#人工智能 阿里云推出通义千问 Qwen2 系列模型,完全开源,提供 0.5B~72B 之间 5 个版本,在各项评测中表现不俗。有兴趣的开发者现在就可以通过 GitHub 等平台获取最新模型。查看全文:https://ourl.co/104358
阿里云今天推出了通义千问人工智能模型的重大升级版本:Qwen2,该模型提供 5 个不同的尺寸、上下文长度最高支持 128K tokens,并且在各项测试中表现不俗。
Qwen2 的所有尺寸版本均已同步在 GitHub、HuggingFace 和 ModelScope 上开源,有兴趣的开发者可以立即获取模型进行测试。

此次发布的新版本亮点包括:
- 能力较此前版本有较大幅度提升,在开源模型测试中名列前茅
- 提供 5 个预训练和指令微调模型,包括 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 和 Qwen2-72B
- 在编程领域和数学方面的能力显著提高
- 增加上下文长度,现在最高支持 128K tokens
- 在中文和英语的基础上,增加 27 种语言相关的数据进行训练
在 Qwen1.5 系列模型中只有 32B 和 110B 版使用 GQA,而在 Qwen2 中所有模型都使用 Qwen2,使用 GQA 后有助于提升推理能力和降低显存的占用。
同时诸如 Qwen2-0.5B 和 1.5B 版可以在性能更低的设备上运行,例如在智能手机本地运行 Qwen2-0.5B 而不需要云端处理,这种也是未来的趋势,未来可能所有智能设备都会支持 AI,这就需要更小的模型为本地运行提供支持。
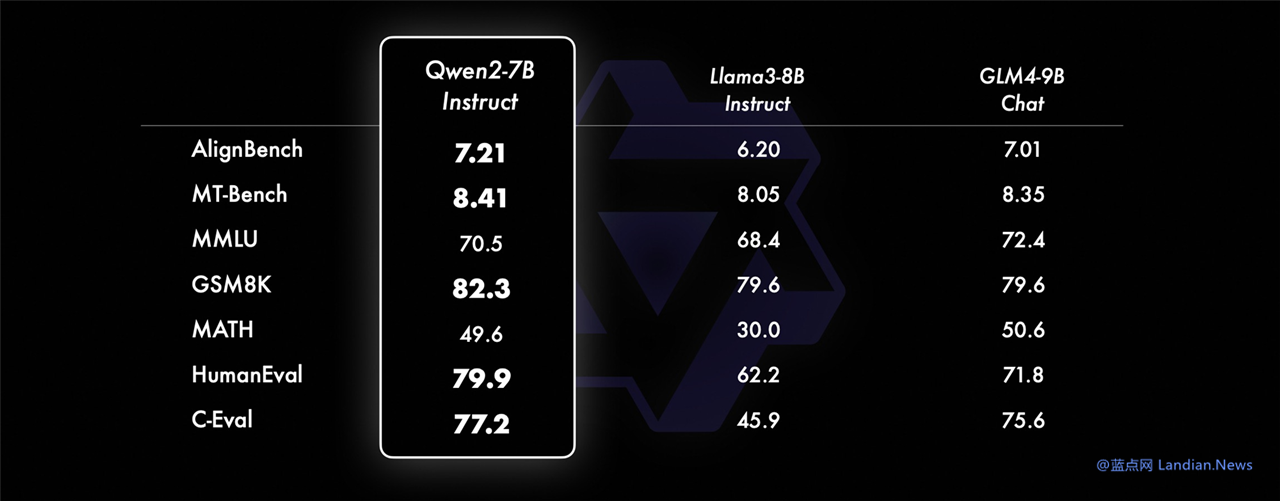
