2024-6-18 21:33:33 Author: hackernoon.com(查看原文) 阅读量:3 收藏
As Kubernetes continues to revolutionize the way we manage and deploy applications, understanding its intricacies becomes essential for developers and operations teams alike. If you don't have a dedicated DevOps team you probably shouldn't be working with Kubernetes.
Despite that, in some cases, a DevOps engineer might not be available while we're debugging an issue. For these situations and for general familiarity we should still keep abreast with common Kubernetes issues to bridge the gap between development and operations. I think this also provides an important skill that helps us understand the work of DevOps better, with that understanding we can improve as a cohesive team. This guide explores prevalent Kubernetes errors and provides troubleshooting tips to help developers navigate the complex landscape of container orchestration.
As a side note, if you like the content of this and the other posts in this series check out my
Identifying Configuration Issues
When you encounter configuration issues in Kubernetes, the first place to check is the status column using the kubectl get pods command. Common errors manifest here, requiring further inspection with kubectl describe pod.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
my-first-pod-id-xxxx 1/1 Running 0 13s
my-second-pod-id-xxxx 1/1 Running 0 13s
Common Causes and Solutions
- Insufficient Resources: Notice that this means resources for the POD itself and not resources within the container. It means the hardware or surrounding VM is hitting a limit.
- Symptom: Pods fail to schedule due to resource constraints.
- Solution: Scale up the cluster by adding more nodes to accommodate the resource requirements.
- Volume Mounting Failures:
- Symptom: Pods cannot mount volumes correctly.
- Solution: Ensure storage is defined accurately in the pod specification and check the storage class and Persistent Volume (PV) configurations.
Detailed Investigation Steps
We can use kubectl describe pod: This command provides a detailed description of the pod, including events that have occurred. By examining these events, we can pinpoint the exact cause of the issue.
Another important step is resource quota analysis. Sometimes, resource constraints are due to namespace-level resource quotas. Use kubectl get resourcequotas to check if quotas are limiting pod creation.
Dealing with Image Pull Errors
Errors like ErrImagePull or ImagePullBackOff indicate issues with fetching container images. These errors are typically related to image availability or access permissions.
Troubleshooting Steps
The first step is checking the image name which we can do with the following command:
docker pull <image-name>
We then need to verify the image name for typos or invalid characters. I pipe the command through grep to verify the name is 100% identical, some typos are just notoriously hard to spot.
Credentials can also be a major pitfall. E.g. an authorization failure when pulling images from private repositories. We must ensure that Docker registry credentials are correctly configured in Kubernetes secrets.
Network configuration should also be reviewed. Ensure that the Kubernetes nodes have network access to the Docker registry. Network policies or firewall rules might block access.
There are quite a few additional pitfalls such as problems with image tags. Ensure you are using the correct image tags. Latest tags might not always point to the expected image version.
If you're using a private registry you might be experiencing access issues. Make sure your credentials are up-to-date and the registry is accessible from all nodes in all regions.
Handling Node Issues
Node-related errors often point to physical or virtual machine issues. These issues can disrupt the normal operation of the Kubernetes cluster and need prompt attention.
To check node status use the command:
kubectl get nodes
We can then identify problematic nodes in the resulting output. It's a cliché but sometimes rebooting nodes is the best solution to some problems. We can reboot the affected machine or VM. Kubernetes should attempt to "self-heal" and recover within a few minutes.
To investigate node conditions we can use the command:
kubectl describe node <node-name>
We should look for conditions such as MemoryPressure, DiskPressure, or NetworkUnavailable. These conditions provide clues about the underlying issue we should address in the node.
Preventive Measures
Node monitoring should be used with tools such as Prometheus, and Grafana to keep an eye on node health and performance. These work great for low-level Kubernetes-related issues, we can also use them for high-level application issues.
There are some automated healing tools such as the Kubernetes Cluster Autoscaler that we can leverage to automatically manage the number of nodes in your cluster based on workload demands. I'm not a huge fan as I'm afraid of a cascading failure that would trigger additional resource consumption.
Managing Missing Configuration Keys or Secrets
Missing configuration keys or secrets are common issues that disrupt Kubernetes deployments. Proper management of these elements is crucial for smooth operation.
