2024-5-25 22:22:56 Author: www.freebuf.com(查看原文) 阅读量:6 收藏
本篇文章主要讲述口令猜解问题的不同应用场景,以及论文Password Guessing using Random Forest(RFGuess)的核心思想,对论文中基于PII的定向猜解的相关算法进行复现,并实现成一个生成社工字典的GUI工具。
原论文地址:https://www.usenix.org/conference/usenixsecurity23/presentation/wang-ding-password-guessing
Repo地址:https://github.com/PadishahIII/RFGuess
PPT:https://www.wolai.com/secnote/row4spm7VvaYAkUmxsFQBT
建议搭配PPT阅读。
Password Guessing using Random Forest 发表于2023年8月,首次提出了用传统机器学习模型处理口令猜解问题,并实现了三种应用场景的口令猜解模型,在现有模型中能达到较好的效果。
口令猜解问题可以分为离线猜解和在线猜解,离线猜解只有计算性能的限制条件,而在线猜解针对的是运行中的系统,往往有尝试次数、网络性能方面的限制(以下内容均面对在线猜解场景)。
Trawling guessing 拖网猜解
拖网猜解的意思是,攻击者没有特定的目标,尽量多地猜出密码。现有的统计模型有PCFG(probabilis-tic context-free gramma)、Markov模型,后面的很多模型都是基于Markov模型改进的,包括本文复现的这篇。现有的深度学习模型有FLA、基于生成对抗网络的PassGAN,深度学习模型需要更庞大的训练集(至少千万级)和更长的训练时间。
Targeted guessing based on PII 基于PII的定向猜解
PII(personal identifiable information)即个人信息,如姓名、生日、手机号码、身份证号等。定向猜解的目标是破解某一系统中某个用户的密码,有很强的针对性,在线猜解的场景下往往存在很多限制条件,我们要使用尽量少的猜解去破解密码。定向猜解领域处于发展初期,这篇论文的作者曾基于Markov模型提出过一个名为Targeted Markov的定向猜解模型,后来作者发现这些基于长度匹配PII的方法存在很大限制,于是提出基于类型(type-based)的PII匹配方法,即TarGuess-Ⅰ模型(2016年提出)。
Targeted guessing based on password reuse
基于密码复用的定向猜解指的是,已知一个人曾经用过的密码,通过施加一些变换猜测现在使用的密码,比如插入、删除字符、leet变换等。统计模型有TarGuess-II,深度学习模型有Pass2Path。