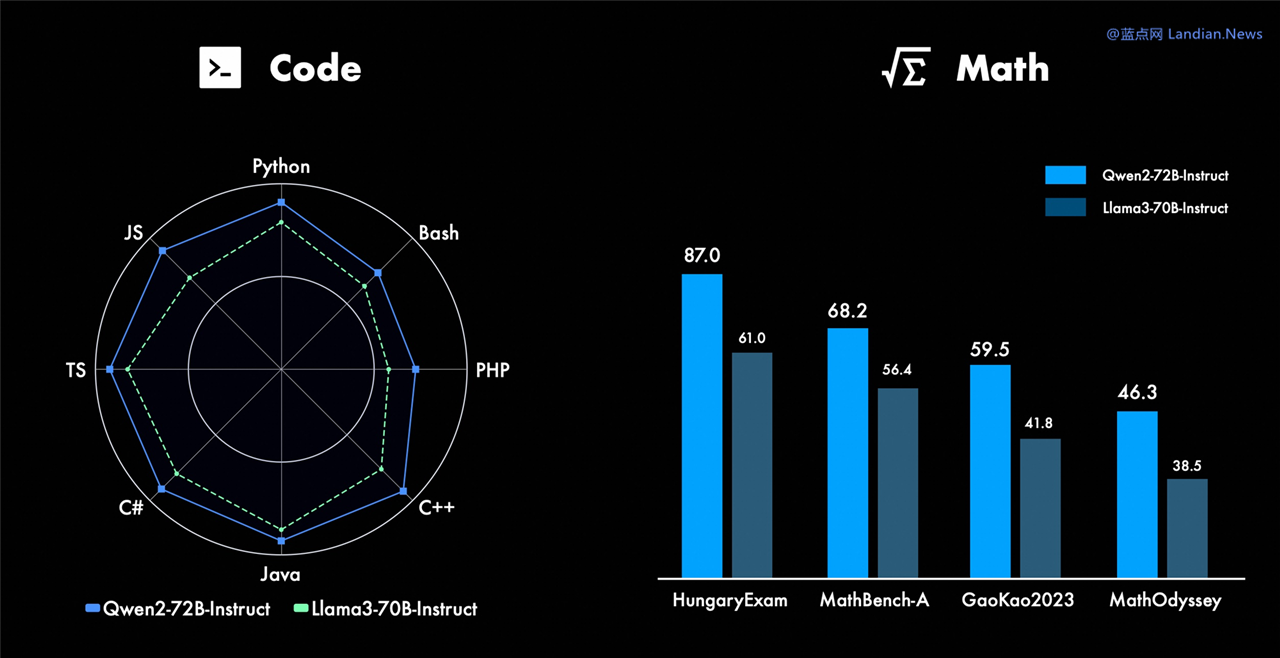
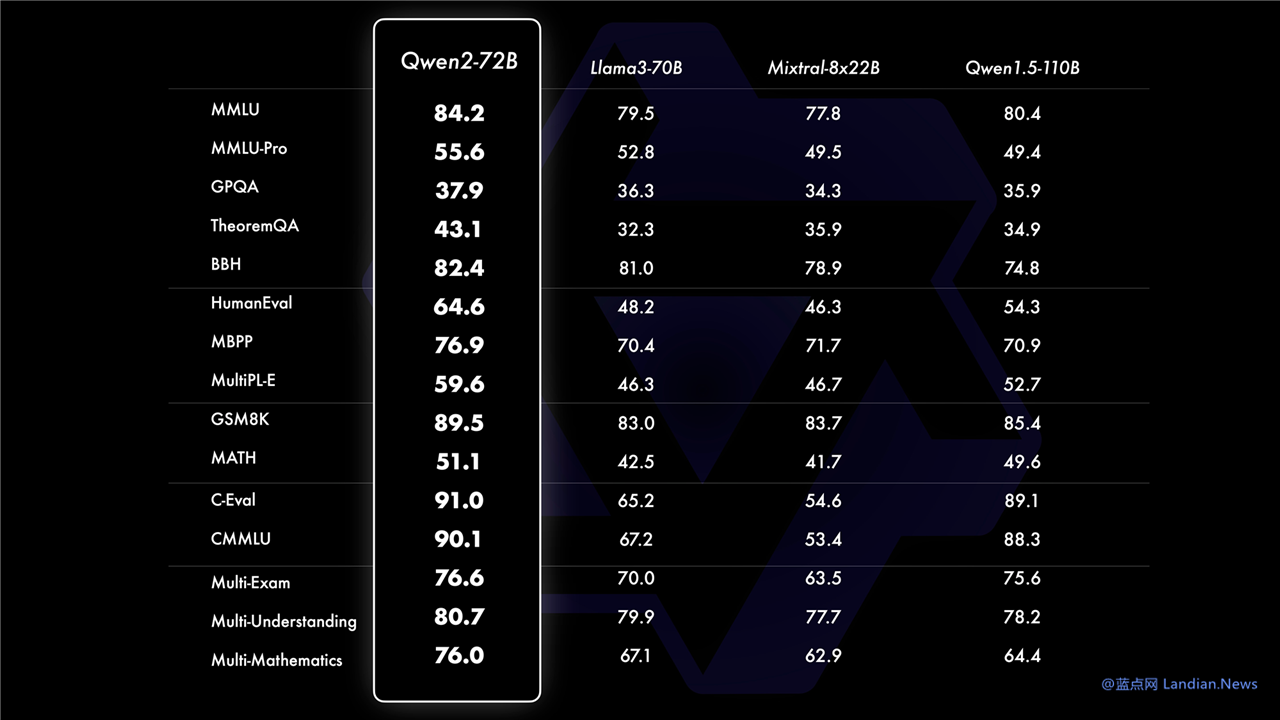
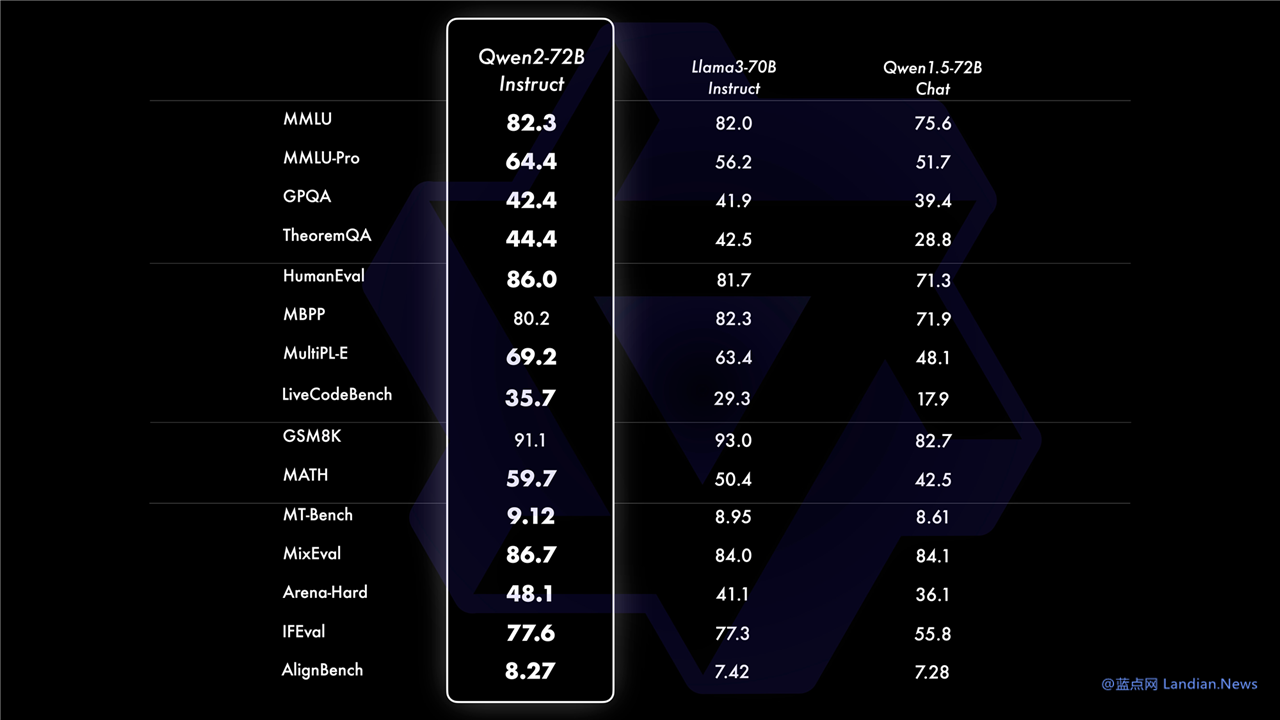
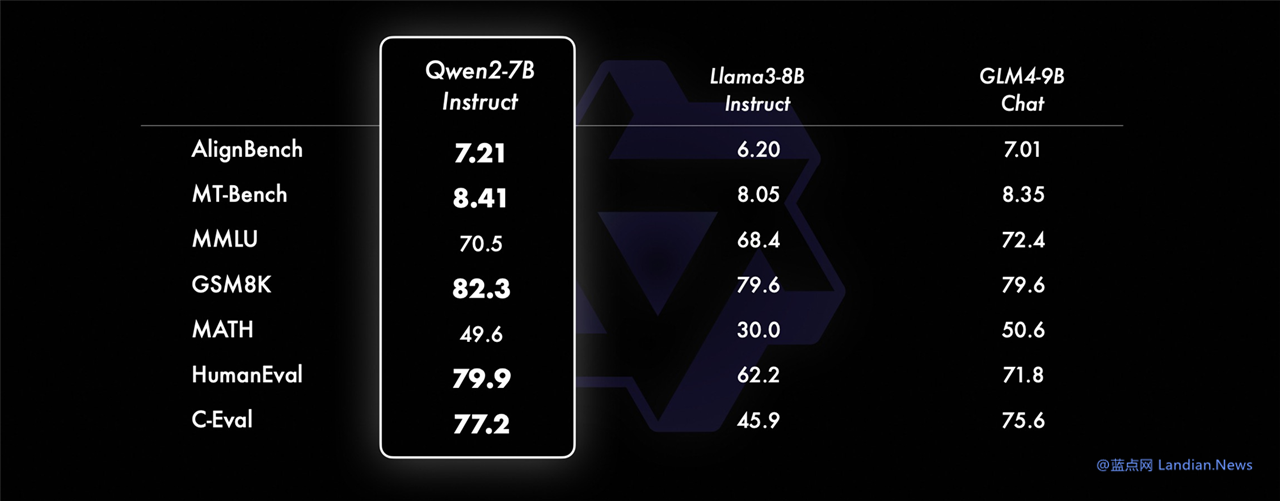
模型评估显示 Qwen2 能力超过 Llama3:
目前人工智能开源 / 开放社区中最重要的两个贡献者就是 Meta 和阿里云,Meta 主要就是 Llama 系列模型最新版本为 Llama3。
在开源 / 开放模型能力评测中,Qwen2-72B 版在各方面超过 Llama3-70B,也超过了 Mixtral-8x22B,所以现在压力给到了 Meta,不知道 Meta 什么时候发布新版本。
阿里云 AI 团队表示:
大规模预训练后,我们对模型进行精细的微调,以提升其智能水平,让其表现更接近人类。这个过程进一步提升了代码、数学、推理、指令遵循、多语言理解等能力。此外,模型学会对齐人类价值观,它也随之变得更加对人类有帮助、诚实以及安全。我们的微调过程遵循的原则是使训练尽可能规模化的同时并且尽可能减少人工标注。我们探索了如何采用多种自动方法以获取高质量、可靠、有创造力的指令和偏好数据,其中包括针对数学的拒绝采样、针对代码和指令遵循的代码执行反馈、针对创意写作的回译、针对角色扮演的 scalable oversight、等等。在训练方面,我们结合了有监督微调、反馈模型训练以及在线 DPO 等方法。我们还采用了在线模型合并的方法减少对齐税。这些做法都大幅提升了模型的基础能力以及模型的智能水平。