
- Cisco Talos has developed a fuzzer that enables us to test macOS software on commodity hardware.
- Fuzzer utilizes a snapshot-based fuzzing approach and is based on WhatTheFuzz framework.
- Support for VM state extraction was implemented and WhatTheFuzz was extended to support the loading of VMWare virtual machine snapshots.
- Additional tools support symbolizing and code coverage analysis of fuzzing traces.
Finding novel and unique vulnerabilities often requires the development of unique tools that are best suited for the task. Platforms and hardware that target software run on usually dictate tools and techniques that can be used. This is especially true for parts of the macOS operating system and kernel due to its close-sourced nature and lack of tools that support advanced debugging, introspection or instrumentation.
Compared to fuzzing for software vulnerabilities on Linux, where most of the code is open-source, targeting anything on macOS presents a few difficulties. Things are closed-source, so we can’t use compile-time instrumentation. While Dynamic Binary instrumentation tools like Dynamorio and TinyInst work on macOS, they cannot be used to instrument kernel components.
There are also hardware considerations – with few exceptions, macOS only runs on Apple hardware. Yes, it can be virtualized, but that has its drawbacks. What this means in practice is that we cannot use our commodity off-the-shelf servers to test macOS code. And fuzzing on laptops isn’t exactly effective.
A while ago, we embarked upon a project that would alleviate most of these issues, and we are making the code available today.
Using a snapshot-based approach enables us to target closed-source code without custom harnesses precisely. Researchers can obtain full instrumentation and code coverage by executing tests in an emulator, which enables us to perform tests on our existing hardware. While this approach is limited to testing macOS running on Intel hardware, most of the code is still shared between Intel and ARM versions.
The simplest way to fuzz a target application is to run it in a loop while changing the inputs. The obvious downside is that you lose time on application initialization, boilerplate code and less CPU time spent on executing the relevant part of the code.
The approach in snapshot-based fuzzing is to define a point in process execution to inject the fuzzing test case (at an entry point of an important function). Then, you interrupt the program at a given point (via breakpoint or other means) and take a snapshot. The snapshot includes all of the virtual memory being used, and the CPU or other process state required to restore and resume process execution. Then, you insert the fuzzing test case by modifying the memory and resume execution.
When the execution reaches a predefined sink (end of function, error state, etc.) you stop the program, discard and replace the state with the previously saved one.
The benefit of this is that you only pay the penalty of restoring the process to its previous state, you don’t create it from scratch. Additionally, suppose you can rely on OS or CPU mechanisms such as CopyOnWrite, page-dirty tracking and on-demand paging. In that case, the operation of restoring the process can be very fast and have little impact on overall fuzzing speed.
Cory Duplantis championed our previous attempts at utilizing snapshot-based fuzzing in his work on Barbervisor, a bare metal hypervisor developed to support high-performance snapshot fuzzing.
It involved acquiring a snapshot of a full (Virtual Box-based) VM and then transplanting it into Barbervisor where it could be executed. It relied on Intel CPU features to enable high performance by only restoring modified memory pages.
While this showed great potential and gave us a glimpse into the potential utility of snapshot-based fuzzing, it had a few downsides. A similar approach, built on top of KVM and with numerous improvements, was implemented in Snapchange and released by AWS Labs.
Around the time Talos published Barbervisor, Axel Souchet published his WTF project, which takes a different approach. It trades performance to have a clean development environment by relying on existing tooling. It uses Hyper-V to run virtual machines that are to be snapshotted, then uses kd (Windows kernel debugger) to perform the snapshot, which saves the state in a Windows memory dump file format, which is optimized for loading. WTF is written in C++, which means it can benefit from the plethora of existing support libraries such as custom mutators or fuzz generators.
It has multiple possible execution backends, but the most fully featured one is based on Bochs, an x86 emulator, which provides a complete instrumentation framework. The user will likely see a dip in performance – it’s slower than native execution – but it can be run on any platform that Bochs runs on (Linux and Windows, virtualized or otherwise) with no special hardware requirements.
The biggest downside is that it was mainly designed to target Windows virtual machines and targets running on Windows.
When modifying WTF to support fuzzing macOS targets, we need to take care of a few mechanisms that aren’t supported out of the box. Split into pre-fuzzing and fuzzing stages, those include:
- A mechanism to debug the OS and process that is to be fuzzed – this is necessary to precisely choose the point of snapshotting.
- A mechanism to acquire a copy of physical memory – necessary to transplant the execution into the emulator.
- CPU state snapshotting – this has to include all the Control Registers, all the MSRs and other CPU-specific registers that aren’t general-purpose registers.
In the fuzzing stage, on the other hand, we need:
- A mechanism to restore the acquired memory pages – this has to be custom for our environment.
- A way to catch crashes as crashing/faulting mechanisms on Windows and macOS, which differ greatly.
CPU state, memory modification and coverage analysis will also require adjustments.
For targeting the macOS kernel, we’d want to take a snapshot of an actual, physical, machine. That would give us the most accurate attack surface with all the kernel extensions that require special hardware being loaded and set up. There is a significant attack surface reduction in virtualized macOS.
However, debugging physical Mac machines is cumbersome. It requires at least one more machine and special network adapters, and the debug mechanism isn’t perfect for our goal (relies on non-maskable interrupts instead of breakpoints and doesn’t fully stop the kernel from executing code).
Debugging a virtual machine is somewhat easier. VMWare Fusion contains a gdbserver stub that doesn’t care about the underlying operating system. We can also piggyback on VMWare’s snapshotting feature.
VMWare debugger stub is enabled in the .vmx file.
debugStub.listen.guest64 = "TRUE"
debugStub.hideBreakpoints = "FALSE"
The first option enables it, and the second tells gdb stub to use software, as opposed to hardware breakpoints. Hardware breakpoints aren’t supported in Fusion.
Attaching to a VM for debugging relies on GDB’s remote protocol:
$ lldb
(lldb) gdb-remote 8864
Kernel UUID: 3C587984-4004-3C76-8ADF-997822977184
Load Address: 0xffffff8000210000
...
kernel was compiled with optimization - stepping may behave oddly; variables may not be available.
Process 1 stopped
* thread #1, stop reason = signal SIGTRAP
frame #0: 0xffffff80003d2eba kernel`machine_idle at pmCPU.c:181:3 [opt]
Target 0: (kernel) stopped.
(lldb)
The second major requirement for snapshot fuzzing is, well, snapshotting. We can piggyback on VMWare Fusion for this, as well.
The usual way to use VMWare’s snapshotting is to either suspend a VM or make an exact copy of the state you can revert to. This is almost exactly what we want to do.
We can set a breakpoint using the debugger and wait for it to be reached. At this point, the whole virtual machine execution is paused. Then, we can take a snapshot of the machine state paused at precisely the instruction we want. There is no need to time anything or inject sentinel instruction. Since we are debugging the VM, we control it fully. A slightly more difficult part is figuring out how to use this snapshot. To reuse them, we needed to figure out the file formats VMware Fusion stores the snapshots in.