We need to use ConfigMaps and secrets. These let us store configuration values and sensitive information securely. To avoid that we need to ensure that ConfigMaps and Secrets are correctly referenced in your pod specifications.
Inspect pod descriptions using the command:
kubectl describe pod <pod-name>
Review the output and look for missing configuration details. Rectify any misconfiguration.
ConfigMap and secret creation can be verified using the command:
kubectl get configmaps
and:
kubectl get secrets
Ensure that the required ConfigMaps and Secrets exist in the namespace and contain the expected data. It's best to keep non-sensitive parts of ConfigMaps in version control while excluding Secrets for security. Furthermore, you should use different ConfigMaps and Secrets for different environments (development, staging, production) to avoid configuration leaks.
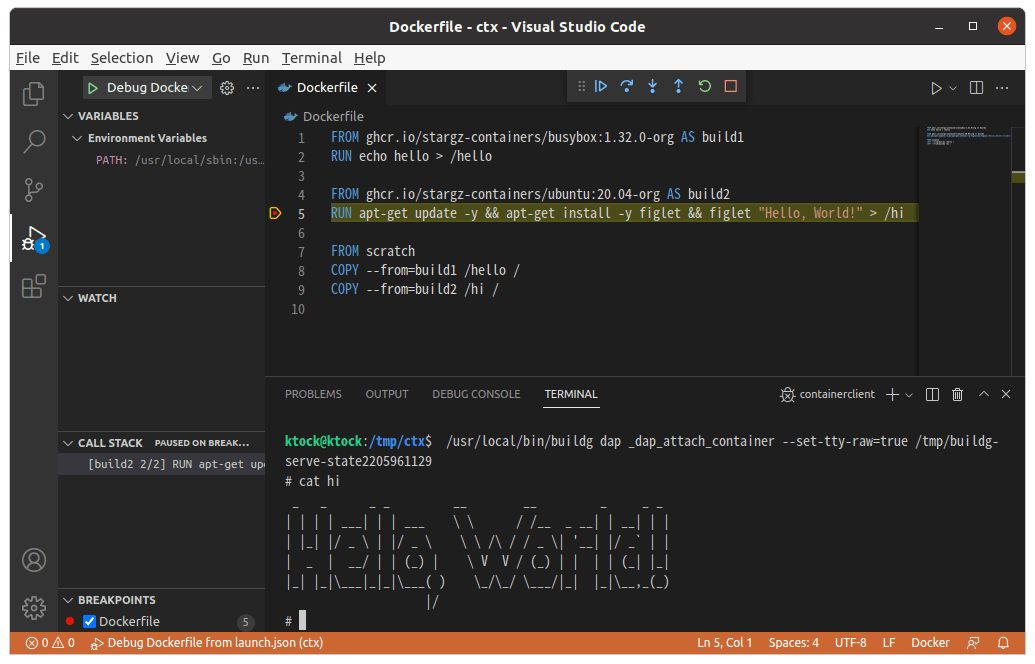
Utilizing Buildg for Interactive Debugging
Buildg is a relatively new tool that enhances the debugging process for Docker configurations by allowing interactive debugging.
It provides Interactive Debugging for configuration issues in a way that's similar to a standard debugging. It lets us step through the Dockerfile stages and set breakpoints. Buildg is compatible with VSCode and other IDEs via the Debug Adapter Protocol (DAP).
Buildg lets us inspect container state at each stage of the build process to identify issues early.
To install buildg follow the instructions on the

Conclusion
Debugging Kubernetes can be challenging, but with the right knowledge and tools, developers can effectively identify and resolve common issues. By understanding configuration problems, image pull errors, node issues, and the importance of ConfigMaps and Secrets, developers can contribute to more robust and reliable Kubernetes deployments. Tools like Buildg offer promising advancements in interactive debugging, further bridging the gap between development and operations.
As Kubernetes continues to evolve, staying informed about new tools and best practices will be essential for successful application management and deployment. By proactively addressing these common issues, developers can ensure smoother, more efficient Kubernetes operations, ultimately leading to more resilient and scalable applications.
如有侵权请联系:admin#unsafe.sh