#人工智能 斯坦福大学 Llama3-V 团队的抄袭者发布公开道歉声明,删除相关抄袭内容同时称他们也是被骗了,他们是被另一个名为 Mustafa 的人骗了 (目前处于失联状态)。不过具体是三人合谋还是两人被骗,这内情可能还需要再等等后续。查看全文:https://ourl.co/104276
此前清华大学的 AI 团队与国内人工智能初创公司面壁智能训练并开源了 MiniCPM 系列模型,这包括面向图文理解的多模态模型 MiniCPM-V 系列,这些模型在开源框架下供全球的 AI 研究团队使用。
不过从 2024 年 5 月 29 日开始,自称为斯坦福大学 Llama3-V 的人工智能团队高调宣传仅需 500 美元就可以训练超越 OpenAI GPT-4V 的 SOTA 多模态模型。
两名作者分别是 Siddharth Sharma 和 Aksh Garg (均为斯坦福大学计算机科学本科生),在高调宣传的同时有网友发现他们推出的 Llama3-V 模型的结构和代码与面壁智能早前推出补救的 MiniCPM-Llama3-V2.5 非常类似,看起来仅对部分变量名称进行了修改和替换。
该事件经过发酵后也引起了面壁智能的关注,该公司发布回应证实斯坦福大学的这个项目确实和 MiniCPM 模型一样,可以识别出清华简(清华大学获捐的战果竹简)战国古文字,这部分古文字为研究团队从清华简上逐字扫描并经由人工标注得来。
斯坦福大学 Llama3-V 团队的这种行为显然已经属于明显的抄袭了,实际上 MiniCPM 提供开源模型,基于开源模型构建新模型是个很正常的操作,但如果只是下载别人的模型简单替换下名称就说是自己训练的,这就属于抄袭行为了。
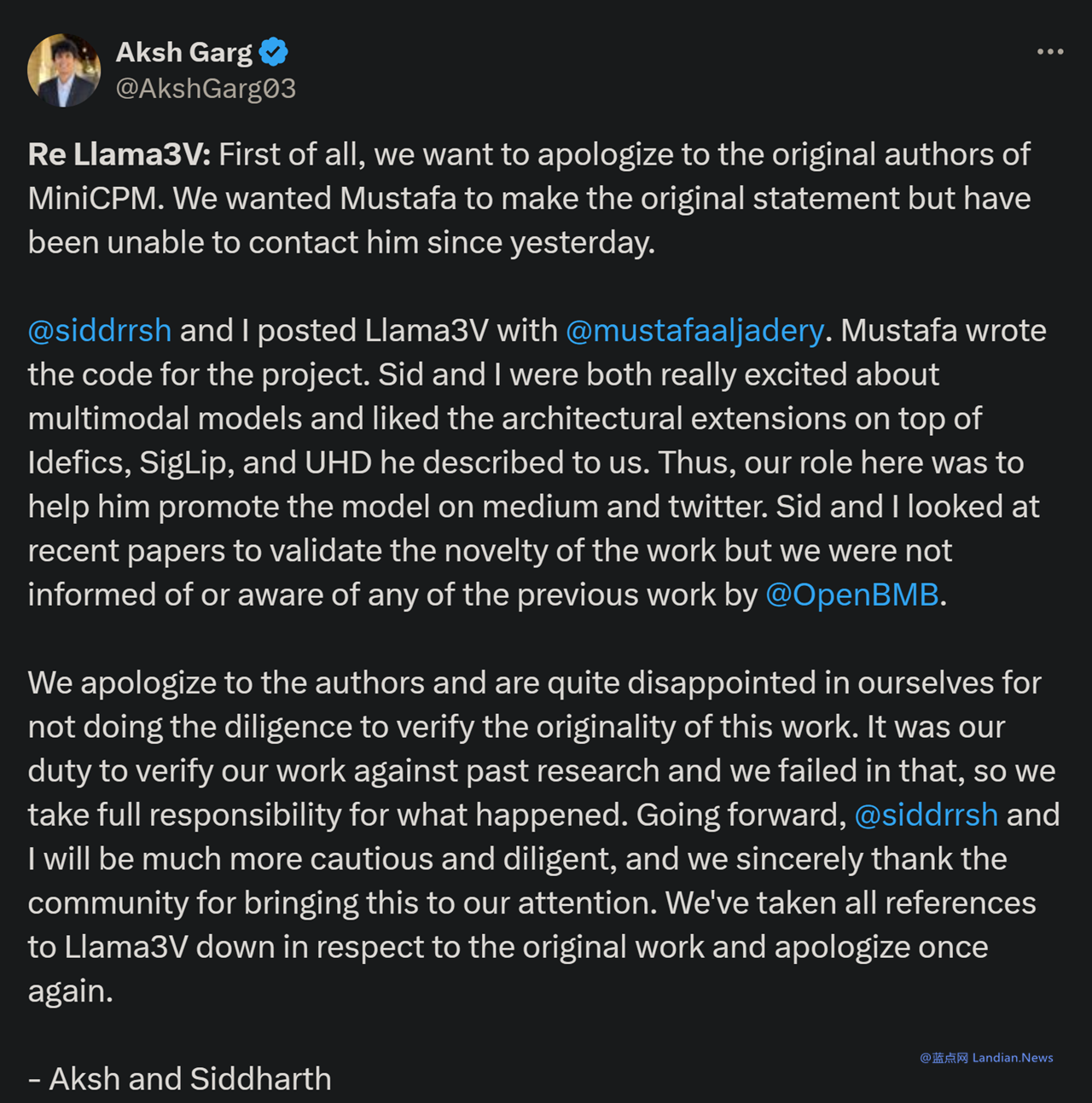
昨天夜里抄袭的两名成员在其 X/Twitter 账号上发布致歉信,不过在致歉信中两名成员指出他们引用的是另一名研究人员编写的代码,这名研究人员名为 Mustafa Aljadery。
于是这两人帮助 Mustafa 在 Medium 和 X/Twitter 上推广这个模型,他们自称没有完整尽职调查也就是没有发现 Mustafa 发布的模型是抄袭面壁智能的。
而 Mustafa 则将自己的 X/Twitter 设置为受保护状态,没有发布任何回应 (而且现在也处于失联状态),所以不清楚这是三人合谋还是两人被 Mustafa 骗了。