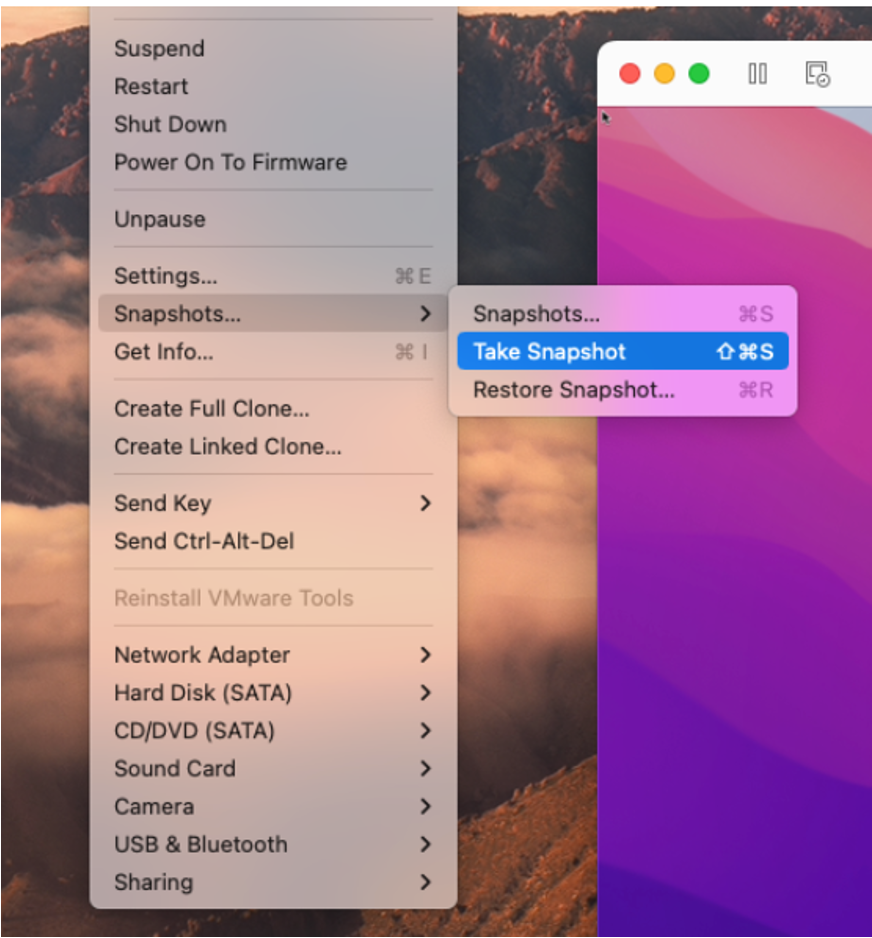
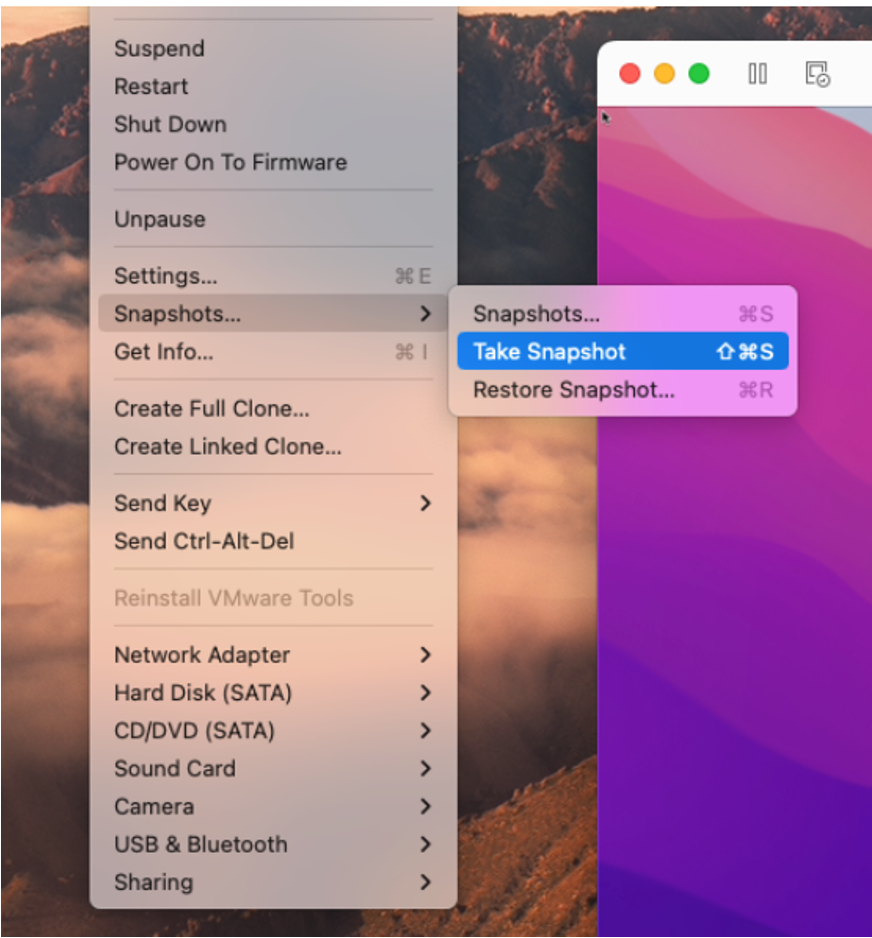
Fusion’s snapshots consist of two separate files: a vmem file that holds a memory state and a vmsn file that holds the device state, which includes the CPU, all the controllers, busses, pci, disks, etc. – everything that’s needed to restore the VM.
As far as the memory dump goes, the vmem file is a linear dump of all of the VM’s RAM. If the VM has 2GB of RAM, the vmem file will be a 2GB byte-for-byte copy of the RAM’s contents. This is a physical memory layout because we are dealing with virtual machines and no parsing is required. Instead, we just need a loader.
The machine state file, on the other hand, uses a fairly complex, undocumented format that contains a lot of irrelevant information. We only care about the CPU state, as we won’t be trying to restore a complete VM, just enough to run a fair bit of code. While undocumented, it has been mostly reverse-engineered for the Volatility project. By extending Volatility, we can get a CPU state dump in the format usable by WhatTheFuzz.
With both file formats figured out, we can return to WTF to modify it accordingly. The most important modification we need to make is to the physical memory loader.
