Table of Links
Conclusion, Reproducibility, and References
D. Nuances comparing prior work
2 DATASET DESIGN
2.1 PLUGINS AND TOOLS
ToolTalk is designed for a paradigm where individual users will be able to customize a personal assistant with a number of plugins available through various online stores. This can be seen as similar to how a user might customize their phone with apps of various functionality. Each plugin contains a set of tools designed around a single purpose such as managing a calendar, buying movie tickets, or listening to music. We define a tool as a single function needed to accomplish that purpose such as creating an event, searching for movies, or playing a song. We assume that most plugins will need to contain multiple tools. For example, a theoretical “Calendar” plugin should not only have the ability to create events, but also to then search, modify, and delete these events.
For our dataset, we defined 7 plugins containing a total of 28 tools (see Appendix A for the full list). Using similar domains as those in Li et al. (2023), we created the following plugins:
• AccountTools: containing tools for account management such as logging in and out, updating account information, or looking up other users.
• Alarm: adding, deleting, and finding alarms.
• Calendar: creating, modifying, deleting, and searching events and meetings
• Email: searching inbox and sending emails
• Message: sending and reading messages from other users

• Reminder: setting, completing, and deleting reminders on a to do list
• Weather: querying current weather, weather forecasts, and historic weather data based on location
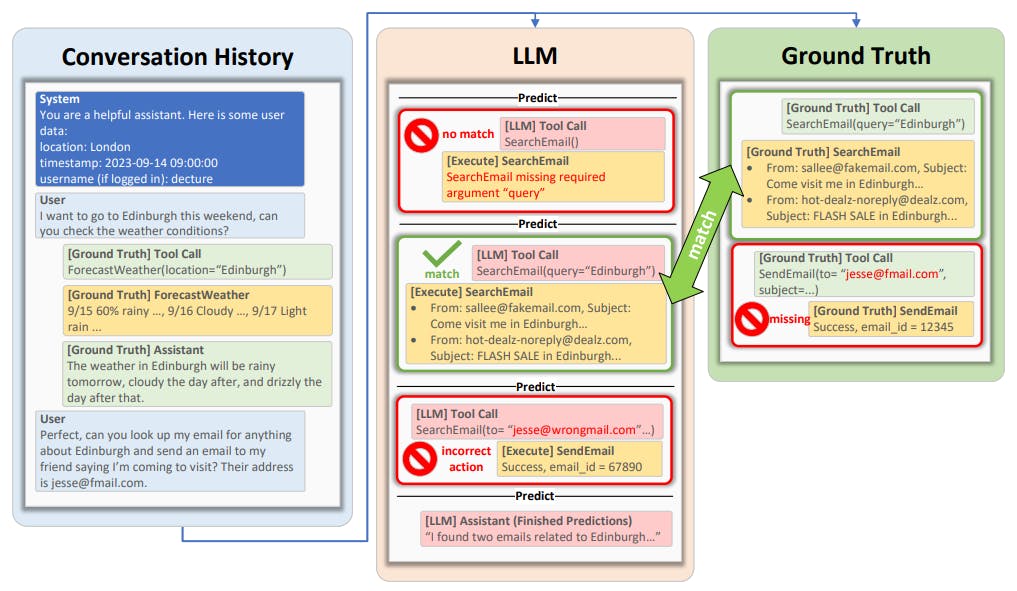
To teach the LLM about how to use the tools, each tool contains a high-level description, verbose documentation about each of its parameters, and a description of its return value. To facilitate evaluation, each tool has a simulated implementation in Python, along with a method to judge whether two invocations of the same tool with different parameters should be considered equivalent. We also note for each tool whether it is considered an action (has side effects) or not. We also include accompanying databases with mock information about fictional existing users, emails, reminders, and so on, for the simulated tool implementations to use.
2.2 CREATING CONVERSATIONS
To help create realistic conversations that exercise our tools and plugins, we used GPT-4. For each subset of 3 plugins from the 7 plugins we have defined, we create prompts which lists the documentation for all the tools in these 3 plugins, and instructs GPT-4 to create 3 realistic scenarios involving a user trying to accomplish a task that uses at least 5 tool calls from the random subset of plugins. We create as many prompts as the number of tools that exist in the subset of 3 plugins currently under consideration, such that each prompt instructs GPT-4 to specifically use one of the tools in the subset of 3 plugins. We provide the prompt template used in Appendix B.
The above procedure results in the generation of ∼400 scenarios. We then repeatedly sampled a scenario evenly from all tools, discarding sampled scenarios that do not involve the required tool, hallucinate non-existent tools, or seem implausible. Using a sampled scenario as general guidance, we manually create a conversation, writing down all of its parts by hand.
Each conversation consists of a user utterance, the tool calls that the assistant should make given that utterance, the expected return values for those calls, and the assistant’s natural language responses given the user’s utterances plus the tool calls and their results, repeating in that order until the conversation is finished. As metadata for the conversation, we also specified a timestamp for the conversation, and the user’s location and username.[1] We ensure that each conversation contains at least 3 tool calls. We repeat the above sampling of scenarios until we have written 50 conversations.
Additionally, we create 28 “easy” conversations completely by hand, one for each tool. This easy version of ToolTalk consists of a few turns of user-assistant dialogue followed by a single tool call. Combined with the prior 50 “hard” examples, we create a total of 78 conversations comprising ToolTalk.
After constructing conversations, we ensure that the databases used by our simulated tool implementations contain the necessary content so that when we execute the ground truth tool calls as listed in the conversations we have created, they return the same ground truth values.
[1] For scenarios that use tools such as UserLogin or RegisterAccount, we omit the username to simulate a user that has yet to log in or have an account.
如有侵权请联系:admin#unsafe.sh