口令猜解问题可以视作一个特殊的多分类问题,但比常规多分类问题需要更高准确率,如果按照一般分类问题处理,就需要更大的数据集来达到基本的准确率要求。目前的口令猜解模型通常是基于统计或者深度学习实现的,基于统计的模型天然具有过拟合的弊端,深度学习模型则需要庞大的训练集(至少千万级)以及相当久的训练时间。于是,基于机器学习的口令猜解模型RFGuess应运而生,很好地克服了以上两种模型的弊端,并达到相当高的准确率。
Markov模型
Markov n元模型提出一个假设:密码中的每一个字符只和前面n个字符有关,而和其他字符无关。以Markov模型为基础,我们可以将口令猜解问题转化成多分类问题,把某个字符前面的n个字符视作特征,该字符视作类别。这样所有监督学习方法都可以应用在口令猜解问题上。因为特征的维度低,又需要达到很高的准确率,所以集成学习方法更加适用。本篇论文使用随机森林进行模型训练。
随机森林
随机森林由多个决策树组成,当预测一个样本的类别时,这个算法会让每一棵决策树投票,用票数最多的类别作为最终的预测结果。为了保证这些决策树各不相同,训练模型时会为每棵决策树随机选择特征和样本。
决策树有三种主流的划分节点的方法:ID3, C4.5, CART,划分标准分别是信息增益、信息增益率、Gini指数。其中Gini指数最为直观,计算起来最为简单,可以有效降低训练时间,所以本篇论文选择Gini指数。(Gini指数(Gini impurity)指的是,在集合中随机选择两个样本,这两个样本类别不同的概率)
提取特征
基本思想
首先我们需要将密码分割,主要有两种思想,length-based思想主要在trawling guessing场景适用,type-based思想是前者的改进,以更好地应用在基于PII的场景中。对于基于长度(length-based)的口令猜解模型(如PCFG),密码会被解析成若干个段,数字段用D表示,字母段用L,特殊字符段用S,然后用下标表示段的长度,如L8表示连续8个字母组成的段,如此一来,Password123!会编码成L8D3S1。基于类型(type-based)的口令猜解模型依然会把密码解析成若干个段,但是段的下标表示的是段的类型,例如,我们用N表示"姓名"这一种个人信息,用N1表示全名,N2表示姓氏,N3表示名字,用B表示"生日",B1表示YYYYMMDD格式的生日,B2表示MMDD格式的生日,那么密码字符串zhangsan0908就可以编码成N1B2,同时也可以编码成N2N3B2,而对于密码中不属于个人信息的字符则保留该字符的原始特征。
Trawling guessing
在拖网猜解中,我们会把字符转化成一个4维向量,各个维度描述如下:
- 字符类型: 0,1,2,3分别表示特殊字符,数字,大写字母和小写字母
- 字符的序列值:如a~z用1~26表示,数字1~9用1~9表示
- 键盘所在行数:如数字1在第一行,字母q在第二行
- 键盘所在列数:如数字1在第一列,字母w在第二列