WTF uses Windows’ dmp file format, so we need our own handler. Since our memory dump file is just a direct one-to-one copy of physical RAM, mapping it into memory and then mapping the pages is very straightforward, as you can see in the following excerpt:
bool BuildPhysmemRawDump(){
//vmware snapshot is just a raw linear dump of physical memory, with some gaps
//just fill up a structure for all the pages with appropriate physmem file offsets
//assuming physmem dump file is from a vm with 4gb of ram
uint8_t *base = (uint8_t *)FileMap_.ViewBase();
for(uint64_t i = 0;i < 786432; i++ ){ //that many pages, first 3gb
uint64_t offset = i*4096;
Physmem_.try_emplace(offset, (uint8_t *)base+offset);
}
//there's a gap in VMWare's memory dump from 3 to 4gb, last 1gb is mapped above 4gb
for(uint64_t i = 0;i < 262144; i++ ){
uint64_t offset = (i+786432)*4096;
Physmem_.try_emplace(i*4096+4294967296, (uint8_t *)base+offset);
}
return true;
}We just need to fake the structures with appropriate offsets.
The last piece of the puzzle is how to catch crashes. In WTF, and our modification of it, this is as simple as setting a breakpoint at an appropriate place. On Windows, hooking nt!KeBugCheck2 is the perfect place, we just need a similar thing in the macOS kernel.
The kernel panics, exceptions, faults and similar on macOS go through a complicated call stack that ultimately culminates in a complete OS crash and reboot.
Depending on what type of crash we are trying to catch and the type of kernel we are running, we can put a breakpoint on exception_triage function, which is in the execution path between a fault happening and the machine panicking or rebooting:
With that out of the way, we have all the pieces of the puzzle necessary to fuzz a macOS kernel target.
MacOS’ IPv6 stack would be a good example to illustrate how the complete scheme works. This is a simple but interesting entry point into some complex code. Attack surface that is composed of a complex set of protocols, is reachable over the network and is stateful. It would be difficult to fuzz with traditional fuzzers because network fuzzing is slow, and we wouldn’t have coverage. Additionally, this part of the macOS kernel is open-source, making it easy to see if things work as intended. First thing, we’ll need to prepare the target virtual machine.
VM preparation
This will assume a few things:
- The host machine is a MacBook running macOS 12 Monterey.
- VMWare fusion as a virtualization platform
- Guest VM running macOS 12 Monterey with the following specs:
- SIP turned off.
- 2 or 4 GB of RAM (4 is better, but snapshots are bigger).
- One CPU/Core as multithreading just complicates things.
Since we are going to be debugging on the VM, it's prudent to disable SIP before doing anything else.
We'll use VMWare's GDB stub to debug the VM instead of Apple’s KDP because it interferes less with the running VM. The VM doesn't and cannot know that it is enabled.
Enabling it is as simple as editing a VM's .vmx file. Locate it in the VM package and add the following lines to the end:
debugStub.listen.guest64 = "TRUE"
debugStub.hideBreakpoints = "FALSE"To make debugging, and our lives, easier, we'll want to change some macOS boot options. Since we've disabled SIP, this should be doable from a regular (elevated) terminal:
$ sudo nvram boot-args="slide=0 debug=0x100 keepsyms=1"
The code above changes macOS' boot args to:
- Disable boot time kASLR via slide=0.
- Disable watchdog via
debug=0x100, this will prevent the VM from automatically rebooting in case of a kernel panic. keepsyms=1, in conjunction with the previous one, prints out the symbols during a kernel panic.
Setting up a KASAN build of the macOS kernel would be a crucial step for actual fuzzing, but not strictly necessary for testing purposes.
Target function
Our fuzzing target is function ip6_input which is the entry point for parsing incoming IPv6 packets.
void
ip6_input(struct mbuf *m)
{
struct ip6_hdr *ip6;
int off = sizeof(struct ip6_hdr), nest;
u_int32_t plen;
u_int32_t rtalert = ~0;It has a single parameter that contains a mbuf that holds the actual packet data. This is the data we want to mutate and modify to fuzz ipv6_input.
Mbuf structures are a standard structure in XNU and are essentially a linked list of buffers that contain data. We need to find where the actual packet data is (mh_data) and mutate it before resuming execution.
struct mbuf {
struct m_hdr m_hdr;
union {
struct {
struct pkthdr MH_pkthdr; /* M_PKTHDR set */
union {
struct m_ext MH_ext; /* M_EXT set */
char MH_databuf[_MHLEN];
} MH_dat;
} MH;
char M_databuf[_MLEN]; /* !M_PKTHDR, !M_EXT */
} M_dat;
};struct m_hdr {
struct mbuf *mh_next; /* next buffer in chain */
struct mbuf *mh_nextpkt; /* next chain in queue/record */
caddr_t mh_data; /* location of data */
int32_t mh_len; /* amount of data in this mbuf */
u_int16_t mh_type; /* type of data in this mbuf */
u_int16_t mh_flags; /* flags; see below */
}
This means that we will have to, in the WTF fuzzing harness, dereference a pointer to get to the actual packet data.
Snapshotting
To create a snapshot, we use the debugger to set a breakpoint at ip6_input function. This is where we want to start our fuzzing.
Process 1 stopped
* thread #2, name = '0xffffff96db894540', queue = 'cpu-0', stop reason = signal SIGTRAP
frame #0: 0xffffff80003d2eba kernel`machine_idle at pmCPU.c:181:3 [opt]
Target 0: (kernel) stopped.
(lldb) breakpoint set -n ip6_input
Breakpoint 1: where = kernel`ip6_input + 44 at ip6_input.c:779:6, address = 0xffffff800078b54c
(lldb) c
Process 1 resuming
(lldb)
Then, we need to provoke the VM to reach that breakpoint. We can either wait until the VM receives an IPv6 packet, or we can do it manually. To send the actual packet, we prefer using `ping6` because it doesn’t send any SYN/ACKs and allows us to easily control packet size and contents.:
The actual command is:
ping6 fe80::108f:8a2:70be:17ba%en0 -c 1 -p 41 -s 1016 -b 1064The above simply sends a controlled ICMPv6 ping packet that is as large as possible and padded with 0x41 bytes. We send the packet to the en0 interface – sending to the localhost shortcuts the call stack and packet processing are different. This should give us a nice packet in memory, mostly full of AAAs that we can mutate and fuzz.
When the ping6 command is executed, the VM will receive the IPv6 packet and start parsing it, which will immediately reach our breakpoint.
Process 1 stopped
* thread #3, name = '0xffffff96dbacd540', queue = 'cpu-0', stop reason = breakpoint 1.1
frame #0: 0xffffff800078b54c kernel`ip6_input(m=0xffffff904e51b000) at ip6_input.c:779:6 [opt]
Target 0: (kernel) stopped.
