2024-5-27 15:0:37 Author: hackernoon.com(查看原文) 阅读量:1 收藏
Authors:
(1) Zhihang Ren, University of California, Berkeley and these authors contributed equally to this work (Email: [email protected]);
(2) Jefferson Ortega, University of California, Berkeley and these authors contributed equally to this work (Email: [email protected]);
(3) Yifan Wang, University of California, Berkeley and these authors contributed equally to this work (Email: [email protected]);
(4) Zhimin Chen, University of California, Berkeley (Email: [email protected]);
(5) Yunhui Guo, University of Texas at Dallas (Email: [email protected]);
(6) Stella X. Yu, University of California, Berkeley and University of Michigan, Ann Arbor (Email: [email protected]);
(7) David Whitney, University of California, Berkeley (Email: [email protected]).
Table of Links
- Abstract and Intro
- Related Wok
- VEATIC Dataset
- Experiments
- Discussion
- Conclusion
- More About Stimuli
- Annotation Details
- Outlier Processing
- Subject Agreement Across Videos
- Familiarity and Enjoyment Ratings and References
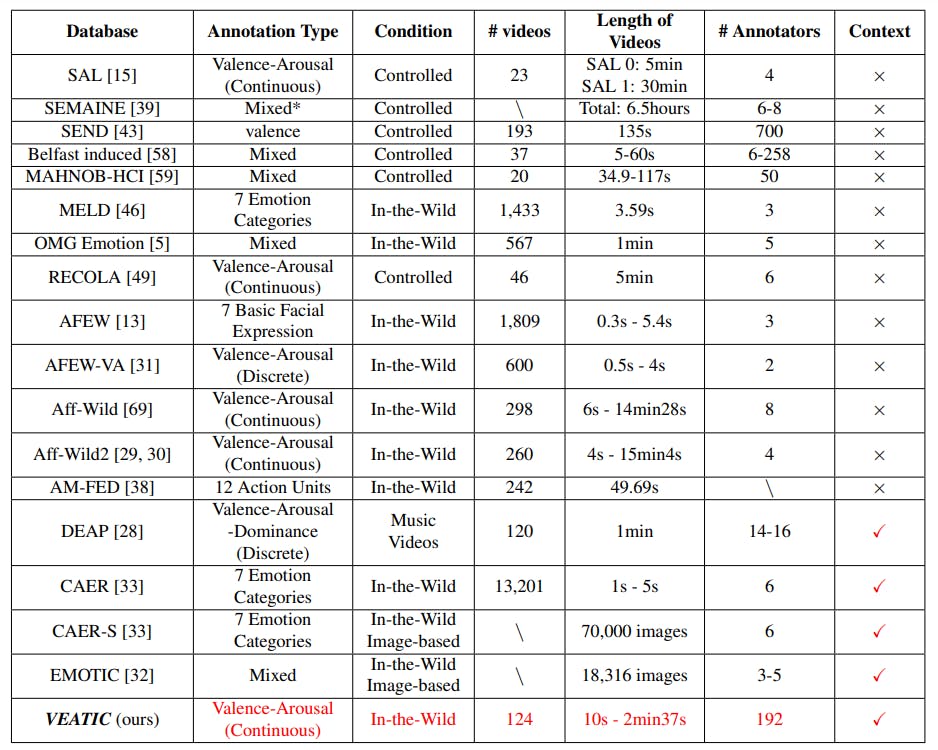
Recently, there have been several datasets that provide frames with both facial and context information, like CAER [33] and EMOTIC [32]. CAER [33] is a videobased dataset that contains categorical labels of each video frame, and EMOTIC [32] is an image-based dataset containing both categorical expression labels and continuous valence-arousal-dominance ratings. Unlike these datasets, our dataset is video-based and contains continuous valence and arousal ratings. A detailed comparison between our dataset with previous datasets can be found in Table 1.
Based on various emotion datasets, studies have started to focus on how to infer emotion automatically. Human affect can be inferred from many modalities, such as audio [70, 68, 65], visual [40, 54, 55, 37], and text [68, 22]. For visual inputs, in particular, there are three major tasks.

The valence-arousal estimation task aims to predict the valence and arousal of each image/frame [71, 69, 29, 30]; the expression recognition task focuses on classifying emotional categories of each image/frame [66, 57, 67]; and the action unit (AU) detection task intends to detect facial muscle actions from the faces of each image/frame [25, 56, 35, 64]. Currently, most proposed methods rely highly on the facial area to infer the emotional state. Indeed, the facial area contains rich information about the human emotional state. However, contextual factors also provide essential information that is necessary for humans to correctly infer and perceive the emotional states of others [8, 9, 10]. Several studies [33, 32, 40] have started to incorporate context information as a source of affect inference. In this study, we also adopted both facial and context information to achieve the new task, i.e., to infer the valence and arousal for each video frame.
To infer the affect of a person, we usually need to deal with temporal information of either audio segments, video frames, or words. Many studies [68, 69, 29, 30] started to utilize long short term memory (LSTM) [23], gated recurrent unit (GRU) [11], or recurrent neural network (RNN) [24, 50] to process the temporal information. With the emergence of the visual transformer (ViT) [14], attention has been shifted. Many video understanding tasks [19, 1, 36] have utilized ViT for temporal information understanding and achieving state-of-the-art performance. Our baseline method also adopted ViT as a tool to process the temporal information in video clips.
如有侵权请联系:admin#unsafe.sh