如此,我们把字符编码成了一个4维向量。根据Markov模型,我们假设密码中的字符只和前面的6个字符有关,即6元Markov模型。我们将密码分成若干个数据元(datagram),每个数据元由6个字符组成,例如pass123456的数据元集合为: BsBsBsBsBsp , BsBsBsBspa , ... , passEsEs (Bs表示开始符号,Es表示结束符号) 。现在数据元可以编码成24维向量(6×4=24),我们再加入两个维度:
数据元在密码字符串中的位置:如
s12345在pass123456中处于第9位数据元在LDS段中的位置:如
pass123456属于L4D6,数据元s12345在D段的第5位于是,我们首先将一个密码解析成若干个数据元,然后每个数据元被编码成一个26维向量,作为特征值。
数据元的标签就是它在密码中的下一个字符,将该字符按照上述方式编码成4维向量。
Targeted guessing based on PII
基于长度的思想并不能很好地提取出密码中的PII特征,但我们只需要做一些修改即可实现基于类型的特征提取方法。我们在此节简单介绍了基于类型的PII匹配方式,用字母表示PII类型,数字表示更加细化的PII类型,如N表示姓名这一PII类型,N1表示全名,N3表示姓氏,后面两者都属于姓名信息。其他编码可以在这里查看。将这样的数据元转化成特征向量是很简单的,把N1编码成1001,N2编码成1002,B1编码成2001,依次类推。 一个密码可能有多种表示方式(Representation, i.e. Rep),如zhangsan0908就可以编码成N1B2,同时也可以编码成N2N3B2,所以我们要选择一种。直观上,我们要选频率最高的编码,每确定一个密码的编码,就将它的频数减一,然后继续编码其他密码。 计算特征向量的方式和上一节类似,我们将上面的N1、N2定义为PII Tag,将Tag转化成4维向量:Tag类型、值、键盘行列数,键盘行列数取0,N1会转化成(1000, 1, 0, 0)。最终我们仍然将数据元转化成26维向量。
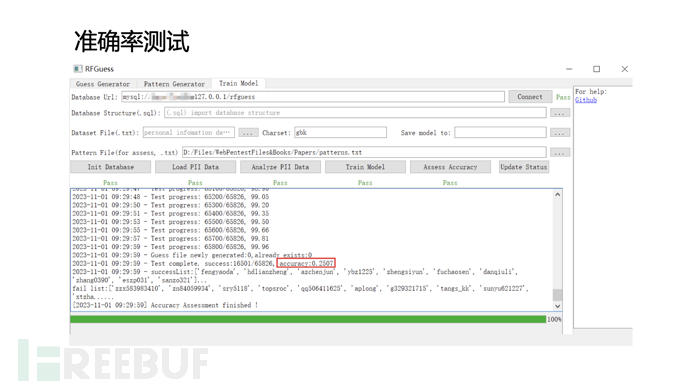
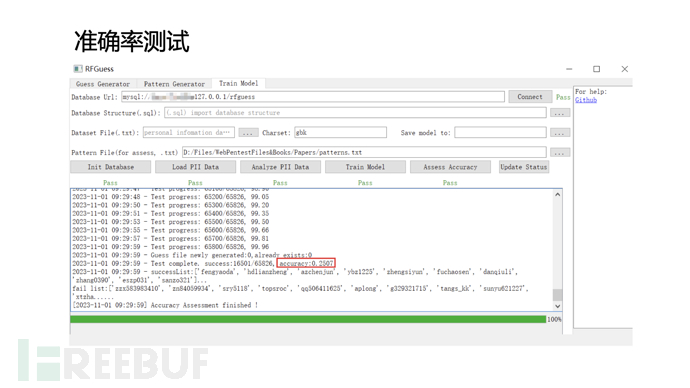
我对论文中Targeted guessing based on PII这一场景的算法进行了复现,并实现了一个社工字典生成工具,用GUI可视化训练过程,工具地址:RFGuess. 工具的用法在Readme中已经介绍很详细了。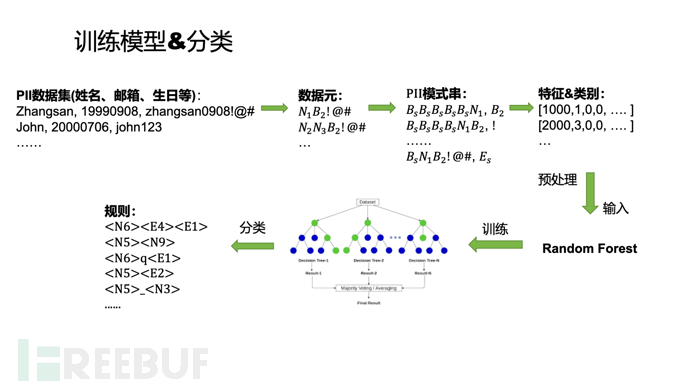
工具执行过程:
数据集->转化成特征向量->训练模型->生成规则->生成字典 (->测试准确率)
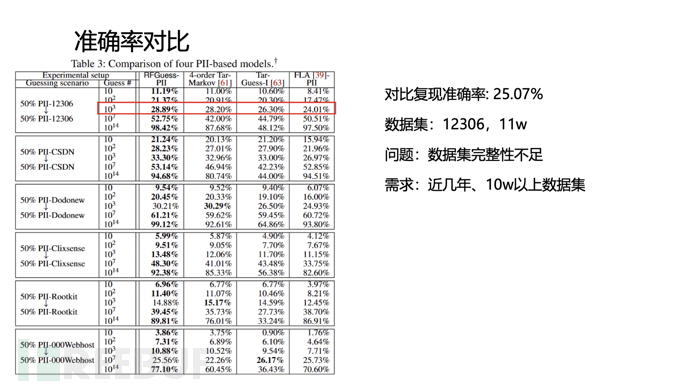
准确率对比
| 数据集 | 字典大小 | 工具准确率 | 论文准确率 |
|---|---|---|---|
| 50% PII-12306 → 50% PII-12306 | 1000 | 25.07% | 28.89% |
如有侵权请联系:admin#unsafe.sh