(lldb)The VM is now paused and we have the address of our mbuf that contains the packet which we can fuzz. Fusion's gdb stub seems to be buggy, though, and it leaves that int 3 in place. If we were to take a snapshot now, the first instruction we execute would be that int3, which would immediately break our fuzzing. We need to explicitly disable the breakpoint before taking the snapshot:
(lldb) disassemble
kernel`ip6_input:
0xffffff800078b520 <+0>: pushq %rbp
0xffffff800078b521 <+1>: movq %rsp, %rbp
0xffffff800078b524 <+4>: pushq %r15
0xffffff800078b526 <+6>: pushq %r14
0xffffff800078b528 <+8>: pushq %r13
0xffffff800078b52a <+10>: pushq %r12
0xffffff800078b52c <+12>: pushq %rbx
0xffffff800078b52d <+13>: subq $0x1b8, %rsp ; imm = 0x1B8
0xffffff800078b534 <+20>: movq %rdi, %r12
0xffffff800078b537 <+23>: leaq 0x98ab02(%rip), %rax ; __stack_chk_guard
0xffffff800078b53e <+30>: movq (%rax), %rax
0xffffff800078b541 <+33>: movq %rax, -0x30(%rbp)
0xffffff800078b545 <+37>: movq %rdi, -0xb8(%rbp)
-> 0xffffff800078b54c <+44>: int3
0xffffff800078b54d <+45>: testl %ebp, (%rdi,%rdi,8)Sometimes, it's just buggy enough that it won't update the disassembly listing after the breakpoint is removed.
(lldb) breakpoint disable
All breakpoints disabled. (1 breakpoints)
(lldb) disassemble
kernel`ip6_input:
0xffffff800078b520 <+0>: pushq %rbp
0xffffff800078b521 <+1>: movq %rsp, %rbp
0xffffff800078b524 <+4>: pushq %r15
0xffffff800078b526 <+6>: pushq %r14
0xffffff800078b528 <+8>: pushq %r13
0xffffff800078b52a <+10>: pushq %r12
0xffffff800078b52c <+12>: pushq %rbx
0xffffff800078b52d <+13>: subq $0x1b8, %rsp ; imm = 0x1B8
0xffffff800078b534 <+20>: movq %rdi, %r12
0xffffff800078b537 <+23>: leaq 0x98ab02(%rip), %rax ; __stack_chk_guard
0xffffff800078b53e <+30>: movq (%rax), %rax
0xffffff800078b541 <+33>: movq %rax, -0x30(%rbp)
0xffffff800078b545 <+37>: movq %rdi, -0xb8(%rbp)
-> 0xffffff800078b54c <+44>: int3
0xffffff800078b54d <+45>: testl %ebp, (%rdi,%rdi,8)
So, we can just step over the offending instruction to make sure:
(lldb) step
Process 1 stopped
* thread #3, name = '0xffffff96dbacd540', queue = 'cpu-0', stop reason = step in
frame #0: 0xffffff800078b556 kernel`ip6_input(m=0xffffff904e51b000) at ip6_input.c:780:12 [opt]
Target 0: (kernel) stopped.
(lldb) disassemble
kernel`ip6_input:
0xffffff800078b520 <+0>: pushq %rbp
0xffffff800078b521 <+1>: movq %rsp, %rbp
0xffffff800078b524 <+4>: pushq %r15
0xffffff800078b526 <+6>: pushq %r14
0xffffff800078b528 <+8>: pushq %r13
0xffffff800078b52a <+10>: pushq %r12
0xffffff800078b52c <+12>: pushq %rbx
0xffffff800078b52d <+13>: subq $0x1b8, %rsp ; imm = 0x1B8
0xffffff800078b534 <+20>: movq %rdi, %r12
0xffffff800078b537 <+23>: leaq 0x98ab02(%rip), %rax ; __stack_chk_guard
0xffffff800078b53e <+30>: movq (%rax), %rax
0xffffff800078b541 <+33>: movq %rax, -0x30(%rbp)
0xffffff800078b545 <+37>: movq %rdi, -0xb8(%rbp)
0xffffff800078b54c <+44>: movl $0x28, -0xd4(%rbp)
-> 0xffffff800078b556 <+54>: movl $0x0, -0xe4(%rbp)
0xffffff800078b560 <+64>: movl $0xffffffff, -0xe8(%rbp) ; imm = 0xFFFFFFFF
0xffffff800078b56a <+74>: leaq -0x1d8(%rbp), %rdi
0xffffff800078b571 <+81>: movl $0xa0, %esi
0xffffff800078b576 <+86>: callq 0xffffff80001010f0 ; __bzero
0xffffff800078b57b <+91>: movq $0x0, -0x100(%rbp)
0xffffff800078b586 <+102>: movq $0x0, -0x108(%rbp)
0xffffff800078b591 <+113>: movq $0x0, -0x110(%rbp)
0xffffff800078b59c <+124>: movq $0x0, -0x118(%rbp)
0xffffff800078b5a7 <+135>: movq $0x0, -0x120(%rbp)
0xffffff800078b5b2 <+146>: movq $0x0, -0x128(%rbp)
0xffffff800078b5bd <+157>: movq $0x0, -0x130(%rbp)
0xffffff800078b5c8 <+168>: movzwl 0x1e(%r12), %r8d
0xffffff800078b5ce <+174>: movl 0x18(%r12), %edx Now, we should be in a good place to take our snapshot before something goes wrong. To do that, we simply need to use Fusion's "Snapshot" menu while the VM is stuck on a breakpoint.
VM snapshot state
As mentioned previously, the .vmsn file contains a virtual machine state. The file format is partially documented and we can use a modified version of Volatility (a patch is available in the repository).
Simply execute Volatility like so, making sure to point it at the correct `vmsn` file:
$ python2 ./vol.py -d -v -f ~/Virtual\ Machines.localized/macOS\ 11.vmwarevm/macOS\ 11-Snapshot3.vmsn vmwareinfoIt will spit out the relevant machine state in the JSON format that WTF expects. For example:
{
"rip": "0xffffff800078b556",
"rax": "0x715d862e57400011",
"rbx": "0xffffff904e51b000",
"rcx": "0xffffff80012f1860",
"rdx": "0xffffff904e51b000",
"rsi": "0xffffff904e51b000",
"rdi": "0xffffff904e51b000",
"rsp": "0xffffffe598ca3ab0",
"rbp": "0xffffffe598ca3c90",
"r8": "0x42",
"r9": "0x989680",
"r10": "0xffffff80010fdfb8",
"r11": "0xffffff96dbacd540",
"r12": "0xffffff904e51b000",
"r13": "0xffffffa0752ddbd0",
"r14": "0x0",
"r15": "0x0",
"tsc": "0xfffffffffef07619",
"rflags": "0x202",
"cr0": "0x8001003b",
"cr2": "0x104ca5000",
"cr3": "0x4513000",
"cr4": "0x3606e0",
"cr8": "0x0",
"dr0": "0x0",
"dr1": "0x0",
"dr2": "0x0",
"dr3": "0x0",
"dr6": "0xffff0ff0",
"dr7": "0x400",
"gdtr": {
"base": "0xfffff69f40039000",
"limit": "0x97"
},
"idtr": {
"base": "0xfffff69f40084000",
"limit": "0x1000"
},
"sysenter_cs": "0xb",
"sysenter_esp": "0xfffff69f40085200",
"sysenter_eip": "0xfffff69f400027a0",
"kernel_gs_base": "0x114a486e0",
"efer": "0xd01",
"tsc_aux": "0x0",
"xcr0": "0x7",
"pat": "0x1040600070406",
"es": {
"base": "0x0",
"limit": "0xfffff",
"attr": "0xc000",
"present": true,
"selector": "0x0"
},
"cs": {
"base": "0x0",
"limit": "0xfffff",
"attr": "0xa09b",
"present": true,
"selector": "0x8"
},
"ss": {
"base": "0x0",
"limit": "0xfffff",
"attr": "0xc093",
"present": true,
"selector": "0x10"
},
"ds": {
"base": "0x0",
"limit": "0xfffff",
"attr": "0xc000",
"present": true,
"selector": "0x0"
},
"fs": {
"base": "0x0",
"limit": "0xfffff",
"attr": "0xc000",
"present": true,
"selector": "0x0"
},
"gs": {
"base": "0xffffff8001089140",
"limit": "0xfffff",
"attr": "0xc000",
"present": true,
"selector": "0x0"
},
"ldtr": {
"base": "0xfffff69f40087000",
"limit": "0x17",
"attr": "0x82",
"present": true,
"selector": "0x30"
},
"tr": {
"base": "0xfffff69f40086000",
"limit": "0x67",
"attr": "0x8b",
"present": true,
"selector": "0x40"
},
"star": "0x001b000800000000",
"lstar": "0xfffff68600002720",
"cstar": "0x0000000000000000",
"sfmask": "0x0000000000004700",
"fpcw": "0x27f",
"fpsw": "0x0",
"fptw": "0x0",
"fpst": [
"0x-Infinity",
"0x-Infinity",
"0x-Infinity",
"0x-Infinity",
"0x-Infinity",
"0x-Infinity",
"0x-Infinity",
"0x-Infinity"
],
"mxcsr": "0x00001f80",
"mxcsr_mask": "0x0",
"fpop": "0x0",
"apic_base": "0x0"
}Notice that the above output contains all the same register content as our debugger shows but also contains MSRs, control registers, gdtr and others. This is all we need to be able to start running the snapshot under WTF.
