2024-6-5 20:30:31 Author: hackernoon.com(查看原文) 阅读量:0 收藏
Authors:
(1) Sasun Hambardzumyan, Activeloop, Mountain View, CA, USA;
(2) Abhinav Tuli, Activeloop, Mountain View, CA, USA;
(3) Levon Ghukasyan, Activeloop, Mountain View, CA, USA;
(4) Fariz Rahman, Activeloop, Mountain View, CA, USA;.
(5) Hrant Topchyan, Activeloop, Mountain View, CA, USA;
(6) David Isayan, Activeloop, Mountain View, CA, USA;
(7) Mark McQuade, Activeloop, Mountain View, CA, USA;
(8) Mikayel Harutyunyan, Activeloop, Mountain View, CA, USA;
(9) Tatevik Hakobyan, Activeloop, Mountain View, CA, USA;
(10) Ivo Stranic, Activeloop, Mountain View, CA, USA;
(11) Davit Buniatyan, Activeloop, Mountain View, CA, USA.
Table of Links
- Abstract and Intro
- Current Challenges
- Tensor Storage Format
- Deep Lake System Overview
- Machine Learning Use Cases
- Performance Benchmarks
- Discussion and Limitations
- Related Work
- Conclusions, Acknowledgement, and References
7. DISCUSSION AND LIMITATIONS
Deep Lake’s primary use cases include (a) Deep Learning Model Training, (b) Data Lineage and Version Control, (c) Data Querying, and Analytics, (d) Data Inspection and Quality Control. We took NumPy [55] arrays as a fundamental block and implemented
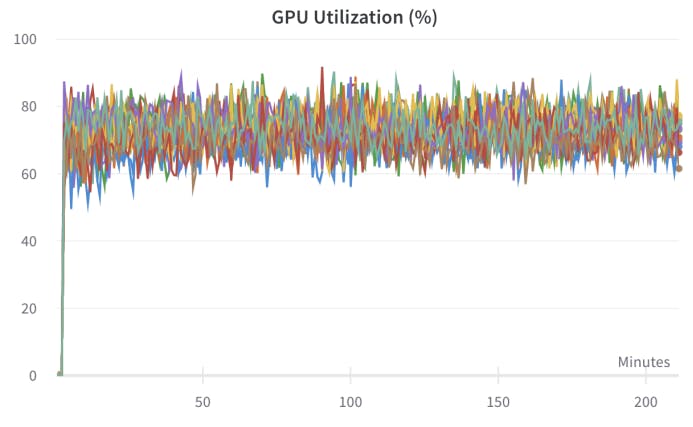
![Figure 10: GPU utilization of single 16xA100 GPU machine while training 1B parameter CLIP model [60]. The dataset is LAION-400M [68] streaming from AWS us-east to GCP us-central datacenter. Each color demonstrates single A100 GPU utilization over training.](https://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-za83u00.png?auto=format&fit=max&w=1920)
version control, streaming dataloaders, visualization engine from scratch.
7.1 Format Design Space
The Tensor Storage Format (TSF) is a binary file format designed specifically for storing tensors, which are multi-dimensional arrays of numerical values used in many machine learning and deep learning algorithms. The TSF format is designed to be efficient and compact, allowing for fast and efficient storage and access of tensor data. One key advantage of the TSF format is that it supports a wide range of tensor data types, including dynamically shaped tensors.
In comparison, the Parquet [79] and Arrow [13] formats are columnar file formats that are designed for storing and processing large analytical datasets. Unlike TSF, which is specifically designed for tensor data, Parquet and Arrow are optimized for efficient storage and querying of analytical workloads on tabular and time-series data. They use columnar storage and compression techniques to minimize storage space and improve performance, making them suitable for big data applications. However, TSF has some advantages over Parquet and Arrow when it comes to tensor data. TSF can support tensor operations and efficient streaming to deep learning frameworks.
Other tensor formats [18, 52, 23, 57] are efficient for massively massively parallelizable workloads as they don’t require coordination across chunks. Tensor Storage Format key trade-off is enabling to store dynamically shape arrays inside a tensor without padding memory footprint. For example, in computer vision it is very common to store multiple images with different shapes or videos have dynamic length. To support the flexibility, minor overhead is introduced in the form of previously discussed chunk encoder that in practice we haven’t observed impact on production workloads.
7.2 Dataloader
Deep Lake achieves state-of-the-art results in local and remote settings, as seen in benchmarks for iterating on large images Fig. 7. Primarily, it has been faster than FFCV [39], which claimed a reduction of ImageNet model training up to 98 cents per model training. Furthermore, Deep Lake achieves similar ingestion performance to WebDataset [19]. Deep Lake significantly outperforms on larger images. Parquet is optimized for small cells and analytical workloads, while Deep Lake is optimized for large, dynamically shaped tensorial data. Compared to other data lake solutions, its minimal python package design enables Deep Lake to be easily integrated into large-scale distributed training or inference workloads.
7.3 Future work
The current implementation of Deep Lake has opportunities for further improvement. Firstly, the storage format does not support custom ordering for an even more efficient storage layout required for vector search or key-value indexing. Secondly, Deep Lake implements branch-based locks for concurrent access. Similar to Delta ACID transaction model [27], Deep Lake can be extended to highlyperformant parallel workloads. Thirdly, the current implementation of TQL only supports a subset of SQL operations (i.e., does not support operations such as join). Further work will focus on making it SQL-complete, extending to more numeric operations, running federated queries in external data sources and benchmarking against SQL engines.
如有侵权请联系:admin#unsafe.sh