2024-6-19 23:0:28 Author: hackernoon.com(查看原文) 阅读量:6 收藏
Authors:
(1) Bobby He, Department of Computer Science, ETH Zurich (Correspondence to: [email protected].);
(2) Thomas Hofmann, Department of Computer Science, ETH Zurich.
Table of Links
Simplifying Transformer Blocks
Discussion, Reproducibility Statement, Acknowledgements and References
A Duality Between Downweighted Residual and Restricting Updates In Linear Layers
C ADDITIONAL EXPERIMENTS
In this section, we provide additional experiments and ablations on top of those provided in the main paper. The experiments in this section are ordered to follow the chronological order of where they are referenced (or most relevant) in the main paper.
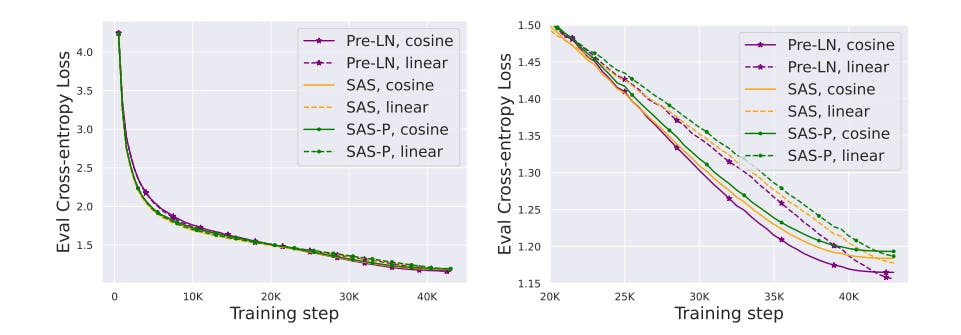
Linear vs Cosine decay LR schedule Fig. 11 compares linear and cosine decay LR schedule. We see that linear decay provides better final performance across both our models and baselines, and use linear decay throughout the rest of the paper.

Shaped Attention vs Value-SkipInit Fig. 12 explains our reasons for using Shaped Attention Eq. (5) (Noci et al., 2023) over the modified attention matrix, αI + βA(X), Eq. (4), that was introduced by He et al. (2023) in Value-SkipInit. We see that Shaped Attention gives a small but consistent gain throughout training. The experiments here follow the same training and hyperparameter setup as those in Sec. 4.
Sensitivity to MLP block gain initialisation In Sec. 4.1, we motivated downweighting the initialisation of trainable MLP block weight βFF (c.f. Eqs. (1) and (7)) in skipless architectures to replicate the implicit downweighting mechanism of Pre-LN skips. Fig. 13 shows the sensitivity of final loss to our initialisation for trainable βFF.






Fig. 14 is the equivalent of Fig. 3 but with LL-tied (yellow line with diamond markers) and all-tied (blue line with star markers) included. In Fig. 14, we see that matching the functional output (as in LL tied) with orthogonal initialisation provides a slight improvement to close the gap between the random orthogonal (green line) and identity (purple line) initialisations. Matching the attention sub-block outputs (as in all-tied) further improves performance, but does not fully close the gap to identity initialisation. Interestingly, it seems like orthogonally initialised values and projections do benefit from being trainable (i.e. small but non-zero βV , βP ). We leave a further exploration of these observations to future work.

Figs. 16 to 19 plot the corresponding trajectories, of the model in Fig. 4, for various other trainable scalar parameters we have: namely, the three shaped attention parameters 1) α on the identity (Fig. 16), 2) β on the softmax attention output (Fig. 17), 3) γ on the centring matrix (Fig. 18), as well as 4) βFF on the MLP block (Fig. 19). We see that none of these other scalar parameters converge to zero. The shaped attention parameters have error bars denoting standard deviations across (the 12) heads.





Identity values and projections with default Pre-LN block In Sec. 4.2 we observed that removing values and projection parameters by setting them to the identity improves the convergence speed per parameter update of transformer blocks with skipless attention sub-blocks. This raises the question of whether the same would occur in the standard block that uses attention sub-blocks skip connections i.e. the Pre-LN block. In Fig. 20 we compare the default Pre-LN block to one with values and projections set to be identity. We see that in this case identity values and projections actually slightly hurt performance in terms of loss reduction per update, in constrast to the skipless case. We also tried to downweight the attention block residual (βSA < 1 in the notation of Eq. (1)) with identity values and projections to see if the scale of the attention skip and residual was the reason for this difference, but this did not change the findings of Fig. 20. We do not have a satisfying explanation for this, but our intuition is that identity value and projections (as opposed to e.g. Gaussian/random orthogonal initialisation) with attention skip means that the two branches of the skip are no longer independent at initialisation and interfere with each other, though it is unclear that this would continue to hold during training.

Linearising MLP activations As stated in Sec. 4.3, we tried to use the recent idea of “linearising” activation functions in order to obtain better signal propagation (Martens et al., 2021; Zhang et al., 2022; Li et al., 2022) in deep NNs with skip connections, and recover lost training speed when the MLP skip is removed. In particular, Li et al. (2022) show for Leaky ReLU,






We see that all blocks without MLP skip train significantly slower than our SAS block (which matches the training speed of the Pre-LN block). In fact, linearising ReLU into LReLU seemed to hurt training speed rather than help it. These findings are consistent with those of previous works with AdamW optimiser (Martens et al., 2021; Zhang et al., 2022; He et al., 2023). We note that a big reason behind this is that the architectures with skipless MLP sub-blocks required an order of magnitude smaller learning rate (1e − 4 vs 1e − 3) otherwise training was unstable.
Loss vs training step In Fig. 23, we provide the equivalent plot to Fig. 5, but in terms of loss over the steps taken. Our SAS and SAS-P essentially match the Pre-LN model in terms of loss reduction per step, whilst removing normalisation slightly hurts performance.
Crammed Bert loss vs training step In Fig. 24 we plot the MLM loss in the Crammed Bert setting on the Pile dataset, as a function of the number of microbatch steps taken. Because our models have higher throughput they are able to take more steps within the 24 hour allotted time.
GLUE breakdown In Table 2, we provide a breakdown of the GLUE results in Table 1 in terms of different tasks.


如有侵权请联系:admin#unsafe.sh