Fuzzing harness and fixups
Our fuzzing harness needs to do a couple of things:
- Set a few meaningful breakpoints.
- A breakpoint on target function return so we know where to stop fuzzing.
- A breakpoint on the kernel exception handler so we can catch crashes.
- Other handy breakpoints that would patch things, or stop the test case if it reaches a certain state.
- For every test case, find a proper place in memory, write it there, and adjust the size.
All WTF fuzzers need to implement at least two methods:
bool Init(const Options_t &Opts, const CpuState_t &)bool InsertTestcase(const uint8_t *Buffer, const size_t BufferSize)
Init
Method Init does the fuzzing initialization steps, and this is where we would register our breakpoints.
To begin, we need the end of theip6_input function, which we will use as the end of execution:
(lldb) disassemble -n ip6_input
...
0xffffff800078cdf2 <+6354>: testl %ecx, %ecx
0xffffff800078cdf4 <+6356>: jle 0xffffff800078cfc9 ; <+6825> at ip6_input.c:1415:2
0xffffff800078cdfa <+6362>: addl $-0x1, %ecx
0xffffff800078cdfd <+6365>: movl %ecx, 0x80(%rax)
0xffffff800078ce03 <+6371>: leaq 0x989236(%rip), %rax ; __stack_chk_guard
0xffffff800078ce0a <+6378>: movq (%rax), %rax
0xffffff800078ce0d <+6381>: cmpq -0x30(%rbp), %rax
0xffffff800078ce11 <+6385>: jne 0xffffff800078d07f ; <+7007> at ip6_input.c
0xffffff800078ce17 <+6391>: addq $0x1b8, %rsp ; imm = 0x1B8
0xffffff800078ce1e <+6398>: popq %rbx
0xffffff800078ce1f <+6399>: popq %r12
0xffffff800078ce21 <+6401>: popq %r13
0xffffff800078ce23 <+6403>: popq %r14
0xffffff800078ce25 <+6405>: popq %r15
0xffffff800078ce27 <+6407>: popq %rbp
0xffffff800078ce28 <+6408>: retq
This function has only one ret, so we can use that. We'll add a breakpoint at 0xffffff800078ce28 to stop the execution of the test case:
Gva_t retq = Gva_t(0xffffff800078ce28);
if (!g_Backend->SetBreakpoint(retq, [](Backend_t *Backend) {
Backend->Stop(Ok_t());
})) {
return false;
}The above code sets up a breakpoint at the desired address, which executes the anonymous handler function when hit. This handler then stops the execution with Ok_t() type, which signifies the non-crashing end of the test case.
Next, we'll want to catch actual exceptions, crashes and panics. Whenever an exception happens in the macOS kernel, the function exception_triage` is called. Regardless if this was caused by something else or by an actual crash, if this function is called, we may as well stop test case execution.
We need to get the address of exception_triage first:
(lldb) p exception_triage
(kern_return_t (*)(exception_type_t, mach_exception_data_t, mach_msg_type_number_t)) $4 = 0xffffff8000283cb0 (kernel`exception_triage at exception.c:671)
(lldb)Now, we just need to add a breakpoint at 0xffffff8000283cb0:
Gva_t exception_triage = Gva_t(0xffffff8000283cb0);
if (!g_Backend->SetBreakpoint(exception_triage, [](Backend_t *Backend) {
const Gva_t rdi = Gva_t(g_Backend->Rdi());
const std::string Filename = fmt::format(
"crash-{:#x}", rdi);
DebugPrint("Crash: {}\n", Filename);
Backend->Stop(Crash_t(Filename));
})) {
return false;
}
This breakpoint is slightly more complicated as we want to gather some information at the time of the crash. When the breakpoint is hit, we want to get a couple of registers that contain information about the exception context we use to form a filename for the saved test case. This helps differentiate unique crashes.
Finally, since this is a crashing test case, the execution is stopped with Crash_t() which saves the crashing test case.
With that, the basic Init function is complete.
InsertTestcase
The function InsertTestcase is what inserts the mutated data into the target's memory before resuming execution. This is where you would sanitize any necessary input and figure out where you want to put your mutated data in memory.
Our target function's signature is ip6_input(struct mbuf *), so the mbuf struct will hold the actual data. We can use lldb at our first breakpoint to figure out where the data is:
(lldb) p m->m_hdr
(m_hdr) $7 = {
mh_next = 0xffffff904e3f4700
mh_nextpkt = NULL
mh_data = 0xffffff904e51b0d8 "`\U00000004\U00000003"
mh_len = 40
mh_type = 1
mh_flags = 66
}
(lldb) memory read 0xffffff904e51b0d8
0xffffff904e51b0d8: 60 04 03 00 04 00 3a 40 fe 80 00 00 00 00 00 00 `.....:@........
0xffffff904e51b0e8: 10 8f 08 a2 70 be 17 ba fe 80 00 00 00 00 00 00 ....p...........
