版上,而且它还处于开发阶段,所以需要开发者编译最支持Linux内核的版本。将随Linux内核5.1版本一起发布BPFTool版本。BPFTool的一个重要功能就是可以扫描系统,进而了解系统支持了哪些BPF特性、系统中已经加载了何种BPF程序等。比如可以查看内核的哪个版本支持了哪种BPF程序,或者是否启用了BPF JIT编译器等。
BPFTrace[4]是BPF的高级跟踪语言。它允许开发者用简洁的DSL编写BPF程序,并将它们保存为脚本,开发者可以执行这些脚本,而不必在内核中手动编译和加载它们。它的灵感来自其他著名的Trace工具,比如awk和DTrace,BPFTrace将会是DTrace的一个很好的替代品。与直接使用BCC或其他BPF工具编写程序相比,使用BPFTrace的一个优点是,BPFTrace提供了许多不需要自己实现的内置功能,比如聚合信息和创建直方图等。
Kubectl-trace [5]是Kubernetes命令行kubectl的一个非常棒的插件。它可以帮助开发者在Kubernetes集群中调度BPFTrace程序,而不必安装任何附加的包或模块。它通过使用trace-runner容器镜像,通过Kubernetes作业调度来实现,trace-runner镜像中已经安装了运行程序所需的所有东西,可以在DockerHub中下载使用。

6. 总结
BPF机制通过在Linux内核事件的处理流程上,插入用户定义的BPF程序,实现对内核的软件定义,极大的提高了内核行为分析与操作的灵活性、安全性和效率,降低了内核操作的技术门槛。
Linux容器,作为云原生环境重要的支撑技术,是Linux内核上用于隔离和管理计算机进程的一组特性的抽象,高度依赖了Linux内核的底层功能。那么从内核的角度来看,(1)内核知道所有的进程/线程运行情况;(2)通过cgroups,内核可以知道Container Runtime配置的CPU/内存/网络等资源的配额以及使用情况;(3)从namespace的层面,内核可以知道Container Runtime配置的进程隔离情况、网络堆栈的情况、容器用户等众多的信息;(4)还可以知道容器环境内网络的连接以及网络流量的情况;(5)容器对系统调用、内核功能使用等信息。
因此,对于云原生环境来讲,如果能够拿到上述内核所拥有的种种信息,对于云原生应用的性能提升、可视化监控以及安全检测有着重要的意义。
参考文献
[1] The BSD Packet Filter: A New Architecture for User-level Packet Capture,http://www.tcpdump.org/papers/bpf-usenix93.pdf
[2] eBPF 简史,https://www.ibm.com/developerworks/cn/linux/l-lo-eBPF-history/index.html
[3] IO visor,https://iovisor.github.io/bcc/
[4] BPFTrace,https://github.com/iovisor/bpftrace
[5] Kubectl-trace,https://github.com/iovisor/kubectl-trace
[5] Linux Observability with BPF,https://www.oreilly.com/library/view/linux-observability-with/9781492050193/
如有侵权请联系:admin#unsafe.sh