(lldb) p (struct mbuf *)0xffffff904e3f4700
(struct mbuf *) $8 = 0xffffff904e3f4700
(lldb) p ((struct mbuf *)0xffffff904e3f4700)->m_hdr
(m_hdr) $9 = {
mh_next = NULL
mh_nextpkt = NULL
mh_data = 0xffffff904e373000 "\x80"
mh_len = 1024
mh_type = 1
mh_flags = 1
}
(lldb) memory read 0xffffff904e373000
0xffffff904e373000: 80 00 30 d7 02 69 00 00 62 b4 fd 25 00 0a 2f d3 ..0..i..b..%../.
0xffffff904e373010: 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA
(lldb)
At the start of ip6_input function, inspecting m_hdr of the first parameter shows us that it has 40 bytes of data at 0xffffff904e51b0d8 which looks like a standard ipv6 header. Additionally, grabbing mh_next and inspecting it shows that it contains data at 0xffffff904e373000 of size 1,024, which consists of ICMP6 data and our AAAAs.
To properly fuzz all IPv6 protocols, we'll mutate the IPv6 header and encapsulated packet. We'll need to separately copy 40 bytes over to the first mbuf and the rest over to the second mbuf.
For the second mbuf (the ICMPv6 packet), we need to write our mutated data at 0xffffff904e373000. This is fairly straightforward, as we don't need to read or dereference registers or deal with offsets:
bool InsertTestcase(const uint8_t *Buffer, const size_t BufferSize) {
if (BufferSize < 40) return true; // mutated data too short
Gva_t ipv6_header = Gva_t(0xffffff904e51b0d8);
if(!g_Backend->VirtWriteDirty(ipv6_header,Buffer,40)){
DebugPrint("VirtWriteDirtys failed\n");
}
Gva_t icmp6_data = Gva_t(0xffffff904e373000);
if(!g_Backend->VirtWriteDirty(icmp6_data,Buffer+40,BufferSize-40)){
DebugPrint("VirtWriteDirtys failed\n");
}
return true;
}
We could also update the mbuf size, but we'll limit the mutated test case size instead. And that's it – our fuzzing harness is pretty much ready.
Everything together
Every WTF fuzzer needs to have a state directory and three things in it:
- Mem.dmp: A full dump of RAM.
- Regs.json: A JSON file describing CPU state.
- Symbol-store.json: Not really required, can be empty, but we can populate it with addresses of known symbols, so we can use those instead of hardcoded addresses in the fuzzer.
Next, copy the snapshot's .vmm file over to your fuzzing machine and rename it to mem.dmp. Write the VM state that we got from volatility into a file called regs.json.
With the state set up, we can make a test run. Compile the fuzzer and test it like so:
c:\work\codes\wtf\targets\ipv6_input>..\..\src\build\wtf.exe run --backend=bochscpu --name IPv6_Input --state state --input inputs\ipv6 --trace-type 1 --trace-path .The debugger instance is loaded with 0 items
load raw mem dump1
Done
Setting debug register status to zero.
Setting debug register status to zero.
Segment with selector 0 has invalid attributes.
Segment with selector 0 has invalid attributes.
Segment with selector 8 has invalid attributes.
Segment with selector 0 has invalid attributes.
Segment with selector 10 has invalid attributes.
Segment with selector 0 has invalid attributes.
Trace file .\ipv6.trace
Running inputs\ipv6
--------------------------------------------------
Run stats:
Instructions executed: 13001 (4961 unique)
Dirty pages: 229376 bytes (0 MB)
Memory accesses: 46135 bytes (0 MB)
#1 cov: 4961 exec/s: infm lastcov: 0.0s crash: 0 timeout: 0 cr3: 0 uptime: 0.0s
c:\work\codes\wtf\targets\ipv6_input>In the above, we run WTF in run mode with tracing enabled. We want it to run the fuzzer with specified input and save a RIP trace file that we can then examine. As we can see from the output, the fuzzer run was completed successfully. The total number of instructions was 13,001 (4,961 of which were unique) and most notably, the run was completed without a crash or a timeout.
Analyzing coverage and symbolizing
WTF's symbolizer relies on the fact that the targets it runs are on Windows and that it generally has PDBs. Emulating that completely would be too much work, so I've opted to instead do some LLDB scripting and symbolization.
First, we need LLDB to dump out all known symbols and their addresses. That's fairly straightforward with the script supplied in the repository. The script will parse the output of image dump symtab command and perform some additional querying to resolve the most symbols. The result is a symbol-store.json file that looks something like this:
{"0xffffff8001085204": ".constructors_used",
"0xffffff800108520c": ".destructors_used",
"0xffffff8000b15172": "Assert",
"0xffffff80009e52b0": "Block_size",
"0xffffff80008662a0": "CURSIG",
"0xffffff8000a05a10": "ConfigureIOKit",
"0xffffff8000c8fd00": "DTRootNode",
"0xffffff8000282190": "Debugger",
"0xffffff8000281fb0": "DebuggerTrapWithState",
"0xffffff80002821b0": "DebuggerWithContext",
"0xffffff8000a047b0": "IOAlignmentToSize",
"0xffffff8000aa8840": "IOBSDGetPlatformUUID",
"0xffffff8000aa89e0": "IOBSDMountChange",
"0xffffff8000aa6df0": "IOBSDNameMatching",
"0xffffff8000aa87b0": "IOBSDRegistryEntryForDeviceTree",
"0xffffff8000aa87f0": "IOBSDRegistryEntryGetData",
"0xffffff8000aa87d0": "IOBSDRegistryEntryRelease",
"0xffffff8000ad6740": "IOBaseSystemARVRootHashAvailable",
"0xffffff8000a68e20": "IOCPURunPlatformActiveActions",
"0xffffff8000a68ea0": "IOCPURunPlatformHaltRestartActions",
"0xffffff8000a68f20": "IOCPURunPlatformPanicActions",
"0xffffff8000a68ff0": "IOCPURunPlatformPanicSyncAction",
"0xffffff8000a68db0": "IOCPURunPlatformQuiesceActions",
"0xffffff8000aa6d20": "IOCatalogueMatchingDriversPresent",
"0xffffff8000a04480": "IOCopyLogNameForPID",
"0xffffff8000a023c0": "IOCreateThread",
"0xffffff8000aa8c30": "IOCurrentTaskHasEntitlement",
"0xffffff8000a07940": "IODTFreeLoaderInfo",
"0xffffff8000a07a90": "IODTGetDefault",
"0xffffff8000a079b0": "IODTGetLoaderInfo",
"0xffffff8000381fd0": "IODefaultCacheBits",
"0xffffff8000a03f00": "IODelay",
"0xffffff8000a02430": "IOExitThread",
"0xffffff8000aa7830": "IOFindBSDRoot",
"0xffffff8000a043c0": "IOFindNameForValue",
"0xffffff8000a04420": "IOFindValueForName",
"0xffffff8000a03e30": "IOFlushProcessorCache",
"0xffffff8000a02580": "IOFree",
"0xffffff8000a029e0": "IOFreeAligned",
"0xffffff8000a02880": "IOFreeAligned_internal",
"0xffffff8000a02f60": "IOFreeContiguous",
"0xffffff8000a03c40": "IOFreeData",
"0xffffff8000a03840": "IOFreePageable",
"0xffffff8000a03050": "IOFreeTypeImpl",
"0xffffff8000a03cd0": "IOFreeTypeVarImpl",
"0xffffff8000a024b0": "IOFree_internal", The trace file we obtained from the fuzzer is just a text file containing addresses of executed instructions. Supporting tools include a symbolize.py script which uses a previously generated symbol store to symbolize a trace. Running it on ipv6.trace would result in a symbolized trace:
ip6_input+0x36
ip6_input+0x40
ip6_input+0x4a
ip6_input+0x51
ip6_input+0x56
bzero
bzero+0x3
bzero+0x5
bzero+0x6
bzero+0x8
ip6_input+0x5b
ip6_input+0x66
ip6_input+0x10b
ip6_input+0x127
ip6_input+0x129
ip6_input+0x12e
ip6_input+0x130
m_tag_locate
m_tag_locate+0x1
m_tag_locate+0x4
m_tag_locate+0x8
m_tag_locate+0xa
m_tag_locate+0x37
m_tag_locate+0x4b
m_tag_locate+0x4d
m_tag_locate+0x4e
ip6_input+0x135
ip6_input+0x138
ip6_input+0x145
ip6_input+0x148
ip6_input+0x14a
ip6_input+0x14f
ip6_input+0x151
m_tag_locate
m_tag_locate+0x1
m_tag_locate+0x4
m_tag_locate+0x8
m_tag_locate+0xa
m_tag_locate+0x14
...
lck_mtx_unlock+0x4e
lck_mtx_unlock+0x52
lck_mtx_unlock+0x54
lck_mtx_unlock+0x5a
lck_mtx_unlock+0x5c
lck_mtx_unlock+0x5e
ip6_input+0x1890
ip6_input+0x189b
ip6_input+0x18a2
ip6_input+0x18a5
ip6_input+0x18c0
ip6_input+0x18c7
ip6_input+0x18ca
ip6_input+0x18e3
ip6_input+0x18ea
ip6_input+0x18ed
ip6_input+0x18f1
ip6_input+0x18f7
ip6_input+0x18fe
ip6_input+0x18ff
ip6_input+0x1901
ip6_input+0x1903
ip6_input+0x1905
ip6_input+0x1907
ip6_input+0x1908The complete trace is longer, but at the end, can easily see that the retq instruction was reached if we compared the function offsets.
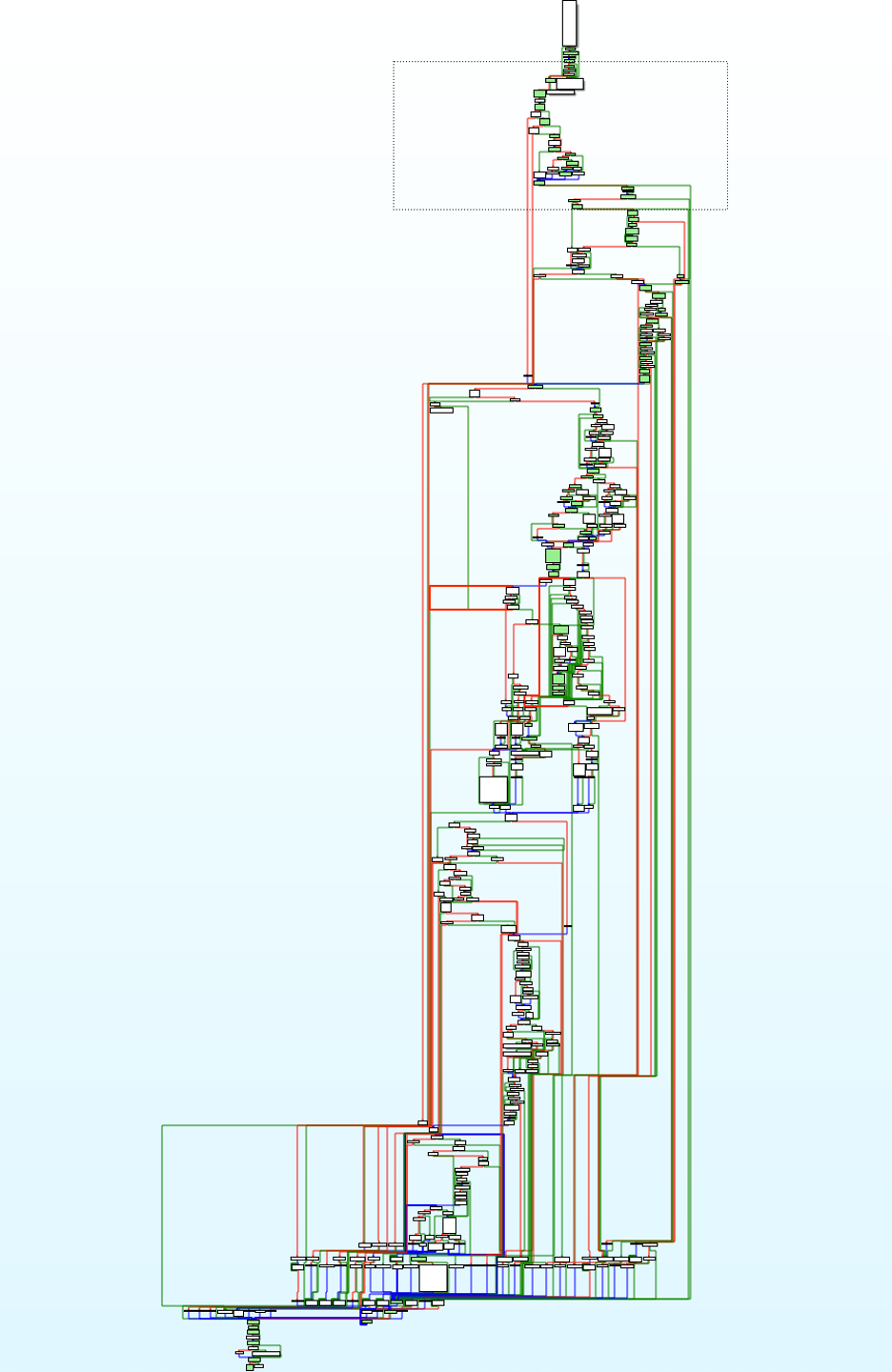
Trace files are also compatible with Ida Lighthouse, so we can just load them into it to get a visual coverage overview:
Avoiding checksum problems
Even without manual coverage analysis, with IPv6 as a target, it would be quickly apparent that a feedback-driven fuzzer isn’t getting very far. This is due to various checksums that are present in higher-level protocol packets, for example, TCP packet checksums. Randomly mutated data would invalidate the checksum and the packet would be rejected early.
There are two options to deal with this issue: We can fix the checksum after mutating the data, or leverage instrumentation to NOP out the code that performs the check. This is easily achieved by setting yet another breakpoint in the fuzzing harness that will simply modify the return value of the checksum check:
//patch tcp_checksum check
retq = Gva_t(0xffffff80125fbe57); //
if (!g_Backend->SetBreakpoint(retq, [](Backend_t *Backend) {
g_Backend->Rax(0);
})) {
return false;
}Running the fuzzer
Now that we know that things work, we can start fuzzing. In one terminal, we start the server:
c:\work\codes\wtf\targets\ipv6_input>..\..\src\build\wtf.exe master --max_len=1064 --runs=1000000000 --target .
Seeded with 3801664353568777264
Iterating through the corpus..
Sorting through the 1 entries..
Running server on tcp://localhost:31337..
And in another, the actual fuzzing node:
c:\work\codes\wtf\targets\ipv6_input> ..\..\src\build\wtf.exe fuzz --backend=bochscpu --name IPv6_Input --limit 5000000
The debugger instance is loaded with 0 items
load raw mem dump1
Done
Setting debug register status to zero.
Setting debug register status to zero.
Segment with selector 0 has invalid attributes.
Segment with selector 0 has invalid attributes.
Segment with selector 8 has invalid attributes.
Segment with selector 0 has invalid attributes.
Segment with selector 10 has invalid attributes.
Segment with selector 0 has invalid attributes.
Dialing to tcp://localhost:31337/..You should quickly see in the server window that coverage increases and that new test cases are being found and saved:
Running server on tcp://localhost:31337..
#0 cov: 0 (+0) corp: 0 (0.0b) exec/s: -nan (1 nodes) lastcov: 8.0s crash: 0 timeout: 0 cr3: 0 uptime: 8.0s
Saving output in .\outputs\4b20f7c59a0c1a03d41fc5c3c436db7c
Saving output in .\outputs\c6cc17a6c6d8fea0b1323d5acd49377c
Saving output in .\outputs\525101cf9ce45d15bbaaa8e05c6b80cd
Saving output in .\outputs\26c094dded3cf21cf241e59f5aa42a42
Saving output in .\outputs\97ba1f8d402b01b1475c2a7b4b55bc29
Saving output in .\outputs\cfa5abf0800668a09939456b82f95d36
Saving output in .\outputs\4f63c6e22486381b907daa92daecd007
Saving output in .\outputs\1bd771b2a9a65f2419bce4686cbd1577
Saving output in .\outputs\3f5f966cc9b59e113de5fd31284df198
Saving output in .\outputs\b454d6965f113a025562ac9874446b7a
Saving output in .\outputs\00680b75d90e502fd0413c172aeca256
Saving output in .\outputs\51e31306ef681a8db35c74ac845bef7e
Saving output in .\outputs\b996cc78a4d3f417dae24b33d197defc
Saving output in .\outputs\2f456c73b5cd21fbaf647271e9439572
#10699 cov: 9778 (+9778) corp: 15 (9.1kb) exec/s: 1.1k (1 nodes) lastcov: 0.0s crash: 0 timeout: 0 cr3: 0 uptime: 18.0s
Saving output in .\outputs\3b93493ff98cf5e46c23a8b337d8242e
Saving output in .\outputs\73100aa4ae076a4cf29469ca70a360d9
#20922 cov: 9781 (+3) corp: 17 (10.0kb) exec/s: 1.0k (1 nodes) lastcov: 3.0s crash: 0 timeout: 0 cr3: 0 uptime: 28.0s
#31663 cov: 9781 (+0) corp: 17 (10.0kb) exec/s: 1.1k (1 nodes) lastcov: 13.0s crash: 0 timeout: 0 cr3: 0 uptime: 38.0s
#42872 cov: 9781 (+0) corp: 17 (10.0kb) exec/s: 1.1k (1 nodes) lastcov: 23.0s crash: 0 timeout: 0 cr3: 0 uptime: 48.0s
#53925 cov: 9781 (+0) corp: 17 (10.0kb) exec/s: 1.1k (1 nodes) lastcov: 33.0s crash: 0 timeout: 0 cr3: 0 uptime: 58.0s
#65054 cov: 9781 (+0) corp: 17 (10.0kb) exec/s: 1.1k (1 nodes) lastcov: 43.0s crash: 0 timeout: 0 cr3: 0 uptime: 1.1min
#75682 cov: 9781 (+0) corp: 17 (10.0kb) exec/s: 1.1k (1 nodes) lastcov: 53.0s crash: 0 timeout: 0 cr3: 0 uptime: 1.3min
Saving output in .\outputs\00f15aa5c6a1c822b36e33afb362e9ecLikewise, the fuzzing node will show its progress:
The debugger instance is loaded with 0 items
load raw mem dump1
Done
Setting debug register status to zero.
Setting debug register status to zero.
Segment with selector 0 has invalid attributes.
Segment with selector 0 has invalid attributes.
Segment with selector 8 has invalid attributes.
Segment with selector 0 has invalid attributes.
Segment with selector 10 has invalid attributes.
Segment with selector 0 has invalid attributes.
Dialing to tcp://localhost:31337/..
#10437 cov: 9778 exec/s: 1.0k lastcov: 0.0s crash: 0 timeout: 0 cr3: 0 uptime: 10.0s
#20682 cov: 9781 exec/s: 1.0k lastcov: 3.0s crash: 0 timeout: 0 cr3: 0 uptime: 20.0s
#31402 cov: 9781 exec/s: 1.0k lastcov: 13.0s crash: 0 timeout: 0 cr3: 0 uptime: 30.0s
#42667 cov: 9781 exec/s: 1.1k lastcov: 23.0s crash: 0 timeout: 0 cr3: 0 uptime: 40.0s
#53698 cov: 9781 exec/s: 1.1k lastcov: 33.0s crash: 0 timeout: 0 cr3: 0 uptime: 50.0s
#64867 cov: 9781 exec/s: 1.1k lastcov: 43.0s crash: 0 timeout: 0 cr3: 0 uptime: 60.0s
#75446 cov: 9781 exec/s: 1.1k lastcov: 53.0s crash: 0 timeout: 0 cr3: 0 uptime: 1.2min
#84790 cov: 10497 exec/s: 1.1k lastcov: 0.0s crash: 0 timeout: 0 cr3: 0 uptime: 1.3min
#95497 cov: 11704 exec/s: 1.1k lastcov: 0.0s crash: 0 timeout: 0 cr3: 0 uptime: 1.5min
#105469 cov: 11761 exec/s: 1.1k lastcov: 4.0s crash: 0 timeout: 0 cr3: 0 uptime: 1.7minBuilding this snapshot fuzzing environment on top of WTF provides several benefits. It enables us to perform precisely targeted fuzz testing of, otherwise, hard-to-pinpoint chunks of macOS kernel. We can perform the actual testing on commodity CPUs, which enables us to use our existing computer resources instead of being limited to a few cores. Additionally, although emulated execution speed is fairly slow, we can leverage Bosch to perform more complex instrumentation. Patches to Volatility and WTF projects, as well as additional support tooling, is available in our GitHub repository.